Pytorch使用VGG16模型进行预测猫狗二分类
目录
1. VGG16
1.1 VGG16 介绍
1.1.1 VGG16 网络的整体结构
1.2 Pytorch使用VGG16进行猫狗二分类实战
1.2.1 数据集准备
1.2.2 构建VGG网络
1.2.3 训练和评估模型
1. VGG16
1.1 VGG16 介绍
深度学习已经在计算机视觉领域取得了巨大的成功,特别是在图像分类任务中。VGG16是深度学习中经典的卷积神经网络(Convolutional Neural Network,CNN)之一,由牛津大学的Karen Simonyan和Andrew Zisserman在2014年提出。VGG16网络以其深度和简洁性而闻名,是图像分类中的重要里程碑。
VGG16是Visual Geometry Group的缩写,它的名字来源于提出该网络的实验室。VGG16的设计目标是通过增加网络深度来提高图像分类的性能,并展示了深度对于图像分类任务的重要性。VGG16的主要特点是将多个小尺寸的卷积核堆叠在一起,从而形成更深的网络。
1.1.1 VGG16 网络的整体结构
VGG16网络由多个卷积层和全连接层组成。它的整体结构相对简单,所有的卷积层都采用小尺寸的卷积核(通常为3x3),步幅为1,填充为1。每个卷积层后面都会跟着一个ReLU激活函数来引入非线性。
VGG16网络主要由三个部分组成:
-
输入层:接受图像输入,通常为224x224大小的彩色图像(RGB)。
-
卷积层:VGG16包含13个卷积层,其中包括五个卷积块。
-
全连接层:在卷积层后面是3个全连接层,用于最终的分类。
VGG16网络结构如下图:
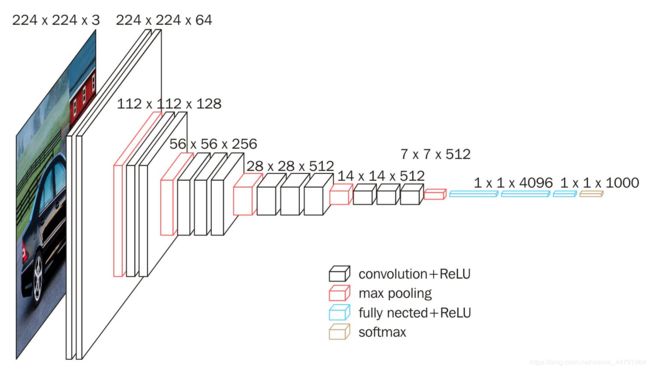
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
3、conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
4、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
5、conv4三次[3,3]卷积网络,输出的特征层为512,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
6、conv5三次[3,3]卷积网络,输出的特征层为512,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
1.2 Pytorch使用VGG16进行猫狗二分类实战
在这一部分,我们将使用PyTorch来实现VGG16网络,用于猫狗预测的二分类任务。我们将对VGG16的网络结构进行适当的修改,以适应我们的任务。
1.2.1 数据集准备
首先,我们需要准备用于猫狗二分类的数据集。数据集可以从Kaggle上下载,其中包含了大量的猫和狗的图片。在下载数据集后,我们需要将数据集划分为训练集和测试集。训练集文件夹命名为train,其中建立两个文件夹分别为cat和dog,每个文件夹里存放相应类别的图片。测试集命名为test,同理。
import torch
import torchvision
import torchvision.transforms as transforms
# 定义数据转换
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据集
train_dataset = ImageFolder("train", transform=transform)
test_dataset = ImageFolder("test", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)1.2.2 构建VGG网络
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 2
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 3
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 4
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block 5
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 2) # 输出层,二分类任务
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 展开特征图
x = self.classifier(x)
return x
# 初始化VGG16模型
vgg16 = VGG16()
在上述代码中,我们定义了一个VGG16类,其中self.features部分包含了5个卷积块,self.classifier部分包含了3个全连接层。
1.2.3 训练和评估模型
import torch.optim as optim
# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 10
model = VGG16()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item()}")
torch.save(model,'model/vgg16.pth')
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
print(outputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on test images: {(correct / total) * 100}%")
在训练模型时,我们使用交叉熵损失函数(CrossEntropyLoss)作为分类任务的损失函数,并采用随机梯度下降(SGD)作为优化器。同时,我们将模型移动到GPU(如果可用)来加速训练过程。