Eureka和Zookeeper的区别
Eureka和Zookeeper的区别
● Mysql,Oracle,SqlServer等关系型数据库遵循的原则是 ACID 原则;
即 :A: 原子性 C: 一致性 I: 独立性 D: 持久性
● Redis,Mogodb 等非关系型数据库遵循的原则是 CAP 原则;
即: C: 一致性, A: 可用性, P: 分区容错性(服务对网络分区故障的容错性)
CAP理论:
在任何分布式系统中,最多只能实现两点(即 CP 或者 AP),而由于当前网络延迟故障会导致丢包等问题,所以分区容错性是必须实现的,也就是NoSql 数据库 P 必须得有,剩余的一致性和可用性只能二选一,没有NoSql数据库能同时实现三点。
Eureka和Zookeeper就是CAP定理实现
Eureka概述
Eureka是spring Cloud中的一个负责服务注册与发现的组件, 遵循CAP理论中的 A(可用性)和 P(分区容错性)
一个Eureka中分为 eureka server 和 eureka client 其中 eureka server 作为服务的注册与发现中心,eureka client 既可以作为服务的生产者,也可以作为服务的消费者。
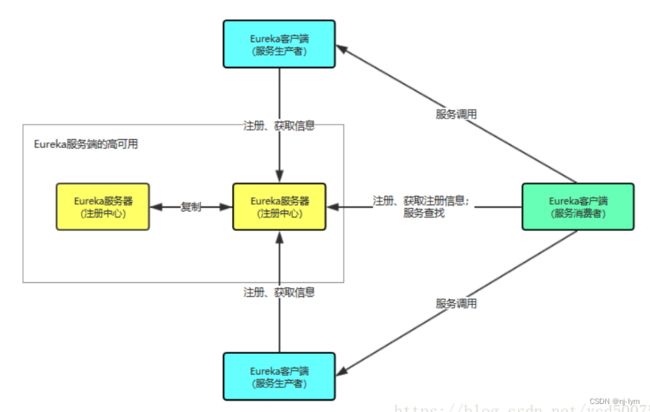
上图中,我们首先会启动一个或多个Eureka server,这些Eureka server同步保留着所有的服务信息。然后我们启动不同的 eureka client,向服务端发起服务注册和服务查询。不论向那个eureka server进行注册,最终都会同步给所有配置好的eureka server。我们所获取的服务信息也同样都是一致的。
Eureka注册中心实现
step1: 引入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-serverartifactId>
dependency>
step2: 在启动类中添加注解 @EnableEurekaServer
@SpringBootApplication
@EnableEurekaServer
public class ServiceRegistryApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceRegistryApplication.class, args);
}
}
step3: 在配置文件中配置
#服务端口
server.port=8077
#服务名称
spring.application.name=eureka-server
#服务地址
eureka.instance.hostname=localhost
#不向注册中心注册自己 (true表示向注册中心注册自己)
eureka.client.register-with-eureka=false
#取消检索服务
eureka.client.fetch-registry=false
#开启注册中心的保护机制,默认是开启
eureka.server.enable-self-preservation=true
#设置保护机制的阈值,默认是0.85。
eureka.server.renewal-percent-threshold=0.5
#注册中心路径,如果有多个eureka server,在这里需要配置其他eureka server的地址,用","进行区分,如"http://address:8888/eureka,http://address:8887/eureka"
eureka.client.service-url.default-zone=http://${eureka.instance.hostname}:${server.port}/eureka
step4: 进入http://localhost:8077 查看注册中心
Eureka client服务注册(生产者)
step1: 引入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
step2: 在启动类中添加注解 @EnableEurekaClient
@SpringBootApplication
// 注意:服务端配置的是EnableEurekaServer,客户端配置的是EnableEurekaClient
@EnableEurekaClient
public class UserServerApplication {
public static void main(String[] args) {
SpringApplication.run(UserServerApplication.class, args);
}
}
step3: 配置
#服务端口
server.port=7001
#服务名称
spring.application.name=user
#服务地址
eureka.instance.hostname=localhost
#注册中心路径,表示我们向这个注册中心注册服务,如果向多个注册中心注册,用“,”进行分隔
eureka.client.serviceUrl.defaultZone=http://localhost:8077/eureka
#心跳间隔5s,默认30s。每一个服务配置后,心跳间隔和心跳超时时间会被保存在server端,不同服务的心跳频率可能不同,server端会根据保存的配置来分别探活
eureka.instance.lease-renewal-interval-in-seconds=5
#心跳超时时间10s,默认90s。从client端最后一次发出心跳后,达到这个时间没有再次发出心跳,表示服务不可用,将它的实例从注册中心移除
eureka.instance.lease-expiration-duration-in-seconds=10
step4: 创建一个controller,用来提供一个服务,并填写返回值
@RestController
public class UserController {
@GetMapping("users/{id}")
public String getUser(@PathVariable("id") String id) {
System.out.println("接收到请求[/users/" + id + "]");
return "testUser";
}
}
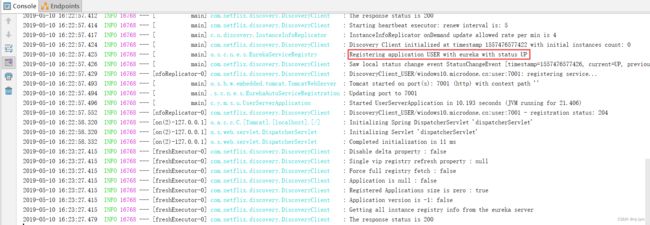
step5: 运行启动类,查看打印出来的日志信息,红框内容表示用eureka注册服务user,状态为up
Eureka client 服务注册(消费者)
在eureka中,实际上是不区分服务的消费者和服务生产者的,一个服务的消费者,同样也可以是一个服务的生产者。因此我们首先要做的就是再创建一个eureka client。这个enreka client命名为roleServer
step1: 创建eureka client
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
step2: 在启动类中添加注解 @EnableEurekaClient
@SpringBootApplication
// 注意:服务端配置的是EnableEurekaServer,客户端配置的是EnableEurekaClient
@EnableEurekaClient
public class UserServerApplication {
public static void main(String[] args) {
SpringApplication.run(UserServerApplication.class, args);
}
}
step3: 配置
#服务端口
server.port=7001
#服务名称
spring.application.name=user
#服务地址
eureka.instance.hostname=localhost
#注册中心路径,表示我们向这个注册中心注册服务,如果向多个注册中心注册,用“,”进行分隔
eureka.client.serviceUrl.defaultZone=http://localhost:8077/eureka
#心跳间隔5s,默认30s。每一个服务配置后,心跳间隔和心跳超时时间会被保存在server端,不同服务的心跳频率可能不同,server端会根据保存的配置来分别探活
eureka.instance.lease-renewal-interval-in-seconds=5
#心跳超时时间10s,默认90s。从client端最后一次发出心跳后,达到这个时间没有再次发出心跳,表示服务不可用,将它的实例从注册中心移除
eureka.instance.lease-expiration-duration-in-seconds=10
step4: 创建一个配置类,创建RestTemplate来进行服务间的连接
@Configuration
public class RestConfig {
@Bean
@LoadBalanced //负载均衡
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
step5: 在Controller中进行服务的调用
@RestController
public class RoleController {
// 这里配置的是我们要调用的服务实例名,我们要调用USER服务,因此这里的地址是USER
private String rest_url_prefix = "http://user";
@Autowired
private RestTemplate restTemplate;
@GetMapping("roles/{id}")
public String getRole(@PathVariable("id") String id) {
System.out.println("接收到请求[/roles/" + id + "]");
// 调用USER服务中的/users/{id}服务
return restTemplate.getForObject(rest_url_prefix + "/users/" + id, String.class);
}
}
ZooKeeper概述
● zookeeper是一个开源的分布式应用程序协调系统,简称ZK,它是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据的发布/订阅、负载均衡、名称服务、分布式协调/通知、集群管理、Master选举、分布式锁、和分布式队列等
● ZK 允许分布式进程通过共享的分层命名空间相互协调,该命名空间的组织方式与标准文件系统类似,名称空间由数据寄存器(在ZK中,称为Znodes)组成。这些寄存器类似于文件和目录,与设计用于存储的典型文件系统有所不同, zookeeper数据保存在内存中,这意味着zookeeper可以实现高吞吐量和低延迟数。zookeeper实现非常注重高性能,高可用性,严格有序的访问,不会成为单点故障并且可以实现复杂的同步。
Zookeeper集群概念
集群角色:
● Leader: 领导者,通过集群选举产生的主节点,负责集群的读与写工作。
● Follower: 追随者,有资格参与集群选举,但未能被成功选举为Leader的备用选举节点,负责集群的读服务。
● Observer: 观察者,没有资格参与集群选举,负责集群的读服务,同步Leader状态。 Observer的目的在于扩展系统, 提高读取速度。
注意: 当Leader故障之后ZooKeeper集群会通过Follower选举新的Leader,如果老的Leader故障修复之后,会再次接管集群中的Leader脚本,新的Leader则会退回Follower角色,一般集群中无需设置Observer节点。
Follower主要有四个功能:
• 1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
• 2 .接收Leader消息并进行处理;
• 3 .接收Client的请求,如果为写请求,发送给Leader进行投票;
• 4 .返回Client结果;
Follower的消息循环处理如下几种来自Leader的消息:
• 1 .PING消息: 心跳消息;
• 2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
• 3 .COMMIT消息:服务器端最新一次提案的信息;
• 4 .UPTODATE消息:表明同步完成;
• 5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
• 6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
Observer
• Zookeeper需保证高可用和强一致性;
• 为了支持更多的客户端,需要增加更多Server;
• Server增多,投票阶段延迟增大,影响性能;
• 权衡伸缩性和高吞吐率,引入Observer
• Observer不参与投票;
• Observers接受客户端的连接,并将写请求转发给leader节点;
• 加入更多Observer节点,提高伸缩性,同时不影响吞吐率;
Zookeeper的读写机制
- zookeeper是一个有多个server组成的集群
- 一个leader,多个follower
- 每个server保存一份数据副本
- 全局数据一致
- 分布式读写
- 更新请求转发,由leader实施
Zookeeper工作原理
» Zookeeper的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。
» 当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和leader的状态同步以后,恢复模式就结束了。 状态同步保证了leader和server具有相同的系统状态。
» 一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。 这时候当一个server加入zookeeper服务中,它会在恢复模式下启动, 发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在Broadcast状态,直到leader崩溃了或者leader失去了大部分 的followers支持。
» 广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。 所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64为的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
» 当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
» 每个Server启动以后都询问其它的Server它要投票给谁。
» 对于其他server的询问,server每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统启动时每个server都会推荐自己)
» 收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。
» 计算这过程中获得票数最多的的sever为获胜者,如果获胜者的票数超过半数,则该server被选为leader。否则,继续这个过程,直到leader被选举出来
» leader就会开始等待server连接
» Follower连接leader,将最大的zxid发送给leader
» Leader根据follower的zxid确定同步点
» 完成同步后通知follower 已经成为uptodate状态
» Follower收到uptodate消息后,又可以重新接受client的请求进行服务了
Zookeeper集群的数目
• Leader选举算法采用了Paxos协议;
• Paxos核心思想:当多数Server写成功,则任务数据写成功如果有3个Server,则两个写成功即可;如果有4或5个Server,则三个写成功即可。
• Server数目一般为奇数(3、5、7)如果有3个Server,则最多允许1个Server挂掉;如果有4个Server,则同样最多允许1个Server挂掉由此, 我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。
Zookeeper 的数据模型
» 层次化的目录结构,命名符合常规文件系统规范
» 每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
» 节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
» Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
» 客户端应用可以在节点上设置监视器
» 节点不支持部分读写,而是一次性完整读写
Zookeeper 的节点
» Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
» Znode的类型在创建时确定并且之后不能再修改
» 短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
» 持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
Zookeeper有四种形式的目录节点
» PERSISTENT: 持久的
» EPHEMERAL: 暂时的
» PERSISTENT_SEQUENTIAL: 持久化顺序编号目录节点
» EPHEMERAL_SEQUENTIAL: 暂时化顺序编号目录节点