GPT笔记
GPT
采用两阶段法,第一阶段无监督预训练,第二阶段针对不同的任务进行有监督地精调。预训练阶段GPT使用Transformer的decoder结构。
给定句子 U = { u 1 , u 2 , . . . , u n } U=\{u_1, u_2, ..., u_n\} U={u1,u2,...,un},使用标准的语言建模目标,最大化似然概率
L 1 ( U ) = ∑ i P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(U) = \sum_i P(u_i | u_{i-k},..., u_{i-1}; \Theta) L1(U)=i∑P(ui∣ui−k,...,ui−1;Θ)
其中 Θ \Theta Θ是模型参数, k k k是滑动窗口
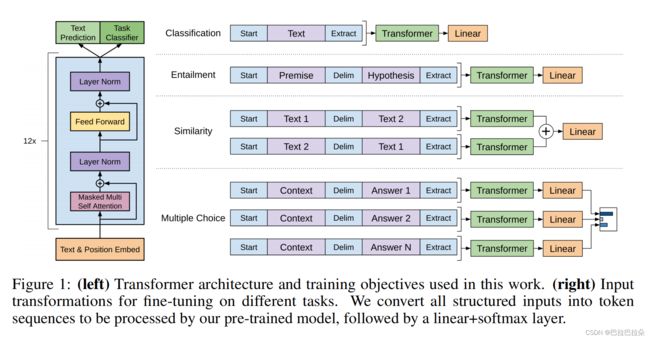
使用Transformer decoder,但是和原论文的decoder有所不同,只保留了一个masked multi-head attention,如下图
预训练阶段
设 u = ( u − k , . . . , u − 1 ) \mathbf u=(u_{-k}, ..., u_{-1}) u=(u−k,...,u−1)表示输入的句子, n n n表示层数, W p W_p Wp表示位置Embedding, W e W_e We表示词向量权重矩阵,
h 0 = u W e + W p \mathbf h_0 = \mathbf uW_e + W_p h0=uWe+Wp
h i = t r a n s f o r m e r _ b l o c k ( h i − 1 ) i ∈ [ 1 , n ] \mathbf h_i = \mathrm {transformer\_block}(h_{i-1}) \ \ \ \ \ i\in [1,n] hi=transformer_block(hi−1) i∈[1,n]
P ( u ) = s o f t m a x ( h n W e T ) P(\mathbf u) = \mathrm {softmax}(\mathbf h_nW^T_e) P(u)=softmax(hnWeT)
精调阶段
输入句子 x 1 , x 2 , . . . , x m x_1, x_2,...,x_m x1,x2,...,xm,有label为 y y y,预训练最后一个Transformer block输出的第 m m m个向量 h l m h_l^m hlm,加上输出预测层 W y W_y Wy
P ( y ∣ x 1 , x 2 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x_1,x_2,...,x_m) = \mathrm {softmax}(h^m_l W_y) P(y∣x1,x2,...,xm)=softmax(hlmWy)
最大化概率函数
L 2 ( C ) = ∑ ( x , y ) P ( y ∣ x 1 , x 2 , . . . , x m ) L_2(C) = \sum_{(x,y)} P(y|x_1,x_2,...,x_m) L2(C)=(x,y)∑P(y∣x1,x2,...,xm)
将语言模型损失作为一个辅助损失能有效帮助提升精调性能
L ( C ) = L 1 ( C ) + λ L 2 ( C ) L(C) = L_1(C) + \lambda L_2(C) L(C)=L1(C)+λL2(C)
模型参数配置
预训练:
Transformer层数=12
attention维度=768
head_num=12
FFN网络中中间层的维度=3072 (=768*4)
dropout_rate=0.1
激活函数=GELU
learning_rate 最大是2.5e-4,前面2000步从0逐渐增大,后面逐渐减小
精调:
dropout=0.1
learning_rate=6.25e-5
batchsize=32
lambda=0.5