研0的学习day3
今天主要是一个jdbc的api详解
1.DriverManager
a.注册驱动
b.获取数据库的链接(有其固定的格式)

2.Connection(数据库链接对象作用)
1.获取执行的SQL对象

2.管理事务

事务:事务是数据库章节,之前没看,看到这搜了一下,大概就是一个sql语句或者语句集。但是事务是具有原子性的,即开始的话就不会中途停止,所以这里若是出错的话就通过try/catch来进行一个rollback(回滚),回滚放在catch中。若是事务执行失败,则数据库退回之前状态,于数据库无影响。
try {
//开启事务
conn.setAutoCommit(false);
//执行sql
int count1 = stat.executeUpdate(sql1);
//处理结果
System.out.println(count1);
int i=3/0;
//执行sql
int count2 = stat.executeUpdate(sql2);
//处理结果
System.out.println(count2);
//提交事务
conn.commit();
} catch (Exception e) {
//回滚事务
conn.rollback();
throw new RuntimeException(e);
}这就是一个事务异常的出错后,进行的一次事务回滚。
3.statement(执行SQL语句)
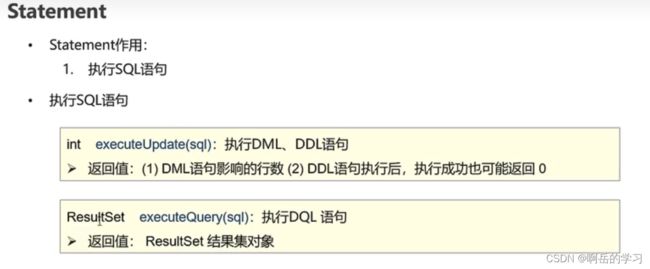
//期间对这个进行了一个测试,主要是对executeUpdate的测试,对其返回的数据进行一个测试。因为返回的是一个影响的sql行数,因此可以用来判定一些东西,如:登录密码的修改是否成功
//用到了一个@test,但是需要导入一个junit包,我的是导不进,所以没有用到@test,直接是主函数来解决DML,没有去测试DDL了,但是看弹幕说,主方法是测试不出来DDL的。

4.ResultSet
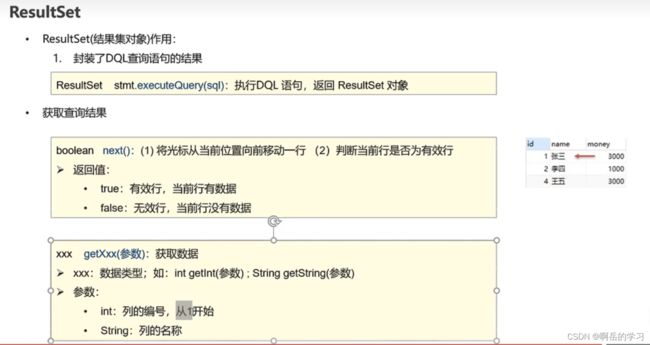
在图中的数据库表中,有一个箭头,即作为一个默认光标。依次从第一个数据库来判定查询结果,一直到最后一行数据,然后返回结果。
所以其代码的实现主要是一个这样的结构。

现实while判定是否存在下一行,若有则获取数据,若无,则跳出循环。
public static void main(String[] args) throws Exception {
// //注册驱动
// Class.forName("com.mysql.jdbc.Driver");
//获取链接
String url="jdbc:mysql://localhost:3306/db1?useSSL=false";
String username="root";
String password="123456";
Connection conn = DriverManager.getConnection(url,username,password);
//定义sql语句
String sql="select * from tb_user";
//获取执行sql对象statement
Statement stat= conn.createStatement();
//执行sql
ResultSet rs = stat.executeQuery(sql);
//处理结果,遍历rs中的所有数据
//6.1光标向下移动一行,并判断下一行是否有数据
while (rs.next()){
//6.2获取数据 getXXX
// int id = rs.getInt(1);
// String name = rs.getString(2);
// double word = rs.getDouble(3);
//
// System.out.println(id);
// System.out.println(name);
// System.out.println(word);
// System.out.println("---------------");
int id = rs.getInt("id");
String name = rs.getString("username");
double word = rs.getDouble("password");
System.out.println(id);
System.out.println(name);
System.out.println(word);
System.out.println("---------------");
}
//释放资源
rs.close();
stat.close();
conn.close();
}其后编写的代码没有使用一个注册驱动了,其实前面也可也不使用注册驱动。这是对整张表进行一个获取,所以对其定义sql语句有变化,是对整张表的一个获取。在resultset中,在获取数据阶段有两种获取方式,一是直接按表都顺序进行一个获取,另外一个是按表的列名称进行一个获取【当时也没有看懂为什么可以按照顺序获取,我的理解是按照列名获取,这样来说更能保证一个安全和准确】

将一个id作为一个java对象,并存放ArrayList(因为arraylist是存放对象的),之后可以直接拿出来进行一个展示
![]()
之后是做了一个案例演示,先是创建一个类,并针对数据表来创建3个私有成员,并封装。引出其setter和getter方法(快捷键:alt+insert)。之后在resultset中的while里面进行一个set,在外层创建一个arraylist集合,并将数据放入集合中。
public class JDBCDemo_ResultSet {
public static void main(String[] args) throws Exception {
//获取链接
String url="jdbc:mysql://localhost:3306/db1?useSSL=false";
String username="root";
String password="123456";
Connection conn = DriverManager.getConnection(url,username,password);
//定义sql语句
String sql="select * from tb_user";
//获取执行sql对象statement
Statement stat= conn.createStatement();
//执行sql
ResultSet rs = stat.executeQuery(sql);
//创建集合
List list = new ArrayList<>();
//处理结果,遍历rs中的所有数据
//6.1光标向下移动一行,并判断下一行是否有数据
while (rs.next()){
Account account = new Account();
//6.2获取数据 getXXX
int id = rs.getInt("id");
String name = rs.getString("username");
double word = rs.getDouble("password");
account.setId(id);
account.setName(name);
account.setWord(word);
//存入集合
list.add(account);
}
System.out.println(list);
//释放资源
rs.close();
stat.close();
conn.close();
} 5.PreparedStatement

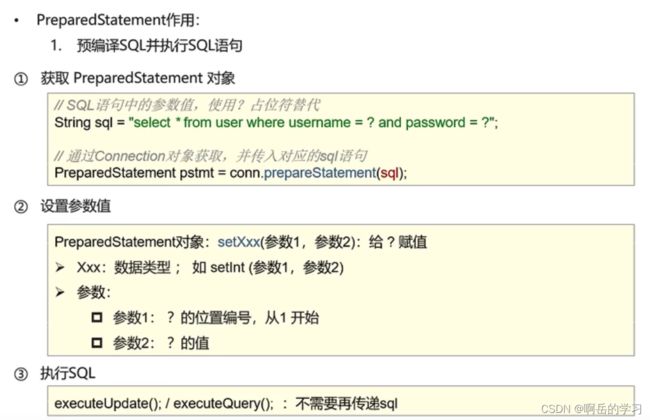
preparedstatement这个主要是一个sql防注入的,后面的框架部分都会有自动sql防注入,而且这节需要引入一些jar包,但是找不到,所以就没有对这个部分进行一个具体的练手。
以上是jdbc的api详解,接下来是jdbc的数据库连接池
-----------------------------------------------------------------------------------------------------------------------------
jdbc连接池
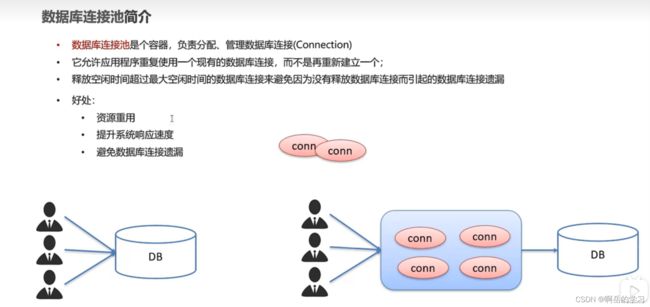
连接池于我的理解就是类似于一个工具包中,有许多的已经创建的对象,用户可以直接从工具包中将对象取出,拿出来使用,而不用针对盖用户重新去创建一个对象,因为这样创建对象,毕竟属于很底层的操作,虽然不难确很是繁琐,所以针对此就创建了连接池。

druid连接池的一个链接测试,之前忘写了,现在补上。
package druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
/**
* Druid数据库链接演示
*/
public class DruidDemo {
public static void main(String[] args) throws Exception {
//1.导入jar包
//2.定义配置文件
//3.加载配置文件
Properties prop = new Properties();
prop.load(new FileInputStream("jdbc-demo/src/druid.properties"));
//4.获取连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
//获取数据库链接
Connection connection = dataSource.getConnection();
System.out.println(connection);
// System.out.println(System.getProperty("user.dir"));
}
}
接下来是对连接池的一个案例测试,
1.先是在数据库中,创建所需要的数据库表
-- 删除tb_brand表
drop table if exists tb_brand;
-- 创建tb_brand表
create table tb_brand
(
-- id 主键
id int primary key auto_increment,
-- 品牌名称
brand_name varchar(20),
-- 企业名称
company_name varchar(20),
-- 排序字段
ordered int,
-- 描述信息
description varchar(100),
-- 状态:0:禁用 1:启用
status int
);
-- 添加数据
insert into tb_brand (brand_name, company_name, ordered, description, status)
values ('三只松鼠', '三只松鼠股份有限公司', 5, '好吃不上火', 0),
('华为', '华为技术有限公司', 100, '华为致力于把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界', 1),
('小米', '小米科技有限公司', 50, 'are you ok', 1);
SELECT * FROM tb_brand;以上是所需要的sql语句,通过此创建的数据表如下

然后是针对表的性质,创建一个新的类Brand,对其封装,并对成员进行setter和getter
这里对这个还不是很熟悉,所以提供具体的代码
package com.itheima.jdbc.com.itheima.pojo;
/**
* 品牌
*/
public class Brand {
// id 主键
private Integer id;
// 品牌名称
private String brandName;
// 企业名称
private String companyName;
// 排序字段
private Integer ordered;
// 描述信息
private String description;
// 状态:0:禁用 1:启用
private Integer status;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getBrandName() {
return brandName;
}
public void setBrandName(String brandName) {
this.brandName = brandName;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public Integer getOrdered() {
return ordered;
}
public void setOrdered(Integer ordered) {
this.ordered = ordered;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public Integer getStatus() {
return status;
}
public void setStatus(Integer status) {
this.status = status;
}
@Override
public String toString() {
return "Brand{" +
"id=" + id +
", brandName='" + brandName + '\'' +
", companyName='" + companyName + '\'' +
", ordered=" + ordered +
", description='" + description + '\'' +
", status=" + status +
'}';
}
}
接下来是查询数据

下面是对其案例测试的代码
package example;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import com.itheima.jdbc.com.itheima.pojo.Brand;
import org.junit.Test;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* 品牌数据的增删改查
*/
public class BrandTest {
/**
* 查询所有
* 1.SQL:select * from tb_brand;
* 2.参数:不需要
* 3. 结果:List
*/
@Test //测试用例
public void testSelectALl() throws Exception {
//1.获取链接
//加载配置文件
Properties prop = new Properties();
prop.load(new FileInputStream("src/druid.properties"));
//获取连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
//获取数据库链接
Connection conn = dataSource.getConnection();
//2.定义SQL
String sql ="select * from tb_brand;";
//3.获取pstmt对象
PreparedStatement pstmt = conn.prepareStatement(sql);
//4.设置参数【但是此处不需要设置参数】
//5.执行SQL
ResultSet rs = pstmt.executeQuery();
//6.处理结果List封装Brand对象,装载list集合
Brand brand = null;
List brands = new ArrayList<>();
while(rs.next()){
//获取数据
int id = rs.getInt("id");
String brandName = rs.getString("brand_name");
String companyName = rs.getString("company_name");
int ordered = rs.getInt("ordered");
String description = rs.getString("description");
int status = rs.getInt("status");
//封装Brand对象
brand = new Brand();
brand.setId(id);
brand.setBrandName(brandName);
brand.setCompanyName(companyName);
brand.setOrdered(ordered);
brand.setDescription(description);
brand.setStatus(status);
//装载集合
brands.add(brand);
}
System.out.println(brands);
//7.释放资源
rs.close();
pstmt.close();
conn.close();
}
}
先是进行一个链接,这里直接用到是druid的链接,我觉得可能用最开始的url,username,password也是可以进行一个链接的。但是这个毕竟要方便很多,功能也确实强大些。然后后面的一些步骤都是可以对其进行写入。
但是最后我第一次运行时,它的properties文件的路径是不对的,所以我也困惑也一下,然后看到一篇博文,具体什么也不记得了,我想起他之前说的也可也通过一个语句直接定位properties文件位置,然后我尝试了,成功了,哈哈哈。很开心。。。
System.out.println(System.getProperty("user.dir"));【这就是该语句】