SE、CBAM、ECA注意力机制(网络结构详解+详细注释代码+核心思想讲解+注意力机制优化神经网络方法)——pytorch实现
这期博客我们来学习一下神秘已久的注意力机制,刚开始接触注意力机制的时候,感觉很有意思,事实上学会之后会发现比想象中的要简单,复杂的注意力机制后续会讲解,这期博客先讲解最常见的三种SE、CBAM、ECA注意力机制。
注意力机制更详细的可以被称为资源分配机制,神经网络的计算能力是有限的,因为我们为了在有限的资源下提高神经网络的准确性,因此我们要对识别对象的重要特征,增加更多的资源(在神经网络中叫做权重)用来提高识别的准确率。卷积神经网络特征的提取,越来越成为大家研究的重点,由于卷积神经网络提取特征时对于每部分特征的提取都是相同权重,并不能专注于有效特征的提取,反而提取了很多无用的特征,增大运算量,因此跟人类相似的注意力机制(专注有效特征提取的方式)得到了发展。注意力机制思想的引入主要在于使得卷积神经网络提取有效的特征,删掉无用的特征。事实上卷积神经网络并不能算是人工智能,我用一个简单的例子来形容就是:假如我们要识别一个人,卷积神经网络更像是一个扫描仪,对着当前的图像进行扫描,根据胳膊,腿,身材等部分综合判断(每部分占的权重一样),然后得出结论这是我们要识别的那个人,但是真正的人我们在现实生活中识别人的时候往往是这个人的脸是占更大权重的,比如说一个人他瘦了好多,我们也能认出来他,因为只要他没整容,他的脸对于我们对他的身份进行识别就占决定性作用。因此在我们对人进行识别的过程中,我们需要更在意他的脸,身材等其他部分占的权重非常少,这就是注意力机制的思想。注意力机制极大的提高了人处理图像的效率,准确性和速度,深度学习的注意力机制跟人类的注意力机制类似,或者说深度学习中注意力机制的发展就是借鉴了人类注意力机制的思想。
大家对注意力机制的理解可能存在某种误解,其实这东西很简单,不管是哪类注意力机制,都类似一个插件,可以各类卷积神经网络或者目标检测网络中对网络进行优化,使网络关注到更重要的特征,类似SENET是从通道领域关注到通道类特征,类似CBAM,从通道和空间领域对重要特征进行优化等等,东西很简单,就放到卷积神经网络的卷积层之后就行了,当然你也可以放到更有意思的地方,根据你对网络改进的需要,当然我只是想表达这个东西不难,很容易的意思。因为放置注意力机制一般也不会改变特征的通道数,所以就是个万能插件,代码放进去就能用。可以插入各类CNN分类网络和YOLO系列和RCNN系列的算法中进行优化,是个简单好用的trick。
SE(通道注意力机制):
论文下载地址:https://arxiv.org/pdf/1709.01507v2.pdf
论文名称:Squeeze-and-Excitation Networks,翻译过来是:挤压和激励网络
网络结构图如下:
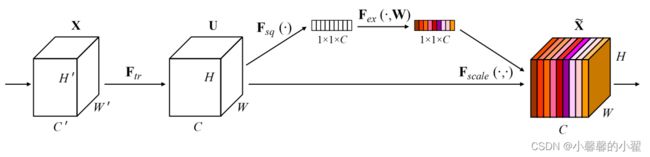
SE通道注意力机制的流程:
1、对输入的图像特征进行全部平均池化。
2、再将图像特征经过两个全连接层,第二个全连接层的神经元个数与输入特征层相同,这样也保证了图像的通道数不会改变。
3、最后使用Sigmod函数将输出限制到(0-1)之间,然后作为通道注意力机制产生的权重,跟原特征图进行相乘,获取最终的加入注意力机制的提取后的特征图。
SENET代码:
import torch.nn as nn
class SE_block(nn.Module):
def __init__(self, channel, scaling=16): #scaling为缩放比例,
# 用来控制两个全连接层中间神经网络神经元的个数,一般设置为16,具体可以根据需要微调
super(SE_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // scaling, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // scaling, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
CBAM(混合注意力机制)
论文下载链接:https://arxiv.org/abs/1807.06521
论文名称:CBAM: Convolutional Block Attention Module翻译过来是CBAM卷积块注意力模块
CBAM之所以被叫做混合注意力机制,是因为相较于SENET通道注意力机制,他在保留原有通道注意力机制的基础上加入了空间注意力机制,从通道和空间两个方面对网络进行优化,使得优化后的网络可以从通道和空间两个角度获取更为有效的特征,进一步提高模型同时在通道和空间两个角度的特征提取效果,结构图如下图所示:
CBAM结构图
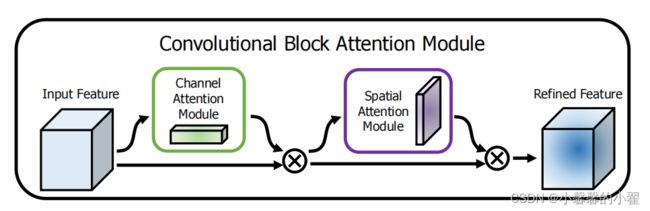
Channel Attention Module:通道注意力机制模块
Spatial Attention Module:空间注意力机制模块
CBAM会对输入的图像分别进行通道注意力机制和空间注意力机制的处理,两个模块是串联在一起的如上图所示,输入的图像进行先经过通道注意力机制,再通过空间注意力机制两个处理,最终形成通道权重,与输入的图像相乘,得到最终的图像特征图。下面分别介绍通道注意力机制和空间注意力机制的结构。
Channel Attention Module:通道注意力机制模块
通道注意力机制的结果如上图所示,他跟SENET这个通道注意力机制还有点不一样,CBAM的通道注意力机制模块,首先对输入的图像分别同时进行最大池化和平均池化两个处理,然后将最大池化和平均池化的结果分别输出共享的全连接层进行处理,然后将两者处理的结果进行叠加,然后使用Sigmoid函数缩放到(0-1)之间,作为通道注意力机制权重,最后与输入图像进行相乘,获得最后的图像特征图。
Spatial Attention Module:空间注意力机制模块
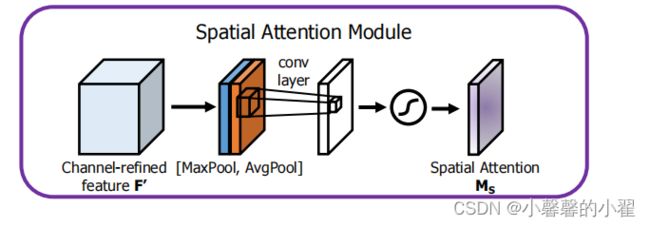
空间注意力机制的结构如上图所示,空间注意力机制对于输入的特征图,进行最大池化处理和平均池化处理,然后将两者处理的结果在同一维度上进行堆叠,再利用一个1*1的卷积调整通道数,不改变通道数,最后使用Sigmoid函数缩放到(0-1)之间,作为通道注意力机制权重,最后与输入图像进行相乘,获得最后的图像特征图。
CBAM代码:
import torch.nn as nn
import torch
class ChannelAttention(nn.Module): #通道注意力机制
def __init__(self, in_planes, scaling=16):#scaling为缩放比例,
# 用来控制两个全连接层中间神经网络神经元的个数,一般设置为16,具体可以根据需要微调
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // scaling, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // scaling, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
out = self.sigmoid(out)
return out
class SpatialAttention(nn.Module): #空间注意力机制
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
x = self.sigmoid(x)
return x
class CBAM_Attention(nn.Module):
def __init__(self, channel, scaling=16, kernel_size=7):
super(CBAM_Attention, self).__init__()
self.channelattention = ChannelAttention(channel, scaling=scaling)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
ECA(通道注意力机制的改进版)
论文下载链接:https://arxiv.org/pdf/1910.03151.pdf
论文题目:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
翻译过来ECA Net:有效的通道注意力机制深度卷积神经网络
ECA事实上是SENET的改进版,它去除了原来SENET中的全连接层,换成了1*1的卷积核进行处理,使得模型参数变小,变得更加轻量级,因为ECA的作者认为卷积具有良好的跨通道信息捕捉能力,因此捕捉所有通道的信息是没必要的,因此取消了全连接层,换成了1*1的卷积。
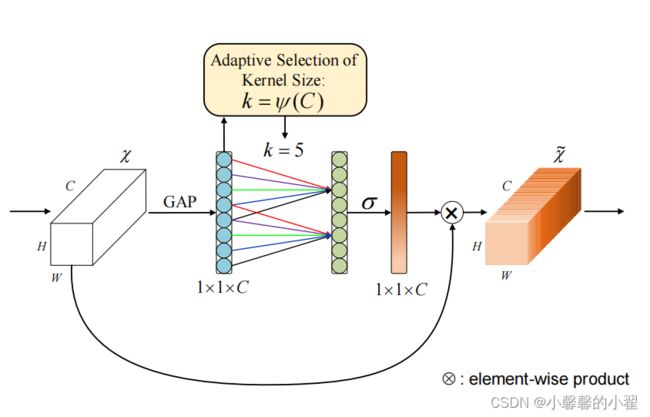
ECA代码:
import torch.nn as nn
import math
class ECA_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(ECA_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
out = x * y.expand_as(x)
return out
如何使用注意力机制优化神经网络:
将注意力机制放在网络的卷积层之后即可,
类似我之前用来优化Alexnet和Resnet,代码如下图所示:
class alexnet(nn.Module):
def __init__(self):
super(alexnet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
SENET(48 , r = 0.5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
SENET(128, r=0.5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
SENET(192, r=0.5),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
SENET(192, r=0.5),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
SENET(128, r=0.5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7),
)
def forward(self , x):
x = self.model(x)
return x
class SENET(nn.Module):
def __init__(self, channel, r=0.5): # channel为输入的维度, r为全连接层缩放比例->控制中间层个数
super(SENET, self).__init__()
# 全局均值池化
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
# 全连接层
self.fc = nn.Sequential(
nn.Linear(channel, int(channel * r)), # int(channel * r)取整数 #通道压缩
nn.ReLU(), # relu激活函数进行激活 ()激励
nn.Linear(int(channel * r), channel), # 展开
nn.Sigmoid(), # 折算成0到1之间的权重
)
def forward(self, x):
# 对x进行分支计算权重, 进行全局均值池化
branch = self.global_avg_pool(x) # 前向传播先平均池化
branch = branch.view(branch.size(0), -1) # 展开
# 全连接层得到权重
weight = self.fc(branch) # 经过全连接得到权重
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘 即乘以权重
hi, wi = weight.shape
weight = torch.reshape(weight, (hi, wi, 1, 1))
# 乘积获得结果
scale = weight * x # weight为权重 x为输入的 输出结果
return scale因为并不会改变通道数,因此不用修改代码,直接放到卷积层后面就行了,很简单,有问题朋友欢迎在评论区指出,感谢!

下面给出上述三个代码和下载好的论文下载链接:
https://pan.baidu.com/s/1aPXJ4O_el-ZxCsZWpQMnbw
提取码:fd1i