(10)强化:贪婪模式,捕获组,正则替换,正则分割,反向引用,UBB,断言,委托,Invoke,lambda,Action
一、作业问题
1、问:.net正则表达式默认使用unix的正则表达式模式?
答:在C#和.NET中,默认使用的是基于ECMAScript标准的正则表达式模式,而不是UNIX风
格的正则表达式模式。
这意味着在C#和.NET中,正则表达式的语法和行为更接近于ECMAScript规范定义的正则
表达式。它们支持大部分的正则表达式元字符、量词和模式匹配功能,例如字符类、
组、选择、捕获和反向引用等。
注意,某些功能和选项可能在不同正则表达式引擎之间有所不同,所以在编写正则表达
式时需要注意跨平台和跨引擎的兼容性。
问:什么是ECMAScript规范?
答:ECMAScript是一种由Ecma International组织定义的脚本语言规范,它在C#和.NET中
的上下文中并不直接适用。ECMAScript规范主要用于定义JavaScript的语法、语义和
基本对象模型。JavaScript是一种在Web开发中广泛使用的脚本语言。
ECMAScript规范为JavaScript运算符、控制流语句、函数定义、对象模型等等。它定
义了JavaScript的核心语法和行为,以确保在不同的实现中,JavaScript的行为是一
致的。
ECMAScript规范确保了不同的 JavaScript 引擎(例如浏览器中的V8引擎和Node.js中
的引擎)能够在遵循同一规范的前提下解释和执行JavaScript代码。这使得开发人员能
够编写与特定JavaScript引擎无关的脚本,从而提高了可移植性和互操作性。
C#和.NET中正则表达式实现与ECMAScript规范的相似,但并不直接遵循ECMAScript规
范。它们遵循.NET平台的正则表达式语法和行为。
2、问:下面代码为什么前面不能成功,而后面成功了?
int[] ints = { 1, 2, 3 };
Object[] objs1 = ints;//失败
string[] s = { "a", "b", "c" };
Object[] objs2 = s;//成功
答:注意int[],string[],object[]是兄弟类,有共同的父类array
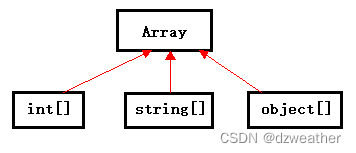
int[] 无法隐式转换为 Object[],是因为数组在C#中是协变的,但并不适用于值类型。
虽然int是从System.Object类型派生的,但值类型数组不能直接隐式转换为object[]
数组。这是为了防止将值类型元素放置在将来可能会修改元素类型的数组中,从而导致
类型不安全。
string[] 可以隐式转换为 Object[],是因为字符串是引用类型。引用类型数组是协变
的,允许将派生类数组隐式转换为基类数组。
总结:值类型数组无法进行协变转换,而引用类型数组可以进行协变转换。
因此int[]转object[]出错;string[]可转object[]两者是引用且string是object
的子类。
注意:这里的协变不是string[]数组转object[]数组,而是里面的元素转换。
那么string[]是怎样详细的转换为object[]的呢?
在C#中,数组是协变的,这意味着在特定条件下,派生类型数组可以隐式转换为基类类
型数组。然而,这种协变仅适用于引用类型数组,而不适用于值类型数组。
string[]数组可以隐式转换为object[]数组,因为string是派生类,object是基类。转
换过程涉及的操作是从数组的内部表示来看的。具体的转换过程是:
创建一个新的 object[] 数组。
将 string[] 的元素逐个复制到 object[] 数组中。
这样,object[] 数组就包含了与 string[] 相同的元素,因为每个 string 都可以视
为 object。
关于为什么这种协变被允许,是因为在实际使用上是相对安全的。由于string是不可变
的,所以不会发生修改 string 元素类型的情况。因此,允许将 string[] 隐式转换为
object[],在运行时不会引发类型安全问题。
注意,在 object[] 数组中存储的仍然是引用,只是静态类型发生了变化。这意味着你
不能将非 string 类型的对象直接赋值给 objs2 数组元素,因为这可能导致运行时异
常。
string[] s = { "a", "b", "c" };
object[] objs2 = s;
objs2[0] = "d";// 可以修改对象的值
objs2[1] = 123;//运行时异常,因为实际上objs2数组中存储的还是string[]的元素类型
问:什么是静态类型?
答:静态类型(static type)是指变量、表达式或者成员在编译期间已知的类型。它是
指变量在声明时所使用的类型,也可以是表达式的结果类型或者成员的类型。
静态类型在编译时确定,并在编译期间进行类型检查。它决定了编译器在编译阶段如何
处理和推断变量、表达式和成员的操作和使用。
静态类型的一个重要特性是类型安全性。静态类型系统通过验证操作和使用的类型是否
与预期的类型兼容来确保类型安全。这样可以在编译阶段捕获一些类型错误,避免在运
行时出现类型不匹配或者无效的操作。
int num = 10; // 静态类型为 int
string name = "John"; //静态类型为 string
int result = 5 + 3; // 表达式 "5 + 3" 的静态类型为 int
string message = "Hello, " + name;//表达式"Hello, "+name的静态类型为string
public class MyClass
{
public int MyProperty { get; set; } //MyProperty的静态类型为int
public string MyMethod() //MyMethod返回值的静态类型为string
{
return "Hello";
}
}
静态类型是C#类型系统中的重要概念,它提供了类型安全性和编译时类型检查的好处。
通过使用静态类型,可以在编写代码时更早地发现潜在的错误,并提供更好的代码可
读性和可维护性。
问:简单地说下一协变与逆变?
答:协变:就是子转父;
逆变:就是父转子。
协变性和逆变性使得委托和泛型接口在处理派生类型和基类型之间的转换时更加灵
活。它们提供了一种方式来安全地在继承关系中进行类型转换,从而更好地支持泛
型编程和多态行为。
问:类型转换只能发生在父子之间,不能发生在兄弟之间?
答:实际上,C#中存在一种称为"强制类型转换(cast)"的操作,可以用于将一种类型
转换为另一种类型,包括兄弟类型之间的转换。但是,这种转换只有在两个类型之间存
在继承或实现关系时才能够成功。
兄弟类型转换,需要满足:
类型必须存在继承关系或者实现相同接口。例如,类A和类B在继承自同一个基类或
实现同一个接口时,可以进行类型转换。
需要使用显示的强制类型转换操作符(cast)。在C#中,使用括号和目标类型表示
强制类型转换的语法。
class Animal {}
class Dog : Animal {}
Animal animal = new Dog();
Dog dog = (Dog)animal; // 兄弟类型之间的强制类型转换
问:最开始Object[] objs1 = ints;如何才能保证正确转换?
答:值向引用,是一个装箱过程,且int->object需要强制类型转换。
(1)就是老式的一个一个转:
int[] n = { 1, 2, 3 };
object[] o = new object[n.Length];
for (int i = 0; i < n.Length; i++)
{
o[i] = (object)n[i];
}
(2)用Array.ConvertAll,将一个数组的元素进行转换,并返回另一种类型的数组。
int[] n = { 1, 2, 3 };
object[] o =Array.ConvertAll(n,x=>(object)x);
n为源数组参数,第二参数是一个委托,指定每个元素的转换方式。x=>(object)x意即
对于每一个输入元素参数x,都返回(object)x的值。最终所有转换后的值组成新的数组。
(3)用linq
int[] n={1,2,3};
object[] o = n.Select(x=>(object)x).ToArray();
用LINQ的Select方法对数组 n 中的每个元素执行一个操作,并返回一个新的序列。在
这种情况下,操作是将每个元素 x 强制转换为 object 类型。
Select 方法返回的是一个序列(Sequence),而不是数组。
序列是一种可枚举的集合类型,类似于数组,但它具有延迟执行的特性。这意味着在
调用 Select 方法时,并没有立即执行转换操作,而是返回一个表示转换操作的查询
表达式。如果你想要将序列转换为数组,则使用 .ToArray() 方法,
3、问:object与object[]的什么区别?
答:在C#中,object 和 object[] 是两种不同的类型。
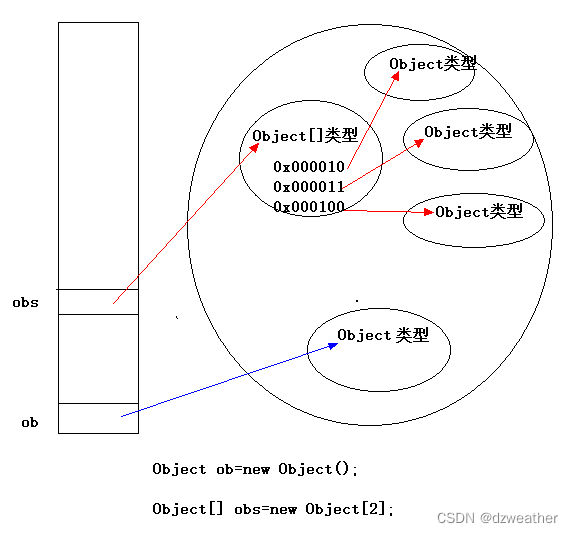
object 是C#中的基类,所有的类都直接或间接地从 object 继承。这意味着任何类型的对
象都可以赋值给 object 类型的变量。object 是一种动态类型,可以存储任意类型的对象。
在使用 object 类型时,需要注意的是,它会导致装箱和拆箱的操作,可能会带来性能上的
开销。
object obj = 42; // 将int类型赋值给object类型的变量
obj = "Hello World"; // 将string类型赋值给object类型的变量
object[] 是一个数组类型,它可以存储多个元素,而每个元素都可以是任意类型的对象。
数组的每个元素都是 object 类型,也就是说,它可以持有任何类型的对象。数组的长度是
固定的,一旦创建,就不能再改变。
object[] array = new object[3];
array[0] = 42; // 存储int类型的对象
array[1] = "Hello"; // 存储string类型的对象
array[2] = new DateTime(2023, 7, 12); // 存储DateTime类型的对象
注意:由于 object[] 是一个数组类型,它的元素仅能是 object 类型或派生自 object 类型
的类型。这意味着,如果将元素类型为其他类型的对象赋值给 object[] 数组的元素,会导
致隐式类型转换和装箱的操作。
4、问: Regex.Match()返回的对象可以为null吗?
答:Regex.Match()方法不会返回null。
相反,失败的情况下,它会返回一个具有Success属性为false的Match对象,你可以通过
检查Success属性来确定是否匹配成功。
二、贪婪模式与非贪婪模式
1、贪婪模式演示:
(1)“1111。11。111。111111。”
贪婪:.+。(默认为贪婪模式,尽可能的多匹配。)1111。11。111。111111。
.+ 也是全部
非贪婪:.+?。(尽可能的少匹配,(1个。))1111。
.+? 结果为1
.*? 结果没有,尽管为"",但匹配是成功的即Success为True
(.+。)*
注意:当在“限定符”后使用?的时候,表示终止贪婪模式。此时会尽可能少的匹配。
问:如何判断?是非贪婪符?
答:当?紧跟在一个字符或一个表达式后面时,它将成为一个量词,表示该字符或表达式
出现零次或一次。例如,a?表示匹配一个可选的a字符。
当?跟在一个量词后面时,它将成为一个非贪婪符,表示该量词使用非贪婪模式进行
匹配,尽可能少地匹配字符。例如,a+?表示使用非贪婪模式匹配一个或多个a字符。
所以,对于a?,因为?紧跟在a字符后面,它是作为量词使用的。而对于a+?,因为?跟
在+量词后面,它是作为非贪婪符使用的。
问:什么是限定符?有哪些?
答:正则表达式中,限定符指的是用来限制匹配模式重复次数的特殊字符或符号。
限定符可以出现在正则表达式中的元字符、字符类或子表达式后面。
常用的限定符:
1. "*"(星号):匹配前一个元素零次或多次。
2. "+"(加号):匹配前一个元素一次或多次。
3. "?"(问号):匹配前一个元素零次或一次。
4. "{n}":匹配前一个元素恰好n次。
5. "{n,}":匹配前一个元素至少n次。
6. "{n,m}":匹配前一个元素至少n次,但不超过m次。
此外,还有贪婪限定符和惰性限定符。贪婪限定符(如`*`和`+`)尽可能多地匹配
字符,而惰性限定符(即在贪婪限定符后加上`?`)尽可能少地匹配字符。
例如,`a+b`会匹配最长的连续的a字符,而`a+?b`会匹配最短的连续的a字符。
问:限定符与量词有什么区别?
答:C#的正则表达式中,限定符和量词是相同的概念,可以将它们看作是等价的术语。在不
同的正则表达式引擎中,有时也可以将它们称为限定符,有时称为量词。这是一个术语
上的差异,但它们的功能和使用方式是相同的。
限定符有:
? 限定符表示前面的元素在模式中可以出现零次或一次。例,ab?表示ab或a。
* 表示前面的元素在模式中可以出现零次或多次。例,ab表示a、ab、abb、abbb等。
+ 可以出现一次或多次。例,ab+表示ab、abb、abbb等,但不匹配a。
{n} 必须出现恰好n 次。例,ab{2}表示abb,但不匹配a或abbb。
{n,} 必须出现至少n次。例,ab{2,}表示abb、abbb等,但不匹配a。
{n,m} 必须出现至少n次且不超过m次。
例ab{2,4}表示abb、abbb、abbbb,但不匹配a或abbbbb。
2、"大家好。我是S.H.E。我22岁了。我病了,呜呜。fffff"
贪婪: 我是(.+)。 结果:我是S.H.E。我22岁了。我病了,呜呜。
+、*的匹配默认是贪婪(greedy)的:尽可能多的匹配,直到“再贪婪一点儿”其后的匹
配模式就没法匹配为止。
在+、*后添加?就变成非贪婪模式(? 的另外一个用途):让其后的匹配模式尽早的
匹配。修改成"我是(.+?)。"
注意:有时匹配需要看后面。例如"abcccccc"用^abc*?$看似是非贪婪,但后面需要
结束$来说明,最后匹配的是abcccccc,实则与贪婪与非贪婪没有好大关系。
一般开发的时候不用刻意去修饰为非贪婪模式,只有遇到bug的时候发现是贪婪模式
的问题再去解决。如果匹配的结果比自己预想的要多,那么一般都是贪婪模式的原因。
问:对于"abbbbbb"使用ab??匹配结果是多少?
答:量词后面的?作非贪婪符。
正则引擎会尝试匹配"a”,然后尝试匹配字符"b",因为"b"之后的"?"可以表示前一个
字符重复零次或一次。即b或"",最后一个?表示非贪婪,就是要尽量的少,在b与""之
间只有选择少的"",于是结果就是a.
问:对于"123456"使用\d${6}匹配的结果是什么?
答:对于无效的匹配,在正则引擎中通常会从左到右尝试匹配,即尽可能从左边开始找到
有效的匹配。这意味着当遇到无效的模式时,正则引擎会尽早地停止匹配。
同样地,对于模式"\d${6}",正则引擎会尝试匹配"\d$",然后尝试匹配"{6}"。由于
"$"在这个位置上是无效的,正则引擎会停止匹配,不再继续。这种行为确保了正则引
擎在遇到无效模式时可以提前结束匹配,以提高效率。
注意:*?又不一样。比如a.*?,?为非贪婪符尽量用少的所以结果为a
结论:凡是*?结合在一起,都会让前一个字符或字符集直接“消失”。
例dw(\d+[a-z]*)*?实际上等效于dw,其中\d+[a-z]*直接“消失”
3、"大家好。我是S.H.E。我是S。我是H。我是E。我是杨中科。我是苏坤。我是杨洪波。
我是牛亮亮。我是N.L.L。我是★蒋坤★。呜呜。fffff"
我是(.+)。 匹配的结果并不是每个人姓名,而是贪婪模式到直呜呜
要用非贪婪模式,就找上面的量词,即+,在它的后面加上?就是终止贪婪。
我是(.+?)。 这样就匹配了每个姓名。
string s = "大家好。我是S.H.E。我是S。我是H。我是E。我是杨中科。我是苏坤。我是杨洪波。我是牛亮亮。我是N.L.L。我是★蒋坤★。呜呜。fffff";
MatchCollection mc = Regex.Matches(s, @"我是(.+?)。");
foreach (Match m in mc)
{
Console.WriteLine(m.Value);
Console.WriteLine("\t" + m.Groups[1].Value);
}
Console.WriteLine(mc.Count);
4、问:什么是贪婪模式?
答:正则表达式中,贪婪模式是一种匹配方式,它会尽可能多地匹配字符。
默认情况下,当使用量词(如*、+、?、{})时,正则表达式引擎会采用贪婪模式。贪婪模
式会尽可能地匹配更多的字符。
例如,对于正则表达式 `a.*b`,它表示匹配以 "a" 开始,以 "b" 结尾,并且之间包含任
意数量的字符。如果应用于字符串 "a1b2b3b4b",贪婪模式将会匹配最长的可能结果,即
整个字符串,得到匹配结果 "a1b2b3b4b"。
如果你想要改变贪婪模式,可以在量词后面加上问号(?),形成非贪婪模式。例如,对于
正则表达式`a.*?b`,非贪婪模式会尽可能少地匹配字符。对于同样的字符串"a1b2b3b4b",
非贪婪模式将匹配最短的可能结果,即 "a1b"。
总结,贪婪模式会尽可能多地匹配字符,而非贪婪模式则会尽可能少地匹配字符,取决于量
词后面是否使用问号。在C#中,默认情况下量词使用贪婪模式。
问:什么是非贪婪模式?
答:非贪婪模式(也称为懒惰模式或最小匹配模式)是正则表达式中的一种匹配方式,它尽
可能少地匹配字符。它在C#中通过在量词后添加问号来实现。
三、匹配组
1、正则表达式可以从一段文本中将所有符合匹配的内容都输出出来。
Match获得的是匹配的第一个。Regex.Matches方法可以获得所有的匹配项。
问:匹配和group的区别?
答:匹配和groups是两个相关但不同的概念。
匹配(Match):
匹配是指将正则表达式应用于输入字符串,并找到符合正则表达式规则的内容。在C#
中,使用Regex.Match方法执行匹配操作,它返回一个Match对象。Match对象包含有关
匹配的详细信息,例如匹配的值、开始和结束位置以及是否成功匹配等。
string input = "Hello, my email address is [email protected]";
string pattern = @"\b\w+@\w+\.\w+\b";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
Console.WriteLine("匹配成功!");
Console.WriteLine("匹配的值:" + match.Value);//
Console.WriteLine("开始位置:" + match.Index);//27
Console.WriteLine("结束位置:" + (match.Index + match.Length - 1));//42
}
Console.WriteLine(input.Length);//43
分组(Groups):
分组允许将正则表达式的一部分定义为一个独立的组,并可以通过组索引或组名称访
问。你可以使用圆括号 () 将表达式的一部分括起来,形成一个分组。在C#中,使用
Match.Groups属性来访问分组,该属性返回一个GroupCollection对象,其中包含了
匹配结果中的所有分组。
string input = "My phone number is (123) 456-7890";
string pattern = @"\((\d{3})\)\s(\d{3})-(\d{4})";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
Console.WriteLine("匹配成功!");
Console.WriteLine("完整匹配:" + match.Value);
Console.WriteLine("第一个分组:" + match.Groups[1].Value);
Console.WriteLine("第二个分组:" + match.Groups[2].Value);
Console.WriteLine("第三个分组:" + match.Groups[3].Value);
}
匹配是指将正则表达式应用于输入字符串并找到符合规则的内容,而分组是指将正则表达
式的一部分定义为独立的组,并允许通过索引或名称来访问这些组。
2、案例:从一个页面提取所有Email地址,用WebClient,自己动手写Email群发器。
这里选择一个贴吧的邮件。
WebClient wc = new WebClient();
string s = wc.DownloadString("https://tieba.baidu.com/p/8496398226");
MatchCollection mc = Regex.Matches(s, @"[\w+-]+@[\w+-]+(\.[\w\-]+)+[a-z]");
foreach (Match m in mc)
{
Console.Write(m.Value);
Console.WriteLine("\t" + m.Index);
}
问:请介绍一下WebClient类?
答:WebClient是一个用于简化与Web服务器通信的实用类。它提供了多种方法来发送HTTP请
求并接收响应。WebClient类可以用于执行各种Web请求,如下载文件、上传文件、发送
POST请求等。
WebClient类常用的功能和方法:
(1)下载文件:
可以使用WebClient的`DownloadFile`方法来下载远程文件到本地计算机。
using (WebClient client = new WebClient())
{
client.DownloadFile("http://example.com/file.txt", "localFile.txt");
}
(2)下载字符串:
可以使用WebClient的`DownloadString`方法来下载指定URL的字符串响应。
using (WebClient client = new WebClient())
{
string result = client.DownloadString("http://example.com/data");
Console.WriteLine(result);
}
(3)发送POST请求:
可以使用WebClient的`UploadString`方法来发送POST请求并获取响应。
using (WebClient client = new WebClient())
{
string postData = "key1=value1&key2=value2";
string response = client.UploadString("http://example.com/api", postData);
Console.WriteLine(response);
}
问:上面post的时候不用带请求头吗?
答:在实际的应用场景中,发送POST请求时通常需要携带请求头信息。请求头中包含
了与请求相关的元数据,如内容类型、授权信息、用户代理等。 可以使用WebClient的`Headers`属性来设置请求头信息。
using (WebClient client = new WebClient())
{
client.Headers.Add("Content-Type", "application/json");
client.Headers.Add("Authorization", "Bearer myToken");
string postData = "{\"key\": \"value\"}";
string response = client.UploadString("http://example.com/api", postData);
Console.WriteLine(response);
}
上面使用`Headers`属性来设置请求头的`Content-Type`和`Authorization`字段。然
后,使用`UploadString`方法发送POST请求,并提供请求体数据。
你可以根据实际需求设置其他的请求头信息,例如设置`User-Agent`、`Accept`等。
注意,在发送POST请求时,也需要根据需要设置`Content-Type`字段来指定请求体的
内容类型。
例如,如果发送的是JSON数据,可以将`Content-Type`设置为`application/json`。
总结:在发送POST请求时,通常需要携带请求头信息。
可以使用WebClient的`Headers`属性来设置请求头字段,以满足实际需求。
(4)上传文件:
可以使用WebClient的`UploadFile`方法来上传文件到远程服务器。
using (WebClient client = new WebClient())
{
client.UploadFile("http://example.com/upload", "localFile.txt");
}
问:上面上传时不需要密码?
答:在一般情况下,使用WebClient上传文件不需要密码。但在目标服务器要求身份验
证的情况下,可以使用Credentials属性来提供用户名和密码进行身份验证。
using (WebClient client = new WebClient())
{
string username = "myUsername";
string password = "myPassword";
client.Credentials = new NetworkCredential(username, password);
client.UploadFile("http://example.com/upload", "localFile.txt");
}
(5)发送GET请求:
通过client.DownloadString发送请求。与(1)类似,这里用自定义要求请求头的:
using (WebClient client = new WebClient())
{
client.Headers.Add("User-Agent", "MyApp/1.0");
string response = client.DownloadString("http://example.com/api");
Console.WriteLine(response);
}
使用Headers属性来添加自定义的请求头字段(这里是User-Agent)。
使用DownloadString方法发送GET请求,并获取响应结果(html源码)。
除了上述功能,WebClient还提供了其他有用的方法,如发送GET请求、发送表单数据、设置请求头、设置代理等。
重要提示:使用完WebClient后正确释放资源如webclient.dispose.
在C#中使用WebClient时,推荐使用using语句来确保准确地释放资源。using语句会自
动调用WebClient的Dispose方法来释放资源,避免资源泄漏和内存占用问题。
3、 练习:从网站抓取所有的图片地址,下载到硬盘
WebClient wc = new WebClient();
string s = wc.DownloadString("https://tieba.baidu.com/p/8497297721");
// src=\"http:\/\/tiebapic.baidu.com\/forum\/w%3D580\/sign=
// bfcfd23173d3d539c13d0fcb0a86e927\/7d7297dda144ad342fa7754895a20cf430ad85b3.jpg?
// tbpicau=2023-07-17-05_02169b547e1c903d1848c17f9e015069\"
string p = @"http:\\/\\/tiebapic.baidu.com\\/forum\\/w%3D580\\/sign=[a-z0-9]+?\\/[a-z0-9]+?.jpg.*?\\";
MatchCollection mc = Regex.Matches(s, p);
int i = 0;
foreach (Match m in mc)
{
string w = m.Value.Replace("\\", "");
wc.DownloadFile(w, @"E:\" + (++i).ToString("00") + ".jpg");
}
问:如果webclient.downloadstring返回的是乱码怎么办?
答:有三种方法查看源码是什么编码:
1在源码中查找charset
2用fiddler查看响应的编码
3用HttpWebResponses查看编码
最简单就是1方法。然后,设置webclient编码后,再去获取源,即正常了。
string url = "https://example.com/page.html"; // 请求页面的URL
using (WebClient webClient = new WebClient())
{
webClient.Encoding = Encoding.UTF8;// 设置正确的编码
string content = webClient.DownloadString(url); // 下载页面内容并使用指定编码解码
Console.WriteLine(content);
}
4、练习:抓取所有超链接,特征:href="地址“
WebClient wc = new WebClient();
string s = wc.DownloadString("https://news.163.com/domestic/");
//
string p = @"href=""(https.*?/article.*?html)";
MatchCollection mc = Regex.Matches(s, p);
int i = 0;
foreach (Match m in mc)
{
Console.WriteLine(m.Groups[1]);
}
四、字符串替换
1、Regex.Replace是一个用于替换文本中匹配正则表达式的模式的方法。它允许你通过提供
一个正则表达式的模式和一个替换字符串来替换匹配到的文本。
Regex.Replace语法:
public static string Replace(
string input,
string pattern,
string replacement
);
参数说明:
input:要进行替换的输入字符串。
pattern:一个正则表达式的模式,用于匹配要替换的文本部分。
replacement:用于替换匹配到的文本部分的字符串。
public static void Main(string[] args)
{
string input = "Hello, World!";
string pattern = "[aeiou]";
string replacement = "*";
string result = Regex.Replace(input, pattern, replacement);
Console.WriteLine(result); // Output: H*ll*, W*rld!
}
上面用[aeiou]来匹配字符串中的元音字母,然后使用`*`来替换匹配到的元音字母。
注意,Regex.Replace方法如果找不到匹配的模式,将会返回原始的输入字符串。
问:如何要设置更多的选项:如忽略大小写、多行模式等?
答:可以指定`RegexOptions`等来控制匹配的方式。
例如:可以通过实例方法进行Regex r=new Regex();它有三个重载
(1)new Regex(string pattern)
pattern:一个字符串,表示要使用的正则表达式的模式。
(2)new Regex(string pattern, RegexOptions options)
options:一个 RegexOptions 枚举值,用于指定正则表达式的匹配选项。
RegexOptions枚举的一些常用选项:
None:不使用任何选项。
IgnoreCase:忽略大小写。
Multiline:启用多行模式,使 ^ 和 $ 可以匹配每行的开头和结尾。
Singleline:启用单行模式,使 . 可以匹配换行符。
IgnorePatternWhitespace:忽略模式中的空格和注释。
ExplicitCapture:强制捕获组的行为只能由显式调用的语法元素触发。
使用捕获组不再缓存,除非显示命名组(?
缓存(?:...)的捕获组不受影响
(3)new Regex(string pattern, RegexOptions options, TimeSpan matchTimeout)
matchTimeout:一个 TimeSpan 值,用于指定正则表达式的匹配超时时间。
设置正则表达式匹配超时时间的属性。默认情况下,它的值是
TimeSpan.InfiniteTimeSpan,表示没有超时限制,即匹配操作不
会被中断,直到完成或遇到问题。
通过 Regex.MatchTimeout 属性来设置匹配超时时间。若超时则会抛
出 RegexMatchTimeoutException 异常。
总结:静态方法也可以设置,可熟悉一下各选项要求:
Regex.Match(input,pattern,RegexOptions,matchTimeout);
Regex.Matches(input,pattern,RegexOptions,matchTimeout);
2、练习1:将所有连续的a替换为一个A(原需求:把连续的空格替换为一个空格)
string s = Regex.Replace("你aaa好aa哈哈a你", @"a+", @"A");
string s = Regex.Replace("你aaa好aa哈哈a你", @"a", @"A");
string s = Regex.Replace("你aaa好aa哈哈a你", @"a+", @"");
删除所有连续的a,其实就是将连续的a替换为空字符串。
string s = Regex.Replace("你aaa好aa哈哈a你", @"aa+", @"a");
练习2:将连续的-都替换成一个-
234-----234--------------34------55
string input = "234-----234--------------34------55";
string s = Regex.Replace(input, @"-+", @"-");
3、练习:将hello 'welcome to' beautiful 'China' 替换成
hello 【welcome to】 beautiful 【China】
按老办法:
string input = "hello 'welcome to' beautiful 'China'";
string s = Regex.Replace(input, @" '", @" 【");
s = Regex.Replace(s, @"' |'$", @"】");
问:对前面的捕获组如何引用?
答:引用捕获组:在同一个正则表达式模式中,可以使用 $1、$2 等来引用之前捕获的文
本。这样可以在正则表达式中识别和匹配重复的模式,比如重复的字符或单词。
引申:
分组捕获:使用()来创建捕获组,将多个模式组合在一起,并捕获整个分组的内容。
命名捕获组:可以为捕获组指定名称,(?
非捕获组:用(?:...)用来表示此捕获组不进入,不缓存。
因此直接使用“引用捕获组”,快捷方便替换
string input = "hello 'welcome to' beautiful 'China'";
string s = Regex.Replace(input, @"'(.+?)'", @"【$1】");
注意:引用捕获组是和前面的捕获组(匹配组)是一一对应的。
比如,$0就是索引为0的捕获组,也即整个捕获匹配字串。
极端情况:
我不想替换成捕获组$1,只想替换成由$与1组成的普通字串?
答:可以用\$1或$$1来表示。
小心:\$1并不一定正确,视系统和引擎。
所以为了确保正确,推荐使用$$1
string input = "hello 'welcome to' beautiful 'China'";
string s = Regex.Replace(input, @"'(.+?)'", @"【\$1】");
Console.WriteLine(s);//a
s = Regex.Replace(input, @"'(.+?)'", @"【$$1】");
Console.WriteLine(s);//b
上面a处:hello 【\welcome to】 beautiful 【\China】
b处:hello 【$1】 beautiful 【$1】
所以,请写成$$1
练习:将一段文本中的MM/DD/YYYY格式的日期转换为YYYY-MM-DD格式 ,比如“我的生日
是05/21/2010耶”转换为“我的生日是2010-05-21耶”。
string input = "我的生日是05/21/2010耶";
string s = Regex.Replace(input, @"(\d{2})/(\d{2})/(\d{4})", @"$3-$1-$2");
4、练习:隐去手机号码的中间4位。
string input = "杨中科13409876543黄林18276354908杨硕87654321345何红卫98761234567";
string s = Regex.Replace(input, @"(\d{3})\d{4}(\d{4})", @"$1****$2");
练习:将文本中连续的空格替换为一个空格.
"hello welcome to China."转换为"hello welcome to China"
string input = "hello welcome to China.";
string s = Regex.Replace(input, @"\s{2,}|\.", @"");
5、练习:[email protected]转为***@itcast.cn
[email protected]转为**********@163.com
[email protected]转为**@codeedu.com
string input = "我的生日[email protected]转为耶";
Regex r = new Regex(@"(\w+)(@[-\w]+(\.[\w]+)+)", RegexOptions.ECMAScript);
string s = r.Replace(input, delegate (Match m)
{
string head = new string('*', m.Groups[1].Value.Length);
return head + m.Groups[2].Value;
});
Console.WriteLine(s);
这里面要单独处理匹配项,静态方法里面没有,只有实例方法中有委托参数可以使用。
Regex.Replace() 方法允许你使用委托作为参数,以便在替换过程中自定义逻辑。委托
是一种函数类型,它可以将一个方法作为参数传递给另一个方法。
当你使用 Regex.Replace() 方法时,你可以传递一个委托作为第二个参数,该委托定
义了一个方法,用于确定替换的每个匹配项应该如何替换。
委托需要接受一个 Match 对象作为参数,并返回一个替换字符串。Match 对象表示正
则表达式匹配的一个结果,它包含有关匹配项的信息,如匹配的文本、位置等。
例如:对"Hello 123 World 456"中的数字加倍
string input = "Hello 123 World 456";
Regex regex = new Regex(@"\d+");// 用实例方法来匹配数字
// 使用委托来定义替换逻辑
string result = regex.Replace(input, delegate (Match m)
{
int number = int.Parse(m.Value);
return (number * 2).ToString();
});
Console.WriteLine(result); //Hello 246 World 912
上面使用匿名委托的方式可以使代码更简洁,不需要额外定义一个单独的方法来处理替
换逻辑。匿名委托非常适用于只在特定上下文中使用的简单逻辑。
重要:这个委托参数,整个委托的输入参数固定为Match match,返回固定为string.
因为 Regex.Replace() 方法期望传入一个具有匹配项的委托方法,并且期望该委托
方法能够处理匹配项并返回替换后的字符串。
Match 类型的对象包含了与正则表达式匹配的文本的详细信息,例如匹配的值、位
置等。您可以在委托方法中使用 Match 对象来操作匹配项,并根据需要返回替换后
的字符串。
委托方法的签名通常是固定的,即输入参数为 Match 类型,返回类型为 string。
这是由于 Regex.Replace() 方法的设计和约定。如果需要处理不同类型的输入参
数或返回类型,可以使用其他方法或自定义逻辑来实现更灵活的替换操作。
例如:下面不用匿名委托,自己选用不同委托
private static void Main(string[] args)
{
string input = "Hello, world! This is a test.";
// 在实例中使用委托参数传递替换委托方法
string s = Regex.Replace(input, @"\b\w+\b", ReplaceMatch);
Console.WriteLine(s); //REPLACED REPLACED! REPLACED REPLACED REPLACED REPLACED.
s = Regex.Replace(input, @"\b\w+\b", ComplexReplace);
Console.WriteLine(s); //REPLACED_5, REPLACED_5! REPLACED_2 REPLACED_1 REPLACED_4.
Console.ReadKey();
}
// 定义更复杂的替换逻辑委托方法
private static string ComplexReplace(Match match)
{
string original = match.Value;
string replacement = "REPLACED_" + original.Length;
return replacement;
}
// 定义委托方法,用于将匹配项替换为指定字符串
private static string ReplaceMatch(Match match)
{
string original = match.Value;
string replacement = "REPLACED";
return replacement;
}
6、委托复习:
internal delegate void Mydelegate(string s);// 定义一个委托类型
internal class Program
{
private static void Main(string[] args)
{
// 创建委托实例,并将其与一个方法关联
Mydelegate m = new Mydelegate(Show);
m("Hello world");// 调用委托,实际上会调用关联的方法
Console.ReadKey();
}
private static void Show(string message)
{
Console.WriteLine(message);
}
}
上面定义了一个名为MyDelegate的委托类型,它接受一个字符串参数并返回void。
然后,在Main方法中,我们创建了一个MyDelegate类型的委托实例m,并将其与一个方法
Show关联起来。最后,通过调用委托实例myDelegate来调用关联的方法Show,并传递一
个字符串参数Hello world。
问:委托使用的一般流程是怎样的?
答:使用委托的流程一般分4步骤:
1、定义委托类型:
首先,需要定义一个委托类型,该委托类型描述了要关联的方法的签名(即参数类型
和返回类型)。
2、创建委托实例:
使用定义的委托类型,可以实例化一个委托对象。实例化委托时,可以使用命名方法、
匿名方法或lambda表达式来关联具体方法。
3、关联方法:
将要调用的方法与委托实例关联起来。这可以通过直接赋值给委托实例,或者通过使
用委托合并运算符(+=)来将多个方法关联到同一个委托实例上。
4、调用委托:
通过调用委托实例来执行关联的方法。可以像调用普通方法一样使用委托实例,并传
递所需的参数。委托将自动调用所有关联的方法,并将参数传递给它们。
7、字符串替换: b的使用
The day after tomorrow is my wedding day.The row we are looking for is.row. number 10.
将单词"row"替换为"line":
The day after tomorrow is my wedding day.The line we are looking for is.line. number 10.
注意1: 是将单词"row"替换为"line",而不是将字符串"row"替换为"line"
注意2: \b属于“断言”的一种,只判断是否匹配,并不真正匹配。例如:^或S等。
Regex.Replace(input, @"\brow\b", "Line");
问:\b的判断标准是什么?
答:正则表达式中的 \b 是以 [0-9a-zA-Z_](数字、字母和下划线)为标准来判断是否为
单词边界,而不是以英文字典中单词的定义为判断依据。\b 在匹配边界时,并不考虑
单词的真实性或与字典的对应关系。它仅仅判断当前位置前面是一个单词字符,后面
是一个非单词字符,或者前面是一个非单词字符,后面是一个单词字符。
例如:“This is a_ look3 3a 6_7 99a_d” 使用正则表达式 @"\b.+?\b" 进行匹配,
则里面每一个都可以成为“单词”。
对于要检测真实的单词或正确的拼写,我们需要使用其他的方法,例如使用词典或自
然语言处理库等工具来进行处理。
练习: Hi,how are you?Welcome to our country!请提取出3个字母的单词。
注意3:见备注1.\b表示一边是单词字符,一边不是,不能两边都不是。
string input = "Hi,how are you?Welcome to our thy!";
Regex r = new Regex(@"\b[a-zA-Z]{3}\b");
MatchCollection mc = r.Matches(input);
foreach (Match m in mc)
{
Console.Write(m.Value);
}
引申:
若用[a-z]{3}匹配上面,查看一下每一个match后情况。
当第一次查找到匹配项后,下一次查找时会从当前匹配项的结束位置继续进行查找。具
体来说,会从当前匹配项的索引位置加上匹配项的长度开始。
练习:下面的结果是什么?
string input = "# ## ### #### ## ### # ###.";
MatchCollection mc = Regex.Matches(input, @"\b###\b");
foreach (Match m in mc)
{
Console.WriteLine(m.Value);
}
因为\b找不到,所以整个后面的也就无法匹配,结果是无法匹配。
8、问:什么是替换模式?
答:在C#的正则表达式中,替换模式(也称为替换引用或替换元字符)用于指定替换操
作的结果。常见的替换模式如下:
(1)$0: 引用整个匹配的字符串。
例如,`Regex.Replace(input, pattern, "$0 Replacement")`将匹配的字符
串替换为`Replacement`。
(2)$1, $2, $3等:引用第一个、第二个、第三个等匹配的捕获组。
例如,`Regex.Replace(input, pattern, "$1 $2")`将在匹配的第一个组和
第二个组之间插入一个空格。
(3)$$: 表示一个美元符号`$`。
注意:
如果需要在替换模式中使用`\`字符,应进行双重转义,即使用`\\`表示一
个`\`字符。
如果替换模式中的组号大于实际匹配的组数,将替换为空字符串。
可以使用变量来动态地设置替换模式。
特殊字符(例如`\`, `?`, `*`等)需要使用`\`进行转义,以便在替换模式
中直接使用。
例:"Hello, {name}!"对拼接"Hello, [name]!"
Regex.Replace(input, @"\{(\w+?)\}", "[$1]");
例:"Hello 123 World 456!"中大于200的数字用large,反之用small
string s = "Hello 123 World 456!";
Regex r = new Regex(@"\b\d+?\b");
s = r.Replace(s, delegate (Match m)
{
int n = Convert.ToInt32(m.Value);
if (n > 200)
{
return "large";
}
else
{
return "small";
}
});
Console.WriteLine(s);//Hello small World large!
五、分割拆分字符串
1、Regex.Split()用于以正则表达式模式为分隔符将输入字符串拆分成子字符串的数组。
Regex.Split() 方法接受两个参数:输入字符串和正则表达式模式。
它根据正则表达式模式将输入字符串拆分成多个子字符串,并返回一个字符串数组。
string input = "Hello,World!How are you?";
string[] s = Regex.Split(input, @"\w+");
foreach (string item in s)
{
Console.WriteLine(item + "----OK");
}
Console.WriteLine(s.Length);//6
上面以\w+为分隔符进行分割,有"",",","!"," "," ","?"共6个。返回数组。
重要:
分割可以用几种模式,比如|就可以选择两种或以上。
在分割是一次性分割,不是先进行A分割,再逐个对前面的B分割。
它是逐个向前,分别匹配上面的几种分割模式,成功就马上分割,然后继续向后
进行匹配分割,直到最后无字符时,分割结束。
2、Regex.Split()场景应用举例
Regex.Split()主要用于字符串的拆分和分割操作,结果存储在字符串数组中。常见的场景:
(1)分隔字符串:
使用指定的正则表达式模式作为分隔符,将字符串拆分为多个子字符串。
例如,按照逗号、空格、换行符等特定字符进行拆分。
(2)提取单词或标记:
根据某种特定的模式,将字符串拆分为单词或标记,以用于语言处理、文本分析或标记
化等场景。例如,提取句子中的单词。
string input = "This is a sample sentence.";
string[] s = Regex.Split(input, @"\s+");
foreach (string item in s)
{
Console.WriteLine(item + "----OK");
}
Console.WriteLine(s.Length);//5
上面提取单词,但最后一个为sentence.多了一个.
若修改成string[] s = Regex.Split(input, @"\s+|.");则为6,最后的.分割后最末
一个元素为""
提示:分割中有空串""的情况很多,可以用谓词进行消除。
s = s.Where(x => !string.IsNullOrEmpty(x)).ToArray();
(3)解析和处理日志文件:
当需要从日志文件中提取特定信息时,可以使用 Regex.Split()方法按照特定的模式
将日志行拆分成组件部分,以便进一步处理和分析。
string logs = "2023-07-16 | INFO | This is an information message" + Environment.NewLine +
"2023-07-16 | ERROR | An error occurred: NullReferenceException" + Environment.NewLine +
"2023-07-16 | WARN | Warning: Resource limit exceeded";
string[] s = Regex.Split(logs, @"\s?\|\s?");
foreach (string item in s)
{
Console.WriteLine(item + "----OK");
}
Console.WriteLine(s.Length);//7
(4)分割和处理文件路径:
当需要获取文件路径中的目录、文件名或文件扩展名时,可以使用 Regex.Split() 方
法根据特定的分隔符(如反斜杠或斜杠)将文件路径拆分成不同的部分。
string logs = @"C:\Program Files\MyApp\test.txt";
string[] s = Regex.Split(logs, @"\\");
foreach (string item in s)
{
Console.WriteLine(item + "----OK");
}
Console.WriteLine(s.Length);//4
(5)分隔和处理文本数据:
在文本处理任务中,例如解析 CSV、TSV 或其他结构化文本数据时,Regex.Split()方
法可以使用正则表达式模式拆分行或字段。
string logs = "John,Doe,30" + Environment.NewLine +
"Jane,Smith,25";
string[] s = Regex.Split(logs, @",|\r\n");
foreach (string item in s)
{
Console.WriteLine(item + "----OK");
}
Console.WriteLine(s.Length);//6
性能考虑:
如果需要处理大量的数据或频繁进行分割操作,可以考虑使用更简单的字符串处理方
法(如 String.Split() 方法)来提高性能
3、分割与捕获组的结合
小心:
使用捕获组不能直接进行分割操作。捕获组的主要目的是提取匹配的子字符串,
而不是将字符串分割为数组。简言之:两者结合时是提取操作。
问:下面的提取的字串是哪些?共有多少元素?
string s = "Name: John, Age: 30, Gender: Male";
string[] parts = Regex.Split(s, @"\b(\w+): (\w+\b)");
foreach (string part in parts)
{
Console.Write(part + "-");
}
Console.WriteLine("\n" + parts.Length);
答,-Name-John-, -Age-30-, -Gender-Male--,共有10个元素。
因为当分割模式中包含捕获组时,Regex.Split方法会将捕获组的内容作为元素,
并将匹配到的部分作为分隔符进行分割。
(重点)分割过程如下:
(1)初始时,字符串为 "Name: John, Age: 30, Gender: Male"。
(2)根据正则表达式模式 `\b(\w+): (\w+\b)` 进行匹配,找到第一个匹配项
"Name: John"。
这个匹配项分割前的部分为 "",在分割结果中会出现一个空字符串元素。
后面部分为", Age: 30, Gender: Male"
捕获组 1 匹配到的键是 "Name",捕获组 2 匹配到的值是 "John",它们分
别成为分割结果的元素。进入前面的元素中,即当前数组变成:
["","Name","John"]共3个元素
(3)继续处理剩下的字符串 ", Age: 30, Gender: Male"。
匹配上"Age: 30",它分割前的部分为", ",加入前面的数组成为4个元素数组。
捕获组 1 匹配到的键是 "Age",捕获组 2 匹配到的值是 "30",它们成为分
割结果的两个元素。并进入4个元素的数组中成为6个:
["","Name","John",", ","Age","30"]
(4)重复前面的分割与匹配过程,最终10个元素:
["", "Name", "John", ", ", "Age", "30", ", ", "Gender", "Male",""]
分割结果的元素是根据匹配项和分隔符两者共同决定的。在这个过程中,捕获组
的内容确实不会直接出现在分割结果中,它们只作为正则表达式的一部分来进行
匹配和提取。
例1:正常分割
string s = "Alpha123Beta456Gamma789";
string[] p1 = Regex.Split(s, @"\d+");
for (int i = 0; i < p1.Length; i++)
{
Console.Write(p1[i] + "-");//Alpha-Beta-Gamma--
}
Console.WriteLine("\n" + p1.Length);//4
上面正常分割为["Alpha","Beta","Gamma",""],最末尾将会有空串元素。
例2:分割与捕获组结合
string s = "Alpha123Beta456Gamma789";
string[] p1 = Regex.Split(s, @"(\D+)(\d+)");
for (int i = 0; i < p1.Length; i++)
{
Console.Write(p1[i] + "-");//-Alpha-123--Beta-456--Gamma-789--
}
Console.WriteLine("\n" + p1.Length);//10
小心:有10个元素,第二次对"Beta456Gamma789"分割,前面又会产生空串.
例3:继续理解下
string s = "Alpha123Beta456Gamma789";
string[] p1 = Regex.Split(s, @"\D+(\d+)\D+(\d+)\D+(\d+)");
for (int i = 0; i < p1.Length; i++)
{
Console.Write(p1[i] + "-");//-123-456-789--
}
Console.WriteLine("\n" + p1.Length);//5
先整个匹配,分割成两个空串,一个最前一个最后,然后捕获组有3个,加这两个空
串中间。
六、反向引用
1、在正则表达式替换模式中,通过$1、$2、...来引用分组信息。
而在正则表达式匹配模式中,引用分组信息通过过\1、\2、...来引用分组信息。
这种引用方式就是“反向引用”。
“引用分组信息”,其实就是将分组匹配到的信息保存起来,供后续使用。
问:正则中有几种模式?
答:常用4模式:
1. 匹配模式(Match Pattern):
使用正则表达式匹配一个字符串中的内容。可以使用 `Regex.Match`
或 `Regex.Matches` 方法来进行匹配。这些方法会返回匹配到的结果,可以通过
`Match` 对象或 `MatchCollection` 对象来获取匹配项的详细信息。
2. 替换模式(Replace Pattern):
使用正则表达式进行字符串的替换。可以使用 `Regex.Replace` 方法,将匹
配到的内容替换为指定的字符串或通过替换操作来修改字符串。
3. 分割模式(Split Pattern):
使用正则表达式作为分隔符,将字符串拆分为多个子串。可以使用
`Regex.Split` 方法进行字符串分割操作。
4. 验证模式(Validation Pattern):
使用正则表达式验证输入字符串是否符合特定的模式或格式。可以使用
`Regex.IsMatch` 方法来判断字符串是否匹配正则表达式模式。
每种模式都有不同的用途和方法来实现。根据具体的需求,选择合适的模式和方
法来操作正则表达式可以实现不同的功能。
2、什么是反向引用?
答:反向引用是一种功能,它允许在正则表达式模式中引用之前捕获的内容。使用反
向引用可以简化匹配和替换操作,以及在正则表达式中实现更复杂的模式匹配。
在正则表达式中,通常使用圆括号来创建捕获组。当你在正则表达式中使用圆括
号框起一部分模式时,该部分的匹配结果会被保存到一个编号的捕获组中,捕获
组的编号从左到右依次递增。
要在正则表达式模式中引用之前捕获的内容,可以使用反向引用。反向引用的语
法是 \n,其中 n 是一个正整数,表示引用编号为 n 的捕获组的内容。
例:
"hello hello world world"中使用Regex.Matches(input, @"\b(\w+)\s+\1\b")
其中\1 是反向引用,引用第一个捕获组中的内容。结果:
hello hello
world world
因为正则表达式模式中的捕获组被反向引用,所以只有当重复的单词出现时才会
匹配成功。
反向引用只能引用在之前出现的捕获组,而不能引用在之后的捕获组。
引用不存在的捕获组时,会导致正则表达式的匹配失败或引发异常,具体情况取
决于使用反向引用的方式和上下文。
3、练习
(1)将"杨杨杨杨杨中中中中科科科科科"变成"杨中科"
string s = Regex.Replace(input, @"(.)\1+", @"$1");
(2)将"我...我我..我我我我....爱爱爱.爱.爱...你你...你你你你.."变成"我爱你"
string s = Regex.Replace(input, @"([^.])+(\.)+\1+\2+\1*\2*", @"$1");
下面是通用的:
string s = Regex.Replace(input, @"([^.])+(\.)+(\1*\2*)*", @"$1");
(3)[英汉词典TXT格式.txt]中,提取所有的带叠词的英文单词比如sheep、tool、 proof、 queen、professor、Zoo、eel...
string f = @"E:\英汉词典.txt";
foreach (string line in File.ReadLines(f))
{
string[] s = line.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
if (Regex.IsMatch(s[0], @"(.)\1+"))
{
Console.WriteLine(s[0]);
}
}
问:上面换成string line in File.ReadAllLines(f)后有什么不同?
答:File.ReadAllLines(f)替代File.ReadLines(f)会导致两种不同的行为和性能
差异。
(1). `File.ReadLines(f)`:这个方法返回一个 `IEnumerable
它提供了一个延迟加载的行序列。这意味着在 `foreach` 循环中,每次
迭代只加载一行,可以减少内存的使用。这在处理大型文件时很有用,
因为它避免了一次性加载整个文件到内存中。
(2). `File.ReadAllLines(f)`:这个方法返回一个字符串数组,包含文件中
的所有行。整个文件会被一次性读取到内存中,并返回一个完整的字符
串数组。这在文件较小或需要在循环中多次访问文件内容时更适用。
用File.ReadAllLines(f)替代 File.ReadLines(f),会在内存中一次性加载
整个文件的内容。这在文件较小的情况下可能没有太大问题,但如果处理大
型文件,可能会导致内存占用较高。
性能方面,File.ReadLines(f)的性能相对更好,因为它在需要时才加载行,
而不是一次性加载整个文件。这对于处理大型文件或需要逐行读取的情况来
说,可以节省内存并提高性能。
注意:不论使用哪种方法,读取文件的行都是按照顺序进行的。首先读取第一行,
然后第二行,然后第三行,以此类推。
只是readlines没有读出总行数,故它是不能用于for循环中。
注意:当你使用 foreach 语句来迭代 File.ReadLines() 返回的行序列时,对于
大型文件或者具有复杂行结构的文件,可能会出现多线程并发读取的情况,导致
读取顺序在某些情况下出现错乱。这并不是因为 File.ReadLines() 方法本身返
回的行序列是乱序的,而是因为并发读取引起的顺序混乱。
对于单线程处理的大型文件,File.ReadLines() 方法仍然会按照文件中实际的
行顺序逐行读取文件内容,并正确保持顺序。
(4)从一段文本中提取所有的叠词:
a.“浩浩荡荡、清清白白”、 ...AABB
b.“如火如荼”、“愈演愈烈”、...AXAY
string f = @"E:\失去的森林.txt";
foreach (string line in File.ReadLines(f))
{
MatchCollection mc = Regex.Matches(line, @"(\w)\1(\w)\2|(\w)\w\3\w");
foreach (Match m in mc)
{
Console.WriteLine(m.Value);
}
}
七、UBB代码
1、问:什么是ubb代码?
答:UBB 简称为 Universal Bulletin Board(通用公告板)代码,是一种用于在论坛和社
区中格式化和标记文本的标记语言。UBB 代码可用于在帖子、评论或签名中添加各种
元素和样式,例如粗体、斜体、链接、图像等。
使用UBB代码的主要目的是在论坛或社区中格式化和标记文本,以增强文本的可读性和
呈现效果。
常用的 UBB 代码:
1. 文本样式:
`[b]粗体文本[/b]`:使文本以粗体显示。
`[i]斜体文本[/i]`:使文本以斜体显示。
`[u]下划线文本[/u]`:给文本添加下划线。
2. 链接:
`[url]http://www.example.com[/url]`:创建一个链接到指定网址的文本。
`[url=http://www.example.com]点击这里[/url]`:创建带有自定义文本的链接。
3. 图片:
`[img]http://www.example.com/image.jpg[/img]`:插入指定网址的图像。
`[img=200x200]http://www.example.com/image.jpg[/img]`:设置图像的宽度和高度。
4. 引用:
`[quote]引用的文本[/quote]`:引用一段文本。
`[quote=作者]引用的文本[/quote]`:引用一段文本并指定作者。
UBB 代码的功能非常丰富,不同的论坛可能会支持不同的 UBB 代码。可以在论坛的
帮助文档中查找更多有关如何使用 UBB 代码的信息。
2、练习:开发UBB翻译器。实现 [B]、 [URL]就可以。提供Winform界面,输入UBB代码,转换
为html内容的字符串,然后赋值给WebBrowser控件的DocumentText属性。
[b]fff[/b]→fff
[url=http://www.baidu.com]百度[/url]→百度
多次Replace,每次处理一个替换。注意:[是元字符,需要转义
测试文本:
你好,我发现一个[b]新网站[/b],[b]大家[/b]来看呀[url=http://www.qq.com]秋
秋[/url],另外一个有时间也可以看看[url=http://www.rupeng.com]如鹏[/url],还
有[url=http://www.itcast.cn]传智播客[/url]。吼吼!
private static void Main(string[] args)
{
string ubb = "你好,我发现一个[b]新网站[/b],[b]大家[/b]来看呀[url=http://www.qq.com]秋秋[/url],另外一个有时间也可以看看[url=http://www.rupeng.com]如鹏[/url],还有[url=http://www.itcast.cn]传智播客[/url]。吼吼!";
string html = ConvertUbbtoHtml(ubb);
Console.WriteLine(html);
Console.ReadKey();
}//
private static string ConvertUbbtoHtml(string ubb)
{
ubb = Regex.Replace(ubb, @"\[url=(.+?)\](\w+?)\[/url\]", @"$2");
ubb = Regex.Replace(ubb, @"\[b\](.*?)\[/b\]", @"$1");
return ubb;
}
使用webbrowse控件
private void Form1_Load(object sender, EventArgs e)
{
string ubb = "你好,我发现一个[b]新网站[/b],[b]大家[/b]来看呀[url=http://www.qq.com]秋秋[/url],另外一个有时间也可以看看[url=http://www.rupeng.com]如鹏[/url],还有[url=http://www.itcast.cn]传智播客[/url]。吼吼!";
string html = ConvertUbbtoHtml(ubb);
WebBrowser wb = new WebBrowser();
wb.Dock = DockStyle.Fill;
this.Controls.Add(wb);
wb.DocumentText = html;
}
private string ConvertUbbtoHtml(string ubb)
{
ubb = Regex.Replace(ubb, @"\[url=(.+?)\](\w+?)\[/url\]", @"$2");
ubb = Regex.Replace(ubb, @"\[b\](.*?)\[/b\]", @"$1");
return ubb;
}
将下面ubb代码转html代码
天哪,今天太热了。听说过[size=7][color=#ff0000][b][u]杨中科[/u][/b][/color]
[/size]吗?他有个网站叫: [url=http://www.rupeng.com]茹鹏网[/url]
[b]传智播客[/b]
private string ConvertUbbtoHtml(string ubb)
{
//url->href
ubb = Regex.Replace(ubb, @"\[url=(.+?)\](\w+?)\[/url\]", @"$2");
//[b]->
ubb = Regex.Replace(ubb, @"\[b\](.*?)\[/b\]", @"$1");
//size->
ubb = Regex.Replace(ubb, @"\[size=(\d+?)\](.*?)\[/size\]", @"$2");
//color->
ubb = Regex.Replace(ubb, @"\[color=(.+?)\](.*?)\[/color\]", @"$2");
//[u]->
ubb = Regex.Replace(ubb, @"\[u\](.*?)\[/u\]", @"$1");
return ubb;
}
八、敏感词处理
1、敏感词处理过程
使用正则表达式进行敏感词过滤可以通过以下几个步骤:
(1)创建敏感词列表:
首先,你需要准备一个敏感词列表,其中包含你要过滤的敏感词。可以将这些敏
感词保存在一个文本文件中,每个敏感词占一行,或者将它们保存在一个数组或
集合中,方便后续处理。
(2)构建正则表达式模式:
使用准备好的敏感词列表,构建一个正则表达式模式。在模式中,使用管道
符(`|`)将所有敏感词连接起来,表示匹配任何一个敏感词。
string[] sensitiveWords = { "敏感词1", "敏感词2", "敏感词3" };
string pattern = string.Join("|", sensitiveWords);
上述代码将会生成一个正则表达式模式,形如`敏感词1|敏感词2|敏感词3`。
(3)使用正则表达式进行过滤:
根据你的需求,选择适当的方式使用正则进行过滤。以下是两个常用的方式:
使用`Regex.Replace`方法进行替换:将敏感词替换为指定的内容
(如`*`或其他敏感词替换规则)。
string input = "这是一段包含敏感词的文本,敏感词1和敏感词2都需要被过滤。";
string filteredText = Regex.Replace(input, pattern, "***");
Console.WriteLine(filteredText);
使用`Regex.IsMatch`方法进行匹配:判断文本中是否包含敏感词。
string input = "这是一段包含敏感词的文本,敏感词1和敏感词2都需要被过滤。";
bool containsSensitiveWords = Regex.IsMatch(input, pattern);
Console.WriteLine(containsSensitiveWords);
运行上述代码后,你将得到过滤后的文本或判断是否包含敏感词的结果。
注意,实际应用中,可能需要考虑更复杂的情况,例如大小写不敏感、部分匹配等。
2、做一个WinForm页面,放一个多行文本框,点击按钮对文本框中的内容当作帖子进行判
断。文件路径写死就行,比如c:/网站过滤词(部分).txt。做网站的难点不在页面,
难点仍然是后台C#代码的编写。
用File.ReadAllLines()、List
bannedList,依次处理文件的各行,用=分割每一行,判断第二部分,如果是{MOD}就将
第一部分加入modList,如果是{BANNED}就将第一部分加入bannedList。用ToArray将两
个List转换为数组,然后用string.Join拼接成“安定片|罢餐|百{2}家{2}乐”,然后将
“{”替换成“.{1,”,最后用IsMatch判断是否含有Banned词需要审核汇,如果是的话就禁
止发帖,如果含有mod词汇,则提示。
private void button1_Click(object sender, EventArgs e)
{
StringBuilder sbMode = new StringBuilder();
StringBuilder sbBanned = new StringBuilder();
string[] s = File.ReadAllLines(@"E:\敏感词");
foreach (string s2 in s)
{
string[] m = s2.Split(new char[] { '=' }, StringSplitOptions.RemoveEmptyEntries);
if (m[1] == "{MOD}")
{
sbMode.AppendFormat("{0}|", m[0]);
}
else if (m[1] == "{BANNED}")
{
sbBanned.AppendFormat("{0}|", m[0]);
}
}
sbMode.Remove(sbMode.Length - 1, 1);
sbBanned.Remove(sbMode.Length - 1, 1);
string t = textBox1.Text.Trim();
if (Regex.IsMatch(t, sbBanned.ToString()))
{
MessageBox.Show("禁止发贴");
}
else if (Regex.IsMatch(t, sbMode.ToString()))
{
MessageBox.Show("需人工审核");
}
else
{
MessageBox.Show("可以发贴");
}
}
StringBuilder AppendFormat(string format, params object[] args)
用于将格式化的字符串追加到 StringBuilder 对象的末尾。
用法类似Consle.WriteLine()中的格式。
sb.AppendFormat("My name is {0}, I'm {1} years old.", "John", 25);
九、断言
1、问:正则中的断言是什么?
答:在C#的正则表达式中,断言(assertion)指的是一种特殊的正则语法,用于在匹
配时对位置进行条件的检查,而不进行字符的实际匹配。
断言用`(?...)`的形式表示,其中`...`是要检查的条件。断言可以放在匹配的位置之
前或之后,以确保特定的条件得到满足。
根据断言发生的位置和断言的结果,断言可以分为以下两类:
(1)先行断言(Lookahead Assertion):
先行断言在当前位置之后进行条件判断。
正向先行断言(Positive Lookahead Assertion):
在当前位置之后,判断条件必须满足,才继续向后匹配。
反向先行断言(Negative Lookahead Assertion):
在当前位置之后,判断条件不能满足,才继续向后匹配。
(2)后行断言(Lookbehind Assertion):
后行断言在当前位置之前进行条件判断。
正向后行断言(Positive Lookbehind Assertion):
在当前位置之前,判断条件必须满足,才继续向前匹配。
反向后行断言(Negative Lookbehind Assertion):
在当前位置之前,判断条件不能满足,才继续向前匹配。
正向先行断言(Positive Lookahead Assertion):
string input = "apple123 applexxx";
MatchCollection mc = Regex.Matches(input, @"apple(?=\d+)");
foreach (Match m in mc)
{
Console.Write(m.Value + "_"); //apple_ 第一个
}
反向先行断言(Negative Lookahead Assertion):
string input = "apple123 applexxx";
MatchCollection mc = Regex.Matches(input, @"apple(?!\d+)");
foreach (Match m in mc)
{
Console.Write(m.Value + "_");//apple_ 第二个
}
注意:若错写为@"apple(?!=\d+)"则会匹配两个,因为多了一个=
正向后行断言(Positive Lookbehind Assertion)示例:
string input = "123apple xxxapple";
MatchCollection mc = Regex.Matches(input, @"(?<=\d+)apple");
foreach (Match m in mc)
{
Console.Write(m.Value + "_");
}
反向后行断言(Negative Lookbehind Assertion)示例:
string input = "123apple xxxapple";
MatchCollection mc = Regex.Matches(input, @"(?
同样,若错写为 @"(?
技巧:肯定就是=,否定就是把=替换成!
后向需要<,小的方向朝向句首(左侧)。
2、问:先行后行、肯定否定、断言各指什么?
答:正向表示肯定,负向表示否定。
前向与先行一个意思,表示字符串右侧的方向
后向与后行一个意思,表示字符串左侧的方向。有时称后顾。
3、问:断言在正则中匹配时游标是怎么变化的?
答:断言匹配时游标的变化取决于断言的类型。
有两种常用的断言类型:先行断言和后行断言。
(1)正向断言(Positive Lookahead Assertion):
正向断言用于指定在当前位置后面必须满足一定条件才能匹配。
它的语法形式是`(?=...)`。当正向断言匹配时,游标不会向前移动,它只是检查当
前位置之后是否满足断言条件。
例如,使用正向断言来匹配一个数字后面跟着一个字母的情况:
string input = "1A 2B 3C";
MatchCollection matches = Regex.Matches(input, @"\d(?=[A-Za-z])");
foreach (Match match in matches)
{
Console.Write(match.Value + "_");//1_2_3_
}
这里的游标只检查了数字后面的位置是否满足断言条件,不会移动,不会包含匹配结
果中的字母。
(2)负向断言(Negative Lookahead Assertion):
负向断言用于指定在当前位置后面不能满足一定条件才能匹配。
它的语法形式是`(?!...)`。当负向断言匹配时,游标不会向前移动,它只是检查当
前位置之后是否不满足断言条件。
例如,使用负向断言来匹配一个非空格字符后面不跟着数字的情况:
string input = "A 1 B 2 C";
MatchCollection matches = Regex.Matches(input, @"\D(?!\d)");
foreach (Match match in matches)
{
Console.Write(match.Value + "_");//A_ _B_ _C_
}
共有5个匹配,比如B前面的空格也满足。
游标只检查了非空格字符后面的位置是否不满足断言条件,不会包含匹配结果中的数字。
总结:断言在匹配时不会改变游标的位置,它只是在特定的位置上进行条件的检查,以确
定是否发生匹配。在断言中的匹配结果将不会包含在最终的匹配结果中。
问:\b属于断言吗?
答:是的。因此,在使用\b词边界断言时,游标是不会移动的。\b断言用于匹配单词边界,
即字符是单词字符(字母、数字、下划线)和非单词字符之间的位置。但它本身不会
消耗任何字符,也不会改变游标的位置。
问:^与$属于断言吗?
答:^和$并不被视为断言(assertion)。它们被称为锚定符号(anchor),用于限定模式
的位置,而不是进行条件检查。
当正则表达式的模式中使用^时,游标将被置于字符串的开头位置,并进行匹配操作。
如果匹配成功,游标将保持在开头位置。如果不匹配,则继续尝试匹配字符串的下
一个位置。
当正则表达式的模式中使用$时,游标将被置于字符串的结尾位置,并进行匹配操作。
如果匹配成功,游标将保持在结尾位置。如果不匹配,则继续尝试匹配字符串的前
一个位置。
4、面试题:抓取招聘信息。
只抓取职位的超链接的href、标题,找职位超链接的“模式”
从https://www.58.com/ppeseoll49665/抓取职位,找规律。
使用开发人员工具,可能看到的源代码不准确,一定要用浏览器的源码模式。
把源代码复制到notepad++中,看一下规律:
前面是相同的,只有职位XXX是变化的。
string web = "https://www.58.com/ppeseoll49665/";
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
wc.Headers.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36");
string html = wc.DownloadString(web);
string p = @"(?<=).*?(?=)";
MatchCollection mc = Regex.Matches(html, p);
foreach (Match m in mc)
{
Console.WriteLine(m.Value);
}
Console.WriteLine(mc.Count);
说明:
1,可能有乱码,所以请根据需要设置编码格式。
2,该网站会对WebClient进行监测,需要伪装 User-Agent:尝试将 WebClient 的
User-Agent 设置为常见的浏览器 User-Agent,以模拟正常的浏览器请求。
“User-Agent” 字段是用来告诉服务器发送请求的客户端的类型和版本信息,以便服务
器能够根据不同客户端作出适当的响应。上述代码中给定的字符串是模拟 Chrome 浏
览器在 Windows 10 操作系统上的 User-Agent 字段。
可以利用Fiddler进行跟踪,得出请示头User_Agent的具体东西,直接copy即可.
5、问:下面匹配的结果是什么?
string s = "Hello World!";
MatchCollection mc = Regex.Matches(s, @"\b\w+(?=[aeoui])\b");
foreach (Match m in mc)
{
Console.Write(m.Value + "_");
}
Console.WriteLine("\n" + mc.Count);
答:这题易回答为Hell,实则为空,什么也匹配不上。
通常情况下,断言是无法重复使用的。断言是一种非捕获的括号表达式,它可以用来
限定匹配的位置,但每个断言只能出现一次。
(?=[aeoui])\b这是重复使用,但(?=[aeoui]\b)不是重复使用,是两者组合。
重复使用时,是无效表达,结果是无法预料的,可能无法匹配,可能匹配多个。
就如前面1中介绍断言时(?
6、使用正则表达式建议
(1)不要“过渡”使用正则表达式,简单的操作能用字符串方式直接操作的就用字符串
方式来操作。例如: IndexOf()、StartsWith()EndWith()、Path.GetFileName()、
因为很多基本的字符串操作方式已经有很高效的算法了,用了正则表达式反而效
率低下。
(2)如果多次使用同样的正则表达式,则缓存该对象或者使用new Regex对象的方式
(3)正则表达式是对字符串操作的,不要试图用正则表达式来验证字符串的意义。
比如: 验证是否为闰年,这种操作用程序来操作更高效,更容易。
十、委托
1、问:为什么有委托?
答:通俗地说,委托就如律师、串串、委托人一样可单独帮助做事,而非只传递东西。
引入委托的目的是为了解决一些常见的编程问题,并提供更灵活的代码组织和可重用性。
下面是使用委托的常见场景和优势:
1. 回调机制:
委托使得回调函数的实现更加简单和直观。通过将方法作为委托参数传递给其他
方法,可以在特定的条件满足时调用该方法,从而实现回调功能。
2. 事件处理:
在许多应用程序中,需要响应用户操作或系统事件。通过使用委托,可以将方法
注册为事件的处理程序,当事件发生时,相应的方法会被调用,实现事件驱动的
编程模型。
3. 多播委托:
委托支持使用`+=`运算符来合并多个方法,这样可以创建一个包含多个方法引用的
委托对象。调用多播委托时,会依次调用其中包含的所有方法。这样可以方便地实
现事件触发时调用多个处理程序的功能。
4. 扩展性和可重用性:
通过使用委托,可以将方法从实际的业务逻辑中解耦出来,使得代码更加模块化和
可重用。可以将常用的逻辑抽象成委托,然后将不同的具体实现传递给委托,以实
现不同的行为。
5. 函数式编程:
委托使得C#具备了一些函数式编程的特性。可以将方法作为参数进行传递和操作,
实现更高级的编程技巧和模式,如函数组合、柯里化等。
总的来说,委托提供了一种机制,使得方法可以像任何其他的数据类型一样被传递、
存储和调用,从而增加了代码的灵活性和可重用性。它是C#语言中一个强大而重要
的特性,广泛应用于各种编程场景中。
问:委托的本质是什么?
答:委托是一种类型,它可以存储对其他方法的引用并允许调用这些方法。它可以被看作
是一种函数指针,它可以在运行时动态地指向不同的方法。
委托的本质可以理解为它是一个对象,它包含了对特定方法的引用。委托类型定义了
方法的签名,它指定了可被委托引用的方法所应具有的参数类型和返回类型。通过创建委
托对象并将其指向某个方法,我们可以通过委托对象来调用该方法,就好像直接调用该方
法一样。委托的本质概括如下:
1. 委托是一种类型,它定义了方法的签名。
2. 委托对象可以存储对方法的引用。
3. 委托对象可以在运行时动态地指向不同的方法。
4. 通过委托对象,可以调用所引用的方法。
委托有很多用途,其中一个重要的应用场景是事件处理。通过定义委托类型和相应的
事件,我们可以将事件与特定的处理方法关联起来,当事件发生时,委托对象可以调用被
关联的处理方法。
总结:委托是一种带有特定方法签名的类型,它允许存储对其他方法的引用,并可以
在运行时动态地调用这些方法。委托可以被看作是一种函数指针,提供了灵活和可重用性
的方法调用机制。
问:委托的微观描述是什么?
答:在微观层面上,委托可以被认为是一个类实例,可以调用特定方法的对象。委托本身
是由编译器自动生成的一个类,它会在编译时根据委托的签名创建。每个委托类型都
派生自`System.MulticastDelegate`类,它是一个抽象基类。
在底层实现中,委托包含以下重要的部分:
1. Target(目标):
委托的目标是一个实例方法,它将在委托被调用时执行。委托将对目标方法进行
调用,可以是静态方法或实例方法。如果目标方法是一个实例方法,则委托必须
通过实例化的对象来调用。
2. Method(方法):
委托的方法是被委托引用的实际方法。
3. Invocation List(调用列表):
委托可以包含一个或多个方法的列表。当委托被调用时,会逐个调用列表中的方
法。这使得多个方法可以通过委托进行统一调用。
4. Delegate Type(委托类型):
委托类型定义了委托对象可以引用的方法的签名。它规定了方法应该具有的参数
和返回类型。委托类型在编译时确定,并在运行时使用。
在运行时,委托对象就是对这些信息的封装。当我们通过委托对象调用委托时,它会
查找目标方法,并将参数传递给该方法。如果委托包含多个方法,它会按照调用列表中的
顺序依次调用这些方法。
委托可以被视为一个带有目标、方法、调用列表和类型信息的对象。它提供了一种机
制,使得我们可以在运行时引用和调用不同的方法,从而带来更大的灵活性和可重用性。
2、委托是一种数据类型,象类一样(可以声明委托类型变量)。
方法参数可以是int,string,类类型
void M1(int n){}
void M2(string s){}
void M3(Person p){}
那么能不能把方法也作为参数进行传递?
void M4(M1 method){ method();}??能把方法作为参数吗?
如果能,那么把方法作为参数的意义何在?
使用普通变量的时候是直接取值,或赋值。
而使用委托变量的时候,我们还可以直接调用。
定义委托跟类一样。在定义委托时,需要指定方法的签名,包括参数列表和返回类型。
然后可以创建委托的实例,并将一个或多个方法与该委托实例关联起来。这样,通过
调用委托实例,可以间接调用与之关联的方法。
技巧:如何让人一眼识别是委托类型或变量?
答:(1)委托名常以Delegate作为后缀,以示其是一种委托类型。
例如:ActionDelegate、EventHandlerDelegate。
(2)使用具有描述性和清晰含义的单词或短语作为委托名。这能够使其用途和功能
快速显现。例如:CalculateSumDelegate、SendDataDelegate。
(3)如果委托只表示一种回调函数的签名,可以使用Callback作为后缀。
例如:ProcessDataCallback。
(4)一般情况下,采用驼峰命名法,首字母小写。例如:calculateSumDelegate。
private static void Main(string[] args)
{
Mydelegate mydelegate = new Mydelegate(M1);//实例化委托对象
//比较Myclass myclass=new Myclass();//实例化类
mydelegate();//无参,若是有参则mydelegate(参数)
//比较myclass.show();
Console.ReadKey();
}
public delegate void Mydelegate();//定义委托类型
//比较 public class Myclass{}//定义类
private static void M1()
{ Console.WriteLine("无参没有返回值的委托"); }
问:如何使用委托?
答:声明委托的方式:
delegate 返回值类型 委托类型名(参数);
比如delegate void StringProcess(string s);
注意:除了前面的delegate,剩下部分和声明一个函数一样,但是StringProcess
不是函数名,而是委托类型名。
存储什么样的方法就声明什么类型(方法参数与返回值)的委托。
声明的委托是一种类型,就像int、Person一样,如果要用的话还要声明委托类型
的变量,声明委托类型变量的方式:StringProcess f1;
将委托类型变量指向函数 StringProcess sp = new StringProcess(SayHello),
这样就可以像调用普通函数一样把sp当成函数用了。委托可以看做是函数的指针。整
数可以用整数变量指向它,对象可以用对象变量指向它,函数也可以用委托变量指向
它。
和直接调用函数的区别:用委托就可以指向任意的函数,哪怕是之前没定义的都
可以,而不使用受限于那几种。比如匿名函数,lambda等。
将委托类型变量指向函数还可以简化成StringProcess sp = SayHello,编译器
帮我们进行了new。但是不能sp=PrintIt(),因为这样就成了函数调用。
可以使用委托变量直接指向一个方法,而无需显式地创建委托对象。当你将一
个方法分配给一个委托变量时,C#会隐式地创建一个委托对象。也可以通过显式地
使用new关键字来创建委托对象,然后再将方法分配给它。
无论是隐式地创建委托对象还是显式地创建委托对象,都可以在C#中使用委托
来引用方法。隐式创建委托对象的语法更简洁,因此在实际开发中更为常见。
问:委托的定义一般放在什么地方?
答:类外部定义的委托在整个命名空间中可见和可访问,而类内部定义的委托只在
当前类中可见和可访问。方法内部不允许定义委托。选择在何处定义委托取决
于需要委托的可见性和可访问性的范围。
注意:当在类内定义委托为public或private时区别不大。因为它只是一种数
据类型,而不是实例。数据类型的在类外的可见与不可见,不会对类内本身的
实例产生任何影响。
问:什么是类库?
答:类库是一组已编写好的可重用代码,通常以预编译的形式提供给开发人员使用。
类库中包含了一系列类、接口、和其他相关类型,它们提供了特定功能或解决特定
问题的方法和属性。类库有以下几个用处:
1. 代码重用:
类库可以被多个应用程序共享和重复使用,避免了重复编写相同功能代码的工
作。通过引用类库,开发人员可以直接使用其中的类和方法,提高开发效率。
2. 提供功能扩展:
类库可以用于为现有的应用程序添加新的功能。通过引入具有特定功能的类库,
开发人员可以轻松地扩展现有应用程序的功能,而无需从头开始编写所有代码。
3. 简化开发流程:
使用类库可以简化开发流程,因为它们提供了许多现成的功能和方法,开发人
员可以直接使用而不必从零开始编写。这样可以提高开发效率,并减少错误和
bug的可能性。
4. 提供标准化和共享:
类库可以提供标准化的解决方案和共享的开发资源,让开发人员在开发过程中
能够遵循一致的规范和标准,提高代码的质量和可维护性。
常见的类库包括.NET Framework中的类库,例如ASP.NET、Windows Forms和ADO.NET
等。此外,还有第三方类库,如Json.NET、Entity Framework、Newtonsoft.Json等,
它们提供了各种功能和特性,可以帮助开发人员快速开发应用程序。
问:类库与命名空间的区别是什么?
答:类库(Library)和命名空间(Namespace)作为两个不同的概念存在,区别如下:
1. 定义和功能:
- 类库(Library)是一组已编写好的可重用代码,它包含了一系列类、接口和其
他相关类型,提供了特定功能或解决特定问题的方法和属性。类库是一个可
独立使用的模块,可以被其他应用程序引用和调用。
- 命名空间(Namespace)是用于组织和管理类、结构体、接口、枚举和其他相关
类型的一种机制。它提供了逻辑上的分组,用于避免命名冲突,并将相关的
类型组织在一起。命名空间没有直接提供功能性代码,而是用于组织和管理
代码结构。
2. 作用和目的:
- 类库的主要目的是提供可重用的代码,以便多个应用程序可以共享和重复使用。
它们可以包含通用的功能、算法、数据结构等,供开发人员在应用程序中直
接调用和使用。
- 命名空间的作用是提供一种逻辑上的组织结构,以管理和组织代码。它提供了
一种避免命名冲突的机制,将相关类型组织在一起,使代码更加清晰和可维
护。命名空间还可以帮助开发人员更好地组织自己的代码和项目结构。
3. 使用方式:
- 类库可以作为可引用的模块,通过添加对应的引用,将其导入到应用程序中。
开发人员可以直接使用类库中的类和方法,以实现特定功能。
- 命名空间使用关键字`namespace`定义,并通过命名空间的名称和层次结构来访
问其中的类型。开发人员可以使用`using`语句引入命名空间,以便在代码中
直接使用其中的类型,而不用完全限定类型的名称。
类库经常使用命名空间作为组织和管理其中的类型,并使用命名空间来分离不同的功
能和模块。因此,在C#中,类库和命名空间通常是一起使用的。
3、经典案例1:建一个类库项目,再建两个测试项目。在指定的位置记录当前时间,
(1.输出到控制台2.写入文件。)
(1)新建一个类库,命名为TestClass。注意:定义委托。
public delegate void WriteTimeDelegate();
public class TestClass
{
public void DoSomething(WriteTimeDelegate wtd)
{
Console.WriteLine("===================");
Console.WriteLine("===================");
//执行委托参数
wtd?.Invoke();
Console.WriteLine("===================");
Console.WriteLine("===================");
}
}
(2)新建控制台程序09,并引用上面的类库。
private static void Main(string[] args)
{
TestClass tc = new TestClass();
tc.DoSomething(ShowTime);
Console.ReadKey();
}
private static void ShowTime()
{ Console.WriteLine(DateTime.Now.ToString()); }
(3)新建控制台程序10,并引用前面的类库
private static void Main(string[] args)
{
TestClass tc = new TestClass();
tc.DoSomething(WriteFile);
Console.ReadKey();
}
private static void WriteFile()
{ File.WriteAllText(@"E:\1.txt", DateTime.Now.ToString()); }
通过委托,09调用类库会显示,10调用类库会写到文件,实现重用和扩展,用委托来
自定化。
问:字符串或字符串数组传入无返回值的方法被修改时,原字符串或字符串数组更改了吗
答:字符串没更改。字符串数组更改了。
字符串是不可变的(Immutable),这意味着一旦字符串被创建,它的值就不能被
修改。当你将一个字符串传递给另一个方法时,该方法无法直接修改原始字符串的内
容。任何对字符串的修改实际上都会创建一个新的字符串对象。
如果你想要在方法中修改字符串,并使这些修改对原始字符串可见,你可以通过
使用ref关键字将字符串参数声明为引用类型。
如果你将一个字符串数组传递给一个无返回值的方法,并在方法内部修改该数组
的内容,原始的字符串数组会发生更改。这是因为字符串数组是引用类型,方法接收
到的参数实际上是对数组对象的引用。
经典案例2:(还是单独建一个类库)有一个方法ChangeString(string[] srtArr);
传入一个字符串数组,在每个元素两边加一个’=’。//当我想让元素全部大写,怎么办?
(也可以把委托作为‘参数’)。//将用户的代码“注入”到了你的程序中。
(1)TestClas添加新方法,声明一委托,主要应用里面变化的部分,注意传两个参数
public delegate string GetStringDelegate(string str);
public class TestClass
{
public void ChangeStrings(string[] strs, GetStringDelegate change)
{
for (int i = 0; i < strs.Length; i++)
{ strs[i] = change(strs[i]); }//a
}
}
(2)控制台09程序,用委托应对两种变化
private static void Main(string[] args)
{
TestClass tc = new TestClass();
string[] names = new string[] { "a", "b", "c", "d" };
tc.ChangeStrings(names, Change1);
foreach (string name in names)
{ Console.WriteLine(name); }
tc.ChangeStrings(names, Change2);
foreach (string name in names)
{ Console.WriteLine(name); }
Console.ReadKey();
}
private static string Change1(string s)//变化1
{ return s.ToUpper(); }
private static string Change2(string s)//变化2
{ return string.Concat("★", s, "★"); }
重点是在a处,通过这种形式,实现代码重用。
这样,想变化时,直接重新定义一个方法,传到ChangStrings中即可实现变化。
4、案例:窗体之间传值。
Form1与Form2两窗体,各有一textbox,button。
(1)form1中点击button,会将显示form2,同时将form1中文本框值传给form2中文本框
(2)form2中点击button,关闭本窗体同时将文本框值传回给form1中文本框。
在form1中:
namespace TranslateForm
{
public delegate void GetDelegate(string s);//a
public partial class Form1 : Form
{
public Form1()
{ InitializeComponent(); }
private void button1_Click(object sender, EventArgs e)
{
Form2 form2 = new Form2(textBox1.Text.Trim(), Gets);//b
form2.Show();//c
}
private void Gets(string s)//d
{ this.textBox1.Text = s; }
}
}
在form2中:
namespace TranslateForm
{
public partial class Form2 : Form
{
private GetDelegate _update;//e
public Form2()
{ InitializeComponent(); }
public Form2(string s, GetDelegate gets) : this()//f
{
this.textBox1.Text = s;//g
this._update = gets;//h
}
private void button1_Click(object sender, EventArgs e)
{
this._update(this.textBox1.Text.Trim());//i
this.Close();
}
}
}
form1->form2,在form2创建新构造函数f,以便接受form1中b处的的实例。
b处传两个参数就进入了form2中,实现form1中文件框到form2中,同时将委托的实例方法
传到了form2,以便form2在关闭之前调用方法i处。
form1与form2在同一命名空间下,所以a处的委托定义可以在form1也可在form2中。
问:为什么_update是私有的却能跨类访问form1呢?
答:虽然 _update 是私有字段,但私有访问修饰符只限制了对字段的直接访问,而不
影响通过委托调用相应的方法。
注意,委托的使用可以实现跨类的方法调用,而私有字段限制的是对字段本身的直接
访问而不是调用关联的方法。
不用委托也可以,使用公共属性字符,它还具体方法的特征。获取和设置来变化文本框。
form1:
public partial class Form1 : Form
{
public string txtBox//通过公共属性进行获取和设置
{
get { return textBox1.Text.Trim(); }
set { textBox1.Text = value; }
}
public Form1()
{ InitializeComponent(); }
private void button1_Click(object sender, EventArgs e)
{
txtBox = textBox1.Text.Trim();
Form2 form2 = new Form2(this);//将form1传过去
form2.Show();
}
}
form2:
public partial class Form2 : Form
{
private Form1 _form1;
public Form2()
{ InitializeComponent(); }
public Form2(Form1 form1) : this()
{
this._form1 = form1;//另用字段接收form1
this.textBox1.Text = _form1.txtBox;
}
private void button1_Click(object sender, EventArgs e)
{
_form1.txtBox = textBox1.Text.Trim();
this.Close();
}
}
5、问:Invoke()是什么意思?语法与使用是怎样的?
答:当涉及到使用委托调用方法时,C#提供了两种主要的方式:直接调用委托实例或者
使用Invoke方法。下
在C#中,可以使用委托的Invoke方法来调用委托所引用的方法。Invoke方法提供了
一种显式调用委托实例的方式,它与直接调用委托实例的方式相似,但它在某些场景下
更加灵活,特别是当委托是以变量的形式传递时。
Invoke方法接受与委托定义的方法相匹配的参数,并在执行完委托所引用的方法后
返回相应的结果(如果有的话)。
Invoke 是用于调用委托的方法,它的语法如下:
delegateInstance.Invoke(arguments);
delegateInstance 是一个委托实例,其类型必须与要调用的方法的签名相匹配。
arguments 是被传递给委托引用的方法的参数列表。
arguments 是 Invoke 方法的参数,它应该与委托引用的方法所期望的参数个数和
类型相匹配。在调用 Invoke 方法时,需要根据委托引用的方法的参数签名来传递参数。
这意味着传递的参数的个数、顺序和类型都必须与委托引用的方法的参数一致。
Invoke可以理解为"调用"或"执行",它用于显式地调用委托实例。通常用于表示
使用特定的语法或方法来触发执行某个操作或调用某个函数。当涉及到委托时,
Invoke方法提供了一种调用或执行委托所引用的方法的方式。它提供了一个方法调用
的语法糖,使我们能够更清晰地表达我们要调用委托实例的意图。
private static void Main(string[] args)
{
Action
greetingDeleagate.Invoke("恐龙扛狼");//a
Console.ReadKey();
}
private static void Greet(string name)
{ Console.WriteLine($"Hello,{name}!"); }
问:上面a处可用greetingDeleagate("恐龙扛狼"),为何用invoke?
答:使用`Invoke`方法和直接调用委托实例(如`greetDelegate("John")`)在功能上
是等价的,它们可以实现相同的目的。这是因为编译器会自动将委托实例的直接调用
转化为`Invoke`方法的调用。它们都将调用委托实例,并传递参数 "John"。
然而,有几种情况下可能更倾向于使用`Invoke`方法:
1. 显式性和清晰性:
使用Invoke方法可以使代码更加明确和清晰地表达其意图。显式地调用Invoke方法
可以更明确地表示我们要执行委托实例。
2. 动态调用:
当需要动态地在运行时确定要调用的方法时,使用Invoke方法可以通过方法名称
的字符串动态调用方法。例如,使用反射或根据用户的输入字符串来选择要调用
的方法。
3. 统一的API:
在某些情况下,使用Invoke方法可以提供与其他API的统一性,以便在特定上下
文中使用不同类型的委托。
两者在功能上是等价的。选择使用哪种方式可能取决于代码风格、代码的可读性以及
是否需要动态调用方法等因素。无论选择哪种方式,都能够达到相同的结果。
问:什么是语法糖?
答:语法糖(Syntactic Sugar)是一种语法上的改进,在不改变语言的功能和能力的
情况下,通过更简洁、更易读的语法来表达某种特定的操作或结构。
语法糖不是一种功能新增或语言扩展,而是一种语法层面上的改进,旨在使
代码更加易于编写、阅读和理解,从而提升开发者的生产效率。
例:自动属性:
private int _age;// 传统方式
public int Age
{
get { return _age; }
set { _age = value; }
}
public int Age { get; set; }// 自动属性方式
例:集合初始化器
List numbers = new List();// 传统方式
numbers.Add(1);
numbers.Add(2);
numbers.Add(3);
List numbers = new List { 1, 2, 3 };// 集合初始化器方式
例:空合并运算符(Null Coalescing Operator)
string name = null;// 传统方式
if (name == null)
{
name = "John";
}
string name = null;// 空合并运算符方式
name ??= "John";
6、问:Action是什么意思?
答:Action是一个泛型委托类型,它是表示不返回值的方法的委托。它允许您定义委
托实例并引用不带返回值的方法。
Action委托可以接受0到16个参数,并且不返回任何值。如果方法有参数,则在
委托实例中定义的参数类型必须与方法接受的参数类型相匹配。
语法如下:
Action
T1, T2, …, Tn 是方法参数的类型,可以是任何有效的 C# 类型。
methodName 是表示要引用的方法的名称。
使用 Action 委托非常简便。您可以按照以下步骤使用 Action 委托:
定义一个 Action 委托实例,并指定要引用的方法参数类型(如果需要)。
将方法名称分配给委托实例。
对委托实例进行调用,以执行方法。
private static void Main(string[] args)
{
Action msg = Message;//无参时,无泛型
msg.Invoke();
Action u = Luck;//有一参则带一个泛型类型
u.Invoke("恐龙扛狼");
Console.ReadKey();
}
private static void Message()
{ Console.WriteLine("hello world!"); }
private static void Luck(string s)
{ Console.WriteLine($"Good Luck,{s}!"); }
Action实际是一种语法糖,用于更简捷地使用委托。还可结合Lambda更简捷:
private static void Main(string[] args)
{
Action msg = () => { Console.WriteLine("hello world!"); };
msg.Invoke();
Action u = (string name) =>
{
Console.WriteLine($"Gook Luck,{name}");
};
u.Invoke("恐龙扛狼");
Console.ReadKey();
}
Lambda表达式也被认为是C#中的一种语法糖。它引入了一种更简洁的语法来表示匿名
函数。它是在.NET Framework 3.5版本引入的,为开发人员提供了一种更方便的方法
来定义匿名方法,并且能够被绑定到委托类型或用于LINQ查询。
当使用Lambda表达式时,编译器会将其转换为一个委托或表达式树表示。这个转
换是自动进行的,开发人员无需手动完成。因此,从表面上看,Lambda表达式看起来
像是一种特殊的语法,但实际上它是编译器为我们提供的一种便利方式。
7、问:lambda是指什么?
答:1、Lambda表达式是为匿名函数而引入的。
匿名函数是指没有命名的函数,通常用于临时或简单的函数逻辑,不需要单独定
义一个命名的方法。在传统的编程中,如果需要使用一个简单的函数,往往需要声明
一个具名的方法,并为其命名,这样会增加代码的冗余和复杂性。
Lambda表达式的引入使得创建匿名函数变得更加简洁和直观。通过Lambda表达式,
可以在需要函数的地方直接定义和使用匿名函数,而不需要显式地声明一个具名函数。
这样可以减少代码中不必要的命名和定义,提高代码的可读性和维护性。
2、语法:
(parameters) => expression
parameters表示参数列表,可以是零个或多个参数。如果有多个参数,可以使用
逗号进行分隔。expression表示方法的逻辑,即单个表达式或一系列表达式,它返回
一个值。
=>符号被称为Lambda运算符(Lambda operator),它表示箭头操作符,用于分隔
参数列表和表达式的主体。
参数注意:
a.如果没有参数,可以直接用()表示;
Action msg = () => { Console.WriteLine("hello world!"); };
b.参数类型可以推断出,可以不写类型,当然也可显式声明类型。
Action square = ( x) => Console.WriteLine(x * x);//自动推断参数的类型
Action square = (int x) => Console.WriteLine(x * x);//显式声明
c.只有一个参数时,可以不写括号:
Action square1 = (x) => Console.WriteLine(x * x);
Action square2 = x => Console.WriteLine(x * x);
主体部分注意:
a.如果只有一个语句,可以省略{},更为简略。
Func square = x => x * x;
b.如果只有一个语句,该语句的值就是返回值。
Action msg = () => Console.WriteLine("hello world!"); ;//这里返回为void
c.除了前面,如果主体使用了大括号 {} 包裹,并且没有明确使用 return 关键
字指定返回值,那么它并不会有默认的返回值。
Action printMessage = message =>
{
Console.WriteLine(message); // 没有明确的return语句
};
注意,void可以看为是没有返回值。
Lambda表达式的返回值类型可以根据委托类型推断,也可以通过显式指定lambda
表达式的返回类型来确定。如果没有明确指定返回值类型或通过上下文无法推断出返
回值类型,编译器将会报错。
当使用 List
注意下面都表示一种行为,一种动作,最后用tolist()才转为列表实例。之前返回的是返回一个 IOrderedEnumerable 类型的排序后的字符串序列,所以要转换一下。
1. 筛选:
List numbers = new List { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
List evenNumbers = numbers.Where(n => n % 2 == 0).ToList();
2. 映射:
List names = new List { "Alice", "Bob", "Charlie", "David" };
List nameLengths = names.Select(name => name.Length).ToList();
3. 排序:
List names = new List { "Bob", "Alice", "David", "Charlie" };
List sortedNames = names.OrderBy(name => name).ToList();
4. 判断条件:
List numbers = new List { 1, 2, 3, 4, 5 };
bool allPositive = numbers.All(n => n > 0);//都大于0? 返回true
bool anyEven = numbers.Any(n => n % 2 == 0);//存在一偶数?true
简言之:Where筛选,选出满足条件的。
Select映射,全部元素进行变换后生成新的序列,不是原来的序列。
All全部满足,Any只要有一个满足。
OrderBy排序