通过双十一大考!基于 Golang 的 SOFAMosn 深度剖析
2019年,Service Mesh架构在蚂蚁金服大规模落地,基于 Golang 的数据平面SOFAMosn 在落地过程中经历了双十一等众多挑战,如 Go 各版本的测试选择和参数调整、国密能力的支持、平滑无损升级能力、Runtime bug 的排查修复过程、内存复用、日志异步化等一系列优化。在 Gopher Meetup 北京站上,蚂蚁金服技术专家田阳(烈元)进行了主题为《深度剖析 SOFAMosn -云原生时代的安全网络代理》的演讲。将以上内容从实践出发,一一道来。

以下为演讲内容整理。
00
揭秘 Service Mesh 双十一大考
蚂蚁金服很早开始关注 Service Mesh,并在 2018 年发起 ServiceMesher 社区,目前已有 4000+ 开发者在社区活跃。在技术应用层面,Service Mesh 的场景已经渡过探索期,今年已经全面进入深水区探索。
Service Mesh 基础概念
Istio 清晰的描述了 Service Mesh 最核心的两个概念:数据面与控制面。数据面负责做网络代理,在服务请求的链路上做一层拦截与转发,可以在链路中做服务路由、链路加密、服务鉴权等,控制面负责做服务发现、服务路由管理、请求度量(放在控制面颇受争议)等。
Service Mesh 带来的好处不再赘述,我们来看下蚂蚁金服的数据面和控制面产品:
数据面:SOFAMosn。蚂蚁金服使用 Golang 研发的高性能网络代理,作为 Service Mesh 的数据面,承载了蚂蚁金服双十一海量的核心应用流量。
控制面:SOFAMesh。Istio 改造版,落地过程中精简为 Pilot 和 Citadel,Mixer 直接集成在数据面中避免多一跳的开销。
双十一落地情况概览
今年,蚂蚁金服的核心应用全面接入 SOFAMosn,生产 Mesh 化容器几十万台,双十一峰值 SOFAMosn 承载数据规模数千万 QPS,SOFAMosn 转发平均处理耗时 0.2ms。

在如此大规模的接入场景下,我们面对的是极端复杂的场景,同时需要多方全力合作,更要保障数据面的性能稳定性满足大促诉求,整个过程极具挑战。
SOFAMosn 总览
先总览介绍一下Mosn产品,Mosn是一个多协议、多模块的安全网关、网络代理。它是开源的,采用 Golang 编写。为什么会选择 Go 语言呢?因为 Mosn 是一个比较跨团队的项目,包括系统、中间件、安全等很多团队,每个团队的技术栈都不一样。比如说系统部的技术栈就是 Go 语言,中间件就是 JAVA,安全团队可能有 C++,因此在大团队协作下面就需要有一个编写快捷、使用起来比较方便、在落地成本上也能满足我们的需求的语言,而Go 语言的性能和人力开发成本确实满足我们的需求。
SOFAMosn 项目地址:
https://github.com/sofastack/sofa-mosn
基础能力建设
01
SOFAMosn 的能力大图
SOFAMosn 主要划分为如下模块,包括了网络代理具备的基础能力,也包含了 XDS 等云原生能力。

02
业务支持
SOFAMosn 作为底层的高性能安全网络代理,支撑了 RPC,MSG,GATEWAY 等业务场景。

03
IO 模型
SOFAMosn 支持两种 IO 模型,一个是 Golang 经典模型,goroutine-per-connection;一个是 RawEpoll 模型,也就是 Reactor 模式,I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O)的模式。
在蚂蚁金服内部的落地场景,连接数不是瓶颈,都在几千或者上万的量级,我们选择了 Golang 经典模型。而对于接入层和网关有大量长链接的场景,更加适合于 RawEpoll 模型。


04
协程模型

一条 TCP 连接对应一个 Read 协程,执行收包,协议解析;
一个请求对应一个 worker 协程,执行业务处理,proxy 和 Write 逻辑;
常规模型一个 TCP 连接将有 Read/Write 两个协程,我们取消了单独的 Write 协程,让 workerpool 工作协程代替,减少了调度延迟和内存占用。
05
能力扩展
协议扩展
SOFAMosn 通过使用同一的编解码引擎以及编/解码器核心接口,提供协议的 plugin 机制,包括支持:
SOFARPC;
HTTP1.x/HTTP2.0;
Dubbo;
NetworkFilter 扩展
SOFAMosn 通过提供 network filter 注册机制以及统一的 packet read/write filter 接口,实现了 Network filter 扩展机制,当前支持:
TCP proxy;
Fault injection;
StreamFilter 扩展
SOFAMosn 通过提供 stream filter 注册机制以及统一的 stream send/receive filter 接口,实现了 Stream filter 扩展机制,包括支持:
流量镜像;
RBAC鉴权;
06
TLS 安全链路
作为金融科技公司,资金安全是最重要的一环,链路加密又是其中最基础的能力,在 TLS 安全链路上我们进行了大量的调研测试。
通过测试,原生的 Go 的 TLS 经过了大量的汇编优化,在性能上是 Nginx(OpenSSL)的80%,Boring 版本的 Go(使用 cgo 调用 BoringSSL) 因为 cgo 的性能问题, 并不占优势,所以我们最后选型原生 Go 的 TLS,相信 Go Runtime 团队后续会有更多的优化,我们也会有一些优化计划。

go 在 RSA 上没有太多优化,go-boring(CGO)的能力是 go 的1倍;
p256 在 go 上有汇编优化,ECDSA 优于go-boring;
在 AES-GCM 对称加密上,go 的能力是 go-boring 的20倍;
在 SHA、MD 等 HASH 算法也有对应的汇编优化;
为了满足金融场景的安全合规,我们同时也对国产密码进行了开发支持,这个是 Go Runtime 所没有的。虽然目前的性能相比国际标准 AES-GCM 还是有一些差距,大概是 50%,但是我们已经有了后续的一些优化计划,敬请期待。

07
平滑升级能力
为了让 SOFAMosn 的发布对应用无感知,我们调研开发了平滑升级方案,类似 Nginx 的二进制热升级能力,但是有个最大的区别就是 SOFAMosn 老进程的连接不会断,而是迁移给新的进程,包括底层的 socket FD 和上层的应用数据,保证整个二进制发布过程中业务不受损,对业务无感知。除了支持 SOFARPC、Dubbo、消息等协议,我们还支持 TLS 加密链路的迁移。
容器升级
基于容器平滑升级 SOFAMosn 给了我们很多挑战,我们会先注入一个新的 SOFAMosn,然后他会通过共享卷的 UnixSocket 去检查是否存在老的 SOFAMosn,如果存在就和老的 SOFAMosn 进行连接迁移,然后老的 SOFAMosn 退出。这一块的细节较多,涉及 SOFAMosn 自身和 Operator 的交互。

SOFAMosn 的连接迁移
连接迁移的核心主要是内核 Socket 的迁移和应用数据的迁移,连接不断,对用户无感知。

SOFAMosn 的 metric 迁移
我们使用了共享内存来共享新老进程的 metric 数据,保证在迁移的过程中 metric 数据也是正确的。

08
内存复用机制
基于 sync.Pool;
slice 复用使用 slab 细粒度,提高复用率;
常用结构体复用;

线上复用率可以达到90%以上,当然 sync.Pool 并不是银弹,也有自己的一些问题,但是随着 Runtime 对 sync.Pool 的持续优化,比如 go1.13 就使用 lock-free 结构减少锁竞争和增加了 victim cache 机制,以后会越来越完善。
09
XDS(UDPA)
支持云原生统一数据面 API,全动态配置更新。

前期准备
01
性能压测和优化
在上线前的准备过程中,我们在灰度环境针对核心收银台应用进行了大量的压测和优化,为后面的落地打下了坚实的基础。
从线下环境到灰度环境,我们遇到了很多线下没有的大规模场景,比如单实例数万后端节点,数千路由规则,不仅占用内存,对路由匹配效率也有很大影响,比如海量高频的服务发布注册也对性能和稳定性有很大挑战。
整个压测优化过程历时五个月,从最初的 CPU 整体增加20%,RT 每跳增加 0.8ms, 到最后 CPU 整体增加 6%,RT 每跳增加了 0.2ms,内存占用峰值优化为之前的 1⁄10 。

部分优化措施


在 618 大促时,我们上线了部分核心链路应用,CPU 损耗最多增加 1.7%,有些应用由于逻辑从 Java 迁移到 Go,CPU 损耗还降低了,有 8% 左右。延迟方面平均每跳增加 0.17ms,两个合并部署系统全链路增加 5~6ms,有 7% 左右的损耗。
在后面单机房上线 SOFAMosn,在全链路压测下,SOFAMosn 的整体性能表现更好,比如交易付款带 SOFAMosn 比不带 SOFAMosn 的 RT 还降低了 7.5%。
SOFAMosn 做的大量核心优化和 Route Cache 等业务逻辑优化的下沉,更快带来了架构的红利。
02
Go 版本选择
版本的升级都需要做一系列测试,新版本并不是都最适合你的场景。我们项目最开始使用的 Go 1.9.2,在经过一年迭代之后,我们开始调研当时 Go 的最新版 1.12.6,我们测试验证了新版很多好的优化,也修改了内存回收的默认策略,更好的满足我们的项目需求。
GC 优化,减少长尾请求
新版的自我抢占(self-preempt)机制,将耗时较长 GC 标记过程打散,来换取更为平滑的GC表现,减少对业务的延迟影响。
https://go-review.googlesource.com/c/go/+/68574/ https://go-review.googlesource.com/c/go/+/68573/
Go 1.9.2 
Go 1.12.6 
内存回收策略
在 Go1.12,修改了内存回收策略,从默认的 MADV_DONTNEED 修改为了 MADV_FREE,虽然是一个性能优化,但是在实际使用中,通过测试并没有大的性能提升,但是却占用了更多的内存,对监控和问题判断有很大的干扰,我们通过 GODEBUG=madvdontneed=1 恢复为之前的策略,然后在 issue 里面也有相关讨论,后续版本可能也会改动这个值。
runtime: use MADV_FREE on Linux if available

使用 Go1.12 默认的 MADV_FREE 策略 ,Inuse 43M, 但是 Idle 却有 600M,一直不能释放。

03
Go Runtime Bug 修复
在前期灰度验证时,SOFAMosn 线上出现了较严重的内存泄露,一天泄露了1G 内存,最终排查是 Go Runtime 的 Writev 实现存在缺陷,导致 slice 的内存地址被底层引用,GC 不能释放。

我们给 Go 官方提交了 Bugfix,已合入 Go 1.13最新版。 internal/poll: avoid memory leak in Writev
落地实践
01
CPU 资源分配

最开始不是做1:1,而是4:1,这个设置导致一个问题:在CPU使用率 20%、30% 的时候没有问题,但当你的CPU到了 70%、80% 的时候问题就出来了,当你70%、80%的时候,STW能达到 20ms,整个世界暂停了,这个完全不能忍受。为什么能达到20ms?是因为之前CPU权重调的太低了,在这个时间段 Mosn 达不到 CPU 配额,导致整个响应就很严重。最后强制性把 APP 和 Mosn 调成1:1的 CPU 配额,可以看这个点,在调的时候响应时间从 0.5 直接降到 0.1,这个值也是通过持续压测,持续观察压测出来的,最后确定了一个1:1占比做这个事。在一般小场景下不会出现的。
02
mem 资源分配

内存开始是固定分配的,最开始 Mosn 内存固定为 512M 或者 是1个 G,恰恰这样会出现一些问题。比如说有些应用只用 200M,那你设的 300M 就浪费了;有些应用 1.5个G那就更完蛋。所以说最好的方式,包括运维我们一起做了很多测试和验证,比如说使用超卖,超卖意思是说整个 Pod 是 8G 内存,APP 可以看到 8G 内存,但是 Mosn 只能看到 2个G。这样就保证第一内存不会浪费,我用 200M 剩下的 APP 也可以看到,也可以用。如果我用多了也没有问题,用多了之后不会挂掉,因为是共享的。看这个图明显知道在峰值来的时候冲高,但是慢慢会回落。这样保证系统的稳定性,没办法避免有时候一些突发流量的突增,如果你固定一个 500M,平时只有 200M,可能一个突增就挂掉了。这又引到另外一个问题它真正 OOM 的时候怎么办?如果真的 OOM了,一般内存占的比较大,Java 动不动占 5、6个G,这种情况下我们调整了 OOM 的权重,在内存高的时候先杀 Mosn,因为 Mosn 启动很快几秒钟就起来了,但是 Java 可能5分钟也起不来,不是说 Java 不好的意思,因为它有业务逻辑,有很多的加载,流程比较长。
03
GOMAXPROCS

下一个是P的调整,之前我们没有遇到,这是一个请求延迟,这是 Mack 导致请求延迟很严重的问题,你在标记的时候就导致标记时段太长,请求会被延后处理,导致线上经常有超时的问题。有些核心应用,那种基础组件应用,连接数很多,可能有五六万个,对象数很大、很多。在这种大应用的话,每次 GC 全 GC,每次扫几百毫秒。这种场景下也没有太好的办法,我们就增加了 P 的个数。
这些都是我们压测时发现,做修改进行实时调整,效果还是挺明显的。超时量减少到之前的1%,当然不是说 P 越大就越好,P 多之后上下文切换多,STW 的时候必须要把 P 暂停,P 多了之后,导致 STW 增加,还是要经过线上权衡压测,过多过少都有一些影响。
04
gotrace 导致请求卡顿

这也是一个比较坑的问题,因为我们要看GC,喜欢把GC放在文件里面没事时看一看。说一下背景,因为蚂蚁有一批很慢的机器,它的硬盘很差。当时机房出现了很严重的卡顿现象,最后把它堆加到文件里面进行操作。
可以看一下这个代码,gotrace如果它卡住了就完蛋了,执行不到这儿来。在写卡顿的时候,你的提升日志却是正常的,为什么?因为打的时候你计数已经计过了,所以打出的日志还是很完美很短的,可能有同学会说 IO 卡多久?下一张图,可以卡 500ms 很正常的,这是一个例子,导致你的系统在 IO 很差的时候导致很大的卡顿。
05
独立协程打印日志就不影响业务?
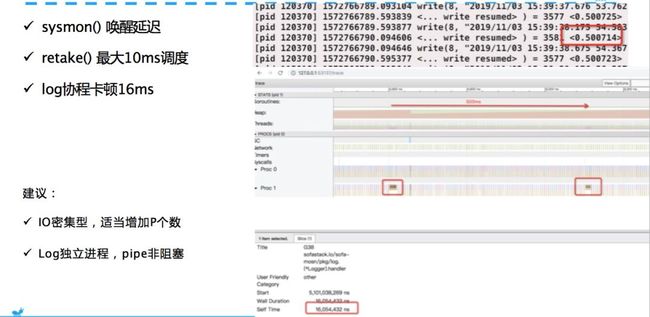
我相信大家的日志协程都是独立的,我当时也这样想,我都异步了,还能影响我吗?虽然不会影响你的主协程,但它会影响调度。
这就是一个 Write resumed,这个时间 0.5s。Write0.5s 用了 500ms 的 IO 操作,这个图也很清楚说明两次唤醒 500ms,它先被卡住,写完之后再唤醒你。关键点是这个东西,这个卡了16ms,意思是说这个写卡顿之后过了16ms才把我清走。sysmon 肯定是有一些延时的,因为它也是多久执行一次,比如说10ms执行一次,所以这个间隔就不会把你迁走。
还有 retake 它最大也有 10ms 的延迟,不会把你干掉。在各种场景综合情况下就会产生图上的现象,这个协程卡了 16ms,16ms 内就不能做操作了,这就导致了你认为一个异步协程对于写日志不会影响主流程,但真真切切对你的调度产生影响。在P上,可能刚来的就受到影响,卡了几毫秒。我们线下测起来卡顿影响很大,虽然不会影响请求主流程,但是你把 write resumed 卡住,不调度你的 work 协程也是没用的。所以 Go 的调度感觉还有很多的改进,建议 IOB 请求可以增加一些个数。跟 Nginx 这些做法都是类似的,对 IOB 请求基本都可以写 work。
IO 密集型,我们尽量写 Work,适当增加 P 个数。还有 Log 独立进程,落地协程让它变成一个进程跑。我的 Mosn 就用 Pipe 非阻塞发,当然还有第三个方案换一块好的硬盘。
总结与展望
验证要符合线上规模场景
切合实际,不要过度优化
GOMAXPROCS 的个人需要根据业务场景压测权衡
让 GO 调度支持优先级,比如让 Log 协程降低优先级
Go 的分代 GC 将会减少大对象数场景下的请求延迟
ROADMAP

Q & A
提问:我想请问一下APP和应用,拦截APP请求的时候通过什么拦截?平滑升级的时候是怎样聚焦落地请求上下文的?
田阳:迁移的话,有点太细节。我一个请求读了一半,会把一半的请求传给新的 Mosn ,新的 Mosn 初始化传八份,让它接着读就OK,相当于读8份数据。我们现在没有做拦截,因为透明劫持。我们的做法是改端口,后面是透明劫持的方案。第一步主要是落地数据,控制面今年和明年优化,控制面也有很多的挑战。
提问:内存泄露的排查过程?
田阳:基本人工,当然也可以使用工具。我刚开始把自己的代码理了无数轮,看自己的代码为什么泄露?最后没有抱一点希望,结果就是因为没有抱一点希望发现就有问题。有时候自己的态度不要完全相信官方是OK的。
重磅活动预告
Gopher Meetup 上海站即将开启。来自蚂蚁金服&携程、趣头条、讯联数据、TutorABC的大咖讲师将带来 Go 开发领域的一线实践经验分享,尽在12月14日,微软加速器!
报名请戳:阅读原文

Go中国
扫码关注
国内最具规模和生命力的 Go 开发者社区
欢迎投稿,请联系:
聪明又努力的 Gopher 们,你“在看”我吗?
