【高可用Hadoop HA配置】
高可用Hadoop HA配置
- 实验名称:Hadoop HA模式环境
-
- 实验对象
- 实验目的
- 实验内容
- 实验步骤
实验名称:Hadoop HA模式环境
实验对象
数据科学与大数据技术专业
实验目的
熟悉Hadoop的HA环境搭建,理解高可用模式
实验内容
完成Hadoop的HA环境搭建
实验步骤
一、集群规划
| 序号 | IP | 主机别名 | 角色 | 集群 |
|---|---|---|---|---|
| 1 | 192.168.137.110 | node1 | NameNode(Active),DFSZKFailoverController(ZKFC),ResourceManager | Hadoop |
| 2 | 192.168.137.111 | node2 | DataNode,JournalNode,QuorumPeerMain,NodeManager | Zookeeper,Hadoop |
| 3 | 192.168.137.112 | node3 | DataNode,JournalNode,QuorumPeerMain,NodeManager | Zookeeper,Hadoop |
| 4 | 192.168.137.113 | node4 | DataNode,JournalNode,QuorumPeerMain,NodeManager | Zookeeper,Hadoop |
| 5 | 192.168.137.114 | node5 | NameNode(Standby),DFSZKFailoverController(ZKFC),ResourceManager,JobHistoryServer | Hadoop |
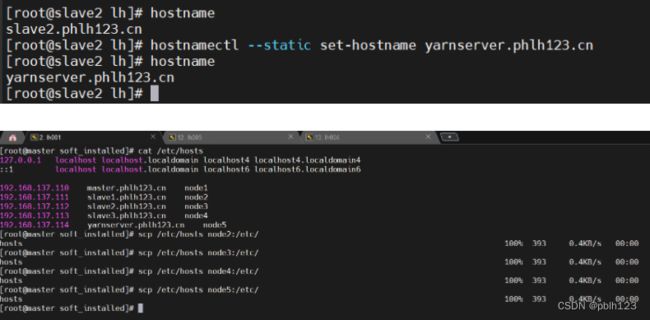
# 主机映射信息
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.137.110 master.phlh123.cn node1
192.168.137.111 slave1.phlh123.cn node2
192.168.137.112 slave2.phlh123.cn node3
192.168.137.113 slave3.phlh123.cn node4
192.168.137.114 yarnserver.phlh123.cn node5
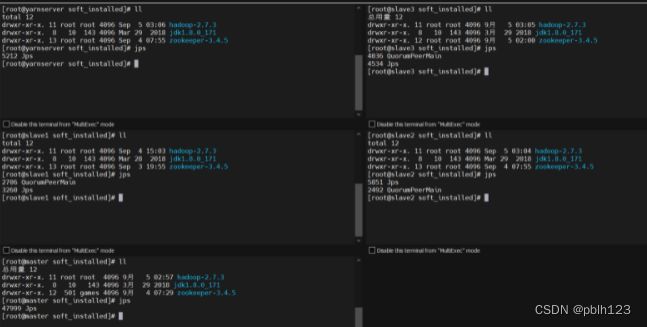
# 软件版本
[root@master soft_installed]# ll
总用量 12
drwxr-xr-x. 12 root root 4096 8月 30 07:03 hadoop-2.7.3
drwxr-xr-x. 8 10 143 4096 3月 29 2018 jdk1.8.0_171
drwxr-xr-x. 12 501 games 4096 9月 4 07:29 zookeeper-3.4.5
二、准备工作
- 安装JDK
- 配置环境变量
- 配置免密码登录
- 配置主机名
三、配置Zookeeper(node1节点上)
配置过程:
在主节点node1上配置Zookeeper
- 解压Zookeeper安装包及前期准备
- 配置zoo.cfg文件
- 创建myid文件
- 将配置好的Zookeeper发送到其他节点
解压Zookeeper安装包及前期准备
# 切换root账号
su
# 解压zookeeper
tar -zxvf zookeeper-3.4.5.tar.gz -C /opt/soft_installed/
# 创建zookeeper的相关目录
mkdir /opt/soft_installed/zookeeper-3.4.5/{zkdata,logs}
# 配置环境变量
vi /etc/profile
# 配置JAVA环境变量
export JAVA_HOME=/opt/soft_installed/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# 配置Hadoop环境变量
export HADOOP_HOME=/opt/soft_installed/hadoop-2.7.3
export HADOOP_LOG_DIR=/opt/soft_installed/hadoop-2.7.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME
# 配置Zookeeper
export ZOOKEEPER_HOME=/opt/soft_installed/zookeeper-3.4.5
export PATH=.:$PATH:$ZOOKEEPER_HOME/bin
# 更改主机名 node4
hostnamectl set-hostname slave3.phlh123.cn
# 更改主机名 node5
hostnamectl --static set-hostname yarnserver.phlh123.cn
# 分发hosts文件到各个节点(node1)
scp /etc/hosts node2:/etc/
scp /etc/hosts node3:/etc/
scp /etc/hosts node4:/etc/
scp /etc/hosts node5:/etc/
配置zoo.cfg文件
cp /opt/soft_installed/zookeeper-3.4.5/conf/zoo_sample.cfg /opt/soft_installed/zookeeper-3.4.5/conf/zoo.cfg
# 配置zoo.cfg
vi /opt/soft_installed/zookeeper-3.4.5/conf/zoo.cfg
cat /opt/soft_installed/zookeeper-3.4.5/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/soft_installed/zookeeper-3.4.5/zkdata
dataLogDir=/opt/soft_installed/zookeeper-3.4.5/logs
clientPort=2181
# cluster
server.1=node2:2888:3888
server.2=node3:2888:3888
server.3=node4:2888:3888
创建myid文件
[root@master ~]# echo 1 > /opt/soft_installed/zookeeper-3.4.5/tmp/myid
[root@master ~]# cat /opt/soft_installed/zookeeper-3.4.5/tmp/myid
1

将配置好的Zookeeper发送到其他节点
# 将环境变量发送到其他节点
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
scp /etc/profile node4:/etc/
scp /etc/profile node5:/etc/
# 将配置好的zookeeper发送到其他节点
scp -r zookeeper-3.4.5/ node2:/opt/soft_installed/
scp -r zookeeper-3.4.5/ node3:/opt/soft_installed/
scp -r zookeeper-3.4.5/ node4:/opt/soft_installed/
scp -r zookeeper-3.4.5/ node5:/opt/soft_installed/
# 配置zookeeper的myid配置文件
# cluster中的server.{num}=node2:2888:3888 需要与myid中的数字一致
vi /opt/soft_installed/zookeeper-3.4.5/zkdata/myid
四、配置Hadoop集群
- 修改配置hadoop-env.sh中JDK路径
- 修改core-site.xml
- 修改hdfs-site.xml(配置有几个namenode)
- 修改mapred-site.xml
- 修改yarn-site.xml
- 修改slaves
- 将配置好的hadoop拷贝到其他节点
修改配置hadoop-env.sh中JDK路径
[root@slave3 ~]# cat /opt/soft_installed/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
# The java implementation to use.需要写出绝对路径
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/opt/soft_installed/jdk1.8.0_171
修改core-site.xml
vi /opt/soft_installed/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<!--fs.default.name,fs.defaultFS二选一 -->
<!--
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
<description>指定HDFS的,非HA下选择</description>
</property>
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://lh1</value>
<description>HDFS的URL,HA下配置</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft_installed/hadoop-2.7.3/hadoopdatas/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
<description>指定HDFS HA配置</description>
</property>
</configuration>
修改hdfs-site.xml(配置有几个namenode)
vi /opt/soft_installed/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>datenode数,默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>如果是true则检查权限,否则不检查(每一个人都可以存取文件)</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/soft_installed/hadoop-2.7.3/hadoopdatas/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/soft_installed/hadoop-2.7.3/hadoopdatas/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!--以下是HDFS HA的配置-->
<!--指定HDFS的nameservices名称为lh1,需要和core-site.xml中保持一致-->
<property>
<name>dfs.nameservices</name>
<value>lh1</value>
<description>hdfs的nameservice为lh1,需要和core-site.xml保持一直</description>
</property>
<property>
<name>dfs.ha.namenodes.lh1</name>
<value>nn1,nn2</value>
<description>lh1集群中两个namenode的名字</description>
</property>
<property>
<name>dfs.namenode.rpc-address.lh1.nn1</name>
<value>node1:9000</value>
<description>nn1的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.lh1.nn1</name>
<value>node1:50070</value>
<description>nn1的http通信地址</description>
</property>
<property>
<name>dfs.namenode.rpc-address.lh1.nn2</name>
<value>node5:9000</value>
<description>nn2的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.lh1.nn2</name>
<value>node5:50070</value>
<description>nn2的http通信地址</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node2:8485;node3:8485;node4:8485/lh1</value>
<description>N指定NameNode的元数据在JournalNode上的存放位置</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft_installed/hadoop-2.7.3/hadoopdatas/journal</value>
<description>JournalNode上元数据和日志文件存放位置</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.lh1</name>
<value>true</value>
<description>开启Namenode失败自动切换</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.lh1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>配置失败时切换实现方式</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
<description>隔离机制,多个机制换行分割,每个机制一行</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_ras</value>
<description>sshfence隔离机制需要ssh免密登录</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
<description>sshfence隔离机制超时时间</description>
</property>
</configuration>
修改mapred-site.xml
vim /opt/soft_installed/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
<!-- 配置MapReduce JobHistory Server地址,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 配置MapReduce JobHistory Server HTTP地址,默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
启动historyserver:mr-jobhistory-daemon.sh start historyserver
停止historyserver:mr-jobhistory-daemon.sh sop historyserver
jobhistoryserver的webUI地址:主机名:19888
当我们启动jobhistoryserver服务之后,在HDFS上/tmp/hadoop-yarn/staging/history路径下会生成两个文件夹:done和done_intermediate。done文件夹下存放已经完成的job,done_intermediate文件夹下存放正在进行的job信息。
修改yarn-site.xml
vim /opt/soft_installed/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 日志服务配置 -->
<property>
<name>yarn.log.server.url</name>
<value>http://0.0.0.0:19888/jobhistory/logs</value>
</property>
<!--开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>lq</value>
</property>
<!--指定RM名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--指定RM名字 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node5</value>
</property>
<!--RM故障自动切换-->
<property>
<name>yarn.resourcemaneger.ha.automatic-failover.recover.enabled</name>
<value>true</value>
</property>
<!--RM故障自动恢复-->
<property>
<name>yarn.resourcemaneger.recovery.enabled</name>
<value>true</value>
</property>
<!--向RM调度资源地址-->
<property>
<name>yarn.resourcemaneger.scheduler.address.rm1</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemaneger.scheduler.address.rm2</name>
<value>node5:8030</value>
</property>
<!--NodeManeger通过该地址交换信息-->
<property>
<name>yarn.resourcemaneger.resource-tracker.address.rm1</name>
<value>node1:8031</value>
</property>
<property>
<name>yarn.resourcemaneger.resource-tracker.address.rm2</name>
<value>node5:8031</value>
</property>
<!--客户端通过该地址向RM提交对应用程序的操作-->
<property>
<name>yarn.resourcemaneger.address.rm1</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemaneger.address.rm2</name>
<value>node5:8032</value>
</property>
<!--管理员通过该地址向RM发送管理命令-->
<property>
<name>yarn.resourcemaneger.admin.address.rm1</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemaneger.admin.address.rm2</name>
<value>node5:8033</value>
</property>
<!--RM HTTP访问地址,查看集群信息-->
<property>
<name>yarn.resourcemaneger.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<name>yarn.resourcemaneger.webapp.address.rm2</name>
<value>node5:8088</value>
</property>
<!--指定zk集群地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves
vim /opt/soft_installed/hadoop-2.7.3/etc/hadoop/slaves
node2
node3
node4
配置环境变量
vim /etc/profile
# 配置JAVA环境变量
export JAVA_HOME=/opt/soft_installed/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# 配置Hadoop环境变量
export HADOOP_HOME=/opt/soft_installed/hadoop-2.7.3
export HADOOP_LOG_DIR=/opt/soft_installed/hadoop-2.7.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export PATH=.:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME
# 配置Zookeeper
export ZOOKEEPER_HOME=/opt/soft_installed/zookeeper-3.4.5
export PATH=.:$PATH:$ZOOKEEPER_HOME/bin
# 生效
source /etc/profile
将配置好的hadoop及环境变量拷贝到其他节点
# 环境变量
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
scp /etc/profile node4:/etc/
scp /etc/profile node5:/etc/
# hadoop
scp -r /opt/soft_installed/hadoop-2.7.3/ node2:/opt/soft_installed/
scp -r /opt/soft_installed/hadoop-2.7.3/ node3:/opt/soft_installed/
scp -r /opt/soft_installed/hadoop-2.7.3/ node4:/opt/soft_installed/
scp -r /opt/soft_installed/hadoop-2.7.3/ node5:/opt/soft_installed/
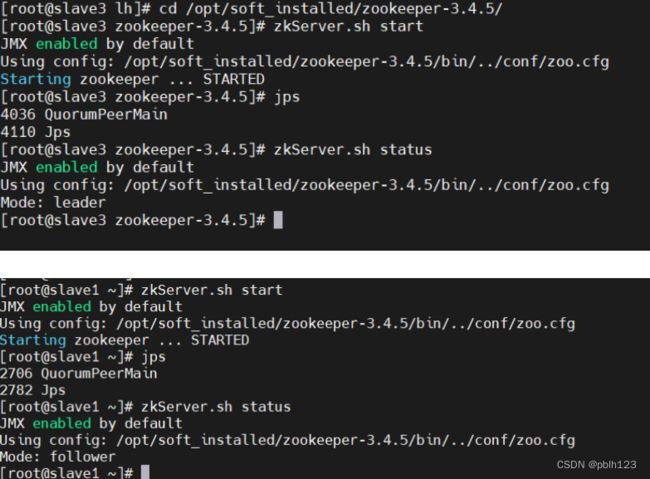
五、启动Zookeeper集群
启动zookeeper(slave1,slave2,slave3)
# 启动
zkServer.sh start
# 验证是否启动成功,//三台虚拟机中有一台leader和两台follower
# 谁先启动,谁leader
zkServer.sh status

格式化ZKFC(在node1上执行)
hdfs zkfc -formatZK

启动journalnode(分别在node2,node3,node4上执行)
hadoop-daemon.sh start journalnode

六、格式化HDFS(node1上执行)
# 1.格式化目录
hdfs namenode -format
# 2.将格式化之后的node1节点hadoop工作目录中的元数据目录复制到node5节点
scp -r /opt/soft_installed/hadoop-2.7.3/hadoopdatas/ node5:/opt/soft_installed/hadoop-2.7.3/
# 3. 初始化完毕之后可以关闭journalnode(分别在node2,node3,node4上执行)(之后在ActiveNN上启动dfs会随之启动全部的journalnode)
hadoop-daemon.sh stop journalnode


八、启动集群
# node1上启动
start-all.sh
# node1,node5上分别启动zkfc
hadoop-daemon.sh start zkfc
# node5上启动resourcemanager
yarn-daemon.sh start resourcemanager
# node5上启动historyserver
mr-jobhistory-daemon.sh start historyserver

九、测试样例
hadoop jar /opt/soft_installed/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
# wordcount
hdfs dfs -mkdir -p /wordcount/input
hdfs dfs -put test.txt /wordcount/input/
hadoop jar /opt/soft_installed/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wordcount/input/ /wordcount/output
十、关闭集群
# node1关闭机器
stop-all.sh
# or
stop-dfs.sh
stop-yarn.sh
# node5 ResourceManager、historyserver关闭
yarn-daemon.sh stop resourcemanager
mr-jobhistory-daemon.sh stop historyserver
# node1,node5关闭zkfc
hadoop-daemon.sh stop zkfc
# (分别在node2,node3,node4上执行)节点关闭Zookeeper
zkServer.sh stop
十一、再次启动
# node1上启动
start-all.sh
# or
start-dfs.sh
start-yarn.sh
#(分别在node2,node3,node4上执行)节点启动Zookeeper
zkServer.sh start
# node1,node5上分别启动zkfc
hadoop-daemon.sh start zkfc
# node1,node5上启动resourcemanager
yarn-daemon.sh start resourcemanager
# node5上启动historyserver
mr-jobhistory-daemon.sh start historyserver
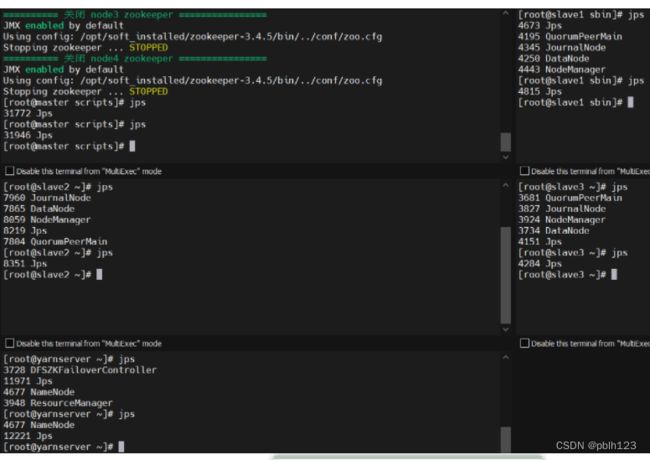
启动后每个节点jps查询
[root@master ~]# jps
63283 NameNode
65027 Jps
64490 DFSZKFailoverController
64718 ResourceManager
[root@yarnserver input]# jps
54355 Jps
54260 JobHistoryServer
53061 DFSZKFailoverController
53579 ResourceManager
52847 NameNode
[root@slave1 soft_installed]# jps
5507 QuorumPeerMain
5653 Jps
5335 NodeManager
5242 JournalNode
5151 DataNode
[root@slave2 ~]# jps
7748 NodeManager
8356 QuorumPeerMain
7654 JournalNode
9049 Jps
7563 DataNode
[root@slave3 soft_installed]# jps
7488 QuorumPeerMain
7126 DataNode
7591 Jps
7306 NodeManager
7215 JournalNode
测试NameNode高可用
[root@yarnserver ~]# jps
3728 DFSZKFailoverController
4057 Jps
3948 ResourceManager
3805 NameNode
[root@yarnserver ~]# kill -9 3805
[root@yarnserver ~]# jps
3728 DFSZKFailoverController
4148 Jps
3948 ResourceManager
[root@yarnserver ~]# hadoop
hadoop hadoop.cmd hadoop-daemon.sh hadoop-daemons.sh
[root@yarnserver ~]# hadoop
hadoop hadoop.cmd hadoop-daemon.sh hadoop-daemons.sh
[root@yarnserver ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/soft_installed/hadoop-2.7.3/logs/hadoop-lh-namenode-yarnserver.phlh123.cn.out
[root@yarnserver ~]# jps
3728 DFSZKFailoverController
4677 NameNode
11672 Jps
3948 ResourceManager
[root@yarnserver ~]#
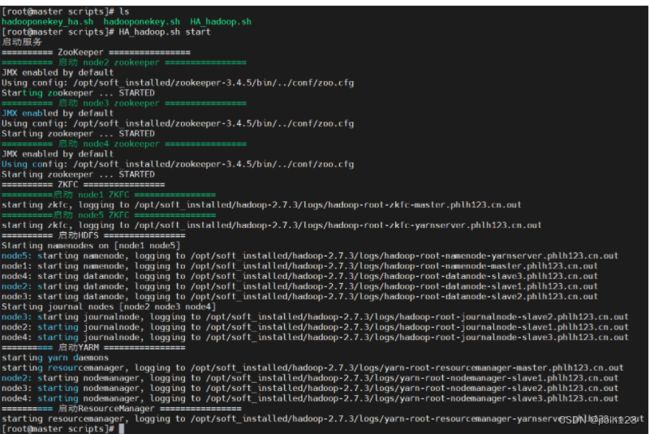
十二、优化HA Hadoop一键启动关闭
[root@master scripts]# cat HA_hadoop.sh
#!/bin/bash
# HA Hadoop 一键启动和一键关闭
if [ $# -ne 1 ];then
echo "无效参数,用法为: $0 {start|stop|restart}"
exit
fi
#获取用户输入的命令
cmd=$1
#定义函数功能
function hadoopManger(){
case $cmd in
start)
echo "启动服务"
remoteExecutionstart
;;
stop)
echo "停止服务"
remoteExecutionstop
;;
restart)
echo "重启服务"
remoteExecutionstop
remoteExecutionstart
;;
*)
echo "无效参数,用法为: $0 {start|stop|restart}"
;;
esac
}
#启动HADOOP
function remoteExecutionstart(){
#zookeeper
echo ========== ZooKeeper ================
for (( i=2 ; i<=4 ; i++ )) ;
do
tput setaf 2
echo ========== 启动 node${i} zookeeper $1 ================
tput setaf 9
ssh node${i} "source /etc/profile ; /opt/soft_installed/zookeeper-3.4.5/bin/zkServer.sh start"
done
#ZKFC
echo ========== ZKFC ================
for node in node1 node5 ;
do
tput setaf 2
echo ==========启动 ${node} ZKFC $1 ================
tput setaf 9
ssh ${node} "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/hadoop-daemon.sh start zkfc"
done
echo ========== 启动HDFS ================
ssh node1 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/start-dfs.sh"
echo ========== 启动YARM ================
ssh node1 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/start-yarn.sh"
echo ========== 启动MR HistoryService ================
ssh node5 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/mr-jobhistory-daemon.sh start historyserver"
echo ========== 启动ResourceManager ================
ssh node5 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/yarn-daemon.sh start resourcemanager"
}
#关闭HADOOP
function remoteExecutionstop(){
echo ========== 关闭ResourceManager ================
ssh node5 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/yarn-daemon.sh stop resourcemanager"
echo ========== 关闭MR HistoryService ================
ssh node5 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/mr-jobhistory-daemon.sh stop historyserver"
echo ========== 关闭YARM ================
ssh node1 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/stop-yarn.sh"
echo ========== 关闭HDFS ================
ssh node1 "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/stop-dfs.sh"
#ZKFC
echo ========== ZKFC ================
for node in node1 node5 ;
do
tput setaf 2
echo ========== 关闭 ${node} ZKFC $1 ================
tput setaf 9
ssh ${node} "source /etc/profile ; /opt/soft_installed/hadoop-2.7.3/sbin/hadoop-daemon.sh stop zkfc"
done
#zookeeper
echo ========== ZooKeeper ================
for (( i=2 ; i<=4 ; i++ )) ;
do
tput setaf 2
echo ========== 关闭 node${i} zookeeper $1 ================
tput setaf 9
ssh node${i} "source /etc/profile ; /opt/soft_installed/zookeeper-3.4.5/bin/zkServer.sh stop"
done
}
#调用函数
hadoopManger