【计算机视觉】A Simple Framework for Open-Vocabulary Segmentation and Detection论文解读

上排:OpenSeeD对开放词汇的实例分割和检测、全景和语义分割、野外实例分割和给定参考框位置和概念的条件分割的可视化。
下一行:我们的OpenSeeD模型在零射击和特定任务传输设置的八个基准测试中优于以前最先进的方法(每个灰条下面列出)。
文章目录
- 一、导读
- 二、介绍
- 三、Related Work
-
- 3.1 Generic Segmentation and Detection
- 3.2 Open-Vocabulary Segmentation
- 3.3 Open-Vocabulary Detection
- 3.4 Weakly-Supervised Segmentation
- 3.5 Learning from Box and Mask
- 四、方法
-
- 4.1 基本损失公式
- 4.2 Bridge Task Gap: Decoupled Foreground and Background Decoding
-
- 4.2.1 语言引导的前景查询选择
- 4.2.2 Learnable background queries
- 4.3 Bridge Data Gap: Conditioned Mask Decoding
- 五、实验
- 六、总结
一、导读
我们提出了OpenSeeD,一个简单的开放词汇分割和检测框架,它可以从不同的分割和检测数据集中共同学习。为了弥补词汇量和标注粒度的差距,我们首先引入一个预训练的文本编码器,对两个任务中的所有视觉概念进行编码,并为它们学习一个共同的语义空间。与只在分割任务上训练的对手相比,这给了我们相当好的结果。为了进一步协调它们,我们找到了两个差异:1)任务差异——分割需要同时提取前景对象和背景对象的掩码,而检测只关心前者;Ii)数据差异框和掩码注释具有不同的空间粒度,因此不能直接互换。为了解决这些问题,我们提出了一种解耦解码来减少前景/背景之间的干扰,并提出了一种条件掩码解码来帮助生成给定盒子的掩码。
为此目的,我们开发了一个包含所有三种技术的简单编码器-解码器模型,并在COCO和Objects365上对其进行联合训练。经过预训练,我们的模型在分割和检测方面都表现出竞争性或更强的 zero shot 可转移性。具体来说,OpenSeeD在开放词汇实例和跨5个数据集的全视分割方面击败了最先进的方法,并且在类似设置下优于LVIS和ODinW上的开放词汇检测。当转移到特定任务时,我们的模型实现了新的SoTA,用于COCO和ADE20K的全景分割,以及ADE20K和cityscape的实例分割。图1中的下一行显示了OpenSeeD和以前的SoTA方法的性能比较。最后,我们注意到OpenSeeD是第一个探索分割和检测联合训练潜力的,并希望它可以作为在开放世界中为这两个任务开发单个模型的强大基线。
二、介绍
开发可转移到新概念或新领域的视觉系统已成为一个重要的研究课题。鉴于开创性工作CLIP中展示的强 zero shot 可转移性,许多研究人员试图通过利用大规模图像-文本对来构建高级开放词汇表模型,用于细粒度视觉任务,如检测和分割。
可以说,检测和分割等核心视觉任务在词汇量和监督的空间粒度上是相当不同的,如图2 (a)所示。例如,常用的公共检测数据集Objects365在大约1.7M的图像中包含365个概念的框注释,而COCO中的掩码注释在0.1M的图像中仅涵盖133个类别。
以前的工作已经探索了利用大量图像文本数据进行开放词汇检测或分割的不同方法,例如从多模态基础模型中提取视觉语义表示,设计细粒度或增强对比学习方法或利用伪标记技术。
据我们所知,大多数(如果不是全部的话)都集中在如何提高检测或分割的性能上。
此外,将弱图像级监督转移到细粒度任务通常需要复杂的设计来缓解巨大的粒度差距,并且容易受到图像-文本对中的噪声的影响。
这就引出了一个很自然的问题:我们能否将检测和分割连接起来,使两者之间的差距更小,从而获得一个良好的开放词汇表模型?
退一步说,将检测和分割结合起来的方法以前主要有两种。一方面,Mask R-CNN 是最早提出在COCO上联合学习检测和实例分割的作品之一。另一方面,研究表明,在Objects365上预训练的检测模型可以可行地转移到COCO全景分割中。然而,如图2 (b)所示,前一种方法需要在包含对齐框和掩码注释的同一数据集上训练模型,而后一种方法遵循预训练-然后微调协议,导致两个独立的闭集模型。
在这项工作中,我们首次提出了从检测和分割数据中共同学习,更重要的是为这两个任务提供了一个开放词汇表模型(图2 (b)底部)。实现这一目标需要回答两个关键问题:i)如何在检测和分割数据之间传递语义知识;二是如何弥合 box 监督与 mask 监督 之间的差距。
首先,两个任务之间的词汇有共同之处,但也有很大的差异。我们需要适应这两种词汇表,并进一步走向开放词汇表。其次,语义和全景分割任务不仅需要分割前景对象(如“狗”和“猫”),还需要分割背景概念(如“天空”和“建筑”),而检测任务只关心前景对象。第三, box 监督 本质上比 mask 监督粗糙。我们可以把 mask 变成 box,但反过来却很难。
最后,我们提出了OpenSeeD,这是一个简单的编码器-解码器框架,通过减轻上述问题来调和这两个任务。
具体来说,我们首先利用单个文本编码器对数据中出现的所有概念进行编码,并训练我们的模型将视觉标记与公共空间中的语义对齐。
其次,我们明确地将解码器中的 object queries 分为两个子类型:前景和背景 queries,其中第一组负责来自分割和检测的前景对象,而第二组仅负责分割中的背景对象。
第三,引入条件掩码解码,从分割数据的真值盒中学习解码掩码,并生成检测数据的掩码助手。因此,我们的OpenSeeD能够无缝地从单独的检测和分割数据中学习,并在各种任务/数据集中实现出色或具有竞争力的零射击和传输性能。图1显示了我们的模型在实例、全景和语义分割任务上的可视化。它还展示了在与我们的训练数据(如SeginW数据集)有很大差异的数据集上的分割结果,并展示了OpenSeeD的条件分割能力。鉴于这些令人鼓舞的结果,我们希望我们的工作可以作为为这两个任务开发单一开放词汇表模型的第一个强有力的基线。
总而言之,我们的主要贡献是:
- 我们是第一个提出一个强大的基线模型,它可以从检测和分割数据中共同学习,并为这两个任务建立一个开放词汇表模型。
- 我们定位了两个任务/数据集的差异,并提出了单独的技术,包括共享语义空间、解耦解码和条件掩码辅助来缓解问题。
- 通过在分割和检测数据上联合训练我们的模型,我们在各种数据集上实现了最先进的零射击和任务转移的分割性能,以及零射击目标检测的竞争性能。

(a)不同视觉任务/数据集的语义词汇量和空间粒度比较。“ITP”是指图像-文本对;“OD”表示目标检测,“SG”表示分割。我们的OpenSeeD是第一个在分割和检测(灰色区域)上共同学习的开放词汇模型。(b)不同类型的方法将目标检测和分割联系起来。
三、Related Work
3.1 Generic Segmentation and Detection
检测和分割一直是视觉界长期存在的问题。这两项任务都需要理解视觉概念是什么,在哪里,但具有不同的空间粒度。通用分割主要包括实例分割、语义分割和泛视分割,针对不同的语义。近年来,基于Transformer的Detection Transformer (DETR)在许多检测和分割模型上取得了重大进展。然而,所有这些方法都受限于有限的词汇表大小。
3.2 Open-Vocabulary Segmentation
许多开放词汇分割模型利用大型预训练的视觉语言模型(例如CLIP或ALIGN)来提取或转移视觉语义知识。
除了使用基础模型外,DenseCLIP和GroupViT表明,从基础模型进行微调或从头开始训练也可以产生优越的零射击性能。最近,X-Decoder提出将所有类型的分词任务和几种视觉语言任务统一起来进行开放词汇分词。在ODISE中,作者研究了一种使用文本到图像扩散模型作为开放词汇分词主干的新方法。与之前的工作不同,我们的模型探索将分割和检测连接起来,这两种方法的数据更清晰,彼此之间的差距更小。
3.3 Open-Vocabulary Detection
类似地,一些开放词汇表检测模型直接利用基础模型进行蒸馏或转移,如OV -DETR和VILD。最近,GLIP将检测作为一个特殊的接地问题来表述,以统一检测和短语接地任务。这些接地数据有助于改善短语和区域之间的对齐,以进行开放检测。
RegionCLIP和DetCLIP从图像-文本对生成伪框标签,用于更广泛的检测。
3.4 Weakly-Supervised Segmentation
弱监督分割通常只使用方框注释作为监督来生成分割。突出的方法是设计教师模型或弱监督损失,如BoxInst、Box2Mask、DiscoBox和Mask autoabelers。这些模型都是闭集的,通常不如有分割监督的模型。
相比之下,我们尝试从开放词汇表模型的分割和检测中尽可能多地利用监督。
3.5 Learning from Box and Mask
主要有两种方法来学习box和mask。第一种是在单个数据集上同时使用框和掩码注释进行训练。突出的方法有Mask R-CNN和HTC。然而,它们仅限于前景实例。第二种方法是只进行box监督预训练,然后再进行分割。例如,HTC和Mask DINO都可以从大规模的检测数据中学习,然后对特定的分割数据集进行微调。然而,这种预训练和微调协议导致两个单独的模型,它们只能检测或分割。此外,这两种模型都是闭集的,因此不能转移到新的概念中。
四、方法
给定分割和检测数据集,OpenSeeD旨在为这两项任务学习开放词汇表模型。
形式上,设 D m = { I i , ( c i , m i ) } i = 1 M D_m = \{I_i,(c_i, m_i)\}_{i=1}^M Dm={Ii,(ci,mi)}i=1M 表示大小为 M 的分割数据集, D b = { I j , ( c j , b j ) } j = 1 N D_b = \{I_j, (c_j, b_j)\}_{j=1}^N Db={Ij,(cj,bj)}j=1N 表示大小为 N 的检测数据集,其中 c 为图像中的视觉概念,m 和 b 分别为对应的mask和框。假设 V = { c 1 , ⋯ , c K } V = \{c_1, \cdots, c_K\} V={c1,⋯,cK} 是 D m D_m Dm 和 D b D_b Db 中出现的 K K K 个独特视觉概念的词汇表。OpenSeeD的目标是学习检测和分割 V V V 及以上的视觉概念。
为了实现这一目标,我们利用了一种通用的编解码器设计,并为OpenSeeD使用了一个文本编码器,如图3所示。我们的模型将图像和词汇 V V V 作为输入,并输出一组预测,包括掩码 P m P_m Pm、框 P b P_b Pb 和分类分数 P c P_c Pc。
更具体地说,我们的模型由一个图像编码器,一个文本编码器和一个解码器组成。给定图像 I I I 和词汇 V V V,我们首先分别用图像编码器和文本编码器对它们进行编码。
之后,解码器以 L L L 查询为输入,交叉关注图像特征得到输出。
( p m , p b , p s ) = D e c ( Q ; O ) p c = S i m ( p s , T ) (p_m, p_b, p_s)=Dec(Q;O)\\ p_c=Sim(p_s, T) (pm,pb,ps)=Dec(Q;O)pc=Sim(ps,T)
其中 P s P_s Ps 是解码后的语义。通过计算 p p p 与 T T T 之间的相似度得分,从 S i m ( P s , T ) Sim(P_s, T) Sim(Ps,T) 中得到视觉语义匹配分数 P c P_c Pc,用于计算训练过程中的损失,并在推理过程中预测类别。
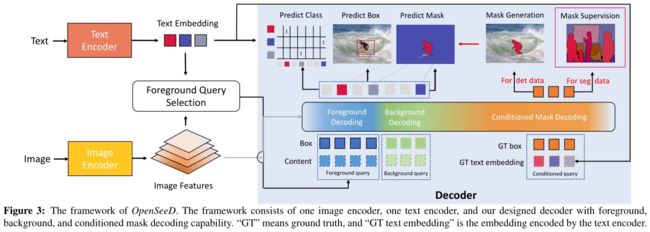
OpenSeeD的框架。该框架由一个图像编码器、一个文本编码器和我们设计的具有前景、背景和条件掩码解码能力的解码器组成。“GT”表示ground truth,“GT文本嵌入”是由文本编码器编码的嵌入。
4.1 基本损失公式
在这个基本公式中,我们试图通过促进共享的视觉语义空间来调和这两个任务,而不触及其他问题。对于多个任务和数据集,损失函数可以写成:

为了清楚起见,我们省略了每个损失项的权重。请注意,对于分割任务,我们可以从掩码m中得到准确的box b,并使用它们来计算项 L b ( P b , b ^ ) L_b(P_b, \hat{b}) Lb(Pb,b^) 中的盒损失。通过对所有术语求和,我们的模型可以获得相当好的开放词汇表性能。此外,它可以使用检测和分割数据进行端到端的预训练,允许它使用一组权重执行开放词汇的分割和检测。
尽管建立了一个强有力的基线,但我们必须考虑两个任务之间的内在差异,如前所述。语义分割和全视分割需要同时识别前景和背景,而检测只关注前景目标的定位。因此,对两个任务使用相同的查询会产生冲突,从而显著降低性能。此外,良好的框预测通常表明良好的掩模,反之亦然。在检测和分割数据上分别训练盒和掩码头会阻碍两个数据集空间监督的协同。
为了解决上述差异,我们为OpenSeeD引入了一种新的解码器设计。我们将查询Q分为三种类型: L f L_f Lf 前台查询 Q f Q_f Qf, L b L_b Lb 后台查询 Q b Q_b Qb 和 L d L_d Ld 条件查询 Q d Q_d Qd,并针对每种类型提出特定于查询的计算方法。
4.2 Bridge Task Gap: Decoupled Foreground and Background Decoding
在不失一般性的前提下,我们将出现在实例分割和检测中的视觉概念定义为前景,而将全景分割中的材料类别定义为背景。为了减轻任务差异,我们分别使用前台查询 Q f Q_f Qf 和后台查询 Q b Q_b Qb 执行前台和后台解码。
具体来说,对于这两种查询类型,我们的解码器预测两组输出: ( P f m , P f b , P f c ) (P_f^m, P_f^b, P_f^c) (Pfm,Pfb,Pfc) 和 ( P b f , P b b , P b c ) (P_b^f, P_b^b, P_b^c) (Pbf,Pbb,Pbc)。我们还将分割数据集中的ground truth分为 ( c f , m f ) (c_f, m_f) (cf,mf)和 ( c b , m b ) (c_b, m_b) (cb,mb)两组,然后对这两组分别进行两次独立的Hungarian Matching处理,如图4 (a)所示。因此,分割时同时使用前景和背景解码,检测时只使用前景解码。

a)不同查询的标签分配。“灰色”是指未用于检测数据的无背景材料。最好以彩色观看。b) OpenSeeD中不同查询(前台、后台、条件查询)的查询交互。所有数据都有后台查询,包括检测数据。“暗”色意味着阻碍互动。

其中, b f ^ \hat{b_f} bf^ 和 b b ^ \hat{b_b} bb^ 分别由 m f m_f mf 和 m b m_b mb 推导而来。
基于这种显式解耦,我们的模型最大限度地提高了检测和分割数据集的前景监督合作,显著减少了前景和背景类别之间的干扰。虽然解耦,但我们注意到这两种类型的查询共享相同的解码器,并通过自关注相互交互,如图4 (b)所示。下面我们将解释如何确定前景和背景查询。
4.2.1 语言引导的前景查询选择
开放词汇表设置与传统的闭集设置的不同之处在于,模型需要定位远远超出训练词汇表的大量前景对象。然而,事实是我们的解码器包含有限数量的前景查询(通常是几百个),这使得它很难处理图像中所有可能的概念。为了解决这个问题,我们提出了一种称为语言引导的前景查询选择的方法,可以根据给定的文本概念自适应地选择查询,如图3左部分所示。给定图像特征O和文本特征T,我们使用轻量级模块来预测每个特征的框和得分。
E b = H e a d ( O ) E c = S i m ( O , T ) E^b=Head(O)\\ E^c=Sim(O, T) Eb=Head(O)Ec=Sim(O,T)
其中Head为 box 头。然后根据 E c E^c Ec 的分数从 E b E^b Eb 和 O O O 中选出排名靠前的 L f L_f Lf 个条目。
然后将选定的 L f L_f Lf 图像特征和框作为前景查询(图3中的蓝色方块)馈送给解码器。通过仅选择与文本相关的令牌作为解码器查询,我们减轻了解码无关语义的问题,并提供了更好的查询初始化。这种提出前景查询的自适应方式使我们的模型能够在测试场景中有效地转换到新的词汇表。
4.2.2 Learnable background queries
与前台查询不同,我们在背景查询中使用可学习的查询嵌入有两个原因。首先,查询选择不能很好地工作,因为选择的参考点经常超出大的和非凸的背景区域,导致次优结果。其次,背景素材的分类数量相对较少,而且一张图片通常包含一些不同的素材(例如,“天空”,“建筑”)。因此,在我们的模型中使用可学习查询可以充分有效地处理背景材料类别,并很好地推广到开放词汇表设置。背景查询在图3中用绿色方块标记。
4.3 Bridge Data Gap: Conditioned Mask Decoding
我们的最终目标是通过使用单个损失函数来训练多个任务来弥合数据差距,从而得到以下损失函数:
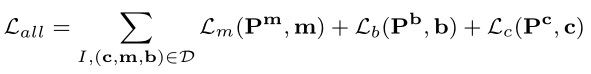
其中,D表示分割和检测数据集的并集。然后,损失函数需要检测数据的mask注释和分割数据的box注释,导致两个任务在空间监督的粒度上存在差异。
正如我们前面所讨论的,我们可以很容易地将对象掩码转换为框,然而,对于检测数据,我们只给出了粗略的位置(框)和类别。那么一个有趣的问题就来了——我们能得到它的掩码吗?
为了解决这个问题,我们利用包含从label&box到mask的丰富映射的分割数据,即(c, b)→m,并提出条件掩码解码来学习映射,如图3最右侧所示。
给定真值概念和框 ( c , b ) (c, b) (c,b),我们使用解码器对掩码进行解码:
P m = D e c ( ( t , b ) ; O ) P_m = Dec ((t, b); O) Pm=Dec((t,b);O)
其中 t t t 为概念提取的文本特征。根据上式,问题就变成了,我们能否从分割数据中学习到一种很好的映射,这种映射可以很好地推广到不同类别的检测数据中?
五、实验
在我们的实验中,我们对两种类型的数据进行了联合预训练,包括全景分割和目标检测。对于全景分割,我们使用带有分割注释的COCO2017(大约110k张图像)。对于目标检测,我们使用Objects365(v1为660k图像,v2为1700k图像)。
我们使用Objects365v1来训练和消融我们的小模型,而Objects365v2只用于训练我们的大模型。我们在预训练涵盖的所有任务上评估我们的模型,包括语义、实例、全视分割和目标检测。特别是,我们对60多个数据集进行了基准测试,这些数据集涵盖了广泛的零采样分割和检测领域。
一种基于零采样方法的多数据集开放词汇分词权。我们的模型是在COCO和Objects365数据上预训练的。“SEG”表示分割数据(COCO),“DET”表示检测数据(Objects365),“ITP”表示图像-文本对/引用/字幕数据。灰色的值是监督结果。X-Decoder (L)不是开源的,所以我们无法评估它在LVIS上的性能。

我们涵盖了六种常用的分割数据集,包括室内场景(ADE20K)、室外场景(Cityscapes)和驾驶场景(BDD100K)。此外,我们还对lvis的分割和检测性能进行了评估。
我们首先比较了之前在分割任务上的工作。总的来说,我们的模型在实例分割上取得了更好的性能,在全景分割和语义分割上取得了相当的性能。与最先进的方法 ODISE 和 XDecoder 相比,OpenSeeD 在 ADE20K 上分别实现了1.1 和 1.9 个掩码 AP 改进。这个差距在cityscape 和 LVIS 上更大。我们的 OpenSeeD 在 cityscape 上的小模型和大模型的掩模 AP 分别比 X-Decoder 高出10.2 和 8.3。在 LVIS 上,我们用发布的 X-Decoder 微小模型对掩码 AP 进行了评估,与我们的 OpenSeeD 微小模型相比,掩码 AP 提高了 9.8。结果表明,联合学习方法可以有效地转移检测数据中的实例级知识进行实例分割。与实例分割相比,泛视分割和语义分割都需要分割背景内容,而背景内容在检测数据中是完全不存在的。尽管如此,我们的OpenSeeD在4个数据集中的3个(除了ADE20K)上仍然优于X-Decoder,并且实现了相当的语义分割性能。三个任务的结果表明,检测数据显著有利于实例级理解,而图像-文本对主要增强语义分割的语义理解。除了分割之外,OpenSeeD还产生了相当好的检测性能。与GLIP相比,我们的OpenSeeD (T)在lvis (21.8 vs . 18.5)上的零射击检测方面优于GLIP (T)(设置A),其中两者仅使用Objects365作为预训练检测数据集。最后,我们强调了我们的模型是第一个可以同时使用分割和检测数据进行预训练并对这两个任务进行零射击转移的模型。
六、总结
我们提出了一个简单的开放词汇分词和检测框架OpenSeeD,该框架使用单一模型从不同的分词和检测数据集中共同学习。为了弥合前景对象和背景对象之间的任务差距,我们提出了一种语言引导的前景查询选择解耦解码方法。我们还共同训练了一个条件掩码解码任务,该任务在推理过程中提供了一个交互式分割接口,并有助于在训练过程中弥合检测数据的数据鸿沟。结果表明,我们的统一模型在保持合理检测性能的同时,显著改善了开放分割。联合预训练的模型也可以无缝转移,以提高密切词汇的表现。
在这项工作中,我们的目标是探索训练一个开放词汇模型的潜力,用于分割和检测。OpenSeeD不使用参考/基础数据或大规模图像-文本对来进一步丰富我们的训练数据和语义覆盖。我们把更大的联合训练留给未来的工作。