python爬虫入门
基础回顾
使用函数, 先导入, 直接点方法名使用
import math
m = math.log10(100)
print(m)
python 交互模式
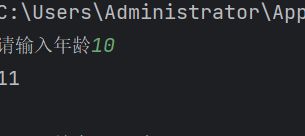
input输入示例
age = int(input("请输入年龄"))
age += 1
print(age)
if else 的使用
和java一样, 只是不加括号, else if 阉割成了 elif
与或非
java : && || !
python : and or not
列表
list = [1, "玩具"]
list.append("狗子")
print(list)
print(list[1])
字典
contact = {"小明": 17, "小耿": 20, "小强": 50}
print(contact["小明"])
print(contact)
for 循环遍历
contact = {"小明": 17, "小耿": 20, "小强": 50}
for name, age in contact.items():
print(name)
print(age)
小明
17
小耿
20
小强
50
f String 表达式
name = "123"
print(f"{name}")
定义函数
def fun(name):
print(name)
fun(123)
对象赋予属性
class Cat:
def __init__(self, name, age, color):
self.name = name
self.age = age
self.color = color
def speak(self):
print("喵" * self.age)
cat1 = Cat("Jojo", 3, "橙色")
print(f"小猫{cat1.name}{cat1.age}岁了颜色是{cat1.color}")
cat1.speak()
继承
class Mammal:
def __init__(self, name, sex):
self.name = name
self.sex = sex
self.num_eyes = 2
def breathe(self):
print(self.name + "在呼吸...")
def poop(self):
print(self.name + "上厕所...")
class Human(Mammal):
def __init__(self, name, sex):
super().__init__(name, sex)
self.has_tail = False
def read(self):
print(self.name + "在阅读...")
class Cat(Mammal):
def __int__(self, name, sex):
super().__init__(name, sex)
self.has_tail = True
def scratch_sofa(self):
print(self.name + "在抓沙发")
cat1 = Cat("jojo", "男")
print(cat1.name)
cat1.poop()
爬虫入门
基础知识
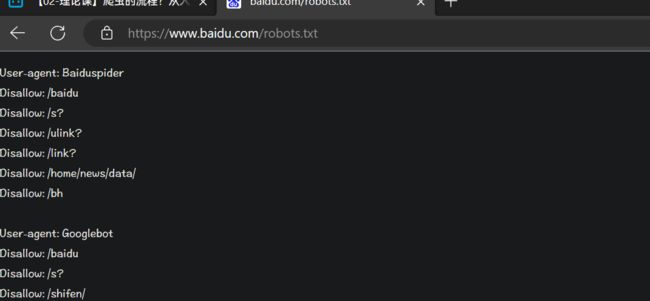
查看网页可爬取文档 …/robots.txt
HTTP响应

text/html; charset=utf-8 响应类型是HTML , 编码是UTF-8
application/json; charset=utf-8 响应类型是JSON, 编码是UTF-8
+++
安装 requests 系统
pip install requests
conda install requests
pip python 包管理工具
https://pip.pypa.io/en/stable/instatlation/
也可以使用 anaconda
+++
requests 库使用
import requests
response = requests.get("http://books.toscrape.com/")
print(response)
一行代码就可以爬到数据了, 打印结果是该网站的html代码
添加 headers
添加headers头的目的是把python编辑器伪装成浏览器, 这里爬取豆瓣网的电影top250
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43"
}
content = requests.get("https://movie.douban.com/top250", headers=headers)
print(content.text)
BeautifulSoup 库
Beautiful Soup是一个Python包,用于解析HTML和XML文档(包括具有格式错误的标记,即非封闭标签,因此以标签汤命名)。它为解析的页面创建了一个解析树,可用于从HTML中提取数据,[3]这对于网页抓取很有用
from bs4 import BeautifulSoup
import requests
# 抓取到内容
content = requests.get("http://books.toscrape.com/").text
# 将HTML内容解析成一个BeautifulSoup对象
soup = BeautifulSoup(content, "html.parser")
# 获得a标签 ..., 此时是一个列表
title = soup.findAll("a", attrs={"title": "It's Only the Himalayas"})
# 通过遍历列表获得a标签内的内容
for t in title:
print(t.text)
params 参数
params = {id: 1}
res = requests.get('https://www.runoob.com/', params=params)
等价于
requests.get('https://www.runoob.com?id=1')
解决乱码问题
答案来自 chatgpt
import requests
url = "http://www.rizhao.gov.cn/"
# 发起HTTP GET请求并获取HTML内容
response = requests.get(url)
response.encoding = response.apparent_encoding
# 解码HTML内容
content = response.text
content.encode().decode('utf-8')
print(content)
抓取分页豆瓣top250
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43"
}
for start_number in range(0, 250, 25):
content = requests.get(f"https://movie.douban.com/top250?start={start_number}", headers=headers).text
soup = BeautifulSoup(content, "html.parser")
titles = soup.findAll("span", attrs={"class", "title"})
for title in titles:
title_string = title.string
if '/' not in title_string:
print(title_string)
headers).text
soup = BeautifulSoup(content, “html.parser”)
titles = soup.findAll(“span”, attrs={“class”, “title”})
for title in titles:
title_string = title.string
if ‘/’ not in title_string:
print(title_string)