llmaindex 多文档管理,索引构建
https://redian.news/wxnews/388999
#创建摘要索引
def creat_summary_index(file_path=r"C:\Users\Asus\Desktop\back_bitspider2\fastAPI_llamaindex\data\新闻\金十快讯"):
# # LLM Predictor (gpt-3.5-turbo)
# Load all wiki documents
wiki_titles = ["1","2","3"]
city_docs = []
for wiki_title in wiki_titles:
docs = SimpleDirectoryReader(input_files=[f"{file_path}/{wiki_title}.txt"]).load_data()
docs[0].doc_id = wiki_title
city_docs.extend(docs)
llm_predictor_chatgpt = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor_chatgpt, chunk_size=1024)
# default mode of building the index
response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)
# 自定义总结
# # customizing the summary query
# summary_query = (
# "Give a concise summary of this document in bullet points. Also describe some of the questions "
# "that this document can answer. "
# )
# doc_summary_index = DocumentSummaryIndex.from_documents(summary_query=summary_query,documents=doc_summary_index)
doc_summary_index = DocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
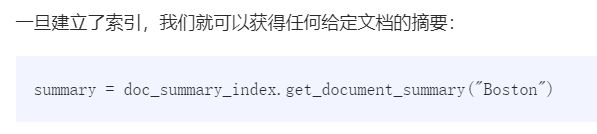
# doc_summary_index.get_document_summary("1")
doc_summary_index.storage_context.persist(r'C:\Users\Asus\Desktop\back_bitspider2\fastAPI_llamaindex\index')
def rebuild_summary_index():
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir=r'C:\Users\Asus\Desktop\back_bitspider2\fastAPI_llamaindex\index')
doc_summary_index = load_index_from_storage(storage_context)
query_engine = doc_summary_index.as_query_engine(response_mode="tree_summarize", use_async=True)
response = query_engine.query("最近有哪些新闻?")
print(response)
15:35:30
析
春秋航空:5月,公司客运运力投入(按可用座位公里计)同比增长167%,环比增长2.48%;旅客周转量(按收入客公里计)同比增长239.78%,环比增长1.45%;客座率为87.84%,同比增长18.82%,环比下降0.89%。(金十数据APP)
15:42:09
析
商务部:持续办好消费活动,将2023年定为消费提振年
金十数据6月15日讯,商务部新闻发言人束珏婷表示,持续办好消费活动。商务部将2023年定为消费提振年,已成功举办民生消费季、全国消费促进月,正在开展绿色消费季、国际消费季等一系列活动。在即将到来的暑期消费季期间,商务部还将推出618、夜生活节、数字消费节等消费新场景。各地也将举办一系列丰富多彩的活动,这些活动贯穿端午、暑期甚至会延续更长时间,将为消费市场增添更多信心。(证券时报)(金十数据APP)
15:46:30
析
格力电器:格力钛生产的新能源汽车已在全国230多个城市运营
金十数据6月15日讯,格力电器董秘邓晓博在6月15日举办的2022年度业绩说明会上表示,公司在绿色能源领域持续发力,致力于新能源电器及近用户侧能源互联网系统关键技术研究和产品开发,协同构建能源信息化与直流化新生态,推动绿色经济转型,目前主要聚焦于光伏空调板块、新能源汽车板块和锂电池板块的布局。其中在新能源汽车板块,格力钛生产的新能源汽车已在北京、上海、广州、成都、南京、天津、武汉等全国230多个城市运营。(证券时报)(金十数据APP)
最近有以下新闻:商务部将2023年定为消费提振年,格力电器董秘邓晓博表示公司在绿色能源领域持续发力,春秋航空5月客运运力投入和旅客周转量增长。
今天大多数构建 LLM 支持的 QA 系统的用户倾向于执行以下某种形式的操作:
- 获取源文档,将每个文档拆分为文本块
- 将文本块存储在向量数据库中
- 在查询期间,通过嵌入相似性和/或关键字过滤器来检索文本块。
- 执行响应并汇总答案
使用文本块进行嵌入检索有一些限制。
- 文本块缺乏全局上下文。通常,问题需要的上下文超出了特定块中索引的内容。
- 仔细调整 top-k / 相似度分数阈值。假设值太小,你会错过上下文。假设值值太大,并且成本/延迟可能会随着更多不相关的上下文而增加,噪音增加。
- 嵌入并不总是为问题选择最相关的上下文。嵌入本质上是在文本和上下文之间分别确定的。
文档摘要索引
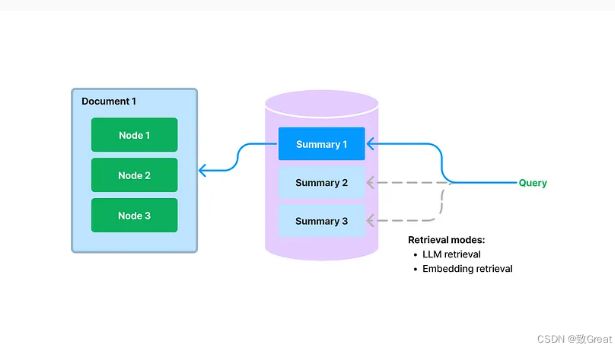
在构建期间,我们提取每个文档,并使用 LLM 从每个文档中提取摘要。我们还将文档拆分为文本块(节点)。摘要和节点都存储在我们的文档存储抽象中。我们维护从摘要到源文档/节点的映射。
在查询期间,我们使用以下方法根据摘要检索相关文档以进行查询:
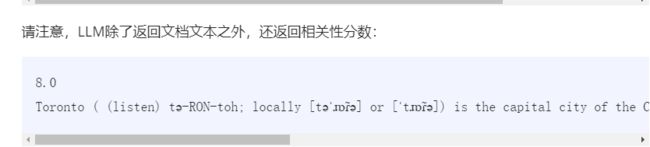
- 基于 LLM 的检索:我们向 LLM 提供文档摘要集,并要求 LLM 确定哪些文档是相关的+它们的相关性分数。
- 基于嵌入的检索:我们根据摘要嵌入相似性(使用 top-k 截止值)检索相关文档。
请注意,这种检索文档摘要的方法(即使使用基于嵌入的方法)不同于基于嵌入的文本块检索。文档摘要索引的检索类检索任何选定文档的所有节点,而不是返回节点级别的相关块。
存储文档的摘要还可以实现基于 LLM 的检索。我们可以先让 LLM 检查简明的文档摘要,看看它是否与查询相关,而不是一开始就将整个文档提供给 LLM。这利用了 LLM 的推理能力,它比基于嵌入的查找更先进,但避免了将整个文档提供给 LLM 的成本/延迟
对于比较长的文章为了避免上下文的割裂,使用摘要,可以将文章所有的信息获取,总结能力非常强

 https://xie.infoq.cn/article/de6a18ecd0e3069f78fc678f5
https://xie.infoq.cn/article/de6a18ecd0e3069f78fc678f5
- 关键词索引

关键词索引是关键词到包含这些关键词的节点的映射。它是多对多的映射,每个关键词可能指向多个节点,每个节点可能有多个映射到它的关键词。在查询时,从查询中提取关键词,只查询映射的节点。
关键词索引适合查询大量数据中的特定关键词,尤其是在知晓用户的查询偏好时颇为适用。例如,用户在查询与健康保健相关的文件进行查询,且只关心与 COVID 19 相关的文档,此时选择关键词索引再合适不过了。




https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/RedisIndexDemo.html

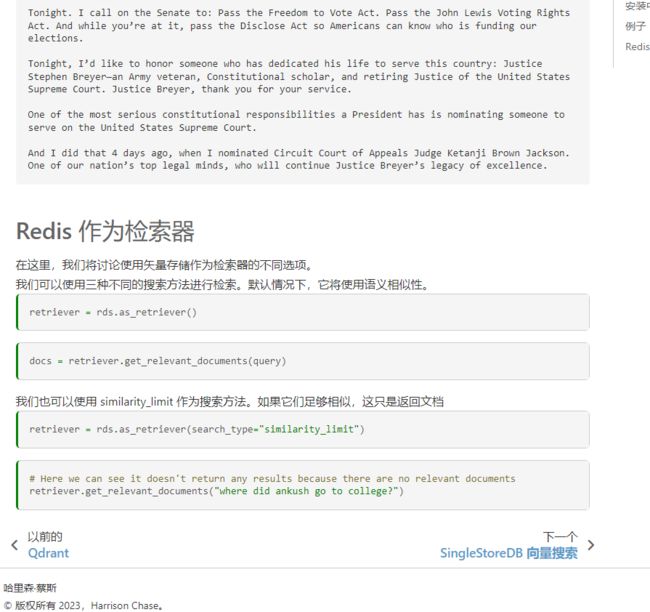
对于经常更新的数据就放在redis里
https://redis.com/solutions/use-cases/vector-database/

 https://juejin.cn/post/7220425595770896444
https://juejin.cn/post/7220425595770896444
1. 背景
Redis(Remote Dictionary Server)是一个开源的,基于内存的键值存储系统,常用于缓存、消息队列等场景。GPT(Generative Pre-trained Transformer)是一种深度学习模型,可以用于处理自然语言任务。要将Redis与GPT结合,我们可以将GPT模型应用于某些特定的应用场景,例如智能对话系统、推荐系统等,而Redis则作为缓存系统,提高整体性能。
2. 案例
- 将模型结果缓存到Redis中:将GPT模型生成的结果(如推荐结果、问答系统回答)存储在Redis中,可以有效减少重复计算的时间。当用户再次请求相同内容时,可以直接从Redis缓存中获取结果,从而提高响应速度。
- 使用Redis作为消息队列:当GPT处理大量请求时,可以使用Redis的发布/订阅功能或列表数据结构作为消息队列。这样可以有效地对请求进行排队处理,避免GPT模型的过载。
- 优化GPT模型:如果可以接受一定的精度损失,可以考虑使用GPT的精简版,如GPT-4 Mini或DistilGPT,以减少计算成本和延迟。此外,也可以使用模型压缩技术,如量化和剪枝,来优化模型。
- 优化Redis配置:根据您的应用需求,调整Redis的配置,如内存限制、缓存策略(如LRU, LFU等)、持久化策略等,以充分利用Redis的性能优势。
- 分布式部署:为了支持更高的并发量,可以考虑将GPT模型和Redis分布式部署。使用负载均衡器将请求分发给不同的GPT实例,并将Redis配置为集群模式,以实现高可用性和可扩展性。
- 监控和调优:定期监控Redis和GPT模型的性能指标,如响应时间、内存使用、CPU利用率等。根据监控数据,及时进行调优,以确保系统的稳定性和高性能。
3. 总结
使用Redis缓存GPT模型的结果,减少重复计算。 利用Redis作为消息队列,管理请求并避免GPT模型过载。 选择适当的GPT模型版本和优化技术以降低计算成本和延迟。 调整Redis配置,以满足应用需求并充分发挥其性能。 采用分布式部署,实现高可用性和可扩展性。 对系统性能进行监控和调优,确保稳定性和高性能。
https://github.com/RedisVentures/LLM-Document-Chat
https://github.com/uhub/awesome-chatgpt