逐行讲解BiLSTM+CRF实现命名实体识别(NER)
文章标题
- 本文概述
- 代码详解
-
- 任务
- 数据处理
-
- 建立词表
- 建立标签字典
- 数据预处理
- Dataset构建
- DataLoader构建
- 模型构建
-
- CRF
- BiLSTM部分
- 训练过程
- 评分结果
- 备注
-
- 预测脚本
本文概述
使用BiLSTM+CRF做中文命名实体识别(NER),代码有详细注释,若有遗漏或不详细可评论补充。
本文使用CLUE Fine-Grain NER中文数据集,数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)。
上篇CRF与HMM对NER进行了介绍,HMM和单个CRF实现NER的代码可自行查看。
本文基于pytorch官方版本进行修改,由于pytorch官方版本只是一个demo,输入为单个序列,本文修改后可进行批次训练。
逐行讲解CRF实现命名实体识别(NER):https://blog.csdn.net/qq_41496421/article/details/126765444?spm=1001.2014.3001.5501
逐行讲解HMM实现命名实体识别(NER):https://blog.csdn.net/qq_41496421/article/details/127623738?spm=1001.2014.3001.5501
数据集详情介绍:https://www.cluebenchmarks.com/introduce.html
数据集下载链接:https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip
本文github代码位置:https://github.com/ZejunCao/NER_baseline
评价指标详细介绍:https://blog.csdn.net/qq_41496421/article/details/127196850?spm=1001.2014.3001.5502
pytorch官方代码参考:https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
代码详解
任务
本文NER任务使用BIO三位标注法,即:
B-begin:代表实体开头
I-inside:代表实体内部
O-outside:代表不属于任何实体
其后面接实体类型,如 ‘B-name’,‘I-company’。
数据处理
建立词表
每个词在输入到LSTM之前都需要转换成一个向量,这就是通常所说的词向量。这里的词是指序列被分割的最小单位,不同任务不同语种分割方法多种多样,在本文NER任务中将字作为最小单位。方法有很多,如one-hot、word2vec等等。
本文采用nn.Embedding方法,首先初始化一个(词向量维度*词个数)大小的矩阵,而每个词对应一个索引,索引所在行就是该词对应的词向量,这个矩阵也作为神经网络的参数进行训练学习。
在此之前,要先遍历数据集,建立一个包含所用到的所有词的词表,每个词都对应一个索引,并将其保存成pkl文件,下次运行时直接加载文件即可,无需再次遍历数据集获取词表,加快运行效率。
def get_vocab(data_path):
# 词表保存路径
vocab_path = '../data/cluener_public/vocab.pkl'
# 第一次运行需要遍历训练集获取到标签字典,并存储成json文件保存,第二次运行即可直接载入json文件
if not os.path.exists(vocab_path):
with open(vocab_path, 'rb') as fp:
vocab = pickle.load(fp)
else:
json_data = []
# 加载数据集
with open(data_path, 'r', encoding='utf-8') as fp:
for line in fp:
json_data.append(json.loads(line))
# 建立词表字典,提前加入'PAD'和'UNK'
# 'PAD':在一个batch中不同长度的序列用该字符补齐
# 'UNK':当验证集或测试集出现词表以外的词时,用该字符代替
vocab = {'PAD': 0, 'UNK': 1}
# 遍历数据集,不重复取出所有字符,并记录索引
for data in json_data:
for word in data['text']: # 获取实体标签,如'name','compan
if word not in vocab:
vocab[word] = len(vocab)
# vocab:{'PAD': 0, 'UNK': 1, '浙': 2, '商': 3, '银': 4, '行': 5...}
# 保存成pkl文件
with open(vocab_path, 'wb') as fp:
pickle.dump(vocab, fp)
# 翻转字表,预测时输出的序列为索引,方便转换成中文汉字
# vocab_inv:{0: 'PAD', 1: 'UNK', 2: '浙', 3: '商', 4: '银', 5: '行'...}
vocab_inv = {v: k for k, v in vocab.items()}
return vocab, vocab_inv
建立标签字典
由于该数据集的特性(在数据处理时可以看到),需要提前获取标签种类,并以本文中BIO方式建立标签字典。与词表一样,第一次遍历获取后将其保存成json文件,下次直接加载json文件即可,加快运行效率。
def get_label_map(data_path):
# 标签字典保存路径
label_map_path = '../data/cluener_public/label_map.json'
# 第一次运行需要遍历训练集获取到标签字典,并存储成json文件保存,第二次运行即可直接载入json文件
if os.path.exists(label_map_path):
with open(label_map_path, 'r', encoding='utf-8') as fp:
label_map = json.load(fp)
else:
# 读取json数据
json_data = []
with open(data_path, 'r', encoding='utf-8') as fp:
for line in fp:
json_data.append(json.loads(line))
'''
json_data[0]数据为该格式:
{'text': '浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,',
'label': {'name': {'叶老桂': [[9, 11]]}, 'company': {'浙商银行': [[0, 3]]}}}
'''
# 统计共有多少类别
n_classes = []
for data in json_data:
for label in data['label'].keys(): # 获取实体标签,如'name','company'
if label not in n_classes: # 将新的标签加入到列表中
n_classes.append(label)
n_classes.sort()
# n_classes: ['address', 'book', 'company', 'game', 'government', 'movie', 'name', 'organization', 'position', 'scene']
# 设计label_map字典,对每个标签设计两种,如B-name、I-name,并设置其ID值
label_map = {}
for n_class in n_classes:
label_map['B-' + n_class] = len(label_map)
label_map['I-' + n_class] = len(label_map)
label_map['O'] = len(label_map)
# 对于BiLSTM+CRF网络,需要增加开始和结束标签,以增强其标签约束能力
START_TAG = ""
STOP_TAG = ""
label_map[START_TAG] = len(label_map)
label_map[STOP_TAG] = len(label_map)
'''
{'B-address': 0, 'I-address': 1, 'B-book': 2, 'I-book': 3, 'B-company': 4, 'I-company': 5, 'B-game': 6,
'I-game': 7, 'B-government': 8, 'I-government': 9, 'B-movie': 10, 'I-movie': 11, 'B-name': 12, 'I-name': 13,
'B-organization': 14, 'I-organization': 15, 'B-position': 16, 'I-position': 17, 'B-scene': 18, 'I-scene': 19,
'O': 20, '': 21, '': 22}
'''
# 将label_map字典存储成json文件
with open(label_map_path, 'w', encoding='utf-8') as fp:
json.dump(label_map, fp, indent=4)
# {0: 'B-address', 1: 'I-address', 2: 'B-book', 3: 'I-book'...}
label_map_inv = {v: k for k, v in label_map.items()}
return label_map, label_map_inv
数据预处理
对数据进行预处理,这里的处理方式与之前文章 HMM 和 CRF 中相同。
def data_process(path):
# 读取每一条json数据放入列表中
# 由于该json文件含多个数据,不能直接json.loads读取,需使用for循环逐条读取
json_data = []
with open(path, 'r', encoding='utf-8') as fp:
for line in fp:
json_data.append(json.loads(line))
# json_data中每一条数据的格式为
'''
{'text': '浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,',
'label': {'name': {'叶老桂': [[9, 11]]}, 'company': {'浙商银行': [[0, 3]]}}}
'''
# 将json文件处理成如下格式
'''
[['浙', '商', '银', '行', '企', '业', '信', '贷', '部', '叶', '老', '桂', '博', '士', '则', '从', '另', '一',
'个', '角', '度', '对', '五', '道', '门', '槛', '进', '行', '了', '解', '读', '。', '叶', '老', '桂', '认',
'为', ',', '对', '目', '前', '国', '内', '商', '业', '银', '行', '而', '言', ','],
['B-company', 'I-company', 'I-company', 'I-company', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name',
'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']]
'''
data = []
# 遍历json_data中每组数据
for i in range(len(json_data)):
# 将标签全初始化为'O'
label = ['O'] * len(json_data[i]['text'])
# 遍历'label'中几组实体,如样例中'name'和'company'
for n in json_data[i]['label']:
# 遍历实体中几组文本,如样例中'name'下的'叶老桂'(有多组文本的情况,样例中只有一组)
for key in json_data[i]['label'][n]:
# 遍历文本中几组下标,如样例中[[9, 11]](有时某个文本在该段中出现两次,则会有两组下标)
for n_list in range(len(json_data[i]['label'][n][key])):
# 记录实体开始下标和结尾下标
start = json_data[i]['label'][n][key][n_list][0]
end = json_data[i]['label'][n][key][n_list][1]
# 将开始下标标签设为'B-' + n,如'B-' + 'name'即'B-name'
# 其余下标标签设为'I-' + n
label[start] = 'B-' + n
label[start + 1: end + 1] = ['I-' + n] * (end - start)
# 对字符串进行字符级分割
# 英文文本如'bag'分割成'b','a','g'三位字符,数字文本如'125'分割成'1','2','5'三位字符
texts = []
for t in json_data[i]['text']:
texts.append(t)
# 将文本和标签编成一个列表添加到返回数据中
data.append([texts, label])
return data
Dataset构建
几个关键操作:
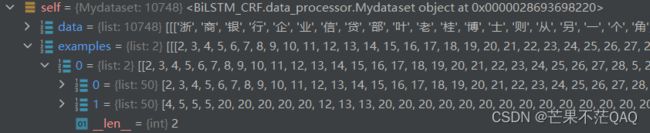
- data_process处理后的文本还是原始文本,存储的是中文汉字,需要将其转化为索引,标签也一样,下图为处理前和处理后的样例

- collect_fn函数,文本数据通常长度不定,而神经网络的输入通常要求一个batch内长度相同,所以需要对其进行填充处理。本文中对每个batch单独填充为动态填充方法,只需要填充到batch内的最大长度即可。还有静态填充方法,取整个数据集中最大序列长度提前进行填充,但会造成大量冗余,降低运行效率。
- 其他的如__getitem__、__len__都为常规操作,这里不做解释。
class Mydataset(Dataset):
def __init__(self, file_path, vocab, label_map):
self.file_path = file_path
# 数据预处理
self.data = data_process(self.file_path)
self.label_map, self.label_map_inv = label_map
self.vocab, self.vocab_inv = vocab
# self.data为中文汉字和英文标签,将其转化为索引形式
self.examples = []
for text, label in self.data:
t = [self.vocab.get(t, self.vocab['UNK']) for t in text]
l = [self.label_map[l] for l in label]
self.examples.append([t, l])
def __getitem__(self, item):
return self.examples[item]
def __len__(self):
return len(self.data)
def collect_fn(self, batch):
# 取出一个batch中的文本和标签,将其单独放到变量中处理
# 长度为batch_size,每个序列长度为原始长度
text = [t for t, l in batch]
label = [l for t, l in batch]
# 获取一个batch内所有序列的长度,长度为batch_size
seq_len = [len(i) for i in text]
# 提取出最大长度用于填充
max_len = max(seq_len)
# 填充到最大长度,文本用'PAD'补齐,标签用'O'补齐
text = [t + [self.vocab['PAD']] * (max_len - len(t)) for t in text]
label = [l + [self.label_map['O']] * (max_len - len(l)) for l in label]
# 将其转化成tensor,再输入到模型中,这里的dtype必须是long否则报错
# text 和 label shape:(batch_size, max_len)
# seq_len shape:(batch_size,)
text = torch.tensor(text, dtype=torch.long)
label = torch.tensor(label, dtype=torch.long)
seq_len = torch.tensor(seq_len, dtype=torch.long)
return text, label, seq_len
DataLoader构建
DataLoader构建很简单,使用torch.utils.data.DataLoader方法
# 建立中文词表,扫描训练集所有字符得到,'PAD'在batch填充时使用,'UNK'用于替换字表以外的新字符
vocab = get_vocab('../data/cluener_public/train.json')
# 建立标签字典,扫描训练集所有字符得到
label_map = get_label_map('../data/cluener_public/train.json')
train_dataset = Mydataset('../data/cluener_public/train.json', vocab, label_map)
valid_dataset = Mydataset('../data/cluener_public/dev.json', vocab, label_map)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, num_workers=0, pin_memory=True, shuffle=True,
collate_fn=train_dataset.collect_fn)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, num_workers=0, pin_memory=False, shuffle=False,
collate_fn=valid_dataset.collect_fn)
模型构建
模型基于torch官网(以下简称参考程序)的程序进行改造,增加了处理批次数据的机制,模型结构上进行了一些小调整。
模型结构:Embedding -> dropout -> BiLSTM -> LayerNorm ->Linear -> CRF,详细注释在代码中。
这里单独把CRF做成一个类进行调用,而另一个类包含除CRF外的所有结构,这里称为BiLSTM部分。
CRF
首先介绍CRF部分,大体结构基于参考程序,改动主要在以下几点:
- 增加batch维度处理,参考程序只能处理单条样本,这里对_forward_alg函数和_score_sentence函数进行了改动;
- 修改矩阵计算方式,减小时间复杂度。
- 假设数据输入维度为(batch_size, seq_len, tagset_size),参考程序没有batch处理,_forward_alg函数的时间复杂度为O(seq_len*tagset_size),_score_sentence函数的时间复杂度为O(seq_len),若增加batch操作,时间复杂度需再乘上batch_size。
- 这里进行改动后,_forward_alg函数的时间复杂度为O(seq_len),_score_sentence函数的时间复杂度为O(batch_size),_viterbi_decode函数的时间复杂度为O(batch_size*seq_len),大大加快程序训练和推理时间。
# log sum exp 增强数值稳定性
# 改进了torch版本原始函数.可适用于两种情况计算得分
def log_sum_exp(vec):
max_score, _ = torch.max(vec, dim=-1)
max_score_broadcast = max_score.unsqueeze(-1).repeat_interleave(vec.shape[-1], dim=-1)
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast), dim=-1))
class CRF(nn.Module):
def __init__(self, label_map, device='cpu'):
super(CRF, self).__init__()
self.label_map = label_map
self.label_map_inv = {v: k for k, v in label_map.items()}
self.tagset_size = len(self.label_map)
self.device = device
# 转移概率矩阵
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
# 增加开始和结束标志,并手动干预转移概率
self.START_TAG = ""
self.STOP_TAG = ""
self.transitions.data[self.label_map[self.START_TAG], :] = -10000
self.transitions.data[:, self.label_map[self.STOP_TAG]] = -10000
def _forward_alg(self, feats, seq_len):
# 手动设置初始得分,让开始标志到其他标签的得分最高
init_alphas = torch.full((self.tagset_size,), -10000.)
init_alphas[self.label_map[self.START_TAG]] = 0.
# 记录所有时间步的得分,为了解决序列长度不同问题,后面直接取各自长度索引的得分即可
# shape:(batch_size, seq_len + 1, tagset_size)
forward_var = torch.zeros(feats.shape[0], feats.shape[1] + 1, feats.shape[2], dtype=torch.float32,
device=self.device)
forward_var[:, 0, :] = init_alphas
# 将转移概率矩阵复制 batch_size 次,批次内一起进行计算,矩阵计算优化,加快运行效率
# shape:(batch_size, tagset_size) -> (batch_size, tagset_size, tagset_size)
transitions = self.transitions.unsqueeze(0).repeat(feats.shape[0], 1, 1)
# 对所有时间步进行遍历
for seq_i in range(feats.shape[1]):
# 取出当前词发射概率
emit_score = feats[:, seq_i, :]
# 前一时间步得分 + 转移概率 + 当前时间步发射概率
tag_var = (
forward_var[:, seq_i, :].unsqueeze(1).repeat(1, feats.shape[2], 1) # (batch_size, tagset_size, tagset_size)
+ transitions
+ emit_score.unsqueeze(2).repeat(1, 1, feats.shape[2])
)
# 这里必须调用clone,不能直接在forward_var上修改,否则在梯度回传时会报错
cloned = forward_var.clone()
cloned[:, seq_i + 1, :] = log_sum_exp(tag_var)
forward_var = cloned
# 按照不同序列长度不同取出最终得分
forward_var = forward_var[range(feats.shape[0]), seq_len, :]
# 手动干预,加上结束标志位的转移概率
terminal_var = forward_var + self.transitions[self.label_map[self.STOP_TAG]].unsqueeze(0).repeat(feats.shape[0], 1)
# 得到最终所有路径的分数和
alpha = log_sum_exp(terminal_var)
return alpha
# 修改矩阵计算方式,加速计算
def _score_sentence(self, feats, tags, seq_len):
# 初始化,大小为(batch_size,)
score = torch.zeros(feats.shape[0], device=self.device)
# 将开始标签拼接到序列上起始位置,参与分数计算
start = torch.tensor([self.label_map[self.START_TAG]], device=self.device).unsqueeze(0).repeat(feats.shape[0], 1)
tags = torch.cat([start, tags], dim=1)
# 在batch上遍历
for batch_i in range(feats.shape[0]):
# 采用矩阵计算方法,加快运行效率
# 取出当前序列所有时间步的转移概率和发射概率进行相加,由于计算真实标签序列的得分,所以只选择标签的路径
score[batch_i] = torch.sum(
self.transitions[tags[batch_i, 1:seq_len[batch_i] + 1], tags[batch_i, :seq_len[batch_i]]]) \
+ torch.sum(feats[batch_i, range(seq_len[batch_i]), tags[batch_i][1:seq_len[batch_i] + 1]])
# 最后加上结束标志位的转移概率
score[batch_i] += self.transitions[self.label_map[self.STOP_TAG], tags[batch_i][seq_len[batch_i]]]
return score
# 维特比算法得到最优路径,原始torch函数
def _viterbi_decode(self, feats):
backpointers = []
# 手动设置初始得分,让开始标志到其他标签的得分最高
init_vvars = torch.full((1, self.tagset_size), -10000., device=self.device)
init_vvars[0][self.label_map[self.START_TAG]] = 0
# 用于记录前一时间步的分数
forward_var = init_vvars
# 传入的就是单个序列,在每个时间步上遍历
for feat in feats:
# 将上一时间步的总概率复制tagset_size次,以便一次性加上所有转移概率
forward_var = forward_var.repeat(feat.shape[0], 1)
next_tag_var = forward_var + self.transitions
# 对每个标签位置取最大值的索引
bptrs_t = torch.max(next_tag_var, 1)[1].tolist()
# 取出当前时间步所有最大值的概率
viterbivars_t = next_tag_var[range(forward_var.shape[0]), bptrs_t]
# 加上当前时间步的发射概率
forward_var = (viterbivars_t + feat).view(1, -1)
# 记录最大值的索引,后续回溯用
backpointers.append(bptrs_t)
# 手动加入转移到结束标签的概率
terminal_var = forward_var + self.transitions[self.label_map[self.STOP_TAG]]
# 在最终位置得到最高分数所对应的索引
best_tag_id = torch.max(terminal_var, 1)[1].item()
# 最高分数
path_score = terminal_var[0][best_tag_id]
# 回溯,向后遍历得到最优路径
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 弹出开始标签
start = best_path.pop()
assert start == self.label_map[self.START_TAG] # Sanity check
# 将路径反转
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, feats, tags, seq_len):
# 所有路径得分
forward_score = self._forward_alg(feats, seq_len)
# 标签路径得分
gold_score = self._score_sentence(feats, tags, seq_len)
# 返回 batch 分数的平均值
return torch.mean(forward_score - gold_score)
这里以_score_sentence举例是如何进行矩阵加速运算的,修改前需要for循环遍历每个时间步取出相应概率,修改后使用列表方式直接取出所有时间步的数据。
# 加速前
def _score_sentence(self, feats, tags, seq_len):
# 初始化,大小为(batch_size,)
score = torch.zeros(feats.shape[0], device=self.device)
# 将开始标签拼接到序列上起始位置,参与分数计算
start = torch.tensor([self.label_map[self.START_TAG]], device=self.device).unsqueeze(0).repeat(feats.shape[0], 1)
tags = torch.cat([start, tags], dim=1)
# 在batch上遍历
for batch_i in range(feats.shape[0]):
# 对所有时间步进行遍历
for seq_i in range(seq_len[batch_i]):
# 取出当前时间步到下一时间步的转移概率和下一时间步的发射概率进行相加,注意起始位置没有发射概率
score[batch_i] += self.transitions[tags[batch_i][seq_i + 1], tags[batch_i][seq_i]] \
+ feats[batch_i][seq_i][tags[batch_i][seq_i + 1]]
# 结束位置也没有发射概率,所以只加上到结束标志位的转移概率
score[batch_i] += self.transitions[self.label_map[self.STOP_TAG], tags[batch_i][seq_len[batch_i]]]
return score
# 修改矩阵计算方式,加速计算
def _score_sentence(self, feats, tags, seq_len):
# 初始化,大小为(batch_size,)
score = torch.zeros(feats.shape[0], device=self.device)
# 将开始标签拼接到序列上起始位置,参与分数计算
start = torch.tensor([self.label_map[self.START_TAG]], device=self.device).unsqueeze(0).repeat(feats.shape[0], 1)
tags = torch.cat([start, tags], dim=1)
# 在batch上遍历
for batch_i in range(feats.shape[0]):
# 采用矩阵计算方法,加快运行效率
# 取出当前序列所有时间步的转移概率和发射概率进行相加,由于计算真实标签序列的得分,所以只选择标签的路径
score[batch_i] = torch.sum(
self.transitions[tags[batch_i, 1:seq_len[batch_i] + 1], tags[batch_i, :seq_len[batch_i]]]) \
+ torch.sum(feats[batch_i, range(seq_len[batch_i]), tags[batch_i][1:seq_len[batch_i] + 1]])
# 最后加上结束标志位的转移概率
score[batch_i] += self.transitions[self.label_map[self.STOP_TAG], tags[batch_i][seq_len[batch_i]]]
return score
BiLSTM部分
参考代码中由于输入只有一条样本,最大长度就是该样本的长度。而batch不为1时,就需要使用padding将多条数据对齐,这里使用了两种方法实现对齐操作,一种是使用torch自带的rnn对齐工具,另一种是根据样本长度不同创建mask进行掩码,两种方法只是实现方式不同。
class BiLSTM_CRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab, label_map, device='cpu'):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim # 词向量维度
self.hidden_dim = hidden_dim # 隐层维度
self.vocab_size = len(vocab) # 词表大小
self.tagset_size = len(label_map) # 标签个数
self.device = device
# 记录状态,'train'、'eval'、'pred'对应三种不同的操作
self.state = 'train' # 'train'、'eval'、'pred'
self.word_embeds = nn.Embedding(self.vocab_size, embedding_dim)
# BiLSTM会将两个方向的输出拼接,维度会乘2,所以在初始化时维度要除2
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=2, bidirectional=True, batch_first=True)
# BiLSTM 输出转化为各个标签的概率,此为CRF的发射概率
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size, bias=True)
# 初始化CRF类
self.crf = CRF(label_map, device)
self.dropout = nn.Dropout(p=0.5, inplace=True)
self.layer_norm = nn.LayerNorm(self.hidden_dim)
def _get_lstm_features(self, sentence, seq_len):
embeds = self.word_embeds(sentence)
self.dropout(embeds)
# 输入序列进行了填充,但RNN不能对填充后的'PAD'也进行计算,所以这里使用了torch自带的方法
packed = torch.nn.utils.rnn.pack_padded_sequence(embeds, seq_len, batch_first=True, enforce_sorted=False)
lstm_out, _ = self.lstm(packed)
seq_unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
seqence_output = self.layer_norm(seq_unpacked)
lstm_feats = self.hidden2tag(seqence_output)
return lstm_feats
# 另一种实现RNN处理不等长序列的方式
def __get_lstm_features(self, sentence, seq_len):
max_len = sentence.shape[1]
mask = [[1] * seq_len[i] + [0] * (max_len - seq_len[i]) for i in range(sentence.shape[0])]
embeds = self.word_embeds(sentence)
self.dropout(embeds)
mask = torch.tensor(mask, dtype=torch.float32, device=self.device)
input = embeds * mask.unsqueeze(2)
lstm_out, _ = self.lstm(input)
seqence_output = self.layer_norm(lstm_out)
lstm_feats = self.hidden2tag(seqence_output)
return lstm_feats
def forward(self, sentence, seq_len, tags=''):
# 输入序列经过BiLSTM得到发射概率
feats = self._get_lstm_features(sentence, seq_len)
# 根据 state 判断哪种状态,从而选择计算损失还是维特比得到预测序列
if self.state == 'train':
loss = self.crf.neg_log_likelihood(feats, tags, seq_len)
return loss
elif self.state == 'eval':
all_tag = []
for i, feat in enumerate(feats):
# path_score, best_path = self.crf._viterbi_decode(feat[:seq_len[i]])
all_tag.append(self.crf._viterbi_decode(feat[:seq_len[i]])[1])
return all_tag
else:
return self.crf._viterbi_decode(feats[0])[1]
训练过程
数据预处理和模型写好了之后,训练和验证过程就简单了,还是那一套标准的流程。
embedding_size = 128
hidden_dim = 768
epochs = 50
batch_size = 32
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = BiLSTM_CRF(embedding_size, hidden_dim, train_dataset.vocab, train_dataset.label_map, device).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
def train():
total_start = time.time()
best_score = 0
for epoch in range(epochs):
epoch_start = time.time()
model.train()
model.state = 'train'
for step, (text, label, seq_len) in enumerate(train_dataloader, start=1):
start = time.time()
text = text.to(device)
label = label.to(device)
seq_len = seq_len.to(device)
loss = model(text, label, seq_len)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'Epoch: [{epoch + 1}/{epochs}],'
f' cur_epoch_finished: {step * batch_size / len(train_dataset) * 100:2.2f}%,'
f' loss: {loss.item():2.4f},'
f' cur_step_time: {time.time() - start:2.2f}s,'
f' cur_epoch_remaining_time: {datetime.timedelta(seconds=int((len(train_dataloader) - step) / step * (time.time() - epoch_start)))}',
f' total_remaining_time: {datetime.timedelta(seconds=int((len(train_dataloader) * epochs - (len(train_dataloader) * epoch + step)) / (len(train_dataloader) * epoch + step) * (time.time() - total_start)))}')
# 每周期验证一次,保存最优参数
score = evaluate()
if score > best_score:
print(f'score increase:{best_score} -> {score}')
best_score = score
torch.save(model.state_dict(), './model.bin')
print(f'current best score: {best_score}')
def evaluate():
# model.load_state_dict(torch.load('./model1.bin'))
all_label = []
all_pred = []
model.eval()
model.state = 'eval'
with torch.no_grad():
for text, label, seq_len in tqdm(valid_dataloader, desc='eval: '):
text = text.to(device)
seq_len = seq_len.to(device)
batch_tag = model(text, label, seq_len)
all_label.extend([[train_dataset.label_map_inv[t] for t in l[:seq_len[i]].tolist()] for i, l in enumerate(label)])
all_pred.extend([[train_dataset.label_map_inv[t] for t in l] for l in batch_tag])
all_label = list(chain.from_iterable(all_label))
all_pred = list(chain.from_iterable(all_pred))
sort_labels = [k for k in train_dataset.label_map.keys()]
# 使用sklearn库得到F1分数
f1 = metrics.f1_score(all_label, all_pred, average='macro', labels=sort_labels[:-3])
print(metrics.classification_report(
all_label, all_pred, labels=sort_labels[:-3], digits=3
))
return f1
train()
评分结果
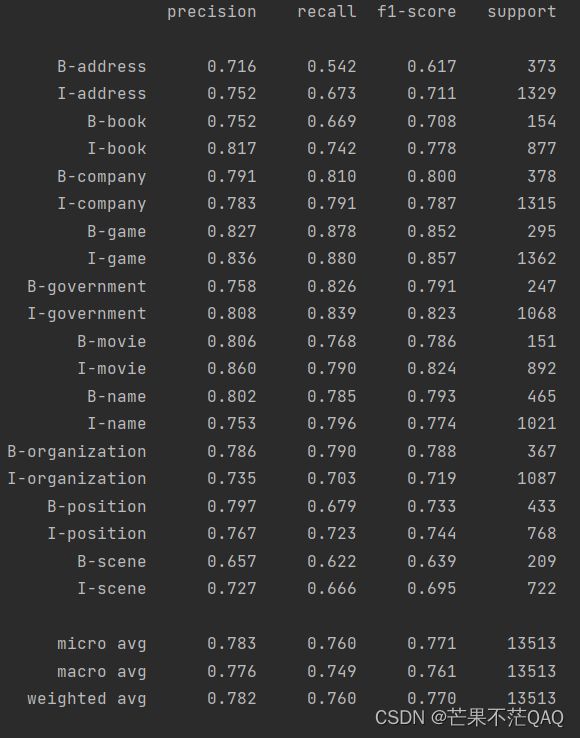
BiLSTM+CRF训练的最优结果如下,当然调调参还会更高。
需要说明的是,这里的分数是字级别的分数,而不是实体级别的分数。CLUENER的github链接上的分数指标是实体级别,相对于字级别会偏低。后续我会在本文github中加入实体级别,可收藏关注哦~~
备注
如需使用此代码,不要无脑复制该网页的所有代码,可有选择的复制或直接下载github代码。
预测脚本
新增了预测脚本,只能处理单条数据,若想处理多条数据,可以在外面套个循环,代码已更新到github上。由于写预测脚本时也改动了一点其他函数,所以推荐重新下载所有文件。
import torch
from BiLSTM_CRF.data_processor import get_vocab, get_label_map
from BiLSTM_CRF.model import BiLSTM_CRF
embedding_size = 128
hidden_dim = 768
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 加载训练时保存的词表
vocab = get_vocab()[0]
# 加载训练时保存的标签字典
label_map, label_map_inv = get_label_map()
# 创建模型并加载模型参数
model = BiLSTM_CRF(embedding_size, hidden_dim, vocab, label_map, device)
model.load_state_dict(torch.load('./model.bin'))
model.to(device)
text = '浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,'
model.eval()
model.state = 'pred'
with torch.no_grad():
text = [vocab.get(t, vocab['UNK']) for t in text]
seq_len = torch.tensor(len(text), dtype=torch.long).unsqueeze(0)
seq_len = seq_len.to(device)
text = torch.tensor(text, dtype=torch.long).unsqueeze(0)
text = text.to(device)
batch_tag = model(text, seq_len)
pred = [label_map_inv[t] for t in batch_tag]
print(pred)
print(chunks_extract(pred))
模型输出的结果为一个一个标签,最终想要的结果为一个一个实体,所以需要对输出进行实体提取。下面函数输入标签列表,输出实体类别和实体对应的索引。
def chunks_extract(pred):
if not pred:
return []
cur_entity = None
res = []
st_idx, end_idx = 0, 0
for i, pred_single in enumerate(pred):
pred_start_B = pred_single.startswith('B')
pred_entity = pred_single.split('-')[-1]
if cur_entity:
if pred_start_B or cur_entity != pred_entity:
res.append({
'st_idx': st_idx,
'end_idx': i,
'label': cur_entity
})
cur_entity = None
if pred_start_B:
st_idx = i
cur_entity = pred_entity
if cur_entity:
res.append({
'st_idx': st_idx,
'end_idx': len(pred),
'label': cur_entity,
})
return res