卷积神经网络
目录
注意:有参数计算的才叫层
1.应用
1.1分类和检索
1.2超分辨率重构
1.3医学任务
1.4无人驾驶
1.5人脸识别
2.卷积
2.1卷积神经网络和传统网络的区别
2.2整体框架
2.3理解卷积(重点)
2.4为何要进行多层卷积
2.5卷积核的参数
2.6参数共享
2.7池化层
2.8整体结构
2.9VGG
2.10残差网络resnet
2.11感受野
参考文献
注意:有参数计算的才叫层
1.应用
1.1分类和检索
分类:简单理解为识别一张图片是狗还是猫。
检索:已经识别出一张图片是个狗,同时把是像狗(是狗)的图片都找出来。
1.2超分辨率重构
定义:就是把一张不清晰的图片变成一张清晰的图片
1.3医学任务
细胞检测等
1.4无人驾驶

1.5人脸识别
2.卷积
2.1卷积神经网络和传统网络的区别
用下图简述:下图左侧为全连接层的神经网络,也是多层感知机的概念,下图右侧是卷积神经网络。当输入一个28×28×1的图片时,传统神经网络会将像素拉成一列,作为输入,而卷积神经网络,则是按照28×28×1的三维特征作为输入。

2.2整体框架
以下图为例简述:
输入层:28×28×1像素的图片
卷积层:提取特征
池化层:压缩特征
全连接层:得到10种分类的概率

2.3理解卷积(重点)
以下图为例简述:首先我们看下图中间的红色框,假设他是一张图片,框中红色的圆圈是猫脸,蓝色框圈起来的是眼和嘴,假设这种图片32×32×3,我们希望能有效提取特征,不同的特征在不同的区域,比方说眼和嘴巴在不同的区域,猫和猫周围的环境也在不同的区域,所以为了提高效率,我们希望能按照区域提取特征,或者说得到嘴和眼睛等的有效特征,所以我们直接按照区域提取特征,比方说用一个5×5×3的卷积在图片中去提取嘴和眼睛的特征,区域的可以简单理解为下图左侧标记的1,2,3...等。
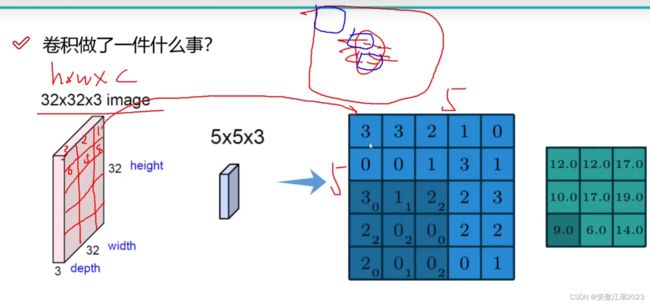
进一步我们用下图理解利用卷积时权重用在什么地方:假设输入是5×5×1的图片(蓝色区域),卷积是3×3×1的核,那么在第一个区域输入为x1,权重为w1(蓝色区域右下角的小标),输出为12,而12就代表该区域的特征,如果该区域是猫的嘴巴,那么12就属于嘴巴的特征。
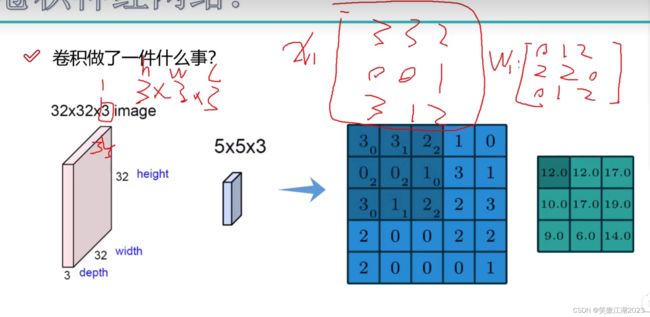
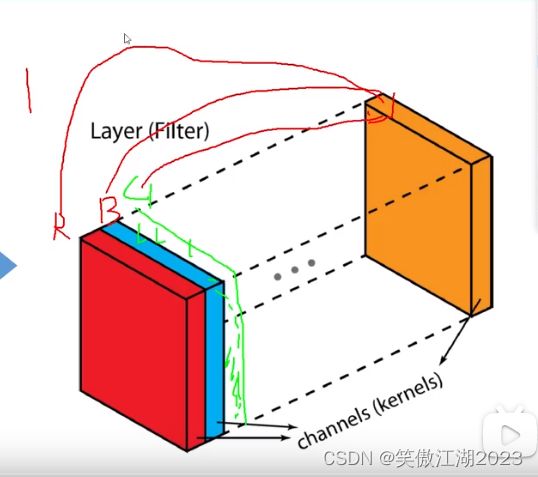
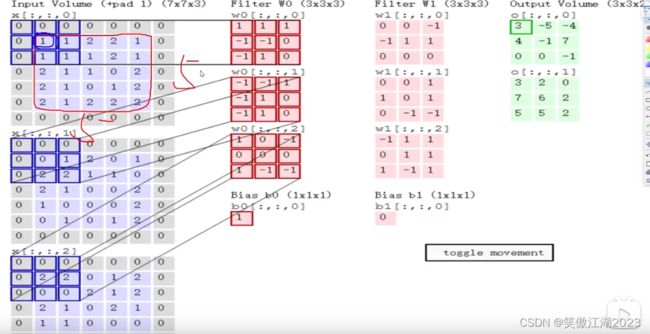
用下图进一步理解卷积的过程:首先我们要理解一个彩色图像在计算机中由RGB三张图组合在一起,才显示为彩色,假设输入为7×7×3,卷积为3×3×3(卷积核的值就是权重),三层卷积核分别和RGB第一个区域相乘,得到结果为R=0,G=2,B=0,也就是wx=2,再加上b输出为3,对应下图右侧绿框第一个值。
注意:这个输出为3×3×2,这个2不是RGB通道数,是彩图的个数。
用下图去理解上图:从下图左侧看,就是说分别对三层RGB进行计算,最后输出归为一层。从下图由侧理解,就是RGB合一重新变成彩图。

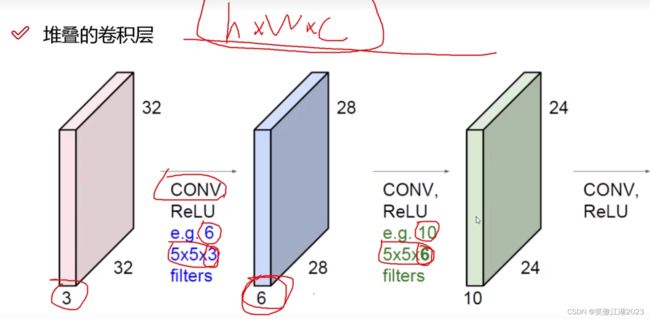
2.4为何要进行多层卷积
从下图简述:卷积的本质是特征提取,比方说,如下图左所示,我们进行三次特征提取,第一次Low-Level得到的特征,变成第二次Mid-Level的输入,同理第三层High-Level的输入是第二层的输出。我们从下图右理解这个过程,加上一张图32×32×3作为输入,用6个大小为5×5×3的卷积核得到6个28×28×1的特征图,其中每一个像素都是输入的RGB三个通道叠加而来,所以这6个特征图理解为彩图,表示为28×28×6,将该新数据作为输入,再用10个5×5×10的卷积核得到10个24×24×1的输出,表示为24×24×10。

2.5卷积核的参数
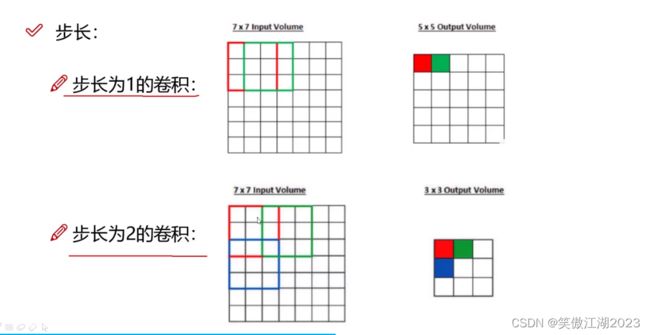
滑动窗口的步长:看下图不同的步长对应的结果不同,从结果讲,步长为1时我们得到的特征较多,比较细腻,但比较慢,步长为2时我们得到的特征较少,比较粗糙,但比较快。
卷积核大小:类似于滑动步长的效果。
边缘填充:从下图右去理解,我们可以看到红色框内是补充前的信息,框中的边界点,如第一个数1,在计算时只能计算1次,那么他只能对对应的结果3产生影响,而红框中间的数,因为参与多次相乘会对多个结果值产生影响,这样就带来一个问题,边界特征提取不充分,有缺失,所以在周围加一层数值0,可以保证边界特征,更有效的被提取。而且添加的数为0,该值不会对结果产生影响。
卷积核个数:取决于想得到多少特征图,注意每一个卷积核的值都不同。
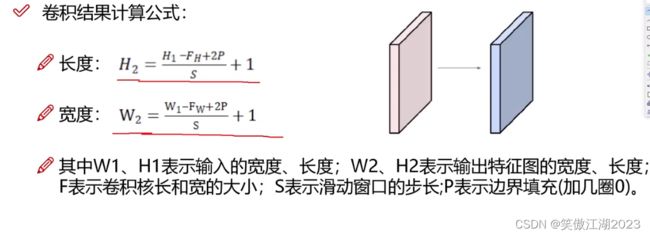
计算公式如下:

2.6参数共享
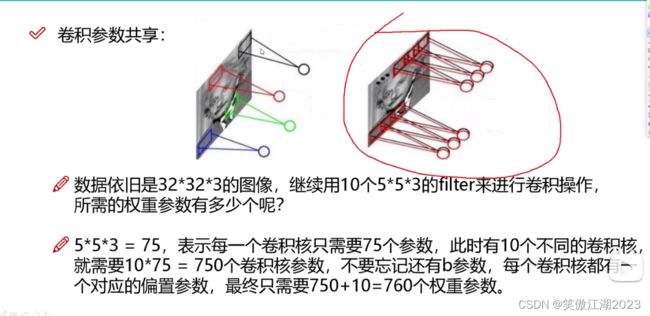
用下图简述:假设下图左为7×7×3的输入,第一个区域我们会用一组卷积核去得到输出特征图,第二个区域我们依然需要一组卷积核去得到输出特征,如果每一个区域对应的卷积核不同,计算量会非常大,为了便于计算,如下图右所示,对输入input Volum区域,用Filter W0 的3×3×3的卷积核进行卷积,用相同的卷积核和输入的每一个区域想乘,就是权值贡献。
从下图左我们看一下卷积参数和全连接参数的数量区别:对于一个32×32×3的图像,想得到10个特征,全连接层需要32×32×3×10=30720个参数,而卷积只需要5×5×3×10=750再加上10个偏置项,也只需要760个,这计算量差距太大了。
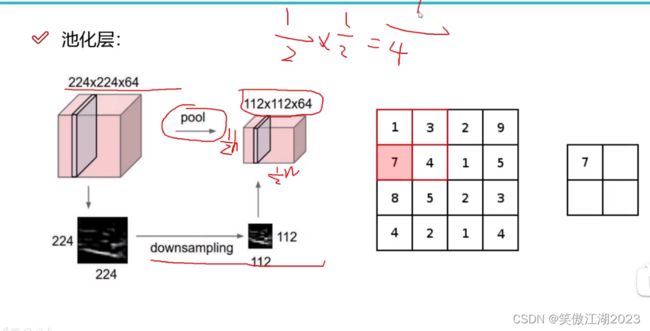
2.7池化层
从下图简述:下图左可以看出经过多层卷积后得到的输出为224×224×64,意思是得到64张特征图,每张特征图上有224×224个特征,可以发现数量太多,不利于计算,所以我们希望在不影响精度的前提下对它瘦身,这就是池化层,下图右就对每张特征图的长和宽进行了一半的瘦身。
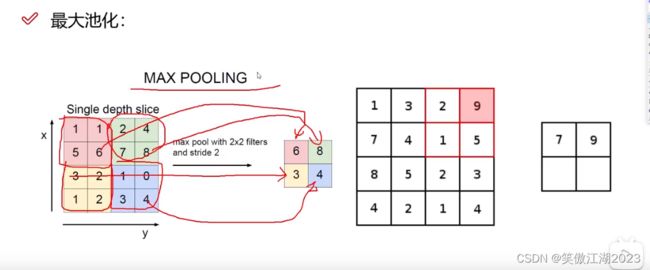
最大池化层:如下图右所示,就是从64张特征图,每张大小224×224,按照2×2的方格区域,选一个最大值出来,结果上讲长宽各自除以2,就是瘦身一半。
注意:该池化层只做了选择,没做计算。
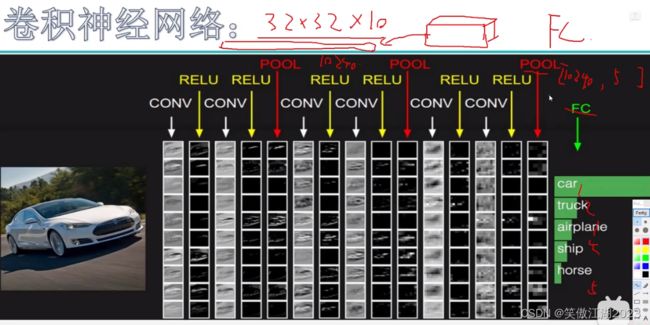
2.8整体结构
从下图简述:每一个卷积层由一个卷积核和非线性函数构成,每一大层网络由两个 卷积层和一个池化层构成,注意一下池化层之间的卷积层的输出结果,经过池化层后变化不大。对于FC(全连接层)之前的操作都是进行特征提取,但我们最终需要的是得到分类的概率结果,我们假FC(设全连接层)之前的池化层,这时得到的输出是32×32×10,但全连接层无法与之相乘,所以需要将32×32×10拉长成1×10240,FC(全连接层)为10240×5,5代表5个类别的概率。
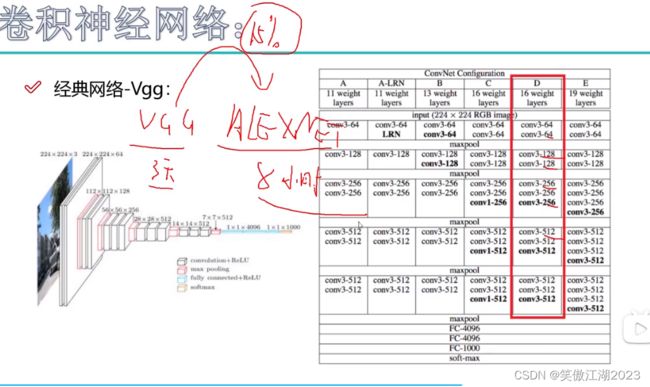
2.9VGG
从下图理解VGG:下图A,B,C,D,E等为VGG的不同版本,我们看D版本,总共16层,它的特点是,每经过一个池化层,长宽瘦一半,但失去的特征,会增加特征图的数量弥补回来,如conv3-64(64代表特征图数量)经过池化层之后,再过过一层卷积,变成conv3-128,特征图数量翻倍。其识别精确率远高于现代初代神经网络架构Alexnet。
问题:按理说,神经网络层数越多,效果越好,为什么VGG不往20层以上叠加,因为实验发现16层的效果好于32层。
解决:resnet
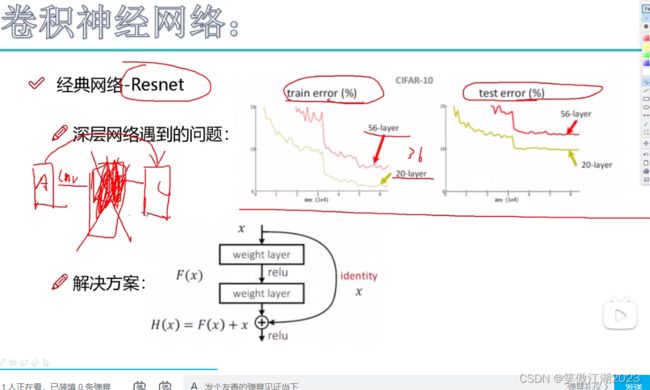
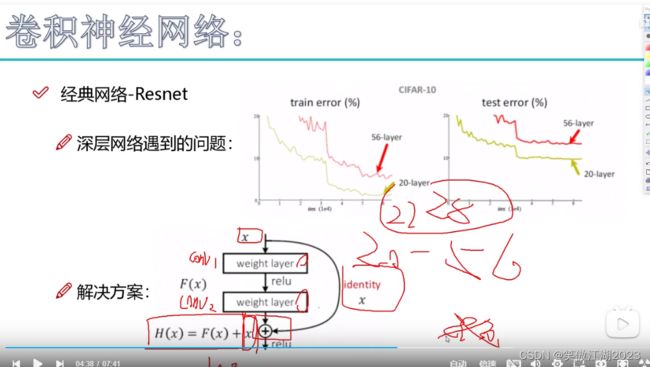
2.10残差网络resnet
从下图左简述resnet:在VGG中我们发现,当层数超过一定数量后,越多反而效果越差,分析原因发现,是因为有些层得到的效果不好,导致之后的效果越来越差。那么根据如何解决差的层提出了resnet.
resnet:可以这样简单理解。比方说有A,B,C三层网络,我们发现B层网络不好,希望剔除,但如果直接剔除,C层就没了输出,也就无法进行,所以提出一个概念,拉一条线,直接绕过B层,将好的结果传递给C层,而B层则用权重为0的系数,令其归零。
从从下图右进一步理解resnet:看解决方案对应的图,假设其是20层以后的网络,这时我们进行了conv1,和conv2两层卷积得到F(x),但我们担心这个结果不好,所以再次引入一条线,将x直接传到最后面的网络,最终结果为F(x)+x,当进行梯度下降时发现F(x)的梯度上升,则往上层反馈将上层卷积参数归零,直接使用x作为输入。
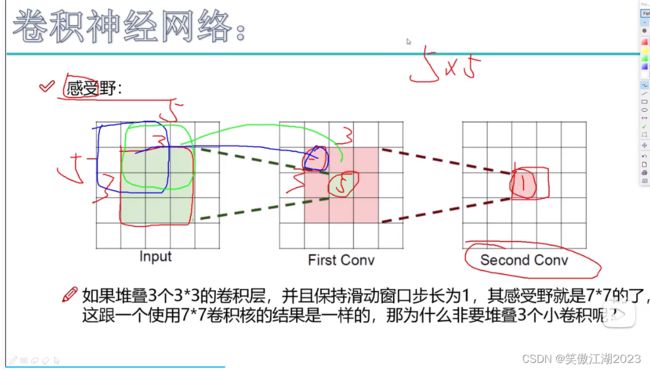
2.11感受野
用下图左简述:inpu为5×5×1,First Conv为3×3×1,Second Conv为1×1×1,First Conv(绿区)的感受野就是对应的input的3×3的绿区,而Second Conv(红区)对应的是上层红区3×3的感受野,上上层全部区域5×5的感受野。 一般来说我们希望感受野越大越好,因为越大看到的东西越多,分辨的就越好。那么问题来了既然越大越好,为什么长用3×3卷积核代替7×7卷积核。
理由:从下图右的计算看,3个3×3的卷积核感受野和一个7×7卷积核的感受野相同,但参数却少了很多,所以用3×3的卷积核代替7×7的卷积核。而且非线性函数也会减少很多,特征提取也会更细致。因为核比较小。

参考文献
1.2-卷积的作用_哔哩哔哩_bilibili