HideSeeker论文阅读
文章目录
-
- 3.1 Overview of Our System HideSeeker
- 3.2 Visual Information Extraction
- 3.3 Relation Graph Learning
- 3.4 Hidden Object Inference
- 4 EVALUATIONS
-
- 4.7 Summary
- 6 DISCUSSIONS AND CONCLUSION


3.1 Overview of Our System HideSeeker
我们设计了一种名为“HideSeeker”的方案,用于发现包括但不限于这两种混淆技术所隐藏的隐私信息。给定一个部分受模糊技术保护的图像,如像素化、模糊化、涂鸦、贴纸覆盖和修复,我们的方法将定位混淆的隐私区域,并推断隐私区域内隐藏对象的类别。如图3所示,HideSeeker由三个模块组成:视觉信息提取、关系图学习和隐藏对象推理。
Visual Information Extraction:首先,我们期望提取隐藏对象的上下文信息。我们观察到,图像的视觉信息可以在语义上分为三类:模糊区域、可识别物体和场景。由于所有的混淆技术都无一例外地留下图像篡改的痕迹,我们从图像篡改检测和定位模型中获得支持,以定位混淆区域。我们将可识别的物体和场景定义为混淆区域的上下文。应用目标检测模型来提取区域特征并检测可识别物体。此外,我们使用整个图像的视觉特征作为场景的表示。
Relation Graph Learning:第二,我们构建一个图 G = ⟨ V , E ⟩ G =⟨V, E⟩ G=⟨V,E⟩,其中节点集 V V V 建模混淆区域及其上下文,边缘集 E E E 建模它们之间的语义和空间关系。对于我们关注的三种视觉信息,我们分别定义混淆区域节点、可识别对象节点和场景节点集。进一步,根据不同节点集之间的关系,我们定义了不同的边。
Hidden Objects Inference:最后,我们根据构建的图像关系图推断出一个对象类混淆的概率。我们应用图神经网络(graph neural networks),通过迭代地聚合来自其邻域的上下文信息来学习混淆区域节点的表示。节点表示的聚合和更新由门循环单元(Gate Recurrent Unit)[22]指导。此外,我们将注意力机制聚合到图神经网络中,以学习混淆区域、可识别物体和场景之间的潜在关系。
3.2 Visual Information Extraction
在这个模块中,我们从模糊图像中获取所有可以观察到的视觉信息。至于需要的视觉信息,我们的灵感来自于人类对隐私保护图像的观察。当人们在社交平台上观看一个受模糊保护的图像时,由于视觉上的不一致或与其他区域的语义异常,人们的目光往往会集中在模糊区域上。如果想知道被保护的是什么,观看者会尝试观察图像中显示的混淆区域的上下文信息以及它们之间的关系,并利用先验知识推断出隐藏物体的类别。以图2(b)的第二幅图像为例,人们可以很容易地在第一眼就对模糊区域进行定位,即红框标记的区域。除此之外,我们还可以识别出桌子上的键盘和显示设备。我们可以推断,这张照片很可能是在办公室里拍的。尽管模糊了,但人们可以推断出,办公室办公桌上与隐私相关的模糊物体可能是一台笔记本电脑。
根据这种直觉,我们提出的方法首先找到模糊区域,并提取它们的区域视觉特征。隐藏物体的上下文信息被具体化为三种类型:混淆区域、可识别物体和场景。混淆技术修改或替换隐私相关物体的像素值。因此,我们很难依靠传统的目标检测模型来提取原始视觉特征进行分类。对于在混淆图像上进行分类任务来说,基于区域建议的方法,同在未混淆图像上相对比,通常表现不佳。然而,我们将混淆视为对原始图像的一种伪造手段。最近的研究根据视觉不一致(visual inconsistencies)[20,40]、局部异常(local anomalies)[41]、噪声模式(noise patterns)[55,58]等线索探索了图像篡改的检测和定位。我们期望在不同的混淆技术中应用一个具有极大泛化能力的图像篡改检测和定位模型。在 ManTra-Net[41]的帮助下,我们有了二进制掩码 M ∈ R H × W M∈\mathbb{R}^{H×W} M∈RH×W,其中 m i j ∈ M m_{ij}∈M mij∈M 定义为:
m i j = { 1 , the pixel at position ( i , j ) is predicted as obfuscated; 0 , otherwise. m_{i j}=\left\{\begin{array}{ll} 1, & \text { the pixel at position }(i, j) \text { is predicted as obfuscated; } \\ 0, & \text { otherwise. } \end{array}\right. mij={1,0, the pixel at position (i,j) is predicted as obfuscated; otherwise.
为了提取模糊区域的位置,利用像素间的距离对 m i j m_{ij} mij 进行聚类。同一混淆区域的掩码像素往往比其他区域的掩码像素距离更近。对于每个像素聚类,我们将可以包含聚类像素的最小边界框(the minimum bounding box)作为混淆区域的位置。混淆区域的位置被标记为 B p = { b 1 p , … , b N p p } B^{p}=\left\{b_{1}^{p}, \ldots, b_{N_{p}}^{p}\right\} Bp={b1p,…,bNpp},其中上标 p p p 是 “privacy-related”。此外,在Faster RCNN[30]中,根据边界框 b i p ∈ B p b_{i}^{p} \in B^{p} bip∈Bp,从感兴趣区域(ROI)池化层之后的全连接(FC)层提取区域视觉特征 f i p ∈ F p f_{i}^{p} \in F^{p} fip∈Fp。
除了隐藏在混淆区域中的隐私相关对象外,一些其他可识别的对象可能是用户分享图像或用户混淆区域的原因。由于剩下的视觉特征,我们可以很容易地用物体检测模型检测和识别这些物体。我们应用 Faster RCNN[30],一种现成的对象检测模型,用于可识别对象的检测和分类。对于对象 o i \mathbf{o}_{i} oi,我们提取视觉特征 f i o f_{i}^{o} fio,就像我们对混淆区域所做的那样。我们将对象检测器的分类和边界框回归结果(bounding box regression results)分别称为可识别对象的类别 l i o ∈ L o l_{i}^{o} \in L^{o} lio∈Lo 和位置 b i o ∈ B o b_{i}^{o} \in B^{o} bio∈Bo。
根据[36]的说法,图像的场景往往与某些隐私信息相关联。例如,在“街道”拍摄的图像中所涉及的隐私信息,很可能与“车”或“人”有关。因此,我们将场景作为与隐私相关物体的潜在指标。对于场景 s \mathbf{s} s,我们寻求学习图像的全局特征作为表示。我们通过 Places365 数据集[53]上预训练的 ResNet-50[17]的最后一个卷积层衍生的视觉特征来描述场景。Places365 数据集包含来自365个场景类别的近180万张图像。
3.3 Relation Graph Learning
对于每个图像,我们用从提取的视觉信息中学习到的关系图 G G G 来描述图像。这个模块旨在构建一个表示混淆区域与其上下文信息之间的语义和空间关系的图。我们将关系图表述为 G = ⟨ V , E ⟩ G =⟨V, E⟩ G=⟨V,E⟩,其中 V V V 中的节点表示来自视觉信息提取模块的视觉信息, E E E 中的边表示它们之间的多义词关系(polysemantic relationships)。关系图学习在算法1中描述。由于我们提取了包括混淆区域、可识别物体和场景的三种类型的语义,我们定义了分别对应于它们的节点集 V = { V p , V o , V s } V=\left\{V^{p}, V^{o}, V^{s}\right\} V={Vp,Vo,Vs}:
Recognizable object nodes V o V^{o} Vo:我们检测并分类与混淆区域同时出现的物体。通过目标检测器Faster RCNN,我们可以得到可识别目标的预测类别和位置。每个物体被定义为一个可识别的节点v∈v o。然后我们将类别标签、边界框以及区域视觉特征串联起来作为可识别对象节点的节点表示:xo = [f o∥lo∥bo]。
Obfuscated region nodes V p V^{p} Vp:每个节点V∈V p表示图像中的一个混淆区域。我们获得由边界框表示的区域的位置和从目标检测器派生的区域视觉特征,并将它们合并到节点中

Scene node V s V^{s} Vs: V s V^{s} Vs 只包含一个表示场景描述的节点V。场景节点v的节点表示由视觉信息提取模块的视觉特征和分类结果组成。我们将场景节点xs表示为拼接: x s = [ f s ∥ l s ∥ 0 ] \mathbf{x}^{s}=\left[f^{s}\left\|l^{s}\right\| \mathbf{0}\right] xs=[fs∥ls∥0],其中0为填充,以保持与其他节点相同的维度。
从节点 u u u 到节点 v v v 的每个有向边 e u → v e_{u \rightarrow v} eu→v 表示 u u u 对 v v v 的影响。在我们的图中,我们将混淆的区域节点和可识别的对象节点统称为区域节点(region nodes)。我们将区域之间的语义和空间关系计算为区域节点之间的边。然而,场景和区域之间的关系与区域之间的关系有很大的不同。毕竟,我们无法计算一张桌子和一个办公室之间的空间关系。因此,我们定义了三种类型的边:
Edges between the scene node and region nodes:场景和物体之间存在经验相关性。例如,在海滩上看到游泳圈或阳伞(parasols)的可能性比在厨房里看到的要大,而在街上出现微波炉的可能性很小。因此,我们计算双向 co-occurrence frequencies of objects and scenes,基于我们在实验室条件下生成的模糊图像。如图4所示,我们通过:
其中 P ( s , o ) P(\mathbf{s}, \mathbf{o}) P(s,o) 近似为物体 o \mathbf{o} o 和场景 s \mathbf{s} s 的共现频率, P ( s ) P(\mathbf{s}) P(s) 和 P ( o ) P(\mathbf{o}) P(o) 分别为物体 o \mathbf{o} o 和场景 s \mathbf{s} s 的出现频率,对于一个可识别的物体节点 u u u 和场景节点 v v v,它们的关系用共现概率来衡量。因此,我们将 u u u 到 v v v 的边的权重定义为:
e u → v = P ( v ∣ u ) (3) e_{u \rightarrow v}=P(v \mid u)\tag{3} eu→v=P(v∣u)(3)
Edges between region nodes:如果节点 u u u 和 v v v 都是区域节点,我们学习 u u u 和 v v v 之间的语义和空间关系,用于它们的边表示。同一类别的两个物体之间的联系比不同类别的物体之间的联系更紧密。我们通过计算视觉相似度(visual similarity)来衡量两个区域的语义关系,具体来说就是视觉特征 f u f_u fu 和 f v f_v fv 的余弦相似度: vis u v = f u f v ⊤ ∥ f u ∥ ⋅ ∥ f v ∥ \operatorname{vis}_{u v}=\frac{f_{u} f_{v}^{\top}}{\left\|f_{u}\right\| \cdot\left\|f_{v}\right\|} visuv=∥fu∥⋅∥fv∥fufv⊤。
至于空间关系 在节点 u u u 和 v v v 之间,我们考虑区域 u u u 和 v v v 的距离、面积重叠(area overlap)和角度,我们计算两个区域中心 ( [ x u , y u ] , [ x v , y v ] ) \left(\left[x_{u}, y_{u}\right],\left[x_{v}, y_{v}\right]\right) ([xu,yu],[xv,yv]) 之间的欧几里得距离(Euclid distance)作为它们之间的距离: dist u v = ∥ b u − b v ∥ 2 \operatorname{dist}_{u v}=\left\|b_{u}-b_{v}\right\|_{2} distuv=∥bu−bv∥2。两个区域提案的Union交集(IoU) iou u v \operatorname{iou}_{u v} iouuv(见图5(b)中的插图)是面积重叠的度量。我们计算角度 theta u v = arctan ( y u − y v x u − x v ) \operatorname{theta}_{u v}=\arctan \left(\frac{y_{u}-y_{v}}{x_{u}-x_{v}}\right) thetauv=arctan(xu−xvyu−yv)。结合区域节点之间的语义和空间关系,我们得到 u u u 到 v v v 边的表示为:
e u → v = W v v i s u v + W d dist u v + W i iou u v + W θ theta u v (4) e_{u \rightarrow v}=\mathbf{W}^{v} \mathrm{vis}_{u v}+\mathbf{W}^{d} \operatorname{dist}_{u v}+\mathbf{W}^{i} \text { iou }_{u v}+\mathbf{W}^{\theta} \text { theta }_{u v}\tag{4} eu→v=Wvvisuv+Wddistuv+Wi iou uv+Wθ theta uv(4)
其中 W v \mathbf{W}^{v} Wv 、 W d \mathbf{W}^{d} Wd、 W i \mathbf{W}^{i} Wi和 W θ \mathbf{W}^{\theta} Wθ 是平衡语义和空间关系权重的参数。

3.4 Hidden Object Inference
根据每个图像的关系图,我们推断隐藏在混淆区域中的隐私相关物体的类别。 我们期望在给定图像中的场景和可识别物体的情况下,学习隐藏物体类的概率分布(probability distribution)。我们在算法2中描述了我们的算法。

图神经网络(Graph Neural Network, GNN)[32]可以通过基于隐藏对象的邻域来帮助描述隐藏对象的表示,通过节点之间的迭代消息传递(iterative message passing)。我们定义第 t t t 个迭代步骤 v v v 的节点状态为 h v ( t ) \mathbf{h}_{v}^{(t)} hv(t),我们初始化节点状态为:
h v ( 0 ) = x v . (5) \mathbf{h}_{v}^{(0)}=\mathbf{x}_{v} .\tag{5} hv(0)=xv.(5)
在一次迭代步骤中,通过聚合其节点表示 x v \mathbf{x}_{v} xv 和其邻域节点的状态和表示来更新 v v v 的节点状态。传播过程可以定义为:
h v ( t ) = f ( x v , x N B R ( v ) , h v ( t − 1 ) , h N B R ( v ) ( t − 1 ) ) , (6) \mathbf{h}_{v}^{(t)}=\mathbf{f}\left(\mathbf{x}_{v}, \mathbf{x}_{\mathrm{NBR}(v)}, \mathbf{h}_{v}^{(t-1)}, \mathbf{h}_{\mathrm{NBR}(v)}^{(t-1)}\right),\tag{6} hv(t)=f(xv,xNBR(v),hv(t−1),hNBR(v)(t−1)),(6)
其中 f ( ⋅ ) f(·) f(⋅) 是一个参数函数, N B R ( v ) \mathrm{NBR}(v) NBR(v) 表示 v v v 的邻域节点。
一些研究表明,图卷积神经网络(Graph Convolutional neural Networks, GCNs)有助于物体检测中的图推理[19,43]。他们使用图形来描述区域之间的关系,并应用 GCNs 来学习感兴趣区域的潜在视觉表征(the latent visual representations)。然而,如果在我们的场景中应用GCNs,我们将面临的问题是,混淆区域的状态可能会对其他节点的学习产生负面影响。继门控图神经网络(Gated Graph Neural Network,GGNN)[22]之后,我们引入门控循环单元(Gated Recurrent Unit)[10],通过重置门(reset gate)控制混淆区域节点对可识别对象节点的负面影响,同时通过更新门(update gate)使用从其他节点收集的消息更新混淆区域节点的状态。
对于每个传播步骤,节点 v v v 根据图的邻接矩阵表示,从其邻居节点 v ∈ N B R ( v ) v∈\mathrm{NBR}(v) v∈NBR(v) 中聚集节点表示为 x ~ v \widetilde{\mathbf{x}}_{v} x v:
x ~ v ( t ) = E : v ⊤ [ h 1 ( t − 1 ) ⋯ h ∣ V ∣ ( t − 1 ) ] , \widetilde{\mathbf{x}}_{v}^{(t)}=E_{: v}^{\top}\left[\begin{array}{lll} \mathbf{h}_{1}^{(t-1)} & \cdots \mathbf{h}_{|V|}^{(t-1)} \end{array}\right], x v(t)=E:v⊤[h1(t−1)⋯h∣V∣(t−1)],
其中 E : v E_{: v} E:v 是与节点 v v v 相关的入边表示,节点状态在第 t t t 个传播步骤中更新为 z v t \mathbf{z}_{v}^{t} zvt,重置为 r v t \mathbf{r}_{v}^{t} rvt:
z v t = σ ( W z x ~ v ( t ) + U z h v ( t − 1 ) ) , r v t = σ ( W r x ~ v ( t ) + U r h v ( t − 1 ) ) , (8) \begin{aligned} \mathbf{z}_{v}^{t}&=\sigma\left(\mathbf{W}^{z} \widetilde{\mathbf{x}}_{v}^{(t)}+\mathbf{U}^{z} \mathbf{h}_{v}^{(t-1)}\right), \\ \mathbf{r}_{v}^{t}&=\sigma\left(\mathbf{W}^{r} \widetilde{\mathbf{x}}_{v}^{(t)}+\mathbf{U}^{r} \mathbf{h}_{v}^{(t-1)}\right), \end{aligned}\tag{8} zvtrvt=σ(Wzx v(t)+Uzhv(t−1)),=σ(Wrx v(t)+Urhv(t−1)),(8)
其中 W z \mathbf{W}^{z} Wz、 U z \mathbf{U}^{z} Uz、 W r \mathbf{W}^{r} Wr 和 U r \mathbf{U}^{r} Ur 分别是更新门和复位门中的可学习参数, σ σ σ 表示 sigmoid 函数。我们使用 z v t \mathbf{z}_{v}^{t} zvt 和 r v t \mathbf{r}_{v}^{t} rvt 更新 v v v 的节点状态,使用激活 tanh \tanh tanh 函数:
h ~ v ( t ) = tanh ( W ⋅ x ~ v ( t ) + U ( r v t ⊙ h v ( t − 1 ) ) ) , h v ( t ) = ( 1 − z v t ) ⊙ h v ( t − 1 ) + z v t ⊙ h ~ v ( t ) , (9) \begin{aligned} \widetilde{\mathbf{h}}_{v}^{(t)}&=\tanh \left(\mathbf{W} \cdot \widetilde{\mathbf{x}}_{v}^{(t)}+\mathbf{U}\left(\mathbf{r}_{v}^{t} \odot \mathbf{h}_{v}^{(t-1)}\right)\right), \\ \mathbf{h}_{v}^{(t)}&=\left(1-\mathbf{z}_{v}^{t}\right) \odot \mathbf{h}_{v}^{(t-1)}+\mathbf{z}_{v}^{t} \odot \widetilde{\mathbf{h}}_{v}^{(t)}, \end{aligned}\tag{9} h v(t)hv(t)=tanh(W⋅x v(t)+U(rvt⊙hv(t−1))),=(1−zvt)⊙hv(t−1)+zvt⊙h v(t),(9)
其中, ⊙ ⊙ ⊙ 是元素乘法。
此外,我们观察到一种现象,一些物体之间的关联更强。例如,一个人更有可能因为他与另一个出席同一事件的人的社会关系(social relationship)而被定义为私人,而不是因为街上的消防栓。我们附加了一种注意力机制来衡量其他节点对混淆区域节点表征的贡献。我们的注意力机制与图注意力网络(Graph Attention Networks,GAT)[38]略有不同。我们计算混淆区域节点 u ∈ V p u \in V^{p} u∈Vp 与其邻域节点之间的相关性(relevance)作为注意力系数:
e ~ u → v = f a ( [ W a ⋅ h u ∥ U a ⋅ h v ] ) , α u → v = σ ( LeakyReLU ( e ~ u → v ) ) . (10) \begin{aligned} \widetilde{e}_{u \rightarrow v} & =\mathbf{f}_{a}\left(\left[\mathbf{W}^{a} \cdot \mathbf{h}_{u} \| \mathbf{U}^{a} \cdot \mathbf{h}_{v}\right]\right), \\ \alpha_{u \rightarrow v} & =\sigma\left(\operatorname{LeakyReLU}\left(\widetilde{e}_{u \rightarrow v}\right)\right) . \end{aligned}\tag{10} e u→vαu→v=fa([Wa⋅hu∥Ua⋅hv]),=σ(LeakyReLU(e u→v)).(10)
其中 [ ⋅ ∥ ⋅ ] [·∥·] [⋅∥⋅] 表示混淆区域节点 u u u 与其邻域中某一个节点 v ∈ N B R ( u ) v∈\mathrm{NBR}(u) v∈NBR(u) 的连接(concatenation), f a ( ⋅ ) \mathbf{f}_a(·) fa(⋅) 是将高维节点状态的连接映射为实数的非线性函数, σ σ σ 为激活的 sigmoid 函数。为了这个目的,我们收集其邻域节点的状态,并在拼接前用注意力系数对其进行加权:
h v ′ = ∥ u ∈ NBR ( v ) α u → v h u (11) \mathbf{h}_{v}^{\prime}=\|_{u \in \operatorname{NBR}(v)} \alpha_{u \rightarrow v} \mathbf{h}_{u}\tag{11} hv′=∥u∈NBR(v)αu→vhu(11)
混淆区域(obfuscated regions)中隐藏物体的识别归结为节点分类问题。最后,将最终的状态和节点表示用于分类:
o i = g ( h i ′ , x i ) o_{i}=\mathbf{g}\left(\mathbf{h}_{i}^{\prime}, \mathbf{x}_{i}\right) oi=g(hi′,xi)
其中 g ( ⋅ ) \mathbf{g}(·) g(⋅) 是分类器,在我们的实验中用 softmax 函数实现。
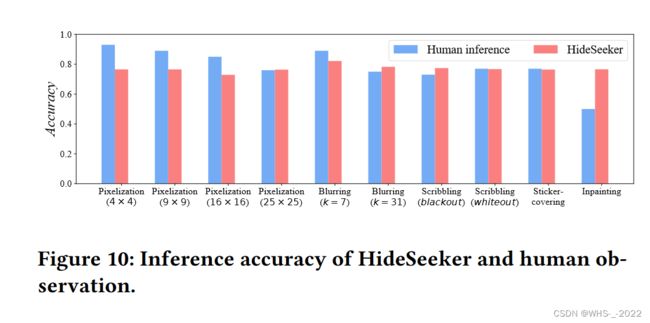
4 EVALUATIONS
4.7 Summary
总之,我们的实验结果通过发现和分类隐藏对象的准确性,证明了图像混淆技术中存在隐私再次泄露(privacy re-disclosure)的风险。客观上,我们的方法在很大程度上优于几种可能用于发现隐藏在混淆图像中的隐私相关对象的方法。此外,我们证明了我们的方案对各种混淆技术具有通用性。我们招募了10名志愿者来观察1000张隐藏物体的混淆图像,我们的结果表明,对于我们测试的一半混淆技术,我们的方案与人眼观察结果相当。特别地,我们的方案可以揭露人眼在图像经过修复混淆后(obfuscated by inpainting)无法发现的隐藏隐私信息。
此外,我们在移动设备上实现了我们的系统,并评估了处理时间成本。我们可以在手机上在两秒内推断出混淆图像中与隐私相关的对象。
6 DISCUSSIONS AND CONCLUSION
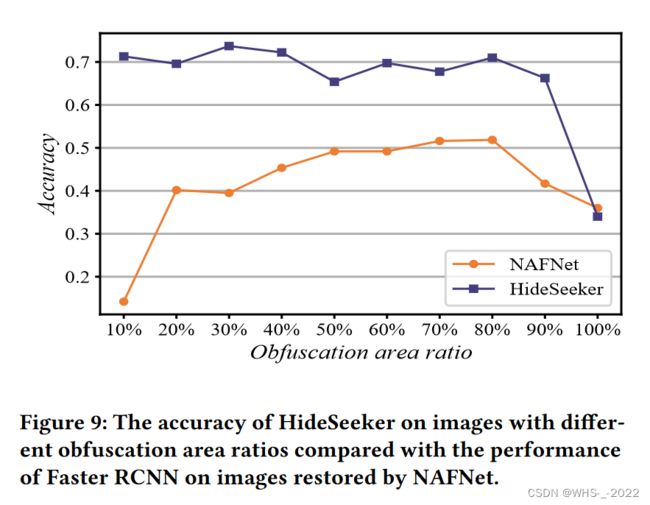
我们的方法可能会受到用于计算机视觉任务的模型性能的影响,包括目标检测、图像操作检测和定位以及场景分类。我们在图11中展示了混淆区域的定位降低了精度,平均损失0.39%。

另一方面,我们对隐藏物体的推断依赖于混淆区域的上下文信息。当
- (1)图像中已经没有可识别的物体时,我们的方案可能会失败;
- (2)混淆区域的比例超过图像的80%。
在第一种情况下,没有任何关于周围物体的线索,我们只能依靠场景的分类和与场景强相关的可能物体。如图9所示,大面积的混淆会严重影响我们的推理。当80%以上的图像被操纵或遮挡时,很难对场景进行准确分类。因此,我们很难对隐藏物体的上下文信息进行建模。
在这项工作中,为了探索受混淆保护的图像的隐私泄露风险,我们设计了一个有效和高效的方案,HideSeeker,来揭示混淆图像中与隐私相关的隐藏对象的类别。物体的原始视觉特征被混淆技术严重操纵或遮挡,导致目标检测算法无法识别它们。我们通过语义和空间关系图整合隐藏物体的上下文信息来解决这一挑战。
几个有趣的任务仍然是未来的工作,包括处理
- 1)没有可识别物体的图像,
- 2)具有极大模糊区域的图像。
我们还计划扩展我们的研究,以发现受保护视频中的隐藏物体。