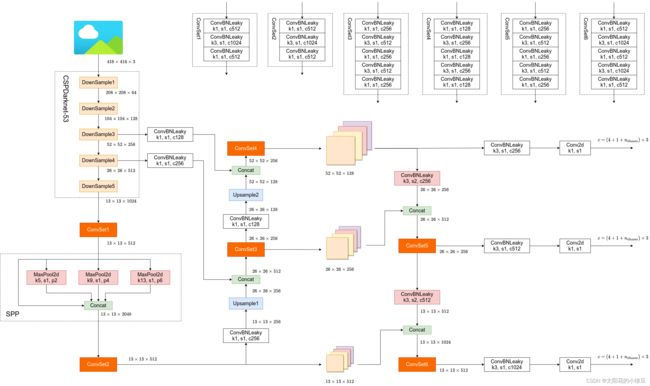
yolov4
yolov4创新点
这里只列举几个重要的:
1、主干特征提取网络:DarkNet53 => CSPDarkNet53
2、特征金字塔:SPP,PAN
3、分类回归层:YOLOv3(未改变)
4、训练用到的小技巧:Mosaic数据增强、Label Smoothing平滑、CIOU、学习率余弦退火衰减
5、激活函数:使用Mish激活函数
网络结构
- Backbone:
CSPDarknet53 - Neck:
SPP,PAN - Head:
YOLOv3
CSP 来自于CSPNet
SPP就是将特征层分别通过一个池化核大小为5x5、9x9、13x13的最大池化层,然后在通道方向进行concat拼接在做进一步融合,这样能够在一定程度上解决目标多尺度问题

PAN(Path Aggregation Network)结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合

这里与论文原文也有所不同,原文是将每个尺度add在一起,但是v4是在深度方向上进行拼接
Mosaic data augmentation
mosaic数据增强其实就是将4张图片resize放在一起 当作一张图片用于网络预测
优点;
可以增加目标个数、可以增加数据的多样性、BN能多次统计多张图片的信息。
BN时我们希望batch_size越大越好,因为这样我们就可以使获得的值更偏向于整体数据的值,但由于内存等的限制,我们的batch_size往往有约束,通过mosaic数据增强,也可以使BN能一次统计多张图片的信息。
定位损失LOSS
在讲解CIOU之前 我们需要先讲解 IOU 定位损失 DIOU 以及GIOU
IOU
IOU Loss的定义是先求出预测框和真实框之间的交集和并集之比,再求负对数,但是在实际使用中我们常常将IOU Loss写成1-IOU。如果两个框重合则交并比等于1,Loss为0说明重合度非常高。IOU满足非负性、同一性、对称性、三角不等性,相比于L1/L2等损失函数还具有尺度不变性,不论box的尺度大小,输出的iou损失总是在0-1之间。所以能够较好的反映预测框与真实框的检测效果。
IOU的优缺点
普通IOU的优缺点很明显,优点:
1、IOU具有尺度不变性
2、满足非负性
同时,由于IOU并没有考虑框之间的距离,所以它的作为loss函数的时候也有相应的缺点:
1、在A框与B框不重合的时候IOU为0,不能正确反映两者的距离大小。
2、IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IOU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。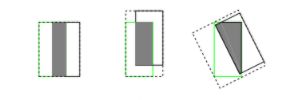
GIOU

GIOU LOSS 范围
Lgiou=1-GIOU [0,2]
当A与B完全重合时 GIOU为1
当A与B无穷远时 无重叠时 GIOU为-1
GIOU可以克服IOU 没有重合时 梯度为0的缺点,同时,即使IOU为0,但是GIOU也会有差别。
计算过程如下:
1.假设A为预测框,B为真实框,S是所有框的集合
2.不管A与B是否相交,C是包含A与B的最小框(包含A与B的最小凸闭合框),C也属于S集合
3.首先计算IoU,A与B的交并比
4.再计算C框中没有A与B的面积,比上C框面积;
5.IoU减去前面算出的比;得到GIoU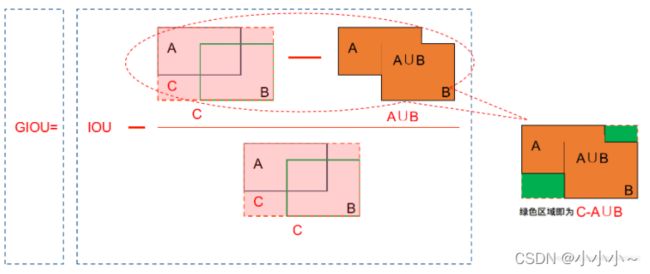
当A与B不变时,我们最小化Lgiou 其实就是 最小化C 其实也就是让A与B更接近。
缺点:
(1)收敛慢
尽管GIoU解决了在IoU作为损失函数时梯度无法计算的问题,且加入了最小外包框作为惩罚项。但是它任然存在一些问题。下图第一行的三张图片是GIoU迭代时预测框收敛情况。其中黑色框代表anchor,蓝色框代表预测框,绿色框代表真实框。
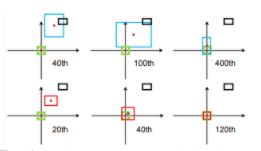
(2)当两个框水平或垂直重合时 退化为IOU
上图中可以看出,GIoU在开始的时候需要将检测结果方法使其与目标框相交,之后才开始缩小检测结果与GT重合,这就带来了需要较多的迭代次数才能收敛问题,特别是对于水平与垂直框的情况下。此外,其在一个框包含另一个框的情况下,GIoU降退化成IoU,无法评价好坏,见下图所示:
水平或垂直重合时,C=(A∪B) 此时GIOU=IOU。

我们可以看出 明明是第三个图 框比较好,但是IOU与GIOU 在这三幅图的损失都是一样的。只考虑了重叠面积。
因此引出了DIOU ,考虑了GT框与预测框的中心点距离。
DIOU
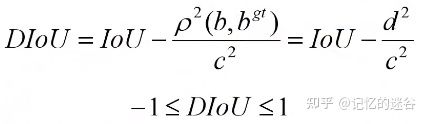
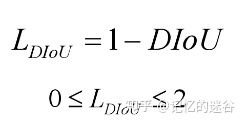
DIOU比GIOU收敛速度更快,准确率也更高。
CIOU
ciou将重叠面积、中心点距离以及长宽比都考虑了进去

CIOU公式:


优化策略
1 Eliminate grid sensitivity
2 IOU threshold(正样本匹配)
其余都可以见 该博主的!!very nice 图也很详细!!
很详细的博文
CSPDark53
CSPDarknet53就是将CSP结构融入了Darknet53中

k代表卷积核的大小
s ss代表步距
c cc代表通过该模块输出的特征层channels
注意,CSPDarknet53 Backbone中所有的激活函数都是Mish激活函数

注意:DownSample1与2,3,4,5不太一样
其两分支通道数并没有 是输入通道的一半,而且 他的残差块的通道数也有所不一样。
YOLOv4 采用的是卷积来进行下采样,而没有用池化,每个DownSample的开始都是进行了一个下采样,之后进行一次卷积,接着就是残差块,最后一个tranision,与layer1拼接,再进行一次tranision。
YOLOv4整体结构: