【AIGC】1、爆火的 AIGC 到底是什么 | 全面介绍
文章目录
- 一、AIGC 的简要介绍
- 二、AIGC 的发展历程
- 三、AIGC 的基石
-
- 3.1 基本模型
- 3.2 基于人类反馈的强化学习
- 3.3 算力支持
- 四、生成式 AI(Generative AI)
-
- 4.1 单模态
-
- 4.1.1 生成式语言模型(Generative Language Models,GLM)
- 4.1.2 生成式视觉模型(Generative Vision Models)
- 4.2 多模态
-
- 4.2.1 视觉语言生成
- 4.2.2 文本音频生成
- 4.2.3 文本图形生成
- 4.2.4 文本代码生成
- 五、AIGC 的应用场景
-
- 5.1 ChatBot
- 5.2 Art
- 5.3 Music
- 5.4 Code
- 5.5 Education
参考论文:A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
发布时间:2023.03
AIGC:AI Generated Content,AI 生成内容,即使用人工智能生成内容,可以生成文字、图像、音频、视频、代码等。
一、AIGC 的简要介绍
AIGC 是使用 Generative AI (GAI,生成式 AI) 的方式,能够模拟人类的方式,在很短的时间内创作大量的内容。比如现在很火的如下两个模型:
- ChatGPT:一个语言模型,能够很快的理解并回复人类的问题
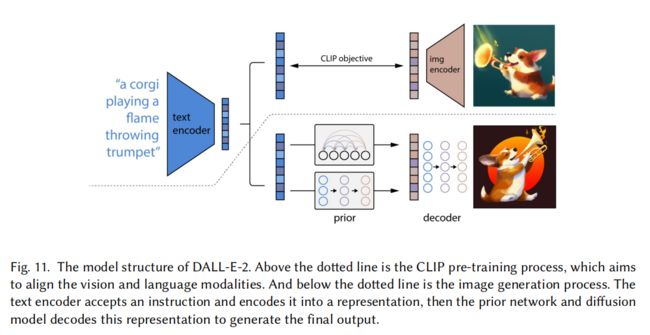
- DALL-E-2:能够在根据文字创作一幅对应的高质量图像,如图 1 所示
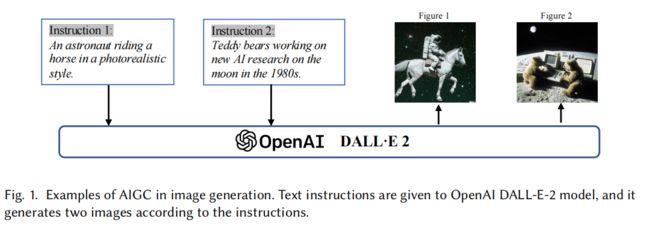
生成式 AI 需要做什么事情:
- 从人类的描述中提取信息
- 根据提取到的信息生成对应的内容
现在的 AIGC 和之前的工作相比有哪些优势:
- 之前的工作:没有大量的数据和硬件支撑
- AIGC:有大量的数据、优秀的基础模型、强有力的硬件计算资源,
- 比如语言模型: GPT-3 的预训练数据为 570G,基础模型尺寸为 175B,而前一版的 GPT-2 预训练数据只有 38G,基础模型尺寸为 1.5B,故 GPT-3 比 GPT-2 有更强的能力。而且 GPT-3 引入了强化学习来学习人类的反馈
- 比如图像模型:stable diffusion,同样在 2022 年提出,且拥有很强的图像生成能力
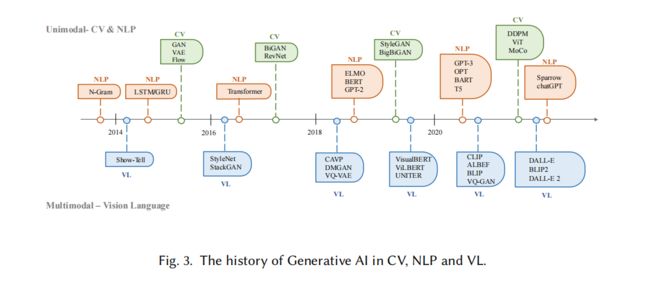
二、AIGC 的发展历程
-
1950s,隐马尔科夫模型(HMMs)和高斯混合模型(GMMs),可以生成序列数据,如台词或时间序列
-
2017 年之前,NLP 和 CV 的发展也分了两条道路:
- NLP:最初是使用 N-gram language modeling 通过学习单词的分布来生成句子,但又不能处理很长的句子,于是就引入了 RNN,后面又有了 LSTM 和 GRU。
- CV:2014 年 GAN 被提出,后面又有 VAE 和 diffusion 模型,用于生成高质量图像
-
2017 年之后,NLP 和 CV 的一部分工作重心逐渐有了合并于 Transformer 的趋势:
- 2017 年,Transformer 被提出并用于 NLP,如 BERT 和 GPT,都有了完胜之前 LSTM 和 GRU 的效果
- 2020 年,ViT 首次将 Transformer 用于图像分类人并取得了很好的效果,之后又有很多如 DETR、Swin、PVT 等基于 Transformer 的方法在图像领域的不同任务上同样取得了很好的效果
-
不仅如此,Transformer 也能够通过整合不同领域的信息来实现多模态任务
- CLIP 就是一个联合使用 vision-languange 的模型,通过将 transformer 的结构和视觉组件的结合,允许其在大量的文本和图像数据上训练。也正是由于其在预训练的时候整合了图像和语言信息,故能够作为图像编码器进行生成。
三、AIGC 的基石
3.1 基本模型
1、Transformer
Transformer 可以作为 backbone 或网络结构来实现多种不同模型的 SOTA,如 GPT-3[9]、DALL-E-2[5]、Codex[2] 和 Gopher[39]。
Transformer 结构大多是基于自注意力机制的 Encoder-Decoder 结构,Encoder 结构用于提取输入内容的隐式表达,Decoder 用于从隐式表达中生成输出。
Transformer 中的自注意力机制用于提取输入序列中不同 word 或 patch 的之间的关系。
Transformer 的另外一个优势在于其弱偏置归纳性,即引入的归纳偏置少,模型不容易很轻易的到达上限,故此使用大数据集进行预训练的 Transformer 能够达到很好的效果,并用于下游任务。
2、预训练的语言模型
Transformer 的结构目前已经成为语言模型的首选结构,也可以将不同方法分为两类:
- autoregressive language modeling(decoder):自回归式语言模型,BERT、RoBERTa、XL-Net
- Masked language modeling(encoder):掩码式语言模型,GPT-3、OPT
- encoder-decoder 模型
3.2 基于人类反馈的强化学习
尽管使用了大量的训练数据,AIGC 也可能并不能总是很好的理解人类的意图,比如实用性和真实性。
为了让 AIGC 的输出更接近于人类的偏好,从人类的反馈中不断进行强化学习也很重要, reinforcement learning from human feedback
(RLHF),比如 Sparrow、InstructGPT、ChatGPT 都使用了强化学习。
RLHF 的整个过程包括三个步骤:
- 其一,是一个基于大量数据预训练得到的语言模型
- 其二,训练一个奖励模型来对人类多种复杂的偏好进行编码
- 其三,对第一步得到的语言模型 θ \theta θ 进行 fine-tuned,来最大化第二步学习到的激励函数
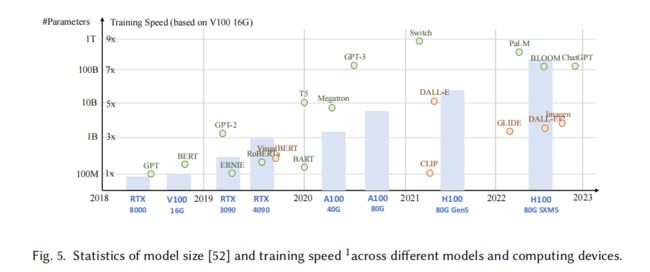
3.3 算力支持
现在发展成熟的硬件、分布式训练、云计算等都为大模型的产生提供了很大的支持
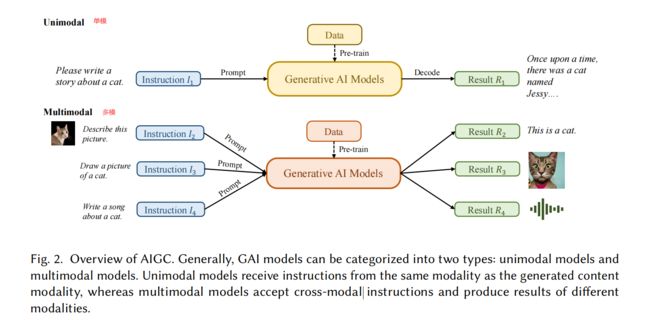
四、生成式 AI(Generative AI)
4.1 单模态
单模态生成模型,就是模型只能接收单一类型的输入,如文本或图像,然后产生对应类型的输出。
- 生成式语言模型:GPT-3、BART、T5 等
- 生成式视觉模型:GAN、VAE、normalizing flow 等
4.1.1 生成式语言模型(Generative Language Models,GLM)
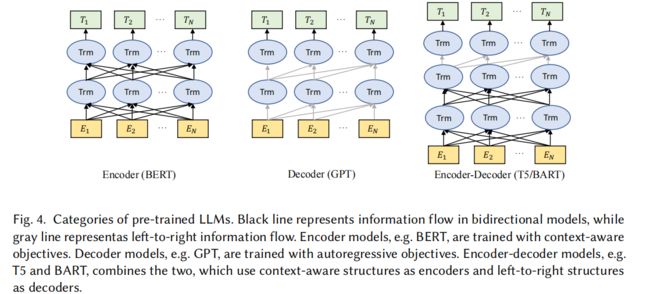
生成式语言模型是 NLP 模型的一种,该模型所要实现的就是经过训练后能够根据其之前所接触过的模式和结构,生成可读的人类语言。
可以用于对话系统、翻译、问答系统等。
现有的 SOTA 预训练语言模型可以分为:
- masked language model(encoder):一般用于分类任务
- autoregressive language model(decoder):一般用于文本生成
- encoder-decoder language:可以利用上下文信息和自回归属性来提高各种任务的性能
1、Decoder models
现有表现较好的基于 decoder 的自回归语言模型是 GPT[61],是使用 self-attention 的 Transformer 模型。还有 BERT、T5、InstructGPT 等。
2、Encoder-Decoder models:
现有的表现较好的是 Text-to-Text Transfer Transformer(T5)[56],同时使用了基于 Transformer 的 Encoder 和 Decoder 来进行预训练。
还有例如 Switch Transformer、ExT5、HELM 等
4.1.2 生成式视觉模型(Generative Vision Models)
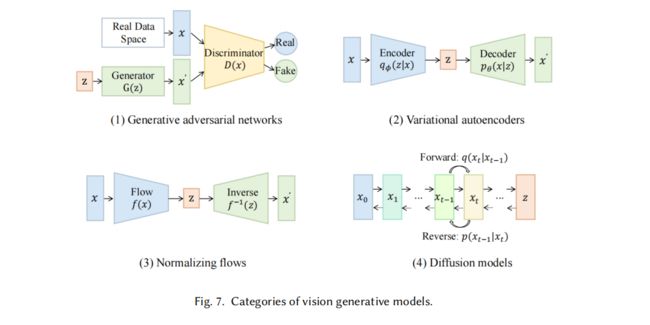
1、GAN,Generative Adversarial Networks(GANs)
GAN 是图像生成领域很流行的一个模型,包括两个模块:
- 生成模型,学习如何生成新的数据
- 判别模型,判断数据是真实的还是生成的假数据
典型方法有:
- LAPGAN
- DCGANs
- Progressive GAN
- SAGAN
- BigGAN
- StyleGAN
- D2GAN
- GMAN
- MGAN
- MAD-GAN
- CoGAN
2、VAE,Variational AutoEncoders
VAE 是生成模型,其原理是尝试学习数据的概率分布并学习如何重建数据使得其更接近原始输入数据。
3、Flow
Normalizing Flow 是一种基于分布变换的方式,使用一系列可逆和可微的映射将简单分布变成复杂分布
4、Diffusion
Diffusion model 是由通过逐步向输入图像中添加高斯噪声的前向扩散,和逐步恢复原图的逆向去噪组成的,是目前 SOTA 的方法。
- DDPM 使用两个马尔科夫链来逐步进行高斯加噪和反向去噪
- SGM(Score-based generative model)
- NCSN
- Score SDE
4.2 多模态
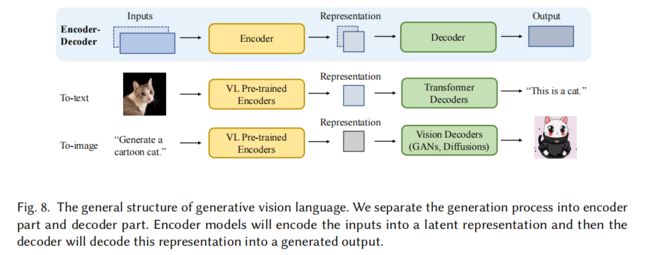
多模态生成的目标是学习一个模型,通过学习从数据中获得的多模态连接和交互来生成原始的模态。
不同模态的连接和交互是非常复杂的,这也使得多模态表示空间比单模态表示空间更难学习。
下面会涉及到各类 SOTA 多模态模型:
- 视觉语言生成
- 文本语音生成
- 文本图形生成
- 文本代码生成
4.2.1 视觉语言生成
Encoder-decoder 结构会经常被用于解决计算机视觉和自然语言处理的多模态生成问题
- Encoder:学习输入数据的复杂特征表达
- Decoder:生成反应跨模态交互、结构、一致性的原始模态表达
视觉语言 Encoder,多模态的结合可以直观的想象通过将两个不同模态的预训练模型结合起来即可,主要有两种:
- concatenated encoder
- cross-aligned encoder
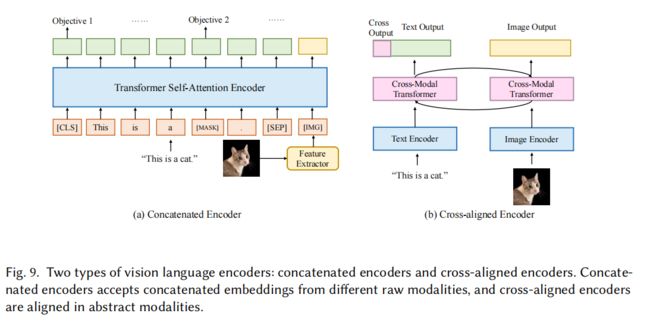
Concatenated Encoder:
- 将两个不同模态的模型 concat 起来,比如最早的 VisualBERT,使用 BERT 作为 text encoder,CNN 作为 image encoder,来自 image encoder 的编码被直接合并到 BERT 的输入编码中,让模型隐式地学习表达。
- VL-BERT,使用 Faster R-CNN 来抽取 RoI,将抽取到的 RoI 信息作为图像区域的编码
- UNITER
Cross-aligned Encoder:
- 该结构一般使用 tow-tower 结构,分别使用单个 tower 学习每个模态对应的特征,然后使用 cross-modality encoder 对两个模态的特征学习联合表达。
- LXMERT 使用 Transformer 来抽取图像特征和文本特征,然后使用了一个多模态 cross-attention 模块来进行协同学习,输出编码是视觉编码、语言编码、多模态编码
- ViLBERT 使用 cross-transformer 模型来对齐两个不同的模态,每个模态输入的 key 和 value 会被输入另外一个模态的 attention module 来生成一个合成的 attention 编码
- CLIP 使用点乘的方式来融合 cross layer,比上面的使用 self-attention 计算量更少

视觉语言模型 Decoder,能够通过给 encoder 得到的编码表达来生成特定模态的表达,主要包括:
- to-text
- to-image
To-text decoders,通常从 encoder 中接收文本上下文表达,并解码为一个句子,主要有如下两种模型,随着大型语言模型的出现,现在很多结构都使用冻结语言 decoder 的方式。
- jointly-trained models,联合训练解码器是指在解码表示时需要完整的交叉模态训练的解码器
- frozen models,冻结大语言模型,值训练 image decoder
To-image decoders,表示给定一条指令,生成对应的图像。用的较多的同样是 encoder-decoder 结构,encoder 用于学习语言信息,decoder 用于合成图像。一般有 GAN-based 和 diffusion-based 方法。
4.2.2 文本音频生成
文本音频生成
文本音乐生成
4.2.3 文本图形生成
4.2.4 文本代码生成
Text Code Generation 可以根据输入的语言描述来说自动的生成可用的代码
- CodeBERT
- CuBERT
- CodeT5
- AST
五、AIGC 的应用场景

5.1 ChatBot
可以和使用者进行基于文本的对话交互,一般使用语言模型来理解并根据问题进行语言的回答。
如微软小冰 Xiaoice,谷歌 Meena,微软 ChatGPT。
5.2 Art
AI 艺术生成是创作艺术品,一般都使用大型数据集在现有的艺术品上进行学习,学习到一定的规则后,模仿相关创作规则来产生新的艺术品。
如 OpenAI 的 DALL-E 系列,Stability.ai 的 DreamStudio,谷歌的 Imagen 等。
5.3 Music
音乐生成是指使用学习到的相关音乐创作规则,产生新的音乐创作。
如 OpenAI 的 Jukebox
5.4 Code
基于 AI 的编程系统包括生成完整的代码、源码和伪代码等
OpenAI 的 CodeGPT 是一个开源的基于 Transformer 结构的模型,还有 CodeParrot、Codex 等。
5.5 Education
还可以用于教育方面,比如生成教学视频、学术论文等。