经典多模态论文阅读笔记
目录
一、ViLBERT
1、数据集
2、方法
Model-architecture
编辑
Co-Attentional Transformer Layers
Image Representations.
Training Tasks (two proxy tasks)and Objectives.
3、实验设置
training ViLBERT
Fine-tuning
4.创新点
5.结论
二、UNITER
0、ABSTRACT
1、INTRODUCTION
3.UNiversal Image-TExt Representation
3.1 Model Overview
3.2 Pre-training Tasks
三、Multimodal Pretraining Unmasked: A Meta-Analysis and a Unified Framework of Vision-and-Language BERTs
(一)统一理论框架
Singe-stream
Dual-stream encoders
Gated Bimodal Transformer Layers
(二)对照实验
1.Experimental Setup
2.Results
四、ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
0、Abstract
1.Introduction
3. Vision-and-Language Transformer
3.1. Model Overview
3.2. Pre-training Objectives
3.3. Whole Word Masking
3.4. Image Augmentation
4. Experiments
4.1overview
4.2. Implementation Details
4.3. Classification Tasks
4.4. Retrieval Tasks
4.5. Ablation Study
5. Conclusion and Future Work
一、ViLBERT
1、数据集
automatically collected Conceptual Captions dataset(google2018发布的)
330万图像,带有弱关联的描述性标题,在web上自动收集
2、方法
Model-architecture
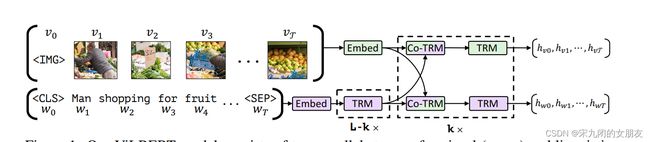
由两个平行的,在image region 和text segment上,使用bert方法的stream组成
每个stream由TRM和Co-TRM(用于模态之间交换信息)组成,两个stream在特定层交换信息
text stream在和视觉特征进行相互作用之前进行了更多处理(虚线处的TRM块)
Co-Attentional Transformer Layers
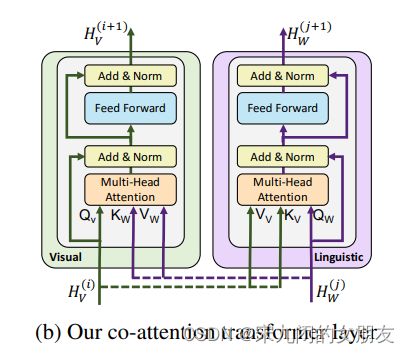
一个模态的query做另一个模态的value和key,在视觉流中perform图像条件的语音attention,在文字流中执行语言条件的图像attention
Image Representations.
生成图像region特征:用预训练好的目标检测网络Faster R-CNN (with ResNet-101 [11] backbone)提取bounding boxes和他们的visual feature。选出的 bounding boxes 均需超过 confidence threshold 并且每张图片只保留 10 到 36 个 high-scoring boxes
空间location编码:image region缺少自然的ordering,用一个5d向量进行编码。投影到和visual feature相同维度,然后两者相加。
Training Tasks (two proxy tasks)and Objectives.

- masked multi-modal modelling task
follow BERT,mask接近15%的word和image(masked text inputs和bert一致,masked image regions的图像特征有90%置0,10%不变),模型根据保留的input重建全部。不是直接预测遮挡的特征值,而是预测相应图像区域在语义类上的分布,为了做监督,我们使用特征提取时使用的预训练detection模型,为遮挡部分输出特征分布,训练模型以最小化两个分布之间的kl divergence。
语言只能识别视觉内容的高水平语义,不太可能重建精确的图像特征。
- multi-modal alignment task
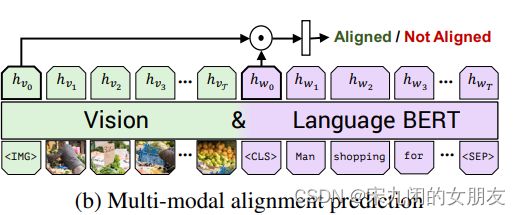
视觉和语言的的inputs整体表示成hIMG and hCLS,逐位相乘(element-wise)后进行二分类预测(the binary prediction),预测vision和language是否匹配对齐。
3、实验设置
training ViLBERT
linguistic stream: 在数据集BookCorpus 和 English Wikipedia上pretrain BERT,用base,12layers,hidden state size of 762,12 attention heads(用large应该表现更好)。
image stream:用上一节提到的Faster R-CNN,TRM和CO-TRM blocks 的隐藏层尺寸:1024,attention head:8。
Fine-tuning
遵循fine-tuning的策略:对pretrained base model 进行修改,然后进行端到端的训练(修改是细微trivial的,相比其他为每个任务单独定制模型的方法,更简单)。
- VQA : VQA 2.0 dataset由110万个关于coco图像的问题组成,每个问题有10个回答
在逐位相乘的上方学习一个两层的MLP,把representation映射到3129个可能的回答。将VQA视作一个多标签的分类任务,基于每个答案和10个人类答案的相关性,为每个答案分配一个软目标分数(soft target score)。在软目标分数上训练(binary cross-entropy loss,batch_size=256,epoch=20,学习率=4e-5,优化器Adam),推理时简单的使用softmax。
4.创新点
- 以往的方法:使用分离的语言和视觉模型去预训练,在大规模的任务上学习grounding作为任务训练的一部分,结果就是学习到目光短浅的grounding,泛化能力差。本文的方法:在各自的流中处理图像和文本输入,这两个流通过Co-attention transformer层进行交互(学习图像和文本的内在联系)
- 一种转折:从将学习视觉和语言之间的基础知识(grounding)仅作为具体任务的一部分,转向把视觉基础知识(visual grounding)作为一种可预训练和可迁移的能力。
5.结论
实验结果:比single-stream效果好,比没有预训练的ViLBERT效果好,数据集大、stream深效果好。和语言、视觉模型分开预训练的SOTA相比,提升了2-10个百分点。在4个任务上SOTA。
二、UNITER
0、ABSTRACT
4个数据集上预训练:COCO、Visual Genome、Conceptual caption和SBU caption
4个pretraining tasks:Masked Language Modeling(MLM), Masked Region Modeling (MRM, with three variants), Image-Text Matching (ITM), and Word-Region Alignment (WRA).
在pretraining tasks上使用conditional masking
实验结果:UNITER在6个V+L任务中SOTA
除了ITM用于全局的图像-文本对齐,还提出了WRA,使用OT(最优传输)鼓励在pretraining中的单词和图像区域的细粒度对齐
1、INTRODUCTION
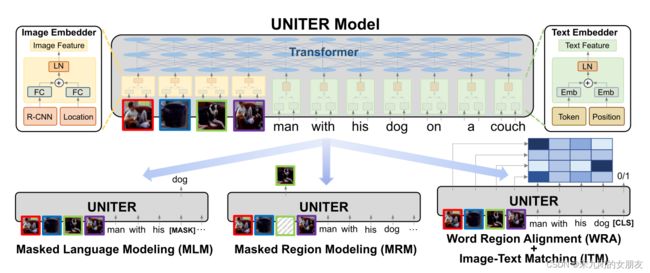
首先,使用image Embedder和 Text Embedder把image regions(visual features 和bounding box features) 和 textual words(tokens and positions)编码到一个通用的嵌入空间。
然后,使用Trm module 学习每个region和每个word的通用的上下文embedding通过well-designed pre-training tasks
- contribution
1)提出UNITER,用于V+L任务的强大通用图像-文本表示
2)提出基于条件掩码的掩码语言/区域建模方法并提出一种新的基于最优传输的词-区域对齐任务
3)V+L达到新的水平,大大超过现有的方法
3.UNiversal Image-TExt Representation
3.1 Model Overview
Image Embedder和 Text Embedder,得到的embedding送入多层TRM。self-attention没有顺序的,所以有必要显式的为token的position和region的location进行编码
image Embedder:先用Faster R-CNN给每个region提取视觉特征,用7d(normalized top/left/bottom/right coordinates, width, height, and area.)向量给每个region的location特征编码,并且用fc层将两个特征映射到相同维度。最终的视觉特征通过相加两个fc的输出然后通过LN层获得。
Text Embedder:和BERT一样,把句子分成WordPieces,最后的特征通过相加两个embedding并且通过LN层获得。
在4个任务上进行预训练,MLM MRM ITM WRA
MRM和MLM和BERT类似,随机mask一些words和regions,token用[MASK]替代,region用all zeros替代,只mask一种模态,防止当masked region恰好被masked word描述时发生潜在的不对齐(misalignment)。
3.2 Pre-training Tasks
- Masked Language Modeling (MLM)
随机mask15%的input words,用[MASK]替代。goal:通过image regions和unmask的words预测masked words。
- Image-Text Matching (ITM)
输入是一个sentence和一组image regions,输出是二分类标签。提取[cls]的representation作为输入的image-text对的联合表示,送去FC层和一个sigmoid 预测得分。
- Word-Region Alignment (WRA)
- Masked Region Modeling (MRM)
mask their visual features的15%,用未遮挡的region和所有的words对遮挡的进行预测。
1)Masked Region Feature Regression (MRFR)
2)Masked Region Classification (MRC)
3)Masked Region Classification with KL-Divergence (MRC-kl)
三、Multimodal Pretraining Unmasked: A Meta-Analysis and a Unified Framework of Vision-and-Language BERTs
paper主要完成两件事:
- 将单流和双流编码器统一在一个单一的理论框架
- 通过对照实验,辨别五个V&L BERT之间的经验差异
contribution in this paper:
- 提出统一的数学框架,目前提出的V&L BERT模型都是这个框架的可能性的一个子集
- 发布VOLTA的pytorch代码(visiolinguistic Transformer architecture)
- 进行一系列对照实验,发现相同条件下,一些模型的表现相同
- 单流和双流表现同样好,但两种模型之间表现可以显著不同,embedding层起关键作用
- V&L BERT对权重初始化很敏感
(一)统一理论框架
Singe-stream
1、encoder
图像-文字对的视觉和语言的feature串联在一起,作为bert的输入
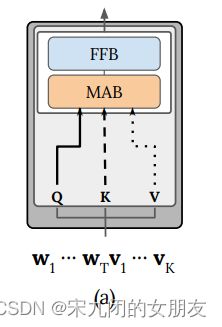
2、transformer layer
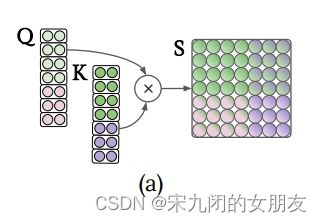
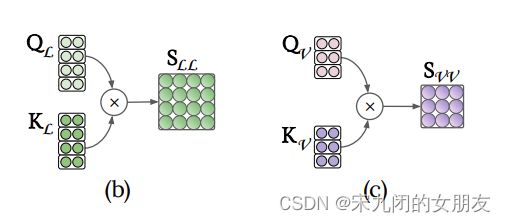
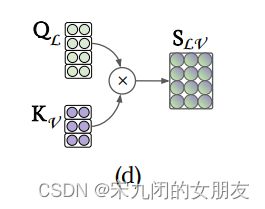
QKV的计算方式:(以Q为例,KV同下)
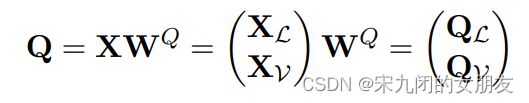
单流的层计算模态内部(对角线的s)和跨模态的注意(不是对角线的s)
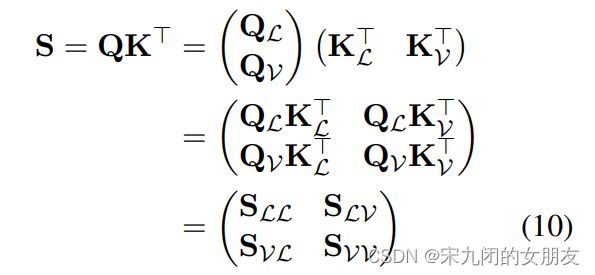
Dual-stream encoders
1、encoder
视觉和语言的feature先被送入两个独立的Trm layer进行处理,然后得到的表示被送入跨模态Trm layer,模态内相互作用与模态间相互作用交替进行。
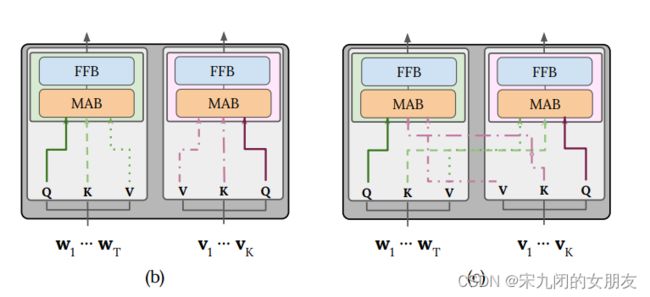
VILBERT和LXMERT都是先做自己的kqv矩阵计算,再把k和v送到其他模态做计算。通过这样做,这些模型明确地约束了每一层模式之间的交互,抑制了在单个流编码器中可能发生的一些交互,同时通过单独的可学习参数集提高了它们的表达能力。
2、transformer layer
Inter-modal Transformer layer
Intra-modal Transformer layer
Gated Bimodal Transformer Layers
- 这是一个架构,single和dual stream都是它的特殊情况,使用这个架构能够在一个controlled environment中评估现有的模型。除原来的输入,多了γ = {γLV, γVL, γLL, γVV} 和 τ = {τMHA, τLN1 , τFF , τLN2 }。
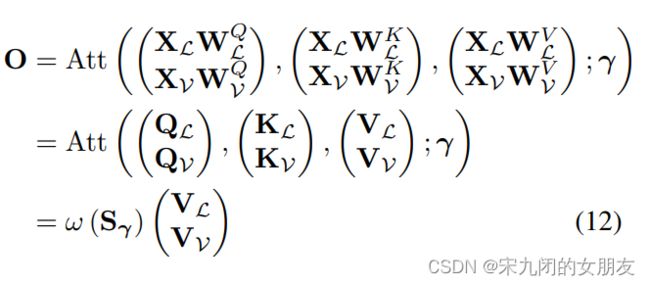
其中Sr中ε → −∞,当r=1,softmax后对角线位置为0,相当于只有模态间,当r=0,所有系数是1,相当有单流,有模态内和模态间,通过控制参数r调节模态内attention和模态间的attention。
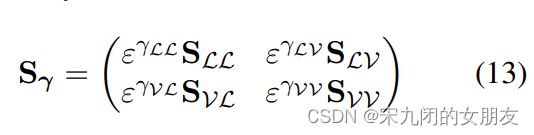
- gated bimodal TRM 允许我们对迄今为止考虑的用于多模trm编码器的交叉模态融合的少数组合的超集进行建模
(二)对照实验
(1)预训练数据和目标
(2)超参数
(3)预训练时的随机初始化引起的variance(差异、方差)
(4)下游任务时多次微调引起的variance
(5)单流 / 双流架构
(6)embedding layer 的选择
1.Experimental Setup
VOLTA (Visiolinguistic Transformer architectures)
实现细节:用Faster R-CNN或ResNet-10提取图像的特征,每个图像有36个region,模型用BERT的参数进行初始化。全连接层和embedding层随机初始化成正态分布,均值为0.0,标准差为0.02,初始偏差向量设为0.0,层归一化权重向量设为1.0。基于预训练目标给出最佳验证性能的参数集用于下游任务。
pretraining:the Conceptual Captions dataset
Downstream evaluation tasks:通常评估的任务跨越四个组:vocab-based VQA 、 image–text retrieval 、 referring expression and multimodal verification。如图5
2.Results
进行对照实验,调查V&L BERT之间报告的性能差异的可能原因
下面的实验用官方发布的代码评估三个模型VIL-BERT, LXMERT and VL-BERT
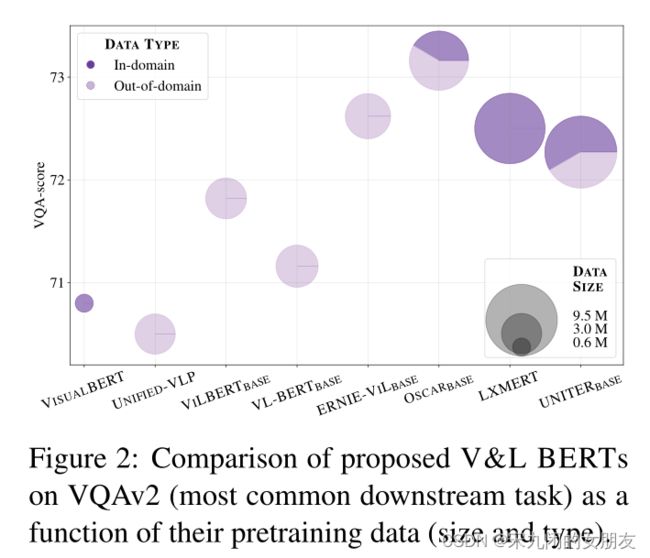
图2表示:数据量的大小可以影响performance
- Same data, similar performance
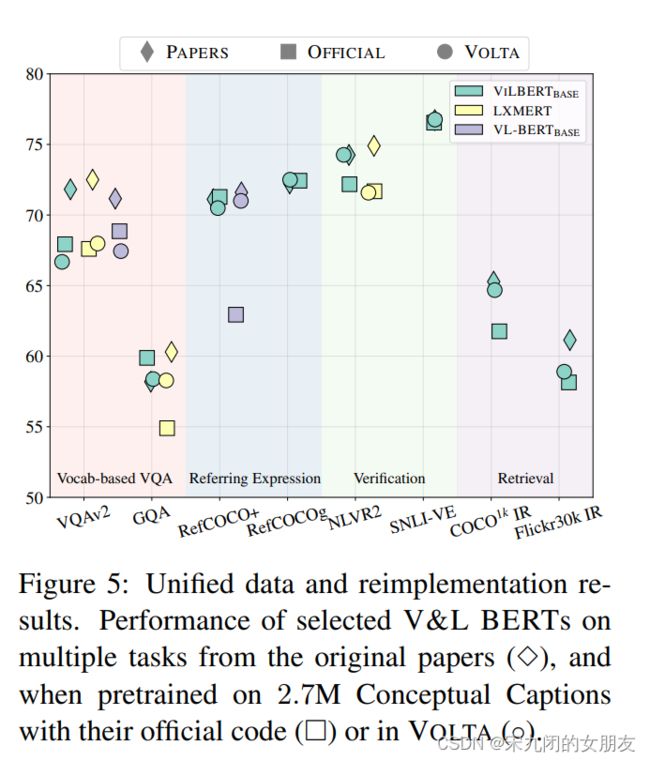
图5 菱形是论文中的结果,方块是使用官方代码在2.7M Conceptual Caption的结果,圆是VOLTA在2.7M Conceptual Caption的结果.在一些任务中,方框表现不好,但是这是因为比原论文中的pretrain数据少。
结论:当使用相同的数据进行预训练时,这些模型之间声称的性能差距会缩小。本节实验演示了VOLTA的正确性,这些模型是按照第三章中介绍的统一架构建的。
- controlled setup
对inputs 、 encoders、 pooling、 pretraining objective、 fine-tuning、 hyperparameter进行设置
结果表明,与官方设置相比,大多数测试的模型在controlled setup中表现类似
- Single- or Dual-stream Architectures
单流和双流差别不大
- The Importance of the Embeddings
embedding层对结果影响很大
四、ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
0、Abstract
提出的背景--目前的VLP(Vision-and-Language Pre-training)方法都要依靠图像特征提取过程,大多数涉及region supervision(物体检测)和convolutional architecture(Resnet),存在问题:
1)效率/速度:只是提取input 的feature就要花费比模态之间交互多得多的computation
2)表现力:因为它是visual embedder和它预定义的视觉词汇的上界
1.Introduction
大多数研究都通过增加视觉embedders的功能来提升性能,为了减轻特征提取的负担,通常在训练时提前缓存region features,所以视觉嵌入很heavy的问题通常被忽视。
我们推测,trm module用于VLP的模态相互作用时,能够像处理文本特征一样,处理视觉特征,代替卷积视觉embedder
ViLT:用统一的方法处理两种模态,比region feature 的模型快十倍,最少比grid feature快四倍,在表现相同甚至表现更好时。
3. Vision-and-Language Transformer
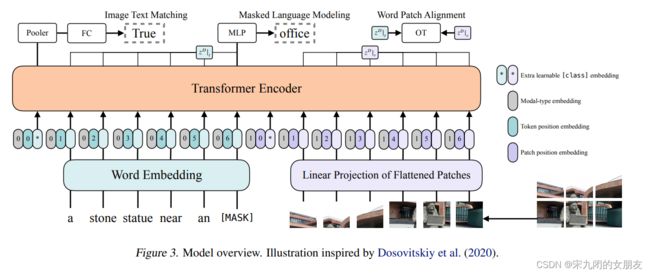
3.1. Model Overview
用ViT初始化interaction trm权重而不是BERT,ViT由堆叠的块组成,其中包括一个多头自注意层(MSA)和一个MLP层。BERT的LN在MSA和MLP层后面,ViT在前面。
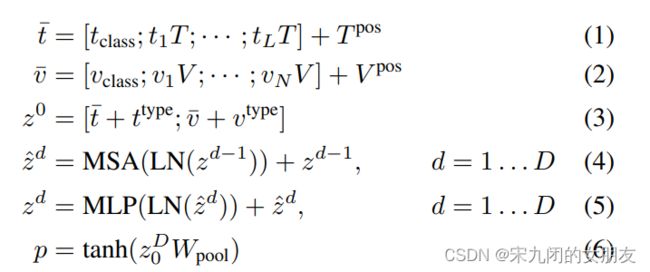
text的input维度是L×|V|,通过|V|×H投影后得到L×H,position的维度是(L+1)× H;
image的input维度是C×H×W,patch大小为P,N = HW/P2,patch后v的维度为N×(P2×C),经过维度为(P2×C)×H的投影后,得到维度为N×H,position embedding的维度是(N+1)×H;
text和image的embedding和他们的对应的模态类型相加,得到z0;
contextualized向量z经过不断迭代,通过D层trm,知道最后输出序列zD;
p是整个多模态的输入,是序列zD的第一个index zD0 投影后送入tanh得到的(如图pooler的过程);
使用的权重是ImageNet上预训练的ViT-B32。
3.2. Pre-training Objectives
- Image Text Matching(ITM)
50%的概率,随机替换aligned image中的image,在pooler的输出后接一个FC层,映射成一个二值logits,用于判断文本和图片是否对应。
受区域对齐目标的启发(UNITER)设计了WPA(word patch alignment),计算两个subset(textual subset 和 visual subset)的对齐分数,使用的是不精确的近端点方法进行最优传输--the inexact proximal point method for optimal transports (IPOT) 。
- Masked Language Modeling.(MLM)
随机mask15%的tokens,文本输出接两层的MLP,通过文本的上下文信息去预测masked tokens
上面两个任务的损失函数都是negative log-likelihood。
3.3. Whole Word Masking
在mask tokens时,遮挡的是一整个word中所有的subword,比如,giraffe被tokenized成三个wordpiece tokens,["gi", "##raf","##fe"],如果不是把三个全部mask,而是["gi","[MASK]", "##fe"],那么,遮挡的token可能不是通过来自图像的信息预测,而是通过两个没有遮挡的词。
3.4. Image Augmentation
图像增强在视觉模型中被证明可以提高泛化能力,DeiT是基于ViT,试验了各种增强技术,证明了augmentation对ViT训练有益。但是在VLP模型中没有image augmentation的研究,视觉特征缓存限制了基于region特征的VLP模型使用图像增强。
在fine-tune中应用RandAugment,除了颜色反转(文本通常包括颜色信息)和剪切(因为可能清除分散在整个图像中的小但是重要的对象)
4. Experiments
4.1overview
4个datasets做预训练:Microsoft COCO(MSCOCO) , Visual Genome (VG) , SBU Captions (SBU) and Google Conceptual Captions (GCC)
下游任务:1)分类:VQAv2 and NLVR2,2)检索:MSCOCO and Flickr30K
分类用不同的初始化参数微调三次,检索任务微调一次
4.2. Implementation Details
优化器:AdamW optimizer
基础学习率为10−4,权重衰退为10−2;
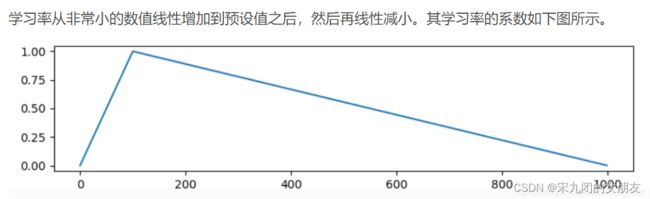
学习率在总训练步骤的前10%warm up, 然后在后面的训练中线性衰减到0。(图是warm up)
关于图像:将输入图像的较短边缘调整为384,将较长的边缘限制在640以下,同时保持长宽比。其他VLP模型中,使用短边800的尺寸。ViLT-B/32产生(384/32)×(640/32)=12×20=240个patches, 因为这是一个很少达到的上限,所以在预训练时最多采样200个patch。
关于文本:tclass、T、Tpos不是从pretrained BERT进行微调,而是scratch,有论文证明效果更好
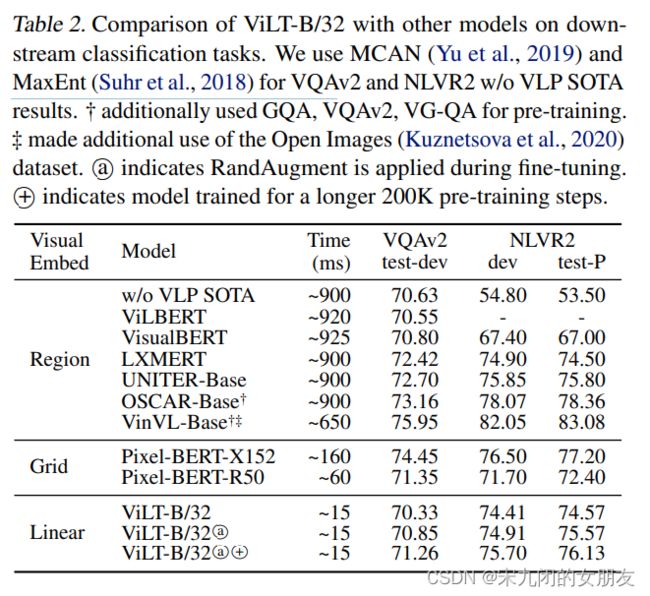
4.3. Classification Tasks
在两个普遍被使用的数据集VQAv2 and NLVR2上被测试,使用一个两层的MLP作为微调head
- Visual Question Answering:常见做法是将任务转换为包含3129个答案类的分类任务。在VQAv2的训练和验证集上对ViLT-B/32进行微调,余下1000validation images进行内部验证。
- Natural Language for Visual Reasoning:给两个图片和一个问题,二分类判断哪个对应。输入两个pairs(question,image1)和(question,image2),每个pair经过ViLT,head把两个pooled 表示(p)合并作为输入,输出二分类预测。
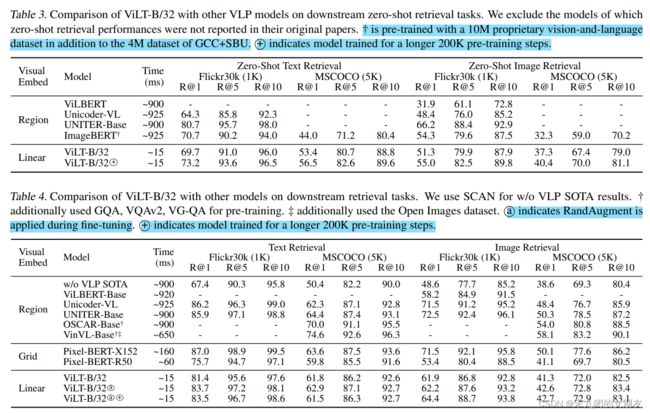
4.4. Retrieval Tasks
对于image-to-text和text-to-image的检索,测试了zero-shot和fine-tune
4.5. Ablation Study
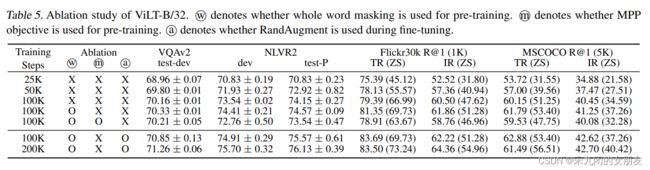
1)随着训练step变长,模型表现不断变好(1-3行),iteration增加到200k后开始降低
2)遮挡全部单词,模型表现变好(3-4行)
3)使用augmentation,模型表现变好(4行和6行)
4)使用masked patch prediction (MPP)进行预训练,模型表现变好
5. Conclusion and Future Work
ViLT是最小的VLP架构,与大量配备卷积视觉嵌入网络的竞争对手相比,是可以胜任的。
ViLT证明了没有卷积和区域监督的VLP网络是可以胜任的。
Scalability:在适当的数据量下,预训练trm的性能可衡量,这一观察结果为性能更好的ViLT变体铺平了道路。
Masked Modeling for Visual Inputs:通过将信息保留到trm的最后一层,视觉模态的掩蔽建模目标有助于保持信息。鼓励未来不使用区域监督的工作,为视觉形态设计更复杂的掩蔽目标。
Augmentation Strategies:对文本和视觉输入的适当增强策略的探索将是有价值的补充。