自监督语义分割面模型——Masked Autoencoders Are Scalable Vision Learners(MAE)论文阅读
1、摘要
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3× or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pretraining and shows promising scaling behavior
本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的MAE方法很简单:我们屏蔽输入图像的随机补丁并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对补丁的可见子集(没有掩码令牌)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码令牌重建原始图像。其次,我们发现掩盖输入图像的高比例,例如75%,产生了一个重要的和有意义的自我监督任务。这两种设计的结合使我们能够高效地训练大型模型:我们加速了训练(3倍或更多)并提高了准确性。我们的可扩展方法允许学习泛化良好的大容量模型:例如,在仅使用ImageNet-1K数据的方法中,vanilla ViT-Huge模型达到了最好的准确率(87.8%)。下游任务的迁移性能优于监督预训练,并显示出有希望的缩放行为。

我们的MAE架构。在预训练过程中,图像补丁的一个大的随机子集(例如75%)被屏蔽掉。该编码器应用于可见补丁的小子集。在编码器之后引入掩码令牌,然后由一个小型解码器处理完整的编码补丁和掩码令牌,以像素为单位重建原始图像。预训练后,丢弃解码器,将编码器应用于未损坏的图像(完整的补丁集)进行识别任务。
2、 ImageNet Experiments
We do self-supervised pre-training on the ImageNet-1K (IN1K) [13] training set. Then we do supervised training to evaluate the representations with (i) end-to-end fine-tuning or (ii) linear probing. We report top-1 validation accuracy of a single 224×224 crop. Details are in Appendix
我们在ImageNet-1K (IN1K)训练集上进行自监督预训练。然后我们利用端到端微调或(i线性探测进行监督训练来评估表征。我们报告了单个224×224作物的前1验证精度。详情见附录。

(a)解码器深度。深度解码器可以提高线性探测精度。
(b)解码器宽度。解码器可以比编码器(1024-d)更窄。
©掩码令牌。没有掩码的编码器比kens更准确、更快(表2)。
(d)重建目标。像素作为重建目标是有效的。
(e)数据增强。我们的MAE工作在最小或没有增强。
(f)掩膜采样。随机抽样效果最好。
Table 1. MAE ablation experiments with ViT-L/16 on ImageNet-1K. We report fine-tuning (ft) and linear probing (lin) accuracy (%). If not specified, the default is: the decoder has depth 8 and width 512, the reconstruction target is unnormalized pixels, the data augmentation is random resized cropping, the masking ratio is 75%, and the pre-training length is 800 epochs. Default settings are marked in gray .
表1。viti - l /16在ImageNet-1K上的MAE消融实验。我们报告了微调(ft)和线性探测(lin)精度(%)。如果未指定,默认为:解码器深度8,宽度512,重建目标为非归一化像素,数据增强为随机调整大小裁剪,掩蔽比为75%,预训练长度为800 epoch。默认设置以灰色标记。
3、Transfer Learning Experiments

Table 3. Comparisons with previous results on ImageNet1K. The pre-training data is the ImageNet-1K training set (except the tokenizer in BEiT was pre-trained on 250M DALLE data [45]). All self-supervised methods are evaluated by end-to-end fine-tuning. The ViT models are B/16, L/16, H/14 [16]. The best for each column is underlined. All results are on an image size of 224, except for ViT-H with an extra result on 448. Here our MAE reconstructs normalized pixels and is pre-trained for 1600 epochs
表3。与先前ImageNet1K结果的比较。预训练数据为ImageNet-1K训练集(除了BEiT中的标记器是在250M DALLE数据上预训练的[45])。所有的自监督方法都是通过端到端微调来评估的。ViT模型为B/16、L/16、H/14[16]。每一栏最好的都用下划线标出。所有的结果都是224的图像大小,除了ViT-H的额外结果是448。在这里,我们的MAE重建归一化像素,并进行1600次预训练。
Object detection and segmentation.
We fine-tune Mask R-CNN [24] end-to-end on COCO [33]. The ViT backbone is adapted for use with FPN [32] (see A.3). We apply this approach for all entries in Table 4. We report box AP for object detection and mask AP for instance segmentation
目标检测和分割。我们在COCO[33]上端到端微调Mask R-CNN。ViT骨干网适用于FPN。我们将此方法应用于表4中的所有条目。我们报告了用于对象检测的框AP和用于实例分割的掩码AP。

COCO object detection and segmentation using a ViT Mask R-CNN baseline. All entries are based on our implementation. Self-supervised entries use IN1K data without labels. Mask AP follows a similar trend as box AP
使用ViT Mask R-CNN基线的COCO对象检测和分割。所有条目都基于我们的实现。自监督条目使用不带标签的IN1K数据。掩码AP的趋势与方框AP相似
Compared to supervised pre-training, our MAE performs better under all configurations (Table 4). With the smaller ViT-B, our MAE is 2.4 points higher than supervised pretraining (50.3 vs. 47.9, APbox). More significantly, with the larger ViT-L, our MAE pre-training outperforms supervised pre-training by 4.0 points (53.3 vs. 49.3)
与监督预训练相比,我们的MAE在所有配置下都表现更好(表4)。在ViT-B较小的情况下,我们的MAE比监督预训练高2.4分(50.3 vs. 47.9, APbox)。更重要的是,随着ViT-L的增大,我们的MAE预训练比监督预训练高出4.0分(53.3比49.3)。
Semantic segmentation.
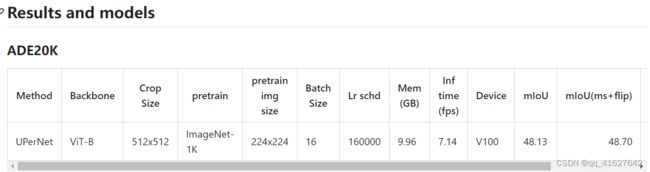
We experiment on ADE20K [66] using UperNet [57] (see A.4). Table 5 shows that our pretraining significantly improves results over supervised pretraining, e.g., by 3.7 points for ViT-L. Our pixel-based MAE also outperforms the token-based BEiT. These observations are consistent with those in COCO
语义分割。我们使用UperNet[57]对ADE20K[66]进行了实验(见A.4)。表5显示,我们的预训练显著提高了监督预训练的结果,例如viti - l提高了3.7分。我们基于像素的MAE也优于基于令牌的MAE。这些观测结果与COCO的观测结果一致。
MMSegmention用法
要使用其他存储库的预训练模型,需要转换关键字。
我们在tools目录中提供了一个beit2mmseg.py脚本,用于将MAE模型的关键字从官方存储库转换为MMSegmentation样式。
python tools/model_converters/beit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}
python tools/model_converters/beit2mmseg.py https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth pretrain/mae_pretrain_vit_base_mmcls.pth
python tools/model_converters/beit2mmseg.py https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_large.pth pretrain/mae_pretrain_vit_large_mmcls.pth
此脚本转换模型并将PRETRAIN_PATH转换后的模型存储在STORE_PATH.
在我们的默认设置中,预训练模型可以定义如下:

验证模型的单尺度结果:
sh tools/dist_test.sh \
work_dirs/runs/train/selfup/mae/upernet_mae-base_fp16_8x2_512x512_160k_ade20k.py checkpoints/mae/upernet_mae-base_fp16_8x2_512x512_160k_ade20k_20220426_174752-f92a2975.pth --eval mIoU
python tools/test.py --config work_dirs/runs/train/selfup/mae/upernet_mae-base_fp16_8x2_512x512_160k_ade20k.py --checkpoint checkpoints/mae/upernet_mae-base_fp16_8x2_512x512_160k_ade20k_20220426_174752-f92a2975.pth --eval mIoU
由于相对位置嵌入要求输入长宽相等,因此采用滑动窗口进行多尺度推理。所以我们设置min_size=512,即最短边为512。所以config的多尺度推理是单独进行的,而不是’–aug-test’。对于多尺度推理:
sh tools/dist_test.sh \
configs/mae/upernet_mae-base_fp16_512x512_160k_ade20k_ms.py \
upernet_mae-base_fp16_8x2_512x512_160k_ade20k_20220426_174752-f92a2975.pth $GPUS --eval mIoU
mmsegmentation/mmseg/models/backbones/mae.py
# Copyright (c) OpenMMLab. All rights reserved.import math
import math
import torch
import torch.nn as nn
from mmcv.cnn.utils.weight_init import (constant_init, kaiming_init,
trunc_normal_)
from mmcv.runner import ModuleList, _load_checkpoint
from torch.nn.modules.batchnorm import _BatchNorm
from mmseg.utils import get_root_logger
from ..builder import BACKBONES
from .beit import BEiT, BEiTAttention, BEiTTransformerEncoderLayer
class MAEAttention(BEiTAttention):
"""Multi-head self-attention with relative position bias used in MAE.
具有相对位置偏差的多头自注意在MAE中的应用
This module is different from ``BEiTAttention`` by initializing the
relative bias table with zeros.
"""
def init_weights(self):
"""Initialize relative position bias with zeros."""
# As MAE initializes relative position bias as zeros and this class
# inherited from BEiT which initializes relative position bias
# with `trunc_normal`, `init_weights` here does
# nothing and just passes directly
pass
class MAETransformerEncoderLayer(BEiTTransformerEncoderLayer):
"""Implements one encoder layer in Vision Transformer.
This module is different from ``BEiTTransformerEncoderLayer`` by replacing
``BEiTAttention`` with ``MAEAttention``.
"""
def build_attn(self, attn_cfg):
self.attn = MAEAttention(**attn_cfg)
@BACKBONES.register_module()
class MAE(BEiT):
"""VisionTransformer with support for patch.
Args:
img_size (int | tuple): Input image size. Default: 224.
patch_size (int): The patch size. Default: 16.
in_channels (int): Number of input channels. Default: 3.
embed_dims (int): embedding dimension. Default: 768.
num_layers (int): depth of transformer. Default: 12.
num_heads (int): number of attention heads. Default: 12.
mlp_ratio (int): ratio of mlp hidden dim to embedding dim.
Default: 4.MLP隐藏维度与编码维度之比
out_indices (list | tuple | int): Output from which stages.
Default: -1.
attn_drop_rate (float): The drop out rate for attention layer.
Default 0.0
drop_path_rate (float): stochastic depth rate. Default 0.0.
norm_cfg (dict): Config dict for normalization layer.
Default: dict(type='LN')
act_cfg (dict): The activation config for FFNs.
Default: dict(type='GELU').
patch_norm (bool): Whether to add a norm in PatchEmbed Block.
Default: False.
final_norm (bool): Whether to add a additional layer to normalize
final feature map. Default: False.
num_fcs (int): The number of fully-connected layers for FFNs.
Default: 2.
norm_eval (bool): Whether to set norm layers to eval mode, namely,
freeze running stats (mean and var). Note: Effect on Batch Norm
and its variants only. Default: False.
pretrained (str, optional): model pretrained path. Default: None.
init_values (float): Initialize the values of Attention and FFN
with learnable scaling. Defaults to 0.1.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
"""
def __init__(self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dims=768,
num_layers=12,
num_heads=12,
mlp_ratio=4,
out_indices=-1,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_cfg=dict(type='LN'),
act_cfg=dict(type='GELU'),
patch_norm=False,
final_norm=False,
num_fcs=2,
norm_eval=False,
pretrained=None,
init_values=0.1,
init_cfg=None):
super(MAE, self).__init__(
img_size=img_size,
patch_size=patch_size,
in_channels=in_channels,
embed_dims=embed_dims,
num_layers=num_layers,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
out_indices=out_indices,
qv_bias=False,
attn_drop_rate=attn_drop_rate,
drop_path_rate=drop_path_rate,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
patch_norm=patch_norm,
final_norm=final_norm,
num_fcs=num_fcs,
norm_eval=norm_eval,
pretrained=pretrained,
init_values=init_values,
init_cfg=init_cfg)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims))
self.num_patches = self.patch_shape[0] * self.patch_shape[1]
self.pos_embed = nn.Parameter(
torch.zeros(1, self.num_patches + 1, embed_dims))
def _build_layers(self):
dpr = [
x.item()
for x in torch.linspace(0, self.drop_path_rate, self.num_layers)
]
self.layers = ModuleList()
for i in range(self.num_layers):
self.layers.append(
MAETransformerEncoderLayer(
embed_dims=self.embed_dims,
num_heads=self.num_heads,
feedforward_channels=self.mlp_ratio * self.embed_dims,
attn_drop_rate=self.attn_drop_rate,
drop_path_rate=dpr[i],
num_fcs=self.num_fcs,
bias=True,
act_cfg=self.act_cfg,
norm_cfg=self.norm_cfg,
window_size=self.patch_shape,
init_values=self.init_values))
def fix_init_weight(self):
"""Rescale the initialization according to layer id.
This function is copied from https://github.com/microsoft/unilm/blob/master/beit/modeling_pretrain.py. # noqa: E501
Copyright (c) Microsoft Corporation
Licensed under the MIT License
"""
def rescale(param, layer_id):
param.div_(math.sqrt(2.0 * layer_id))
for layer_id, layer in enumerate(self.layers):
rescale(layer.attn.proj.weight.data, layer_id + 1)
rescale(layer.ffn.layers[1].weight.data, layer_id + 1)
def init_weights(self):
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
self.apply(_init_weights)
self.fix_init_weight()
if (isinstance(self.init_cfg, dict)
and self.init_cfg.get('type') == 'Pretrained'):
logger = get_root_logger()
checkpoint = _load_checkpoint(
self.init_cfg['checkpoint'], logger=logger, map_location='cpu')
state_dict = self.resize_rel_pos_embed(checkpoint)
state_dict = self.resize_abs_pos_embed(state_dict)
self.load_state_dict(state_dict, False)
elif self.init_cfg is not None:
super(MAE, self).init_weights()
else:
# We only implement the 'jax_impl' initialization implemented at
# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py#L353 # noqa: E501
# Copyright 2019 Ross Wightman
# Licensed under the Apache License, Version 2.0 (the "License")
trunc_normal_(self.cls_token, std=.02)
for n, m in self.named_modules():
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
if 'ffn' in n:
nn.init.normal_(m.bias, mean=0., std=1e-6)
else:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
kaiming_init(m, mode='fan_in', bias=0.)
elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
constant_init(m, val=1.0, bias=0.)
def resize_abs_pos_embed(self, state_dict):
if 'pos_embed' in state_dict:
pos_embed_checkpoint = state_dict['pos_embed']
embedding_size = pos_embed_checkpoint.shape[-1]
num_extra_tokens = self.pos_embed.shape[-2] - self.num_patches
# height (== width) for the checkpoint position embedding
orig_size = int(
(pos_embed_checkpoint.shape[-2] - num_extra_tokens)**0.5)
# height (== width) for the new position embedding
new_size = int(self.num_patches**0.5)
# class_token and dist_token are kept unchanged
if orig_size != new_size:
extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
# only the position tokens are interpolated
pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size,
embedding_size).permute(
0, 3, 1, 2)
pos_tokens = torch.nn.functional.interpolate(
pos_tokens,
size=(new_size, new_size),
mode='bicubic',
align_corners=False)
pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
state_dict['pos_embed'] = new_pos_embed
return state_dict
def forward(self, inputs):
B = inputs.shape[0]
x, hw_shape = self.patch_embed(inputs)
# stole cls_tokens impl from Phil Wang, thanks
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
outs = []
for i, layer in enumerate(self.layers):
x = layer(x)
if i == len(self.layers) - 1:
if self.final_norm:
x = self.norm1(x)
if i in self.out_indices:
out = x[:, 1:]
B, _, C = out.shape
out = out.reshape(B, hw_shape[0], hw_shape[1],
C).permute(0, 3, 1, 2).contiguous()
outs.append(out)
return tuple(outs)
配置文件解析
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder', #type:要构建的模型的类型
pretrained='work_dirs/pretrain/mae/mae_pretrain_vit_base_mmcls.pth',#预训练模型的位置
backbone=dict(
type='MAE',#骨干模块的类型
img_size=(512, 512),
patch_size=16,
in_channels=3,
embed_dims=768,
num_layers=12,
num_heads=12,
mlp_ratio=4,
out_indices=[3, 5, 7, 11],
attn_drop_rate=0.0,
drop_path_rate=0.1,
norm_cfg=dict(type='LN', eps=1e-06),
act_cfg=dict(type='GELU'),
norm_eval=False,
init_values=1.0),
neck=dict(type='Feature2Pyramid', embed_dim=768, rescales=[4, 2, 1, 0.5]),#颈部结构连接ViT主干和解码器头。
decode_head=dict(
type='UPerHead',
in_channels=[768, 768, 768, 768],
in_index=[0, 1, 2, 3],
pool_scales=(1, 2, 3, 6),
channels=768,
dropout_ratio=0.1,
num_classes=150,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=768,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=150,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
train_cfg=dict(),
test_cfg=dict(mode='slide', crop_size=(512, 512), stride=(341, 341)))
dataset_type = 'ADE20KDataset'
data_root = 'data/ade/ADEChallengeData2016'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=4,
train=dict(
type='ADE20KDataset',
data_root='data/ade/ADEChallengeData2016',
img_dir='images/training',
ann_dir='annotations/training',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]),
val=dict(
type='ADE20KDataset',
data_root='data/ade/ADEChallengeData2016',
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='ADE20KDataset',
data_root='data/ade/ADEChallengeData2016',
img_dir='images/validation',
ann_dir='annotations/validation',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
dict(type='TensorboardLoggerHook')
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
optimizer = dict(
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
constructor='LayerDecayOptimizerConstructor',
paramwise_cfg=dict(num_layers=12, layer_decay_rate=0.65))
optimizer_config = dict()
lr_config = dict(
policy='poly',
warmup='linear',
warmup_iters=1500,
warmup_ratio=1e-06,
power=1.0,
min_lr=0.0,
by_epoch=False)
runner = dict(type='IterBasedRunner', max_iters=160000)
checkpoint_config = dict(by_epoch=False, interval=16000)
evaluation = dict(
interval=16000,
metric=['mIoU', 'mFscore'],
pre_eval=True,
save_best='auto')
fp16 = dict(loss_scale='dynamic')
work_dir = 'work_dirs/runs/train/selfup/mae'
gpu_ids = [0]
auto_resume = False