Java-Stream流式编程详解
目录
一、概述
1.1、特性: 不存储数据、不改变数据源、不可重复使用
1.2、生成流的方式
1.3、反转流到集合
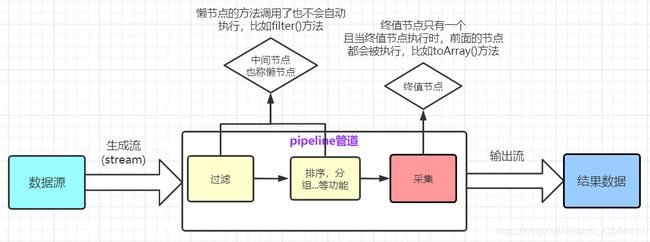
二、中间节点与终值节点
2.1、中间节点
2.2、终值节点
三、Stream的方法
3.1、迭代:peek()
3.2、终点:foreach()
3.3、流式处理
3.4、采集置换:collect()
一、概述
将集合或数组 转换成一种流的元素序列。流不是集合中的元素,也不是一种数据结构,不负责数据的存储。Stream 流也不会改变源对象(源集合)Stream 接口中几乎所有方法的参数都是四大函数式接口接口类型的参数。而函数式接口可以使用 lambda 表达式来简化开发,并且 Stream 接口中的方法基本都是返回对象本身(返回对象本身的方法可以使用链式编程)。所以在使用 Stream 流式计算时,基本上都用到了函数式接口、lambda表达式 和 链式编程。
1.1、特性: 不存储数据、不改变数据源、不可重复使用
可以看作一根管道,用于数据的转换,所以不会存储数据,也不会影响原来的数据。因为stream是一根管道,不可重复使用就是stream用完一次之后,数据就输出了
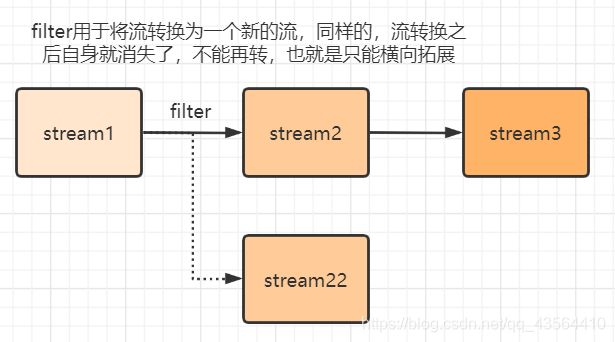
Stream stream1 = Stream.of(1,2,3);
//创建stream2过滤stream1
Stream stream2 = stream1.filter(s->s.equals(1));
//下句代码会出错,因为stream1流用过一次,消失了
Stream stream3 = stream1.filter(s->s.equals(1));1.2、生成流的方式
Array.stream()-用于基本类型
parallelStream() 是并行流方法,并行流就是把内容分成多个数据块,使用不同的线程分别处理每个数据块的流。
Arrays.stream(new int[]{1,2,3}); //使用Array的静态方法创建流但要注意的是,不是所有情况的适合,有些时候并行甚至比顺序进行效率更低,而有时候因为线程安全问题,还可能导致数据的处理错误,因此并行的性能问题非常值得我们思考。下面这个例子就比较慢,因为JVM对基本类型还要装箱开箱操作,不如直接串行计算了
int i = Stream.iterate(1, a -> a + 1).limit(100).parallel().reduce(0, Integer::sum);Stream.of()-用于任何类型
Stream.of(1,"小明",2,new ArrayList<>()); //使用Stream的静态方法创建流Stream.iterate-函数流
//iterate() : 依次对每个新生成的值应用函数; generate() :接受一个函数,生成一个新的值
//生成流,首元素为 0,之后依次加 2
Stream.iterate(0, n -> n + 2)
//生成流,为 0 到 1 的随机双精度数
Stream.generate(Math :: random)
//生成流,元素全为 1
Stream.generate(() -> 1)Files.lines()-用于文件流
Stream stream = Files.lines(Paths.get(“data.txt”));XXX.stream()-用于集合
Collection collection = new ArrayList();
collection.stream(); // 使用Collection类里的成员方法stream()方式创建流1.3、反转流到集合
一般是用Stream.collect()的方法来实现的,下面给一个转为List的例子
public static void main(String[] args) {
// 将数组变成一个列表集合
List list = Arrays.asList(14, 3, 5, 7, 12);
// List集合获取 Stream 流
Stream stream = list.stream();
// 操作 Stream 流
List collect = stream
// 获取 > 5 的元素
.filter((i) -> { return i > 5; })
// 对元素进行升序排序
.sorted()
// 将 Stream 流转换成 List 集合
.collect(Collectors.toList());
// 遍历 转换后的 List 集合
for (Integer i : collect) {
System.out.println(i);
}
} 二、中间节点与终值节点
2.1、中间节点
懒节点不会自动执行,所以下例代码不会打印hello
public static void main(String[] args) {
List list = new ArrayList();
Stream.of(list).filter(a->{
System.out.println("hello");
return true;
}); //没有打印结果
}2.2、终值节点
这时在最后加了.toArray()方法,相当于加上了终值节点,那么此时终值节点+前面的节点都会执行
public static void main(String[] args) {
List list = new ArrayList();
Stream.of(list).filter(a->{
System.out.println("hello");
return true;
}).toArray(); //打印输出hello
}可以查看Stream的API,如果方法的返回值为Stream
三、Stream的方法
常用的方法如下:
- 中间节点:filter()、map()、mapToInt()、flatMap()、sorted()、peek()、reduce()、distinct()
- 终值节点:forEach()、toArray()、collect()

@Data
public class AppleStore {
int id; //编号
String color; //颜色
double weight; //重量
String origin; //产地
}3.1、迭代:peek()
public class StreamTest {
private static List appleStores = new ArrayList();
static {
appleStores.add(new AppleStore(1,"red",1.2,"重庆"));
appleStores.add(new AppleStore(2,"red",1.5,"四川"));
appleStores.add(new AppleStore(3,"yellow",2.6,"重庆"));
appleStores.add(new AppleStore(4,"yellow",2.9,"四川"));
appleStores.add(new AppleStore(5,"red",3.2,"杭州"));
}
public static void main(String[] args) {
//peek()是执行每个节点的方法
//peek里的方法会挨个执行,也就是节点会挨个执行,也称作责任链模式
appleStores.stream().peek(appleStore -> System.out.println(appleStore.getColor())) //打印苹果的颜色
.peek(appleStore -> System.out.println(appleStore.getWeight())) //打印苹果的重量
.peek(appleStore -> System.out.println(appleStore.getOrigin())) //打印苹果的产地
.toArray();
}
}
red1.2重庆
red1.5四川
yellow2.6重庆
yellow2.9四川
red3.2杭州 3.2、终点:foreach()
foreach功能和peek相同,不同是foreach是终值节点,也就是不能再往下继续执行,但执行的结果是和上面是一样的。
appleStores.stream().peek(apple -> System.out.println(apple.getColor())) //打印苹果编号
.peek(apple -> System.out.println(apple.getWeight())) //打印苹果颜色
.forEach(sout-> System.out.println(sout.getOrigin()));
red1.2重庆
red1.5四川
yellow2.6重庆
yellow2.9四川
red3.2杭州3.3、流式处理
3.3.1、过滤:filter(Predicate predicate)
@Test
public void name2() {
appleStores.stream().filter(appleStore -> appleStore.getColor().equals("red")) //过滤出红色的苹果
.peek(appleStore -> System.out.println(appleStore)) //到第二个节点只有红色苹果的数据了
.toArray();
}
AppleStore(id=1, color=red, weight=1.2, origin=重庆)
AppleStore(id=2, color=red, weight=1.5, origin=四川)
AppleStore(id=5, color=red, weight=3.2, origin=杭州)3.3.2、转换:map(Function mapper)
@Test
public void name3() {
//此时数据全部变成了String字符串 因为map中的方法是getColor(),映射成为的是String,对象Stream
appleStores.stream().map(appleStore -> appleStore.getColor()) //获取苹果的颜色
.peek(color -> System.out.print(color+"--"))//循环的是Stream
.toArray();
}
red--red--yellow--yellow--red-- 3.3.3、去重:distinct()
@Test
public void name4() {
appleStores.stream().map(appleStore -> appleStore.getColor()) //获取苹果的颜色
.distinct() //去重
.peek(color -> System.out.print(color+"--"))
.toArray();
}
red--yellow3.3.4、排序:Comparator comparator
@Test
public void name5() {
List collect = appleStores.stream() // 获取appleStores的流
.map(appleStore -> appleStore.getId()) // 转换功能:获取id,从List转换成了List
// 从小到大排序 (本质是调用compareTo()方法,所以类要实现CompareAble接口)
.sorted()
//从大到小排序
.sorted(Comparator.reverseOrder())
// 多字段排序,升序排序(先根据年龄排序,如果年龄相同,则年龄相同的用户根据 id 排序),多字段需要自己实现,也可以用自带的API排序
.sorted(Comparator.comparing(User::getAge).thenComparing(User::getId))
.limit(3) // 取前三个元素
.collect(Collectors.toList()); //将stream流转回List集合
System.out.println(collect);
} 3.3.5、截取:limit(long maxSize) 截取(截取前面n个元素)
public static void main(String[] args) {
// 将数组变成一个列表集合
List list = Arrays.asList(5, 3, 7, 9, 4);
// 获取集合的 Stream 流对象
list.stream()
// 截取(截取前面前4个元素)
.limit(4)
// 遍历
.forEach(System.out::println);
} 3.3.6、丢弃:skip(long n) 丢弃(丢弃前面n个元素)
public static void main(String[] args) {
// 将数组变成一个列表集合
List list = Arrays.asList(5, 3, 7, 9, 4);
// 获取集合的 Stream 流对象
list.stream()
// 丢弃(丢弃前面4个元素)
.skip(4)
// 遍历
.forEach(System.out::println);
} 3.3.7、计数:count() 计数(返回流中元素个数)
public static void main(String[] args) {
// 将数组变成一个列表集合
List list = Arrays.asList(5, 3, 7, 9, 4);
// 获取集合的 Stream 流中元素个数
long count = list.stream().count();
} 3.3.8、拼接:concat(Stream a, Stream b) 拼接(对两个流对象进行拼接)
public static void main(String[] args) {
// 将数组变成一个列表集合
List list_01 = Arrays.asList(1, 2, 3, 4, 5);
List list_02 = Arrays.asList(6, 7, 8, 9, 0);
// 将两个 Stream 流拼接(首尾合并),成一个新的 Stream 流
Stream stream = Stream.concat(list_01.stream(), list_02.stream());
stream.forEach(System.out::println);
} 3.3.9、比较:Optional max(Comparator comparator) 根据Comparator比较器获取最大的元素
public static void main(String[] args) {
// 将数组变成一个列表集合
List list = Arrays.asList(5, 3, 7, 9, 4);
// 获取序列中的值最大的元素
Optional max = list.stream().max(Comparator.comparing((integer -> integer)));
// 获取序列中的值最小的元素
Optional max = list.stream().min(Comparator.comparing((integer -> integer)));
System.out.println(max.get());
} 3.3.10、分割:flatMap(T -> Stream) 将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流
@Test
public void name6() {
List list = new ArrayList<>();
list.add("aaa bbb ccc");
list.add("ddd eee fff");
list.add("ggg hhh iii");
list = list.stream().map(s -> s.split(" ")).flatMap(Arrays::stream).collect(Collectors.toList());
System.out.println(list);
}
//[aaa, bbb, ccc, ddd, eee, fff, ggg, hhh, iii] 3.3.11、匹配: xxxMatch(T -> boolean)
//是否存在一个 person 对象的 age 等于 20:
boolean b = list.stream().anyMatch(person -> person.getAge() == 20);
//是否所有元素都匹配给定的 T -> boolean 条件
boolean result = list.stream().allMatch(Person::isStudent);
//是否没有元素匹配给定的 T -> boolean 条件
boolean result = list.stream().noneMatch(Person::isStudent);3.3.12、查找:findAny() 和 findFirst()
- indAny():找到其中一个元素 (使用 stream() 时找到的是第一个元素;使用 parallelStream()并行时找到的是其中一个元素)
- findFirst():找到第一个元素
值得注意的是,这两个方法返回的是一个 Optional 对象,它是一个容器类,能代表一个值存在或不存在。
3.3.13、归约:reduce((T, T) -> T) 和 reduce(T, (T, T) -> T)
将集合中的所有元素经过指定运算,折叠成一个元素输出,如:求最值、平均数等,这些操作都是将一个集合的元素折叠成一个元素输出。在流中,reduce函数能实现归约。reduce函数接收两个参数:初始值和进行归约操作的Lambda表达式(用于组合流中的元素,如求和,求积,求最大值等)
int age = list.stream().reduce(0, (person1,person2)->person1.getAge()+person2.getAge());
//计算年龄总和:
int sum = list.stream().map(Person::getAge).reduce(0, (a, b) -> a + b);
//与之相同:其中,reduce 第一个参数 0 代表起始值为 0,lambda (a, b) -> a + b 即将两值相加产生一个新值
int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum);
//计算年龄总乘积:
int sum = list.stream().map(Person::getAge).reduce(1, (a, b) -> a * b);
//当然也可以: 即不接受任何起始值,但因为没有初始值,需要考虑结果可能不存在的情况,因此返回的是 Optional 类型
Optional sum = list.stream().map(Person::getAge).reduce(Integer::sum);3.4、采集置换:collect()
Stream采集功能分为List、map、group by、数组、求最大值、求任意值等
@Test
public void name5() {
List collect = appleStores.stream() // 获取appleStores的流
.map(appleStore -> appleStore.getId()) // 转换功能:获取id,从List转换成了List
.limit(3) // 取前三个元素
.collect(Collectors.toList()); //将stream流转回List集合,依赖Collectors类中的几个toXxx()方法
System.out.println(collect);
}
[1, 2, 3]