hive基础
目录
DDL(data definition language)
创建数据库
创建表
hive中数据类型
create table as select建表
create table like语法
修改表名
修改列
更新列
替换列
清空表
关系运算符
聚合函数
字符串函数
substring:截取字符串
replace :替换
regexp_replace:正则替换
regexp:正则匹配
repeat:重复字符串
split :字符串切割
nvl :替换 null 值
concat :拼接字符串
concat_ws:以指定分隔符拼接字符串或者字符串数组
get_json_object:解析 json 字符串
日期函数
unix_timestamp:返回当前或指定时间的时间戳
from_unixtime:转化 UNIX 时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到 当前时区的时间格式
current_date:当前日期
current_timestamp:当前的日期加时间,并且精确的毫秒
month:获取日期中的月
day:获取日期中的日
hour:获取日期中的小时
datediff:两个日期相差的天数(结束日期减去开始日期的天数
date_add:日期加天数
date_sub:日期减天数
date_format:将标准日期解析成指定格式字符串
流程控制函数
case when:条件判断函数
if: 条件判断,类似于 Java 中三元运算符
集合函数
size:集合中元素的个数
map:创建 map 集合
map_keys: 返回 map 中的 key
map_values: 返回 map 中的 value
array 声明 array 集合
array_contains: 判断 array 中是否包含某个元素
sort_array:将 array 中的元素排序
struct 声明 struct 中的各属性
named_struct 声明 struct 的属性和值
collect_list 收集并形成 list 集合,结果不去重
collect_list 收集并形成 list 集合,结果不去重collect_set 收集并形成 set 集合,结果去重
开窗函数
聚合函数
跨行取值函数
分区
增加分区
删除分区
修复分区
hive文件格式
Text File
ORC
Parquet
DDL(data definition language)
创建数据库
//
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]- TEMPORARY:临时表,该表只在当前会话可见,会话结束,表会被删除。
- EXTERNAL:外部表,与之相对应的是内部表(管理表)。管理表意味着 Hive 会完全接管该表,包括元数据和HDFS中的数据。而外部表则意味着hive只接管元数据而不接管HDFS中的数据。
- data_type:数据类型(可以使用cast进行类型转换 :cast('1' as int)+2)
- partition by :分区字段
hive中数据类型
| 数据类型 |
说明 |
| tinyint |
1byte有符号整数 |
| samllint |
2byte有符号整数 |
| int |
4byte有符号整数 |
| bigint |
8byte有符号整数 |
| boolean |
布尔类型 |
| float |
单精度浮点数 |
| double |
双精度浮点数 |
| decimal |
十进制精准数字类型 |
| varchar |
字符序列 需指定最大长度 |
| string |
字符串 无需指定最大长度 |
| timestamp |
时间类型 |
| binary |
二进制数据 |
| array |
数组类型 |
| map |
|
| struct |
结构体 |
create table as select建表
该语法允许用户利用 select 查询语句返回的结果,直接建表,表的结构和查询语句的 结构保持一致,且保证包含 select 查询语句放回的内容
create table like语法
该语法允许用户复刻一张已经存在的表结构,与上述的 CTAS 语法不同,该语法创建出来的表中不包含数据
修改表名
ALTER TABLE table_name RENAME TO new_table_name 修改列
// 该语句允许用户增加新的列,新增列的位置位于末尾。
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)更新列
// 该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]替换列
该语句允许用户用新的列集替换表中原有的全部列。
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)清空表
truncate 只能清空管理表,不能删除外部表中数据。
TRUNCATE [TABLE] table_name关系运算符
| 操作符 |
描述 |
| A=B |
|
| A<=>B |
如果 A 和 B 都为 null 或者都不为 null,则返回 true,如果只有一边为 null,返回 false |
| A<>B,A!=B |
A或者 B 为 null 则返回 null;如果 A 不等于 B,则返回 true,反之返回 false |
| A |
A 或者 B 为 null,则返回 null;如果 A 小于 B,则返回 true,反之返回 false |
| A<=B |
A 或者 B 为 null,则返回 null;如果 A 小于等于 B,则返 回 true,反之返回 false |
| A>B |
A 或者 B 为 null,则返回 null;如果 A 大于 B,则返回 true,反之返回 false |
| A>=B |
A 或者 B 为 null,则返回 null;如果 A 大于等于 B,则返 回 true,反之返回 false |
| A [not] between B and C |
如果 A,B 或者 C 任一为 null,则结果为 null。如果 A 的 值大于等于 B 而且小于或等于 C,则结果为 true,反之为 false。如果使用 not 关键字则可达到相反的效果。 |
| A is null |
如果 A 等于 null,则返回 true,反之返回 false |
| A is not null |
如果 A 不等于 null,则返回 true,反之返回 false |
| in(数值 1,数值 2) |
使用 in 运算显示列表中的值 |
| A [not] like B |
B 是一个 SQL 下的简单正则表达式, 如果 A 与其匹配的话,则返回 true;反之返回 false。B 的表达式说明如下:‘x%’表示 A 必须以字母‘x’开头, ‘%x’表示 A 必须以字母‘x’结尾,而‘%x%’表示 A |
| A rlike B, A regexp B |
B 是基于 java 的正则表达式,如果 A 与其匹配,则返回 true;反之返回 false。匹配使用的是 JDK 中的正则表达式 接口实现的,因为正则也依据其中的规则。例如,正则 表达式必须和整个字符串 A 相匹配,而不是只需与其字 符串匹配。 |
聚合函数
| 操作符 |
描述 |
| count(*) |
统计所有行数,包含null值 |
| count(某列) |
统计该列有多少行,不包括null值 |
| max() |
求最大值,不包括null,除非所有值都是null |
| min() |
求最小值,不包括null,除非所有值都是null |
| sum() |
求和,不包括null |
| avg() |
求平均值,不包括null |
字符串函数
substring:截取字符串
语法一:substring(string A, int start) 返回值:string
说明:返回字符串 A 从 start 位置到结尾的字符串 语法二:substring(string A, int start, int len) 返回值:string
说明:返回字符串 A 从 start 位置开始,长度为 len 的字符串
(1)获取第二个字符以后的所有字符 hive> select substring("atguigu",2);
输出:
tguigu
(2)获取倒数第三个字符以后的所有字符 hive> select substring("atguigu",-3);
输出:
igu
(3)从第 3 个字符开始,向后获取 2 个字符 hive> select substring("atguigu",3,2);
输出:
gureplace :替换
语法:replace(string A, string B, string C) 返回值:string
说明:将字符串 A 中的子字符串 B 替换为 C。 hive> select replace('atguigu', 'a', 'A')
输出:
hive> Atguiguregexp_replace:正则替换
语法:regexp_replace(string A, string B, string C)
返回值:string
说明:将字符串 A 中的符合 java 正则表达式 B 的部分替换为 C。注意,在有些情况下
要使用转义字符。
案例实操:
hive> select regexp_replace('100-200', '(\\d+)', 'num')
输出:
hive> num-numregexp:正则匹配
语法:字符串 regexp 正则表达式
返回值:boolean
说明:若字符串符合正则表达式,则返回 true,否则返回 false。
(1)正则匹配成功,输出 true
hive> select 'dfsaaaa' regexp 'dfsa+'
输出:
hive> true
(2)正则匹配失败,输出 false
hive> select 'dfsaaaa' regexp 'dfsb+';
输出:
hive> falserepeat:重复字符串
语法:repeat(string A, int n) 返回值:string
说明:将字符串 A 重复 n 遍。 hive> select repeat('123', 3);
输出:
hive> 123123123split :字符串切割
语法:split(string str, string pat)
返回值:array
说明:按照正则表达式 pat 匹配到的内容分割 str,分割后的字符串,以数组的形式返
回。
hive> select split('a-b-c-d','-');
输出:
hive> ["a","b","c","d"]nvl :替换 null 值
语法:nvl(A,B)
说明:若 A 的值不为 null,则返回 A,否则返回 B。 hive> select nvl(null,1);
输出:
hive> 1concat :拼接字符串
语法:concat(string A, string B, string C, ......) 返回:string
说明:将 A,B,C......等字符拼接为一个字符串
hive> select concat('beijing','-','shanghai','-','shenzhen');
输出:
hive> beijing-shanghai-shenzhenconcat_ws:以指定分隔符拼接字符串或者字符串数组
语法:concat_ws(string A, string...| array(string)) 返回值:string
说明:使用分隔符 A 拼接多个字符串,或者一个数组的所有元素。 hive>select concat_ws('-','beijing','shanghai','shenzhen');
输出:
hive> beijing-shanghai-shenzhen
hive> select concat_ws('- ',array('beijing','shenzhen','shanghai'));
输出:
hive> beijing-shanghai-shenzhenget_json_object:解析 json 字符串
语法:get_json_object(string json_string, string path)
返回值:string
说明:解析 json 的字符串 json_string,返回 path 指定的内容。如果输入的 json 字符串
无效,那么返回 NULL。
1.获取 json 数组里面的 json 具体数据
hive> select get_json_object('[{"name":"大海海","sex":"男
","age":"25"},{"name":"小宋宋","sex":"男 ","age":"47"}]','$.[0].name');
输出:
hive> 大海海
2.获取 json 数组里面的数据
hive> select get_json_object('[{"name":"大海海","sex":"男 ","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0]');
输出:
hive> {"name":"大海海","sex":"男","age":"25"}日期函数
unix_timestamp:返回当前或指定时间的时间戳
语法:unix_timestamp()
返回值:bigint
案例实操:
hive> select unix_timestamp('2022/08/08 08-08-08','yyyy/MM/dd HH- mm-ss');
输出:
1659946088from_unixtime:转化 UNIX 时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到 当前时区的时间格式
语法:from_unixtime(bigint unixtime[, string format])
返回值:string
案例实操:
hive> select from_unixtime(1659946088);
输出:
2022-08-08 08:08:08current_date:当前日期
hive> select current_date;
输出:
2022-07-11current_timestamp:当前的日期加时间,并且精确的毫秒
hive> select current_timestamp;
输出:
2022-07-11 15:32:22.402
month:获取日期中的月
语法:month (string date) 返回值:int
案例实操:
hive> select month('2022-08-08 08:08:08');
输出:
8day:获取日期中的日
语法:day (string date) 返回值:int
案例实操:
hive> select day('2022-08-08 08:08:08')
输出:
8hour:获取日期中的小时
语法:hour (string date) 返回值:int
案例实操:
hive> select hour('2022-08-08 08:08:08');
输出:
8datediff:两个日期相差的天数(结束日期减去开始日期的天数
语法:datediff(string enddate, string startdate)
返回值:int
案例实操:
hive> select datediff('2021-08-08','2022-10-09');
输出:
-427date_add:日期加天数
语法:date_add(string startdate, int days) 返回值:string
说明:返回开始日期 startdate 增加 days 天后的日期
案例实操:
hive> select date_add('2022-08-08',2);
输出:
2022-08-10date_sub:日期减天数
语法:date_sub (string startdate, int days) 返回值:string
说明:返回开始日期 startdate 减少 days 天后的日期。
案例实操:
hive> select date_sub('2022-08-08',2);
输出:
2022-08-06date_format:将标准日期解析成指定格式字符串
hive> select date_format('2022-08-08','yyyy 年-MM 月-dd 日')
输出:
2022 年-08 月-08 日流程控制函数
case when:条件判断函数
语法一:case when a then b [when c then d]* [else e] end
返回值:T
说明:如果 a 为 true,则返回 b;如果 c 为 true,则返回 d;否则返回 e
hive> select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end from tabl eName;
mary
语法二: case a when b then c [when d then e]* [else f] end
返回值: T
说明:如果 a 等于 b,那么返回 c;如果 a 等于 d,那么返回 e;否则返回 f
hive> select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from t ableName;
mary
if: 条件判断,类似于 Java 中三元运算符
语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值:T
说明:当条件 testCondition 为 true 时,返回 valueTrue;否则返回 valueFalseOrNull
(1)条件满足,输出正确
hive> select if(10 > 5,'正确','错误');
输出:正确
(2)条件满足,输出错误
hive> select if(10 < 5,'正确','错误');
输出:错误集合函数
size:集合中元素的个数
hive> select size(friends) from test; --2/2 每一行数据中的 friends 集合里的个数map:创建 map 集合
语法:map (key1, value1, key2, value2, ...)
说明:根据输入的 key 和 value 对构建 map 类型
案例实操:
hive> select map('xiaohai',1,'dahai',2);
输出:
hive> {"xiaohai":1,"dahai":2}
map_keys: 返回 map 中的 key
hive> select map_keys(map('xiaohai',1,'dahai',2));
输出:
hive>["xiaohai","dahai"]map_values: 返回 map 中的 value
hive> select map_values(map('xiaohai',1,'dahai',2));
输出:
hive>[1,2]array 声明 array 集合
语法:array(val1, val2, ...) 说明:根据输入的参数构建数组 array 类
案例实操:
hive> select array('1','2','3','4');
输出:
hive>["1","2","3","4"]
array_contains: 判断 array 中是否包含某个元素
hive> select array_contains(array('a','b','c','d'),'a');
输出:
hive> truesort_array:将 array 中的元素排序
hive> select sort_array(array('a','d','c'));
输出:
hive> ["a","c","d"]
struct 声明 struct 中的各属性
语法:struct(val1, val2, val3, ...) 说明:根据输入的参数构建结构体 struct 类
案例实操:
hive> select struct('name','age','weight');
输出:
hive> {"col1":"name","col2":"age","col3":"weight"}named_struct 声明 struct 的属性和值
hive> select named_struct('name','xiaosong','age',18,'weight',80);
输出:
hive> {"name":"xiaosong","age":18,"weight":80}collect_list 收集并形成 list 集合,结果不去重
hive>
select
sex,
collect_list(job)
from
employee
group by
sex
结果:
女 ["行政","研发","行政","前台"]
男 ["销售","研发","销售","前台"]collect_list 收集并形成 list 集合,结果不去重collect_set 收集并形成 set 集合,结果去重
hive>
select
sex,
collect_set(job)
from
employee
group by
sex
结果:
女 ["行政","研发","前台"]
男 ["销售","研发","前台"]开窗函数
聚合函数
max:最大值。
min:最小值
sum:求和
avg:平均值
count:计数跨行取值函数
常用窗口函数——lead和lag
功能:获取当前行的上/下边某行、某个字段的值。
语法:
select
order_id,
user_id,
order_date,
amount,
lag(order_date,1, '1970-01-01') over (partition by user_id order by order_date) last_date,
lead(order_date,1, '9999-12-31') over (partition by user_id order by order_date) next_date
from order_info;
--------------------------------------------------------------------------------
first_value和last_value
功能:获取窗口内某一列的第一个值/最后一个值
语法:
select
order_id,
user_id,
order_date,
amount,
first_value(order_date,false) over (partition by user_id order by order_date) first_date,
last_value(order_date,false) over (partition by user_id order by order_date) last_date
from order_info; order_id user_id
--------------------------------------------------------------------------------
rank、dense_rank、row_number
功能:计算排名
语法:
select
stu_id,
course,
score,
rank() over(partition by course order by score desc) rk,
dense_rank() over(partition by course order by score desc) dense_rk,
row_number() over(partition by course order by score desc) rn
from score_info;
备注:row_number()不重复排序,rank()重复且跳数字排序,dense_rank()重复且不跳数字排序。分区
增加分区
alter table dept_partition add partition(day='20220403');
删除分区
alter table dept_partition
drop partition (day='20220403');
删除多个分区:
alter table dept_partition
drop partition (day='20220404'), partition(day='20220405');
修复分区
Hive 将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路
径一致时,分区表才能正常读写数据。若用户手动创建/删除分区路径,Hive 都是感知不到的,
这样就会导致 Hive 的元数据和 HDFS 的分区路径不一致。再比如,若分区表为外部表,
用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,
同样会导致Hive的元数据和HDFS的分区路径不一致。
若出现元数据和HDFS路径不一致的情况,可通过如下几种手段进行修复。
(1)add partition
若手动创建 HDFS 的分区路径,Hive 无法识别,可通过 add partition 命令增加分区元数 据信息,从而使元数据和分区路径保持一致。
(2)drop partition
若手动删除HDFS的分区路径,Hive无法识别,可通过drop partition命令删除分区元 数据信息,从而使元数据和分区路径保持一致。
(3)msck
若分区元数据和 HDFS 的分区路径不一致,还可使用 msck 命令进行修复,以下是该命 令的用法说明。
说明:
msck repair table table_name add partitions:该命令会增加HDFS路径存在但元数据缺 失的分区信息。
msck repair table table_name drop partitions:该命令会删除 HDFS 路径已经删除但元数 据仍然存在的分区信息。
msck repair table table_name sync partitions:该命令会同步HDFS路径和元数据分区信 息,相当于同时执行上述的两个命令。
msck repair table table_name:等价于 msck repair table table_name add partitions 命令hive文件格式
Hive 表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive 表数据的存储格式,可以选择 text file、orc、parquet、sequence file 等。
Text File
文本文件是 Hive 默认使用的文件格式,文本文件中的一行内容,就对应 Hive 表中的一行记录。
ORC
ORC(Optimized Row Columnar)file format 是 Hive 0.11 版里引入的一种列式存储的文件格式。ORC 文件能够提高 Hive 读写数据和处理数据的性能。 与列式存储相对的是行式存储,下图是两者的对比:

(1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
(2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
前文提到的text file和sequence file都是基于行存储的,orc和parquet是基于列式存储的。orc 文件的具体结构如下图所示:

每个 Orc 文件由 Header、Body 和 Tail 三部分组成。其中 Header 内容为 ORC,用于表示文件类型。
Body 由 1 个或多个 stripe 组成,每个 stripe 一般为 HDFS 的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储,每个 stripe 里有三部分组成,分别是 Index Data, Row Data,Stripe Footer。
Index Data:一个轻量级的 index,默认是为各列每隔 1W 行做一个索引。每个索引会 记录第 n 万行的位置,和最近一万行的最大值和最小值等信息。
Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream 来存储。
Stripe Footer:存放的是各个 Stream 的位置以及各 column 的编码信息。
Tail 由 File Footer 和 PostScript 组成。File Footer 中保存了各 Stripe 的其实位置、索引长
度、数据长度等信息,各 Column 的统计信息等;PostScript 记录了整个文件的压缩类型以 及 File Footer 的长度信息等。
在读取 ORC 文件时,会先从最后一个字节读取 PostScript 长度,进而读取到 PostScript, 从里面解析到File Footer长度,进而读取FileFooter,从中解析到各个Stripe信息,再读各 个 Stripe,即从后往前读。
Parquet
Parquet 文件是 Hadoop 生态中的一个通用的文件格式,它也是一个列式存储的文件格 式。Parquet 文件的格式如下图所示:
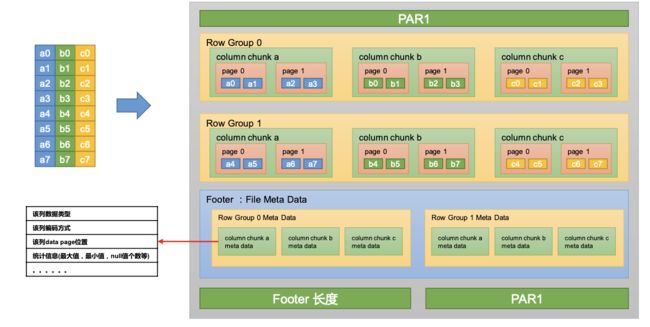
上图展示了一个 Parquet 文件的基本结构,文件的首尾都是该文件的 Magic Code,用 于校验它是否是一个 Parquet 文件。
首尾中间由若干个 Row Group 和一个 Footer(File Meta Data)组成。
每个Row Group包含多个Column Chunk,每个Column Chunk包含多个Page。以下是 Row Group、Column Chunk 和 Page 三个概念的说明:
行组(Row Group):一个行组对应逻辑表中的若干行。
列块(Column Chunk):一个行组中的一列保存在一个列块中。 页(Page):一个列块的数据会划分为若干个页。
Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(ColumnChunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的 Data Page 位置等信息。