【MegDet】《MegDet:A Large Mini-Batch Object Detector》

CVPR-2018
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
-
- 4.1 Learning Rate for Large Mini-Batch
- 4.2 Cross-GPU Batch Normalization
- 5 Experiments
-
- 5.1 Large mini-batch size, no BN
- 5.2 Large mini-batch size, with CGBN
- 6 Conclusion
1 Background and Motivation
近些年目标检测效果的提升集中在 novel network, new framework, or loss design,少有关注 batch-size 层面,分类任务 batch-size 很大,检测任务很小
实录 | 旷视研究院解读COCO2017物体检测夺冠论文(PPT+视频)

小 batch-size 的缺点
实录 | 旷视研究院解读COCO2017物体检测夺冠论文(PPT+视频)

the small mini-batch size is not applicable to re-train the BN layers.( ImageNet 预训练,COCO fine-tune,fine-tune 的时候 BN 冻结了——usually fix the statistics of Batch Normalization and use the pre-computed values on ImageNet dataset)
为啥缺点中说正负样本失衡


比如 batch-size 较大的时候,图 (c)和图(d)在一个 batch 正负样本会比仅图(c)要更均衡一些
检测任务能不能也加大 batch-size,提速的同时保证精度不掉或者更好呢?
CVPR 2018 | 旷视科技物体检测冠军论文——大型Mini-Batch检测器MegDet

2 Related Work
- CNN-based detectors
- one stage
- two stage
- Large mini-batch training
3 Advantages / Contributions
- new interpretation of linear scaling rule(等梯度方差而非等梯度)
- 提出 MegDet,其中 Cross-GPU Batch Normalization(CGBN) 技术大幅度提升目标检测任务的 batch-size,又快又好(33 hours to 4 hours)
- COCO 2017 Challenge,1st place of Detection task.
4 Method
4.1 Learning Rate for Large Mini-Batch
(1) Variance Equivalence
Linear Scaling Rule,batch-size scale,learning rate 也相应的 scale,是基于 gradient equivalence assumption in the SGD updates
目标检测任务的 batch-size 比较小,分类任务的 batch-size 比较大,假设各 batch 间 gradient equivalence 在 batch 比较小的时候似乎有点不妥

作者假设各 batch 的 gradient variance 是 equivalence,重新进行了推导,得到了同 Linear Scaling Rule 一样的结论

MegDet 论文笔记
作者在等方差条件下推导了equivalent learning rate rule(batch s i z e ∗ k size*k size∗k 则 l r ∗ k lr*k lr∗k),而不是等梯度条件
(2)Warmup Strategy
实录 | 旷视研究院解读COCO2017物体检测夺冠论文(PPT+视频)

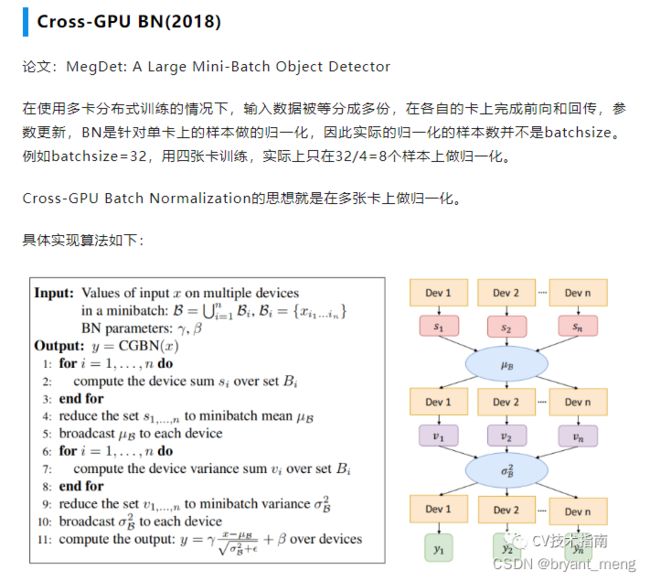
4.2 Cross-GPU Batch Normalization
当时 batch normalization 都是在单张卡上做的,作者实现了多卡算子
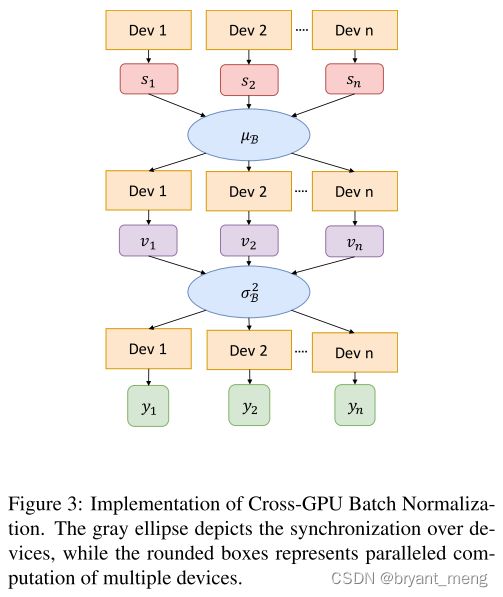

“AllReduce” operation to aggregate the statistics.
use NVIDIA Collective Communication Library (NCCL) to efficiently perform AllReduce operation for receiving and broadcasting.
s 1 s_1 s1 / s 2 s_2 s2 / … / s n s_n sn reduce μ B \mu_B μB
v 1 v_1 v1 / v 2 v_2 v2 / … / v n v_n vn reduce σ B 2 \sigma_B^2 σB2
5 Experiments
数据集 COCO
As for large mini-batch, we use the sublinear memory and distributed training to remedy the GPU memory constraints.
关于 sublinear memory,来自 《Training Deep Nets with Sublinear Memory Cost》(arXiv-2016)陈天奇
如何减少神经网络的内存?

对大规模 model training 感兴趣,请问有相关推荐的文章吗? - Connolly的回答 - 知乎

实录 | 旷视研究院解读COCO2017物体检测夺冠论文(PPT+视频)

计算换内存,占用空间较大的中间变量重复计算,来减少内存的策略
5.1 Large mini-batch size, no BN

没 BN 容易飞
5.2 Large mini-batch size, with CGBN
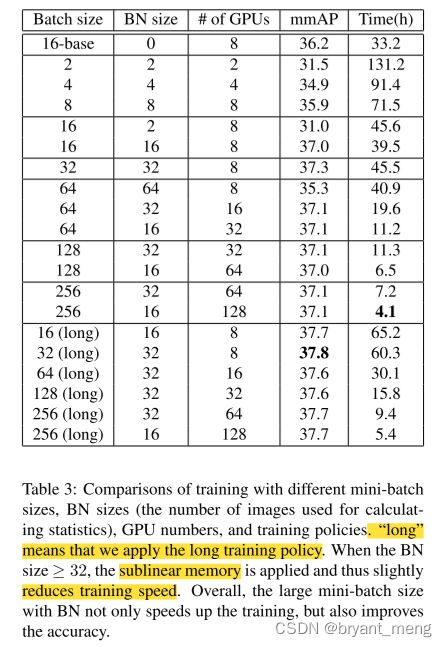
long 指的是更长的 train policy
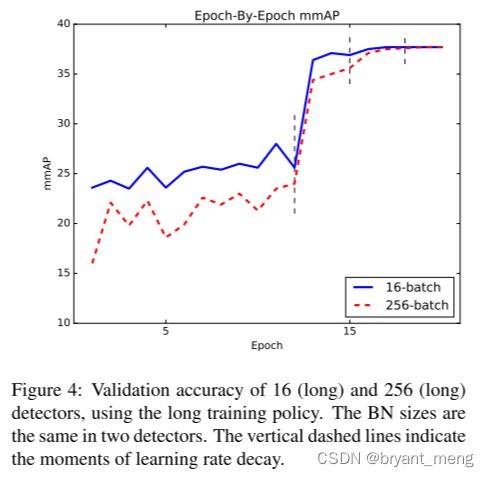
用了大 batch 以后,前期效果不如小 batch,这点和分类任务有出入

感受下检测结果

其他的涨点策略

《论文研读系列》 A Large Mini-Batch Object Detector

CVPR 2018 举办地,Hawaii
6 Conclusion
摘抄一些论文解读的文章
CVPR 2018 | 旷视科技物体检测冠军论文——大型Mini-Batch检测器MegDet

学习率线性尺度原则(LSR)另外一种解释
12分钟训练COCO模型!速度精度双提高

Batch Normalization和它的“后浪”们