The World is Binary: Contrastive Learning for Denoising NextBasket Recommendation
论文地址https://dl.acm.org/doi/10.1145/3404835.3462836
摘要:下一个购物篮推荐旨在通过考虑用户之前购买的购物篮序列,推断出用户下次访问时将购买的一组物品。这项任务已引起学术界和工业界越来越多的关注。现有的解决方案主要侧重于对它们的历史交互进行顺序建模。然而,由于用户行为的多样性和随机性,并非所有这些篮子都有助于确定用户的下一步行动。为了提高推荐性能,有必要对篮子进行去噪并提取可信的相关项目。不幸的是,在目前的文献中,这一维度通常被忽视。
为此,在本文中,我们提出了一个对比学习模型(名为CLEA),用于自动提取与目标项目相关的项目,以供下一个篮子推荐。具体来说,在Gumbel Softmax的支持下,我们设计了一个去噪生成器,以自适应地识别历史篮子中的每个项目是否与目标项目相关。通过这个过程,我们可以为每个用户的每个篮子获得一个正子篮子和一个负子篮子。然后,我们通过一个基于GRU的上下文编码器,基于每个子篮子的组成项,推导出每个子篮子的表示,该编码器表示与目标项相关的偏好或无关的噪声。然后,设计了一个新颖的两阶段锚定引导对比学习过程,在不需要任何项目级关联监督的情况下,同时引导这种关联学习。据我们所知,这是第一次以端到端的方式对一个篮子进行项目级去噪,以便下一个篮子推荐。在四个具有不同特征的真实数据集上进行了广泛的实验。结果表明,我们提出的CLEA比现有的最先进的方案具有更好的推荐性能。此外,进一步的分析还表明,CLEA能够成功地发现与推荐决策相关的真正项目。
引言:1)去噪的重要性;2)对下一个篮子推荐的解释和历史研究工作;3)对所提出的方法的简单阐述。
结论:在本文中,我们解决了下一个篮子推荐场景中的去噪问题,我们提出了一个对比学习模型(名为CLEA)来自动提取与下一个篮子推荐的目标项目相关的项目。具体来说,我们首先设计一个去噪生成器,自适应地识别历史篮子中的每个项目是否与目标项目相关。通过将初始篮子分为两个子篮子,我们通过基于GRU的上下文编码器导出它们的表示,该编码器表达了与目标项目相关的兴趣或无关的噪声。然后,设计了一个新的锚定引导的对比学习过程来同时引导这种关联学习,而不需要任何项目级的关联监督。据我们所知,这是第一次以端到端的方式对一个篮子进行项目级去噪,以便下一个篮子推荐。作为未来的工作,我们计划利用弱监督信号来更好地理解项目之间的相互作用,以便进一步改进。
相关工作:阐述 1)下一个篮子推荐;2)基于注意力机制的推荐。

方法:
首先,设计一个去噪生成器![]() ,它相当于一个二元分类器,决定了篮子里的项目ij是否和目标项目ic相关,等于1相关,等于0不相关,
,它相当于一个二元分类器,决定了篮子里的项目ij是否和目标项目ic相关,等于1相关,等于0不相关,
![]()
f是多层感知机,如果f>=0.5,g就等于1,反之,g等于0.
然而,这种项目级的硬编码(即0和1)不可微,即不能进行反向传播,然后用gumbel softmax作为可微的替代项,以支持离散输出上的模型学习。
重写去噪感知机:
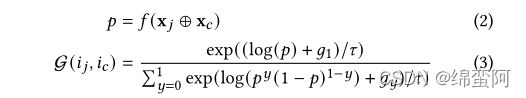
where is i.i.d sampled from a Gumbel distribution as a noisy disturber: = − log(− log()) and ∼ Uniform(0, 1). > 0 is the temperature parameter to smooth the discrete distribution of G. That is, adjusts the sharpness of the relevance estimation generated by G.
这样就可以根据G(*)的值把一个用户的购买历史分解成一个正子篮子序列和负子篮子序列。
其次,对每个子篮子,用一个简单的平均池化操作得到其嵌入表示:
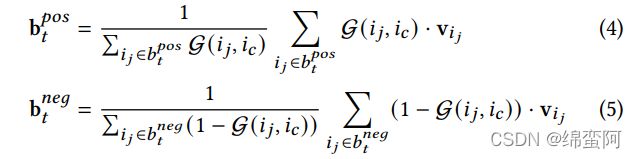
where b and b represent the positive and negative sub-basket representations of -th basket respectively, and v is the learnable embedding representation for item . Afterwards, it becomes straightforward to model the sequential interactions for two sub-basket sequences B and B respectively。
然后用GRU作为上下文编码器为在相应的序列中的每个子序列得到其隐藏表示:
![]()
其隐藏表示最后计算为最后一个子序列 b pos-n(表示为h pos-ic),作为一个用户偏好针对目标项目ic的组成部分,On the contrary, the hidden state h can be considered as a mixture of the user’s preferences irrelevant to . Note that the same GRU network is applied for both sub-basket sequences (i.e., B and B )
最后,执行锚引导的对比学习
Accordingly, we firstly calculate the likelihood that the user will purchase item as follows:
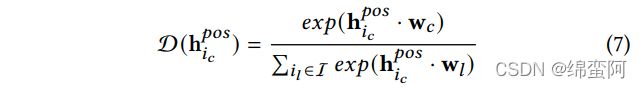
where w and w are the learnable preference embeddings for item and respectively, D (h ) ∈ (0, 1) is the likelihood where a larger value indicates the higher preference. Then the objective function is formulated as follows:

where is the regularization coefficient. Symbol Φ represents all model parameters including Φ for denoising generator G, Φ for GRU module and Φ for likelihood calculator D.
然而,由于缺乏项目级别的相关信息来监督G的学习,用公式8进行模型训练往往会产生不稳定的表现,所以引入了一个两阶段锚引导对比学习过程,以促进CLEA的优化。
具体来说,当不用去噪生成器G,也就是把每个篮子的所有项目都看成是相关的时候,历史篮子的原始序列就等于相应的正子篮子序列,在这种情况下,把经过上下文编码器所得到的结果![]() 看作是一个偏好锚
看作是一个偏好锚![]() 。
。
We believe that h ℎ could introduce some uncertainty, leading to a relatively low preference estimation, i.e., D(h ) >D(h ℎ ).
Similarly, when G performs well, the negative sub-basket generated by G cannot infer the user’s preference over item . That is, the preference estimation made by hℎ should be larger than the counterpart from h , i.e., D(h ℎ ) >D(h ).这段话没看懂
因此,目标函数可以看作是:
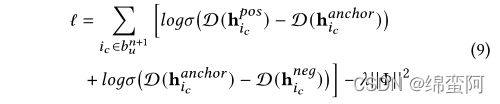
所以,本文设计了一个两阶段的学习过程来适应h ℎ 的优化,具体来说,整个边缘学习过程执行如下:(边缘学习是什么?)
第一步,首先不用去噪生成器训练D(h ℎ )获得一个基准,目标函数为:

第二步,根据等式9用已经预训练好的 D(h ℎ )去引导D(h neg )和D(h pos )的学习过程。
迭代这两步直至收敛。
实验部分略过了。