【论文阅读】Hierarchical Multi-modal Contextual Attention Network for Fake News Detection --- 虚假新闻检测,多模态
本博客系本人阅读该论文后根据自己理解所写,非逐句翻译,欲深入了解该论文,请参阅原文。
论文标题:Hierarchical Multi-modal Contextual Attention Network for Fake News Detection;
关键词:社交媒体,虚假新闻检测,多模态学习;
作者:Shengsheng Qian,Jinguang Wang,Jun Hu,Quan Fang,Changsheng Xu;
中国科学院大学,中国科学院模式识别国家重点实验室;合肥工业大学;
发表会议或期刊:SIGIR 2021;
代码地址:GitHub - wangjinguang502/HMCAN
摘要:
最近,因为广泛传播的虚假新闻会误导读者并带来不好的影响,在社交媒体平台上检测虚假新闻成为了一个最关键的问题。目前为止,从人工定义的特征提取方法到深度学习方法,许多致力于解决检测虚假新闻的模型被提出。但是这些模型仍然有不足:(1)没有利用多模态的上下文信息(multi-modal context information),没有提取到高阶的补充信息( high-order complementary information );(2)在学习新闻表示时忽视了文本内容的完整层次化的语义(full hierarchical semantics of textual content )。为了解决上述问题,本文提出了一个层次化的多模态的基于上下文的注意力网络(hierarchical multi-modal contextual attention network, HMCAN)用来做谣言检测。该模型将多模态上下文信息(multi-modal context information)和文本的层次化的语义信息(hierarchical semantics of text )联合建模为一个统一的深度模型。具体而言,本文使用BERT和ResNet来学习文本和图像表示。然后将所得文本和图像表示送入一个多模态的上下文注意力网络以融合模态内(intra-modality)和模态间(inter-modality)的关系。最后,本文设计了一个层次化的编码网络来捕获虚假新闻检测中丰富的语义信息。在三个公开数据集上的实验证实了本文所提出的模型达到了目前最好的结果。
现存方法的问题:
- 早期的谣言检测主要是通过人力完成的,比如依靠领域专家或者机构识别,但是该方式费时费力;
- 后来出现了自动检测谣言的模型,大致分为两类,其一是传统的学习方法。这些方法根据新闻的多媒体内容和用户的社交上下文信息,手动定义一系列谣言的特征。但是谣言也是不断发展的,其特征也在不断变化更加复杂,仅仅使用手动定义的特征很难完全捕获到所有谣言的特征;
- 自动检测的模型第二类是深度学习的方法,使用神经网络来捕获谣言的特征。但是现有的这类方法大多只关注于文本内容而忽视了新闻的多模态特征,也就是图像等信息;
- 现有的多模态谣言检测方法也有缺陷,比如对多模态上下文信息的利用不充分,不能提取新闻中高阶信息增强检测的性能(fully utilize the multi-modal context information and extract high-order complementary information);以及没有提取文本内容的层次化语义特征( explore and capture the hierarchical semantics of text information,具体来说,其他方法用Bert获得文本特征表示时,都是用Bert的最后一层输出作为文本表示,但Bert的中间隐藏层实际上也包含很多有用的信息,这些层一起就是层次化的语义特征)。
本文主要贡献:
- 针对谣言检测问题,提出了层次化的多模态上下文注意力网络(HMCAN)来联合学习多模态上下文信息和文本的层次化语义信息;
- 设计了多模态上下文注意力网络来建模新闻的多模态特征,来自不同模态的信息可以对另一模态做补充。设计了层次化语义编码模块来提取文本的丰富语义特征;
- 在三个公开数据集上经过实验显示出本文模型比其他SOTA方法具有更强的鲁棒性以及在检测谣言方面更高效。
本文方法及模型:
虚假新闻检测问题可以定义为一个二分类问题,给定一个多模态的新闻P包含文本内容和对应的若干图像,模型的目的是输出一个标签Y来判断该新闻是假新闻(Y=1)还是真新闻(Y=0)。
本文模型整体框架如下图2所示,包含以下几个模块:
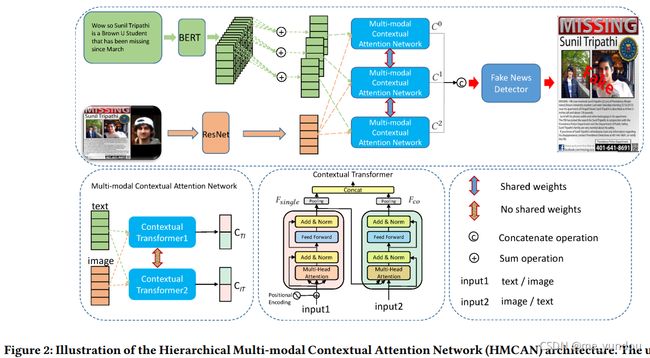
- 文本和图像编码网络:用Bert获取文本的表示向量,用预训练的ResNet50模型来提取图像的特征(预训练表示ResNet50的参数在本文模型训练时固定不变)。给定一个新闻P={W, R}其中W代表新闻的文本内容,R代表视觉内容。首先将W表示为一个包含m个单词的序列,然后经过预训练的Bert得到单词的表示
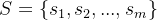 。图像类似,R输入预训练的ResNet50得到n个区域特征
。图像类似,R输入预训练的ResNet50得到n个区域特征 。
。 - 多模态上下文注意力网络:如上图2第二行左边两个图所示,一个多模态上下文注意力网络以文本和图像的表示为输入,经过两个contextual transformer模块(他们俩不共享权重),得到两个向量(图2第二行最左边图片中的
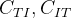 ),令
),令 ,最终得到一个多模态的表示(图2第一行图片中
,最终得到一个多模态的表示(图2第一行图片中 )。具体而言,一个contextual transformer由两个transformer组成(如图2第二行中间一张图片),其中左边的transformer是标准的transformer结构,其QKV均来自输入input1,公式如下。因此该transformer就是学习了input1数据的intra-modality的特征。
)。具体而言,一个contextual transformer由两个transformer组成(如图2第二行中间一张图片),其中左边的transformer是标准的transformer结构,其QKV均来自输入input1,公式如下。因此该transformer就是学习了input1数据的intra-modality的特征。 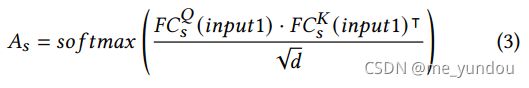
右边的transformer修改了标准transformer结构的输入,其他结构没有改变。其输入的Q来自input2,而KV值则来自input1,是左边transformer的输出结果(公式(5)的结果),公式如下。因此该transformer就是学习了input1和input2两者inter-modality的特征。
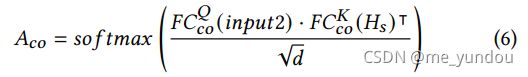
两个transformer的输出分别经过一个pooling之后再拼接在一起,作为contextual transformer的输出结果,也就是左边图片中的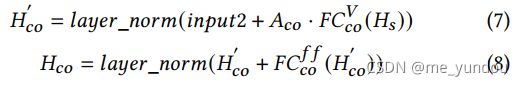 。注意到,一个多模态上下文注意力网络中的一个contextual transformer1的input1和input2分别是text和image内容,而contextual transformer2的input1和input2分别是image和text。
。注意到,一个多模态上下文注意力网络中的一个contextual transformer1的input1和input2分别是text和image内容,而contextual transformer2的input1和input2分别是image和text。 - 层次化编码网络:Bert模型中间层有11个,加上最后一层共有12层表示,为了降低计算量,本文将相邻的4个层的表示求和(4个层为一组),得到3组层次化的文本语义表示。公式如下:其中i代表文本W中的第i个单词,j代表Bert的第j层,s代表每组的向量表示。
将他们分别与图像特征做多模态注意力,然后拼接所得表示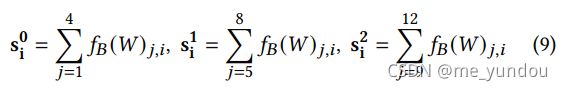 ,就得到了本文模型最终的多模态新闻表示。
,就得到了本文模型最终的多模态新闻表示。 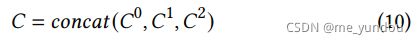
- 虚假新闻检测器: 对新闻的真假进行判断。检测器的输入是新闻的多模态表示C,包含一层全连接层和对应的激活函数,输出该新闻的预测标签,如公式(11):
因此,本文模型的loss是: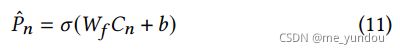
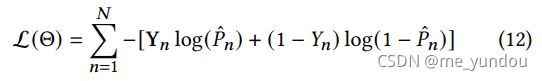
实验:
任务:虚假新闻检测;
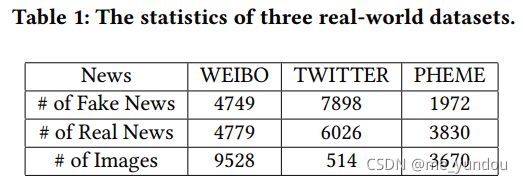
数据集:微博 WEIBO [12], 推特 TWITTER [12, 13](这里推特数据集的初始来源是论文[1]), 和 PHEME [42],各数据集的具体统计信息如下表1所示:
评价指标:使用二分类的准确率Accuracy作为主要评价指标。考虑到数据集不平衡的问题,同时使用二分类中精确率Precision,召回率Recall和F1值作为补充评价指标。
实验设置:Bert和ResNet50使用预训练的模型,也就是不fine-tune。注意:本文对于没有图像的纯文本新闻,会生成对应的虚假图像(dummy images)。其他参数的设置详见论文原文。
对比方法Baselines:包含单模态模型(方法1-4)和多模态模型(方法5-10):
- SVM-TS:使用启发式规则和线性SVM分类器检测虚假新闻;
- CNN:使用学习虚假新闻的特征表示,并且做早期的虚假新闻发现;
- GRU:基于RNNs学习隐藏层表示,同时可以用多层GRU学习一系列新闻组成的变长的时间序列的特征;
- TextGCN:用GCN学习单词和文档的表示,然后将他们一起建模为一个异构图;
- EANN:用一个事件判别器捕获新闻所属事件信息,提取事件无关的新闻特征;
- att-RNN:用注意力机制学习文本、图像、社交信息之间的关系;
- MVAE:用变分自编码器加一个二分类器做检测;
- SpotFake:用预训练的Bert提取文本特征,VGG-19提取图像特征;
- SpotFake+:8的增强版,使用预训练的XLNet提取文本特征;
- SAFE:用相似性关系捕获多模态特征;
实验结果和分析:
所有方法的虚假新闻检测结果值在论文中表2展示,表格较大,这里只展示微博数据集上的实验结果,其他两个数据集的实验结果见原文。
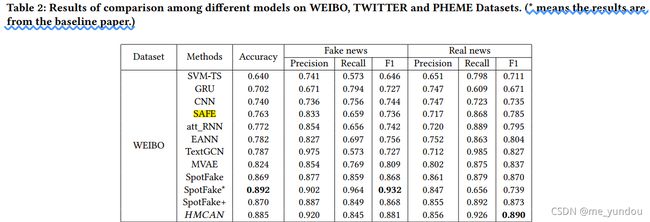
本文从实验结果中得出以下结论:
- 在所有方法中,SVM-TS结果最差,说明人工定义的特征对识别虚假新闻是不够的;
- 基于深度学习的单模态方法(CNN,GRU)结果比SVM-TS好,说明它们提取特征的性能比传统方法好。但是在推特数据集上,CNN只比SVM-TS好,可能是因为CNN对于单词间长距离的语义信息没有捕获到。另外,TextGCN比CNN,GRU结果好,说明图结构对于捕获单词和文档的关系还是有效的;
- 多模态方法att-RNN和MVAE比单模态方法GRU等好,说明除了文本内容之外,额外的图像信息确实对检测虚假新闻是有用的;
- SAFE比CNN好,因为它也用了多个模态的信息。而SpotFake和SpotFake+在推特和微博数据集上比其他baselines方法都好,说明预训练的Bert和XLNet模型确实在提取文本特征方面更好;
- 本文模型HMCAN在推特和PHEME数据集上比其他方法都好。在微博数据集上不如SpotFake论文中的结果,但是在判断真实新闻上,本文的F1结果比它好。而在本文复现的SpotFake模型上的实验结果显示,本文模型的检测结果是比它好的。
HMCAN各部分的分析:如下表3所示,其中HMCAN-V代表去掉了视觉信息只使用文本内容的HMCAN变体;HMCAN-C代表去掉了多模态上下文注意力网络的变体;HMCAN-H代表去掉了层次化语义模块的变体,也就是只使用Bert的最后一层输出表示做后续任务。

从上表3可以看出,去掉任何一个部分都会带来检测结果的降低,说明本文的视觉信息,两种模块都是有用的。(论文原文中对这里分析的很少,个人觉得还有可以挖掘的点,比如可以看出去掉视觉信息之后性能下降很大,去掉多模态部分下降是第二的,说明在这个过程中,图像也就是多模态的信息是非常重要的;而H部分相当于是对文本进行增强,说明文本信息提取已经很多了,所以增加并不多)
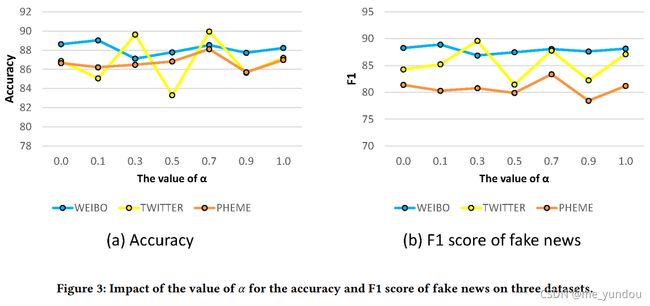
多模态上下文注意力模块中alpha值的影响:
将两个contextual transformer的结果合在一起的方法中的alpha,不同值会对虚假新闻检测的结果有什么影响呢?本文进行了实验,如下图3所示,在Accuracy方面(左图),alpha=0.7时推特和PHEME数据集上结果最好,微博数据集上比0.1时差一点;在F1方面(右图), 微博上0.1最好,推特上0.3最好,PHEME上0.7最好。综上,本文实验中设置alpha=0.7,能在三个数据集上得到较好的结果。
层次化模块中分组数据g不同值的影响:
如下图4所示,当g的值从1升到3时,性能增加,从3之后性能开始下降。到12时会小幅度上升但是仍然低于g=3时,而且当g=12时意味着Bert的输出有12层,计算量太大,因此本文选择了设置g=3.

结论:
未来本文期望探索更有效的提取视觉特征的方式,或者利用额外的知识(knowledge)来辅助识别虚假新闻。
个人理解及问题:
- 本文的虚假新闻检测器只使用了一层全连接层,它的输入特征维度是多少?直接降到2维会不会丢失太多特征?实验设置中只说文本和图像的维度是768,文本的分词数目是多少呢?后面contextual transformer最后的pooling是如何做的(均值还是求和还是拼接?),输出的
 的维度是多少呢?
的维度是多少呢? - 本文对视觉图像提取了region特征,没有使用图像的整体特征,如果加上一个会不会更有效呢?有些虚假新闻的特征能从图像的整体特征上反映出来?
- 本文为什么要特地把SpotFake的论文结果拿出来对比呢?直接使用作者复现的SpotFake结果不就好了吗?而其他的方法又没有展示原始论文结果。
参考文献:
[1] C. Boididou, S. Papadopoulos, D. Dang-Nguyen, G. Boato, and Y. Kompatsiaris. 2016. Verifying multimedia use at mediaeval 2016. In MediaEval 2016 Workshop.
[12] Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In Proceedings of the 25th ACM international conference on Multimedia. ACM, 795–816.
[13] Dhruv Khattar, Jaipal Singh Goud, Manish Gupta, and Vasudeva Varma. 2019. MVAE: Multimodal variational autoencoder for fake news detection. In The World Wide Web Conference. 2915–2921.
[42] Arkaitz Zubiaga, Maria Liakata, and Rob Procter. 2017. Exploiting context for rumour detection in social media. In International Conference on Social Informatics. Springer, 109–123.