面试常见问题(一)
1.==与equals的区别
"==":该运算符不仅可以比较基本数据类型,还可以比较引用类型
如果"=="比较基本数据类型,此时判断他们的值是否相等
如果"=="比较引用类型,判断两个对象指向的内存地址是否相同
"equals":是object 类中的方法,所有继承自object的类都有equals方法,他只能判断引用类型
在object中默认判断地址是否相同,等价于"=="比较两个对象,如果在子类中重写了equals方法,此时也可以判断内容是否相同。
2.ArrayList与LinkedList
相同点:ArrayList与LinkedList都是List的实现类
不同点:
- 底层实现不同:
- ArrayList底层是基于数组实现的,对于普通的数组而言,它是一个可以动态修改的数组。没有数组大小的限制,我们可以进行添加元素和删除元素。
- LinkedList底层是基于双向链表来实现的,每一个元素都和他前一个元素和后一个元素连接在一起
- 工作效率不同:
- ArrayList由于底层的原因,对于查找某个元素的速度很快
- LinkedList对于添加,删除元素的速度更快,因为将元素添加到集合的任意一个位置时,不需要像数组一样重新计算大小或者更新索引。
- LinkedList相比于ArrayList更占用内存:因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
3.HTTP与HTTPS的区别
- HTTP运行在TCP之上;HTTPS是运行在SSL之上,SSL运行在TCP之上
- 两者使用的端口不同:HTTP使用的是80端口,HTTPS使用的是443端口
- 安全性不同:HTTP没有加密,安全性较差;HTTPS有加密机制,安全性较好
- 两者消耗资源大小不一:HTTP消耗的资源较少,HTTPS由于需要加密处理,所以消耗的资源更多
4.HTTP中POST和GET方法的区别
相同点:两者都是HTTP协议中的方法
不同点:
- get方法是用来从服务器上获取资源;post是用来向服务器提交数据的
- get方法的参数是通过URL进行传递的;post方法的参数存放在请求头或者消息体中进行传递的
- get方法相比于post方法更不安全,因为请求参数存在于url中,暴露在外
- get方法在url中传递的参数是有长度限制的(实际上HTTP协议本身对长度没有限制,限制是特定的浏览器以及服务器对他的限制,不同浏览器限制的长度不同。),POST对长度没有限制。
5.Cookie和Session的区别
- 用范围不同:cookie保存在客户端浏览器;session保存在服务器
- 存取方式不同:cookie只能保存ASCII,session可以存储任意类型的数据
- 有效期不同:cookie可设置为长时间保存,比如我们使用的默认登录功能;session一般有时间限制,客户端关闭或者session超时都会失效
- 存储大小不同:单个cookie保存数据大小不能超过4k;session存储数据可远远高于cookie
- 安全性不同:cookie将信息存储在客户端,容易遭到非法获取;session信息存储在服务器,安全新相对来说高一些。
6.HTTP常见的状态码
常见的状态码:
- 200:服务器处理请求成功。
- 301(永久重定向):浏览器请求的资源已经永久移动到了一个新的URL地址,浏览器会自动将请求重定向到新的URL地址
- 302(临时重定向):请求的资源只是暂时移动到了一个新的URL地址,浏览器会在下一次请求时再次访问原始URL地址。
- 400:客户端请求有语法错误,不能被服务器理解
- 403:服务器收到请求,但是没有权限,服务器拒绝提供服务
- 404(未找到):服务器找不到请求的资源
- 500(服务器内部错误):服务器错误,无法完成请求
状态码开头代表的类型:

7.对称加密和非对称加密
对称加密:对称加密指的是加密和解密都是同一个密钥。但是这种加密方式,如果被别人获取密钥,就可以直接获取解密内容,安全性有待提升。
非对称加密:非对称加密用到两个密钥,一个公钥一个私钥。每个客户都拿着一把公钥,服务器拿着一把私钥。公钥加密私钥可以解密;私钥加密公钥可以解密,但是公钥加密公钥不能解密。
区别:对称加密算法相比非对称加密算法来说,加解密的效率要高得多。但是缺陷在于对于秘钥的管理上,以及在非安全信道中通讯时,密钥交换的安全性不能保障。所以在实际的网络环境中,会将两者混合使用.。
8.JVM
8.1JVM运行时数据区
jvm运行时数据区主要分为五种:方法区,堆区,虚拟机栈,本地方法栈,程序计数器。
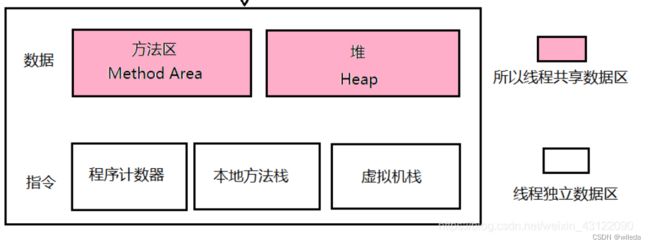
8.1.1方法区
方法区是所有线程共享的内存区域,它用于存储被Java虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。
当方法区无法满足内存分配时,会抛出OutOfMemoryError异常。
8.1.2Java堆
Java堆是Java虚拟机所管理的最大的一块内存,是被所有线程共享的一块区域。堆在虚拟机启动时创建,它的主要作用就是存放对象实例(new 出来的对象)
Java堆也是垃圾回收机制工作的区域。根据Java虚拟机的规定:Java堆可以处在物理结构不连续的内存空间,当前主流的虚拟机都是可扩展的。如果堆中没有内存可分配并且不能再扩展时,将会抛出OutOfMemoryError异常。
8.1.3虚拟机栈
Java虚拟机栈是线程私有的,它的生命周期和线程相同。每个虚拟机栈是由单位的,单位为栈帧。一个方法一个栈帧。每个方法在开始执行的时候都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法出口等。
当虚拟机栈中有很多的方法调用,此时会创建很多个栈帧,如果此时内存不够分配,那么就出现栈溢出的现象。
8.1.4本地方法栈
本地方法栈和虚拟机栈类似,只不过服务的是jvm的本地方法,虚拟机栈服务的是Java方法。
8.1.5程序计数器
程序计数器是一块很小的内存,可以看作是:保存当前线程所正在执行的字节码指令的地址
由于jvm虚拟机的多线程是通过处理器按照一定的标准所调度的,因此为了线程切换之后能按照上次的执行进度接着执行,所以由程序计数器来记录。
8.2垃圾回收机制
垃圾回收机制简称GC
程序在运行过程中,会产生大量的内存垃圾(一些没有引用指向的对象都成为内存垃圾,因为这些对象存在没有什么作用,没有被使用)为了确保程序运行的性能,jvm虚拟机在程序运行过程中不的进行垃圾回收(GC)。
8.3判断对象死亡
8.3.1引用计数法
在对象创建的时候,就给这个对象绑定一个计数器,每次有引用指向这个对象,计数器加一;如果引用指向失效,计数减一。如果计数器一直为0,保持不变,证明该对象已经死亡,可以GC
优点:实现简单,效率较高
缺点:不能解决对象之间循环引用的问题。所以一般不使用
8.3.2可达性分析
这种方法从GC roots开始向下搜索,所走过的路径称为一个引用链。如果从GCroots开始,不能到达某个对象,则证明该对象已经死亡,可以GC
可以作为GCroots的对象:
1、虚拟机栈(栈帧中的本地变量表)中引用的对象;
2、方法区中类静态属性引用的对象;
3、方法区中常量引用的对象;
4、本地方法栈中JNI(即一般说的Native方法)引用的对象
8.4回收算法
8.4.1标记-清除算法
为堆中的每个对象存储一个标记为,用来标记存活还是死亡。等到内存不够分配时,就将标记为死亡的对象进行GC.
优点:可以解决循环引用问题,并且在必要时才回收
缺点:在进行回收操作时应用要挂起等待;回收之后可用内存比较零散,后续申请大内存时不能满足。
8.4.2标记整理算法
和标记清除算法一样,为每一个对象做标记,不同点是,在清除死亡对象之后,会将现存的对象整理到一块,保证空闲的空间连续,方便后续使用
优点:解决内存碎片的问题
缺点:由于整理空间,对象移动了,所以要重新更新引用
8.4.3复制算法
复制算法是将堆内存一分为二,每次只使用其中一块,当这部分内存满了之后,将存活的对象复制到另一部分,然后整体清除该部分内存。
优点:GC效率很高
缺点:每次只是用1/2内存,内存利用率不是很高
5.4.4分代算法
分代算法不是一个具体的回收算法,是将使用特殊的方法,将上述算法综合起来使用,使GC效率更加的搞笑。
分代算法将堆分为新生代和老年代,在新生代区又分为Eden + 2个Survivor。
步骤如下:
首先创建的新对象都会存放在新生代的Eden区,当内存满了之后进行GC,随后将存活的对象移动到其中一个Survivor区,然后进行新的对象创建,再一次将存活的对象放在Survivor,然后整理Survivor,保证其中一个Survivor一直为空。等到对象在Survivor存活达到一定次数之后将其移动到老年代。
8.5类加载
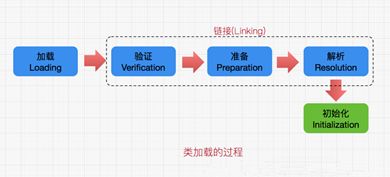
程序主动使用某个类时,发现该类还未被加载,此时就通过JVM经过加载,链接,初始化这三个步骤将类加载到内存当中,并完成响应的操作。
8.5.1加载
加载是指将类的class文件读入到内存当中,并将这些静态数据转换成运行时的数据结构。
8.5.2链接
链接阶段又分为三个步骤
1)验证:主要验证加载的类信息是否符合规范,能否被当前的虚拟机所处理
2)准备:正式为类变量分配内存并且赋初始值,这些内存都在方法区分配
3)解析:虚拟机常量池的符号引用替换为字节引用的过程
8.5.3初始化
初始化阶段就是java虚拟机真正的开始执行类中所编写的java代码 ,初始化完成之后,一个真正的对象就会被创建出来。
8.6双亲委派模型
双亲委派模型就是,如果一个类加载器收到了类加载请求,它首先并不会自己去加载这个类,而是向上请求,委托父类去加载这个类,如果父类也有父类,同样的也会向上请求,直到最顶层加载器才开始尝试加载,如果不能完成这个加载,那就由他的子类加载器去尝试完成,这就是双亲委派模型。
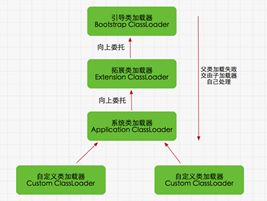
优点:Java类随着加载器有了层级关系 。这种层级关系可以避免类的重复加载,当父类加载器加载之后,子类加载器没有必要再加载了。其次考虑的安全层面,使用双亲委派模型可以保证java核心API不被篡改。例如,用户自己定义了object类,他和java提供的类名相同,如果没有双亲委派模型。用户可能直接调用自己定义的object类,会出现不安全问题。