Resnet 50 残差网络
1.简述
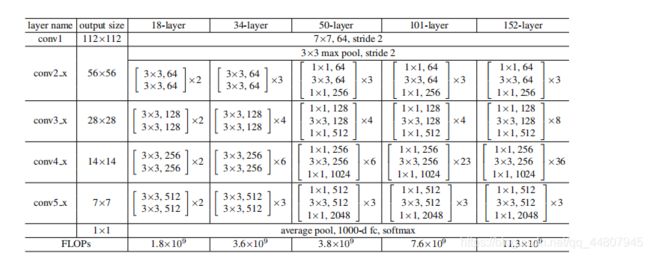
resnet50是何凯明提出,能有效解决深度网络退化问题的一种结构,将输入的多重非线性变化拟合变成了拟合输入与输出的残差,变为恒等映射,50即50层
膜拜巨神:https://github.com/KaimingHe
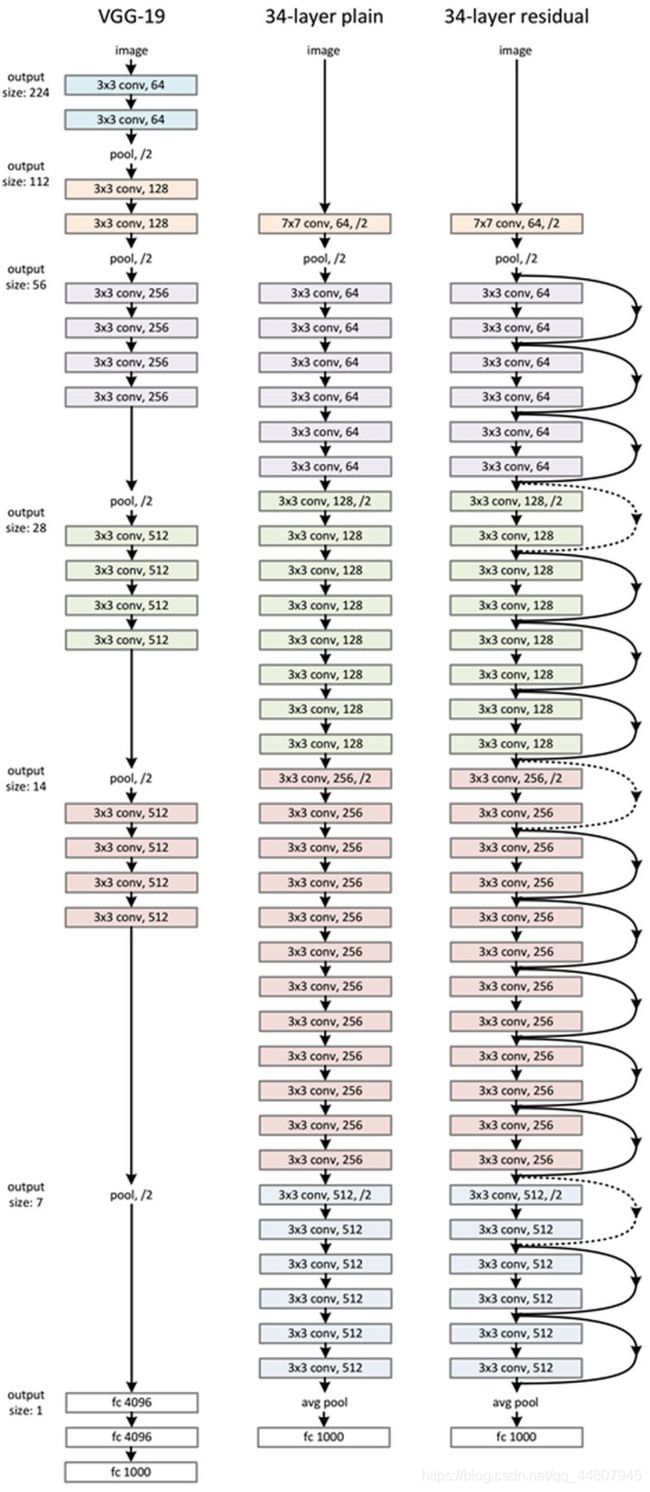
2.基础框架
将block分为两类,block1适用于resnet34及以下,仅有两层结构,需要注意的是,至少应该保证两层,如果只有一层,即
o u t = F ( x , w i ) + x = w i x + b + x out=F(x,w_i)+x=w_ix+b+x out=F(x,wi)+x=wix+b+x仍为线性关系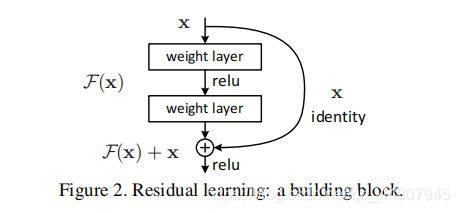
block2结构为三层,加入了一个缩放的操作,具体结构如图
在跨层链接时,往往存在维度,大小不一致的现象,这个时候通常有两种方法,一种是补充零,一种是通过1x1的卷积核进行缩放,套用公式就行
输 出 = [ 输 入 − 核 对 应 边 长 + 2 ∗ p a d d i n g s t r i d e ( 步 长 ) ] + 1 输出=[\frac{输入-核对应边长+2*padding}{stride(步长)}]+1 输出=[stride(步长)输入−核对应边长+2∗padding]+1
通常深度翻倍数和大小缩小倍数一致
3.思路代码
根据框架写了下代码,由于没有试验过,不保证代码完全无bug~~
block2:
class Conv_block(nn.Module):
def __init__(self,in_channels,require_channels):
super().__init__()
if in_channels!=require_channels:
self.downscale=require_channels/in_channels
self.residual=nn.Sequential(
nn.Conv2d(in_channels,require_channels,kernel_size=1,stride=self.downscale),
nn.BatchNorm2d(require_channels),
nn.ReLU(),
nn.Conv2d(require_channels,require_channels,kernel_size=3),
nn.BatchNorm2d(require_channels),
nn.ReLU(),
nn.Conv2d(require_channels,require_channels*4,kernel_size=3),
nn.BatchNorm2d(require_channels*4),
nn.ReLU(),
)
if self.downscale==4:
self.cut=nn.Sequential()
else:
self.cut=nn.Sequential(nn.Conv2d(in_channels,require_channels*4,kernel_size=1,stride=self.downscale))
def forward(self,x):
return nn.ReLU(self.residual(x)+self.cut(x))
resnet50:
class Resnet(nn.Module):
def __init(self,num_classes):
super().__init__()
self.downscale=1
self.con1=nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2),
nn.MaxPool2d(64,64,kernel_size=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1=self._layers(64,64,3)
self.layer2=self._layers(64*4,128,4)
self.layer3=self._layers(128*4,256,6)
self.layer4=self._layers(256*4,512,3)
self.classifier=nn.Sequential(
nn.AdaptiveAvgPool2d(num_classes*4),
nn.AdaptiveAvgPool2d(num_classes),
nn.Softmax()
)
def _layers(self,in_channels,require_channels,num_blocks):
layers=[]
for i in range(num_blocks):
layers.append(Conv_block(in_channels,require_channels))
in_channels=require_channels*4
return nn.Sequential(*layers)
def forward(self,x):
con1=self.con1(x)
l1=self.layer1(con1)
l2=self.layer2(l1)
l3=self.layer3(l2)
l4=self.layer4(l3)
y=self.classifier(l4)
return y
如果希望自己训练的话,也可以写个训练模块试试
def optim(self,type,lr):
param=self.parameters()
if type=='Adam':
self.optimizer=torch.optim.Adam(param,lr)
def define_loss(self,type):
if type=='CrossEntropyLoss':
self.loss=nn.CrossEntropyLoss()
#封装成tensordataset
def train(self,train_loader,epochs,gpu=False,optim,lr,loss):
self.optim(optim,lr)
self.define_loss(loss)
batches=len(train_loader)
for epoch in range(1,epochs+1):
for batch,(data,target) in enumerate(train_loader):
lr_rate=lr*(1-epoch/epochs)*(batch/batches)
for params in self.optimizer.param_groups:
params['lr']=lr_rate
if gpu==True:
data,target=data.cuda(),target.cuda()
out=self.forward(data)
total_loss=self.loss(out,target)
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
#每十个batch,打印一次epoch,batch,loss,lr
if batch%10==0:
print('Epoch:{}/{},batch:{},loss:{},lr:{}'
.format(epoch,epochs,batch,total_loss,lr_rate))