数据库基础与应用一
数据库基础与应用
表结构管理–MySQL基本数据类型
(1)整型:
TINY INT (小整型) 1byte
SMALL INT 2byte
MEDIUM INT 3byte
INT 4byte
BIG INT 8byte
(2)浮点型:
FLOAT(M,D) 4byte
DOUBLE(M,D) 8byte
M总个数 D小数位
(3)字符串类型:
(1)CHAR和VARCHAR
CHAR和VARCHAR类型用于声明常规字符串,CHAR定义固定长度字符串,VARCHAR定义可变长字符串。
CHAR列的长度固定为创建表时声明的长度。长度可以为从0到255的任何值。当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检索到CHAR值时,尾部的空格被删除掉,所以,我们在存储时字符串右边不能有空格,即使有,查询出来后也会被删除。在存储或检索过程中不进行大小写转换。
VARCHAR长度可以指定为0到65535之间的值,与CHAR不同的是,VARCHAR值保存时只保存需要的字符数,另加一个字节来记录长度,所以值保存时不进行填充。
(2)BINARY和VARBINARY
BINARY和VARBINARY用来存储二进制串,其存储和使用方式类似于CHAR和VARCHAR类型。不同的是,它们没有字符集,并且排序和比较基于列值字节的数值。另外,当保存BINARY值时,在它们右边填充0x00(零字节)值以达到指定长度,而非空格。
(3)TEXT和BLOB
TEXT和BLOB是以对象类型保存的文本与二进制,功能类似CHAR和BINARY,一个用来存储字符串,一个用来存储二进制串。在大多数时候,可以将TEXT视为足够大的VARCHAR,将BLOB视为足够大的VARBINARY.但TEXT和BLOB与VARCHAR和VARBINARY的不同之处在于以下几点:
➢当保存或检索 BLOB和TEXT列的值时不删除尾部空格。
➢比较时将 用空格对TEXT进行扩充以适合比较的对象
➢对于BLOB和TEXT列的索引,必须指定索引前缀的长度。对于CHAR和VARCHAR,前缀长度是可选的。
➢BLOB 和TEXT列不能有默认值。
(4)日期时间类型
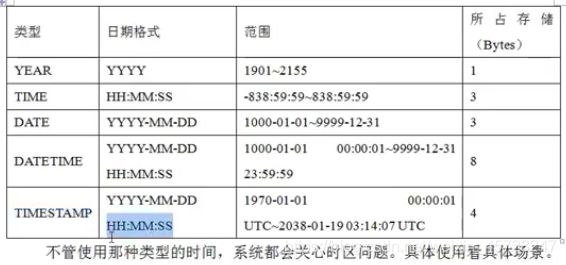
完整的一个表结构:

有三种类型的表,上图的这个表是没有主外键关联的用myisam,就是一个单表操作,速度快,而InnoDB这个适用于有主外键关联的,速度慢,所有涉及到钱、责任是要用InnoDB,一般不同的安全性要求不高的可以用myisam,其次,还有memory表,这个速度最快,但是数据库一关,数据就没了,是储存在内存中的。
一个完整的建表语句
create table admin(
id bigint not null auto_increment primary key,
uname varchar(60) not null,
pwd varchar(60) not null,
nicheng varchar(60) not null,
updtime timestamp not null,
createtime timestamp not null,
role tinyint not null default 1,
unique key unameunip (uname)
)ENGINE=myisam DEFAULT CHARSET=utf8;
用上述语句创建完数据库之后可以用desc来查看表结构,如下图:
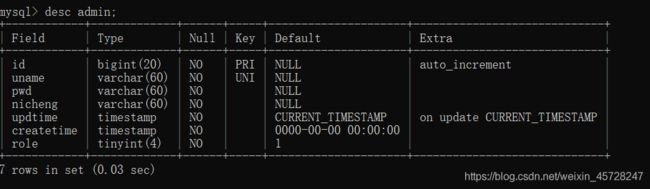
表结构管理–增删改查
(附录)带关联的表结构(数据表查看)
desc 表名;
例如:
desc channels;
新建一个数据库及三个有关联的表
/栏目表/
create table channels( /频道/
id bigint not null auto_increment primary key ,
cname varchar(120) not null, /栏目名称/
flag tinyint not null default 0 /0表栏目可用,1表禁用/
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table books( /书籍/
id bigint not null auto_increment primary key,/书id/
cid bigint not null, /栏目id/
title varchar(120) not null , /标题/
introduction varchar(320), /图书介绍/
constraint fk_channel_id /创建一个外键关联,名字叫fk_ channel_id/
foreign key(cid) references channels(id) /foreign cid做外键,references关联到channels表中的id/
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/内容表/
create table contents( /章节/
id bigint not null auto_increment primary key,
bid bigint not null, /书id/
ctitle varchar(120) not null ,/子标题/
content text , /内容/
updtime timestamp not null,
createtime timestamp not null,
constraint fk_books_id
foreign key(bid) references books(id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
(1)添加字段
给channels表添加一个bnum字段,表示书本数量
alter table channels add bnum int not null default 0;
(2)修改字段
alter table channels modify bnum int not not null default 0;
(3)删除字段
如果我们不需要bnum字段删除用:
alter table channels drop bnum;
(4)数据表删除
删除表、表结构关联关系
drop table channels; /用于删除没有关联的数据表/
如果删除错误的话,先删除没有关联的数据表,然后在删除有关联的表,例如:
drop table contents,books,channels;
基本语法–数据插入
建表的语句:
create table admins(
id bigint not null auto_increment primary key,
uname varchar(60) not null,
pwd varchar(60) not null,
nicheng varchar(60) not null,
updtime timestamp not null,
createtime timestamp not null,
role tinyint not null default 1,
unique key unameunip (uname) /唯一键索引/
)ENGINE=myisam DEFAULT CHARSET=utf8;
/管理员信息表/
create table admininfos(
id bigint not null primary key,
name varchar(60) not null ,
cardid varchar(60) not null, /* 身份证号*/
tel varchar(11) not null,
address varchar(60),
updtime timestamp not null,
createtime timestamp not null,
unique key cardiduniq (cardid),
unique key teluniq (tel)
) ENGINE=myisam DEFAULT CHARSET=utf8;
(1)数据插入
insert into admins (uname,pwd,nicheng,role) values(‘admin’,‘3766’,‘超级管理员’,0);
(2)时间插入
insert into admins (uname,pwd,nicheng,createtime) values(‘xianxia’,‘123123’,‘仙侠频道管理员’,sysdate());
sysdate()是使用的系统时间,此条插入语句不用role(类比数据插入的插入语句),因为默认1是系统管理员。
insert into admins set uname=‘dushi’,pwd=‘1234’,nicheng=‘都市频道管理员’,createtime=sysdate();
这个是第二种插入方案,相对于第一种就是思路清晰,看着方便,便于理解。
select last_insert_id();
命令可以查询刚刚插入一条数据的id,然后根据id插入如下语句
insert into admininfos set id=3,name=‘张三’,cardid=‘1232323243454645’,tel=‘23535343544’,createtime=sysdate();
除此之外呢,还可以指定时间插入:
insert into admins set uname=‘chuanye’,pwd=‘23434’,nicheng=‘穿越频道管理员’,createtime=‘2020-03-09 12:23:00’;
(3)插入异常
插入和上方相同的cardid或者tel
insert into admininfos set id=1,name=‘程涛’,cardid=‘1232323243454645’,tel=‘23533343544’,createtime=sysdate();
会报如下错误:
ERROR 1062 (23000): Duplicate entry ‘1232323243454645’ for key ‘cardiduniq’
基本语法–数据修改
创建一个新的表
create table books( /书籍/
id bigint not null auto_increment primary key,
cid bigint not null, /栏目id/
title varchar(120) not null , /标题/
introduction varchar(320) /图书介绍/
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(1)按id删除

根据id进行删除:delete from books where id=13;
(2)按条件删除
多条件删除:
delete from books where cid=2 and title like ‘%佳%’;
%表示在佳前后都可以有字
如果想要删除introduction为null的,要用is
delete from books where cid=2 and introduction is null;
(3)关联删除
先把关联的表的外键删除,然后在删除要删除的内容
基本语法–数据查询
数据库用的是cms,具体表是admins,admininfos
(1)条件查询
select * from admins where uname=‘xianxia’ and pwd=‘123123’;
(2)指定字段显示
如果不需要显示这么多:
select id,nicheng,role from admins where uname=‘xianxia’ and pwd=‘123123’;

显示时间(时间格式化):
select date_format(updtime,’%Y-%m-%d’) from admins;
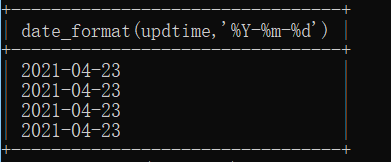
看着标题过长,我们可以用as
select date_format(updtime,’%Y-%m-%d’) as updtime from admins;
(3)连表查询
select a.id,a.nicheng,a.role,ad.name,ad.cardid,ad.tel from admins a,admininfos ad where a.id=ad.id;
admins a,admininfos ad是给这两个表起别名为了以后方便使用
(4)左右连接查询
左连接查询:左边表有的就是显示出来,没有就不显示,以left左边的表为基准有就显示,没有就显示null
select a.id,a.nicheng,a.role,ai.name,ai.tel from admins a left join admininfos ai on a.id=ai.id;

右连接查询:其实就是和左连接相反
select a.id,a.uanme,a.role,ai.name,ai.tel from admininfos ai right join admins a on ai.id=a.id;
(5)统计查询
对表中的价格price求平均值
select avg(price) from books group by cid;
group by是聚合函数,把cid一样的分在一个小组中,然后进行求平均,一个小组一个平均值,当然也可以求最大值等,把avg换成对应的函数就好。比如:count()求和,max()最大值,min()最小值,
事务处理(了解即可)
InnoDB支持事务,MyISAM不支持事务
(1)事务的理论
事务是数据库中一个单独的执行单行(Unit),事务就是由一种数据操纵语言DML语句组成,这一组DML要么全不成功要么全部失败,是一个整体。
(2)事务在实际中的应用
铁路售票系统
以下内容了解即可
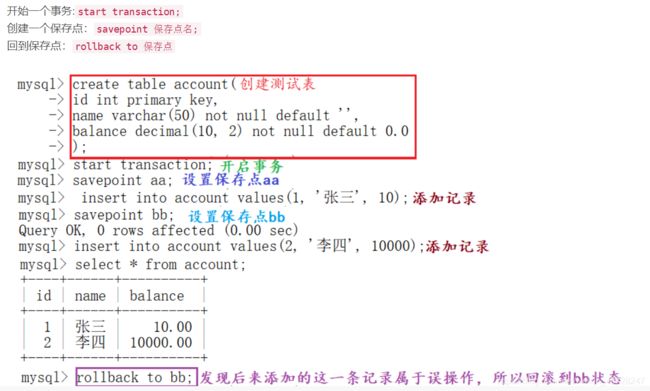
如果一个事务被提交(commit)了,则不可以回滚(rollback)
(3)何处用到事务
涉及到钱和责任还有相对比较重要的用事务
视图
(1)视图的概念和应用场景
视图是一个虚拟表,是从数据库中一个或多个表中导出来的表,其内容由查询定义。同真实表一样,视图包含一系列带有名称的列和行数据。但是,数据库中只存放了视图的定义,而并没有存放视图中的数据。这些数据存放在原来的表中。使用视图查询数据时,数据库系统会从原来的表中取出对应的数据。因此,视图中的数据是依赖于原来的表中的数据的。一旦表中的数据发生改变,显示在视图中的数据也会发生改变。
基于表中数据的只读表,为了简化sql
(2)单表视图
(3)多表视图
(4)视图的创建
create view admininfoview as
select id,name,tel from admininfos;
(5)查看视图
select * from admininfoview;

5.1查看数据库有哪些视图:
show table status where comment =‘view’;
show tables;也可以查看视图,不过查看的内容中包括了数据表
5.1查看视图结构:
desc admininfoview;
(6)修改视图
alter view admininfoview as
select id,name,tel,address from admininfos;
(7)删除视图:
drop view if exists admininfoview;
索引
1.创建索引:
create index titleindex on books(title);
alter table contents add index ctitleindex(ctitle);
2.查看索引:
show index from books;
show keys from contents ;
3.删除索引:
drop index titleindex on books;
alter table contents drop index ctitleindex;
4.唯一键索引:
drop index nameunq on admininfos;
drop index nameunq on admininfos;
5.联合唯一键索引:
create unique index nameunq on admininfos (name,tel);
drop index nameunq on admininfos ;
触发器
触发器:
优点:省事
缺点:增加程序的复杂度,有些业务逻辑在代码中处理,有些业务逻辑用触发器处理,会使后期维护变得困难;
创建触发器:
create trigger triggerName
after/before insert/update/delete on 表名
for each row
begin
sql语句;
end;
DELIMTER是为了防止sql语句后的分号导致提交语句,从而暂停执行。
例子:
新插入的记录对象为new
修改导致原来记录对象为old
增加
DELIMITER //
create trigger addbooknum
after insert on books
for each row
begin
update channels set bnum=bnum+1 where id = new.cid;
end
//
DELIMITER;
减少
DELIMITER //
create trigger deletebooknum
after delete on books
for each row
begin
update channels set bnum=bnum-1 where id = old.cid;
end
//
DELIMITER;
查看触发器:
show triggers;
删除触发器:
drop trigger addbooknum;
drop trigger delbooknum;
存储过程
(1)存储过程概念和用途
定义:一组为了完成特定功能的sql语句集,储存在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给参数(如果该存储过程带有参数)来执行它。
为什么用存储过程?
1.为了快,为了批量执行sql,常用:统计报表,批量执行sql
2.为了共用
(2)创建
delimiter //
create procedure pro_lookbooks()
begin
select * from books; /查询books表/
end
//
delimiter;
注意DELIMITER //,他与存储过程无关。DELIMITER语句将标准分隔符 -分号(;)更改为://。在这种情况下,分隔符从分号(;)更改为双斜杠//。为什么我们必须用分隔符?会因为我们想将存储过程整体传递给服务器,而不是让mysql工具一次解释每个语句。END关键字后,使用分隔符//来解释存储过程的结束。最后一个命令(DELIMITER;)将分隔符更改为分号(;)。
(3)调用
call pro_lookbooks();
(4)查询
显示所有存储过程:
show procedure status;
(5)删除
drop procedure 过程名
drop procedure if exists pro_lookbooks;
drop procedure — 删除存储过程
drop function —删除存储函数
存储过程基本语法–变量
(1)用户变量
声明用户变量,在存储过程之外。用户变量只与连接有关,连接关闭,用户变量消失。
set @a=‘一个新变量’;
查看变量:
select @a;
赋值变量:
select @a:=100;
或者:select ‘hello,world’ into @a;
再或者:select title into @a from books limit 1;
就是把查询books表第一行记录中的title赋值给@a。
(2)局部变量
declare a int;/*必须在存储过程中声明
declare s int default 0;
delimiter //
create procedure pro_hello()
begin
declare s int default 0;
set s=150;
select s;
select @a;
end
//
delimiter;
存储过程基本语法–参数
(1)输入参数
delimiter //
create procedure pro_a(in id int)
begin
select id;
set id=100;
end //
delimiter;
(2)输出参数
delimiter //
create procedure pro_a(out id int)
begin
select id;
set id=100;
end //
delimiter;
(3)输入输出参数
delimiter //
create procedure pro_a(inout id int)
begin
select id;
set id=100;
end //
delimiter;