读《Improved Deep Hashing with Soft Pairwise Similarity for Multi-label Image Retrieval》
引言
现有的传统哈希只要至少一个标签匹配就算事,所以如图的例子中,a-b和a-c都算匹配的
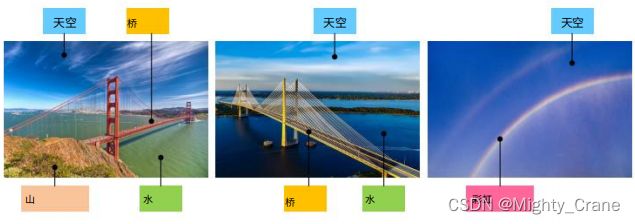
这就没辙top1排序多标签对的相似度,于是针对每个图像所持有的语义标签提出了成对相似性的软定义。具体来说,使用归一化语义标签将成对相似性量化为百分比。(贡献1)
于是提出两种相似度,硬相似度考虑所有标签都匹配,所以用交叉熵学习;软相似度考虑部分标签匹配,所以用均方误差(贡献2)
相关工作
深度哈希学习的一种简单方法是直接对高级特征进行阈值处理,典型的方法是 DLBHC [46],它通过在AlexNet [15] 的最后一个分类层之前插入一个潜在的哈希层来学习类哈希表示。虽然网络在分类任务上得到了很好的微调,但潜在哈希层的特
征被认为是有区别的,这确实比手工制作的特征表现出更好的性能。(也就是说deephash比特征工程好,但相比起直接deep,直接Alexnet或者传统hash效果咋样呢)
对于多标签检索,DSRH [25] 尝试利用多级相似度的排名信息来学习哈希函数,并提出代理损失来解决排名措施的优化问题。 IAH [47] 侧重于学习实例感知图像表示并使用加权三元组损失来保持多标签图像的相似性排名。然而,DSRH [25] 和 IAH [47] 采用的加权三元组损失函数并不强制直接限制学习细粒度多级语义相似性,因为它们专注于根据图像与查询的相似度来保持图像的正确排名(也就是说一直在纠结于损失函数,而没有针对多标签相似度的痛点来解决问题吧)
基于此,DMSSPH [48] 尝试构造哈希函数以最大化输出空间的可辨别性,以保持多标签图像之间的多级相似性。尽管 DMSSPH [48] 已经利用细粒度的多级语义相似性进行成对相似性学习,但仍有进一步探索的空间。 [36] 中提出了一种新颖有效的 TALR 方法,该方法考虑了整数值汉明距离上的绑定排名,并直接优化了基于排名的评估指标平均精度(MAP)[49] 和归一化贴现累积增益(NDCG)[ 50]。它在几个基准数据集中取得了高性能。在 [51] 中,在迁移学习的背景下,提出了两个用于评估监督哈希方法的新协议。
本文则是通过探索多标签数据集上成对语义相似性的多样性来提高哈希质量。具体以连续的形式定义细粒度的成对相似性值(将离散的汉明距离改成连续值?)。于是将成对相似性分为两种情况,并构造一个联合成对损失函数来同时进行特征学习和哈希码生成。
方法
为了考察多标签相似度,量化标签为连续值百分比,也就是两张图的语义标签向量的余弦相似度(本文是第一个使用余弦距离来量化成对图像的细粒度语义相似度的)

图像通过Alexnet,最后fc8层的输出再通过下面的激活函数映射到 (-1,1)(提到本文的Alexnet是可以随意替换成vgg、Googlenet等,所以为啥这俩更新的网络不如初号机有啥说道吗)
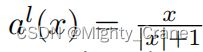
硬相似度

其中Ω是俩哈希码的内积

软相似度
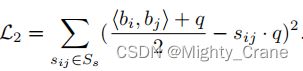
联合学习
为了同时学习这两种情况并形成统一形式,使用Mij来标记这两种情况,其中Mij = 1 表示“硬相似”情况, Mij = 0 表示“软相似”情况。因此,成对相似性损失被重写为:(这不其实就是那俩损失函数结合嘛)

直接优化方程式具有挑战性。 因为二元约束bi ∈ {−1, 1} q需要对网络输出进行阈值处理,这可能导致训练过程中反向传播中的梯度消失问题。
放缩成对量化损失

最终损失为C = L + λQ
实验
性能指标
平均累积增益 (ACG) [60]、归
一化贴现累积增益 (NDCG) [50]、平均值
平均精度 (MAP) [49] 和加权平均精度 (WAP) [25]。
关于哈希损失函数,将高维数据映射到低维二进制编码,提高数据检索的速度和效率。
输入包括四个参数:
D:表示样本的特征向量矩阵,形状为(batch_size, feature_dim)。label:表示样本的标签向量矩阵,形状为(batch_size, num_class),其中num_class表示类别数。alpha、belta和gama:表示三个损失项的权重系数。m:表示哈希码的长度。
具体来说,这个哈希损失函数包括三个部分:余弦相似度损失、哈希码长度约束和正则化项。其中,余弦相似度损失可以通过比较样本对之间的余弦相似度来匹配哈希码,
首先计算标签的余弦相似度矩阵
label_count = tf.expand_dims(tf.sqrt(tf.reduce_sum(tf.square(label), 1)),1)
# 标签向量的模长
norm_label = label/tf.tile(label_count,[1,args.num_class])
# 标签向量的单位向量
w_label = tf.matmul(norm_label, norm_label, False, True)
# 标签向量之间的余弦相似度矩阵
semi_label = tf.where(w_label>0.99, w_label-w_label,w_label)
# 将大于阈值0.99的相似度设置为0后的相似度矩阵
再计算样本的余弦相似度
p2_distance = tf.matmul(D, D, False, True)
哈希码长度约束可以确保哈希码的长度不超过指定的值。在实现中,我们需要计算样本的哈希码,并将其与指定的哈希码长度进行比较,从而得到哈希码长度约束损失。
scale_distance = belta * p2_distance / m
# 对距离矩阵进行缩放后的值
temp = tf.log(1+tf.exp(scale_distance))
loss = tf.where(semi_label<0.01,temp - w_label * scale_distance, gama*m*tf.square((p2_distance+m)/2/m-w_label))
regularizer = tf.reduce_mean(tf.abs(tf.abs(D) - 1))
d_loss = tf.reduce_mean(loss) + alpha * regularizer
从而实现论文中的C=L+αQ
哈希码长度约束可以确保哈希码的长度不超过指定的值,正则化项则可以帮助模型防止过拟合。
该函数的输出包括两个值:
d_loss:表示总的哈希损失值。w_label:表示标签之间的余弦相似度矩阵,形状为(batch_size, batch_size)。
在函数实现中,首先对样本标签进行标准化处理,然后计算标签之间的余弦相似度矩阵,并将其中大于阈值的相似度设为0。接着,计算样本之间的余弦相似度矩阵,并将距离矩阵映射到0到1之间的值域内。最后,计算三个损失项,并将它们加权求和作为总的哈希损失值。
main
这段代码的作用是读取tfrecord文件中的数据,构建AlexNet模型,计算哈希损失(d_loss),并使用优化器进行训练。
具体来说,首先通过reader.read_and_decode函数从tfrecord文件中读取数据(这个在tf2版本里要大改了,需要换成data相关函数),得到一组图像(img)和其对应的标签(label)。然后使用tf.train.shuffle_batch函数将读取的图像和标签打乱,形成一个大小为args.batch_size的批次,用于训练模型。
接下来,使用AlexNet函数构建AlexNet模型,并将批次中的图像数据作为输入,得到一个输出D。这个输出包含了每张图像对应的哈希码。(哈希码的维度由num_bits控制)
然后,使用hashing_loss函数计算哈希损失,并将输出值D和标签值label_batch作为输入参数。其中,args.alpha、args.belta和args.gama是超参数,分别控制相似度损失、哈希码长度约束和正则化项的权重。
最后,将计算得到的哈希损失(d_loss)和模型输出(out)返回。
随后优化训练过程:
- 根据指定的 skip_layers,将所有可训练的变量分成两类:var_list1 和 var_list2。其中,var_list1 包括所有需要 fine-tuning 的变量,var_list2 包括所有需要从头开始训练的变量。
- 定义 learning_rate,并设置指数衰减。
- 定义两个 Adam 优化器:opt1 和 opt2。其中,opt1 的学习率为 learning_rate*0.01,用于优化 var_list1 中的变量;opt2 的学习率为 learning_rate,用于优化 var_list2 中的变量。
- 计算所有变量的梯度 grads,并根据 var_list1 和 var_list2 将 grads 分成两份:grads1 和 grads2。
- 分别用 opt1 和 opt2 对 grads1 和 grads2 中的梯度进行优化,并更新 global_step。
- 将两个优化器的更新操作合并到一个 train_op 中。
因此实现了对整个模型的训练过程,通过不同的优化器对两类变量的梯度进行更新,从而实现 fine-tuning 和从头开始训练两种不同的训练方式。
在训练循环中,通过会话(Session)对象来执行 TensorFlow 计算图(Graph)中的节点(Node)。
首先,定义了一个 Saver 对象来保存训练后的模型。接下来,使用 sess.run 方法来初始化全局变量和本地变量,以及将预训练的模型权重加载到网络中。然后,开启数据集队列线程(这个应该只能用在tf1中,tf2就尬住了),进入训练循环。
训练循环中,通过 sess.run 方法运行了三个节点,分别是 train_op(训练节点)、d_loss(损失节点)和 global_step(全局步数节点)。其中,train_op 是将计算的梯度应用于变量的操作节点,返回值为 None;d_loss 是计算损失的节点,返回值为一个标量;global_step 是一个变量,每次执行训练节点后其值加一。
在训练过程中,通过 step1 % 10 == 0 来控制每迭代 10 次输出一次训练信息,包括当前的迭代次数(step1)、损失值(loss_t)和耗时(elapsed_time)。通过 step1 % args.save_freq == 0 来控制每迭代 args.save_freq 次就保存一次模型。当数据集的所有样本都被遍历一遍后,训练结束。最后,停止队列线程,退出会话。
关于alexnet,卷积的做法类似于caffe,当groups等于1时,直接进行卷积操作;当groups大于1时,将输入和卷积核按照groups数量进行分组,分别进行卷积操作,最后将结果合并起来。最终输出的结果经过偏置、ReLU激活等处理。(groups: 分组卷积的分组数量,默认为1)