哈夫曼编码译码
题目
编写一个哈夫曼编码译码程序。
按词频从小到大的顺序给出各个字符(不超过30个)的词频,根据词频构造哈夫曼树,给出每个字符的哈夫曼编码,并对给出的语句进行译码。
为确保构建的哈夫曼树唯一,本题做如下限定:
(1)选择根结点权值最小的两棵二叉树时,选取权值较小者作为左子树。
(2)若多棵二叉树根结点权值相等,按先后次序分左右,先出现的作为左子树,后出现的作为右子树。
生成哈夫曼编码时,哈夫曼树左分支标记为0,右分支标记为1。
【输入格式】
第一行输入字符个数n;
第二行到第n行输入相应的字符及其权值;
最后一行输入需进行译码的串
【输出格式】
首先按树的先序顺序输出所有字符的编码,每个编码占一行;
最后一行输出需译码的原文,加上original:字样。
输出中均无空格
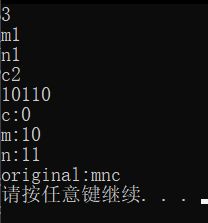
【样例输入】
3
m1
n1
c2
10110
【样例输出】
c:0
m:10
n:11
original:mnc
题意:就是构建一颗哈夫曼树,根据该树确定每个字符的编码,根据编码解码
注意:
-
权值不等,左小右大
-
权值相等,先出现的为左。
-
左为0,右为1
如何实现
哈夫曼树(最优二叉树),使用树的数据结构来存储比较贴切,使用其他的数据结构也行,办法不止一种。
解题步骤:
- 创建哈夫曼树
- 根生成的树,前序遍历输出每个字符的哈夫曼编码。
- 根据哈夫曼编码解码
1.创建哈夫曼树
用一个结构体将输入的数据存放起来,哈夫曼树是最优二叉树,所以只需要定义两个孩子结点
树的节点,可以定义为
struct ThreeNode{
double data; //词频,因为题意说可以是小数。所以使用double
char ch;//字符
ThreeNode *left;//左孩子
ThreeNode *right;//右孩子
};
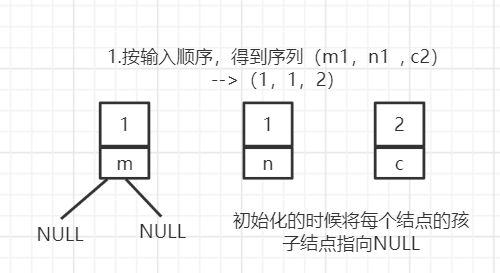
创建过程如下:

一个细节:
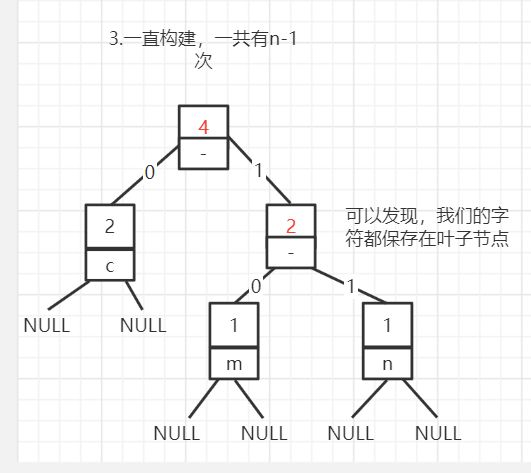
因为需要每次都拿最小的两个值进行合并,并且生成一个新的节点。也就是说每次会减少一个需要构建的节点。那就是需要构建n-1次,直到最后剩下一个结点,无需合并,它就是根节点。使用长度为2n-1的结构体数组来保存每一个结点。
TreeNode v[2*n-1];
当构建完后它的结构应该是这样的,生成的结点用红色标志

需要一个排序规则,方便我们进行对这个结构体数组排序。
这里使用升序排序,这样我们从左往右遍历的时候,能满足数是最小的和最先出现的两个条件
bool cmp(ThreeNode a, ThreeNode b)
{
return a.data < b.data; //根据权值升序排序
}
因为我们不断合成结点,每次合并之前需要对其排序,此时我们已经完成结构体是按照升序排序的功能了。只需要将没有合成过的结点的第1个和第2个拿出来,那他们就是最小的了。直接合成然后放进最后即可。这里使用两个索引记录我们合成到哪个位置,生成的结点该插入哪个位置即可。
TreeNode* createTree(TreeNode *v,int n){
int i=0,index=n-1; //i为0 ,从位置0开始合成。index是生成的结点该放的地方
while(i<2*n-1) //当i走到最后一个结点,无需再构建,也可以使用index控制
{
//1.先排序
sort(v+i,v+index,cmp); //只对范围内的排序。随两个索引变化,排序的范围也变化
//2.合并:拿出排好序序列中的前两个结点。
TreeNode* node1 = &v[i++];//TreeNode* node1 = &v[i];i++;
TreeNode* node2 = &v[i++];
//3.生成新节点,给结点赋值
TreeNode newNode=v[index];
newNode.data=node1->data+node2->data; //权值相加
newNode.ch='-';//随意设置,表示其为中间结点。
newNode.left=node1;//设置左右孩子
newNode.right=node2;
//4.新节点放入到序列中
v[++index]=newNode;
}
return &v[index-1]; //最后一个为根节点
}
2.获取每个字符的编码
我们已经拿到了哈夫曼树,且我们之前设置了新生成的结点的符号是-,使用先序遍历到结点的字符不是-的时候,就输出编码就ok。
同时,我们的到了编码,也可以将每个字符的编码使用map记录下来,方便下一步查询。
编码使用一个整型数组存储,location记录路径(索引),如果是左孩子,就将设置为0。
/**
* 先序顺序输出所有字符的编码
*/
void printCode(TreeNode *root,char code[],int location){
if (root == NULL) {
return;
}
if(root->ch!='-')//说明已经遍历到叶子节点,输出序列
{
printf("%c:",root->ch);
string key="";//准备字符串拼接,也就是map的key
for(int i=0;i<location;i++){//输出记录的长度。
printf("%d",code[i]);
key+=to_string(code[i]);//to_string()将参数转为string类型
}
printf("\n");
//cout<<"key:"<ch<
m.insert(make_pair(key, root->ch));//将值以键值对的形式插入到map中,下一步使用
}
//该节点是左孩子,路径设0
code[location]=0;
location++;//下一个位置给下一个节点用
printCode(root->left,code,location); //递归该节点。
location--;//该节点递归完成。取消该节点的记录。
//右孩子,1
code[location]=1;
location++;
printCode(root->right,code,location);
location--;
}
3.根据哈夫曼编码解码
我们使用了map记录每个字符的编码。
根据给的译码原文。去匹配map即可
for(i=0;i<len;i++)
{
str+=decoding[i];//拼接key
if(m.find(str)!=m.end()){//找到了key,输出
printf("%c",m[str]);
str="";//清空key,重新拼接
}
else
{
//找不到key,什么也不用做,继续拼接,这个可以去掉
}
}
4.完整代码
可以将一些注释打开,能输出一些信息,帮助你理解和调试该程序。
#include
f_decode(decoding,len);
return 0;
}
/**
* 创建树
*/
TreeNode* createTree(TreeNode *v,int n){
int i=0,index=n; //i为0 ,从位置0开始合成。index是生成的结点该放的地方
while(i<2*n-1) //当i走到最后一个结点,无需再构建,也可以使用index控制
{
//1.先排序
sort(v+i,v+index,cmp); //只对范围内的排序。随两个索引变化,排序的范围也变化
//2.合并:拿出排好序序列中的前两个结点。
TreeNode* node1 = &v[i++];//TreeNode* node1 = &v[i];i++;
TreeNode* node2 = &v[i++];
//3.生成新节点,给结点赋值
TreeNode newNode;
newNode.data=node1->data+node2->data; //权值相加
newNode.ch='-';//随意设置,表示其为中间结点。
newNode.left=node1;//设置左右孩子
newNode.right=node2;
//4.新节点放入到序列中
v[index++]=newNode;
}
return &v[2*n-2]; //最后一个为根节点
}
/**
* 排序规则
*/
bool cmp(TreeNode a, TreeNode b)
{
return a.data < b.data; //根据权值升序排序
}
/**
*解码 ,码——>原文
*/
void f_decode(string decoding,int len)
{
string str;
int i=0;
printf("original:");
for(i=0;i<len;i++)
{
str+=decoding[i];//拼接key
if(m.find(str)!=m.end()){//找到了key,输出
printf("%c",m[str]);
str="";//清空key,重新拼接
}
else
{
//找不到key,什么也不用做,继续拼接,这个可以去掉
}
}
}
/**
* 先序顺序输出所有字符的编码
*/
void printCode(TreeNode *root,char code[],int location){
if (root == NULL) {
return;
}
if(root->ch!='-')//说明已经遍历到叶子节点,输出序列
{
printf("%c:",root->ch);
string key="";
for(int i=0;i<location;i++){//输出记录的长度。
printf("%d",code[i]);
key+=to_string(code[i]);//to_string()将参数转为string类型
}
printf("\n");
//cout<<"key:"<ch<
m.insert(make_pair(key, root->ch));//将值以键值对的形式插入到map中
}
//该节点是左孩子,路径设0
code[location]=0;
location++;//下一个位置给下一个节点用
printCode(root->left,code,location); //递归该节点。
location--;//该节点递归完成。取消该节点的记录。
//右孩子,1
code[location]=1;
location++;
printCode(root->right,code,location);
location--;
}