机器学习---概述(一)
文章目录
- 1.人工智能、机器学习、深度学习
- 2.机器学习的工作流程
-
-
- 2.1 获取数据集
- 2.2 数据基本处理
- 2.3 特征工程
-
-
- 2.3.1 特征提取
- 2.3.2 特征预处理
- 2.3.3 特征降维
-
- 2.4 机器学习
- 2.5 模型评估
-
- 3.机器学习的算法分类
-
-
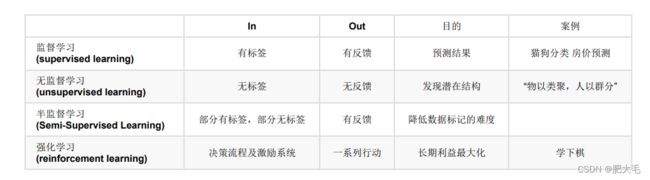
- 3.1 监督学习
-
-
- 3.1.1 回归问题
- 3.1.2 分类问题
-
- 3.2 无监督学习
- 3.3 半监督学习
- 3.4 强化学习
- 3.5 总结
-
1.人工智能、机器学习、深度学习
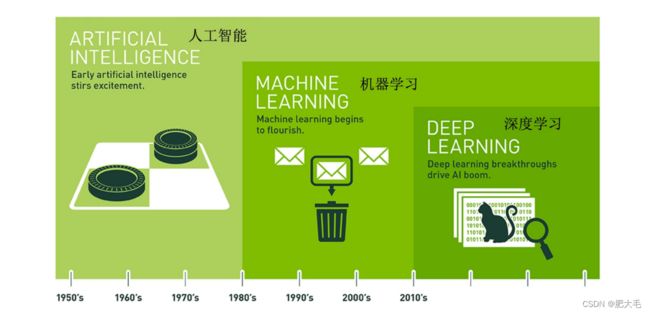
从图中可以看到,人工智能、机器学习、深度学习之间的关系为:机器学习是人工智能的一个实现途径,而深度学习是机器学习的一个方法演变而来的
2.机器学习的工作流程
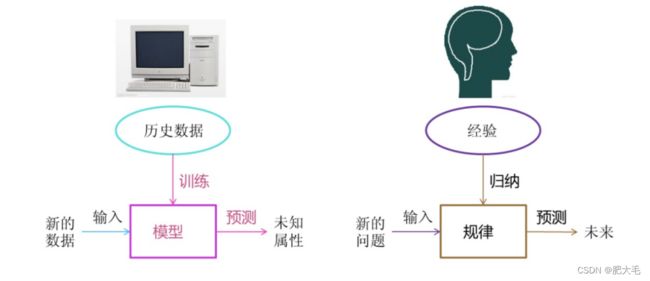
可以将机器学习的工作流程模拟成人思考解决问题的过程,人在遇到一个新的问题的时候,通常会根据以往对解决此类问题的经验来获取到一个规律,根据此规律来预测解决这种新的问题会成功还是失败。
而机器学习的工作流程与之较为相似,当遇到一批新的数据的时候,计算机会自动分析数据来获取模型,根据模型来预测或者评估数据。
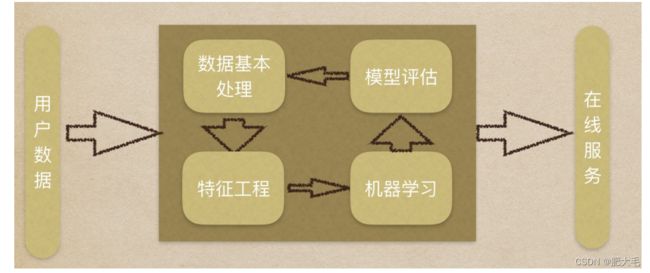
机器学习的工作流程可以分为以下步骤:
1.获取数据
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
如果结果达到要求,上线服务
没有达到要求,就重复上述步骤
2.1 获取数据集
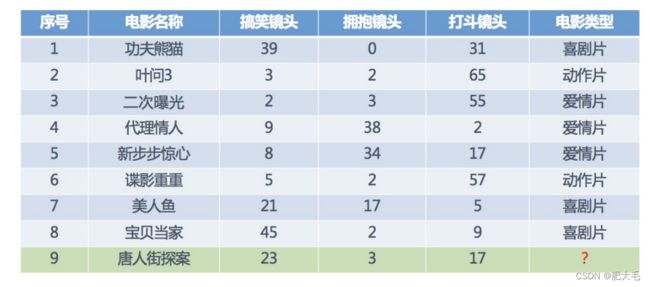
在数据集中,一行数据我们称为一个样本,一列数据我们成为一个特征
,有些数据有目标值(标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值)
数据类型构成
1.特征值+目标值(目标值是连续的或者离散的)
2.只有特征值,没有目标值
数据分割:
机器学习一般会将数据分割为两个部分:
训练数据:用于训练和构建模型
测试数据:在模型检验的时候使用,用于评估模型是否有效
这两部分的划分比例一般为:
训练集70%-80% 测试集20%-30%
2.2 数据基本处理
即对数据进行缺失值、去除异常值等处理
缺失值是指粗糙数据中由于缺少信息而造成的数据的聚类、分组、删失或截断。它指的是现有数据集中某个或某些属性的值是不完全的
2.3 特征工程
特征工程指的是使用专业知识和技巧来处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
特征工程包含:特征提取、特征预处理、特征降维三部分
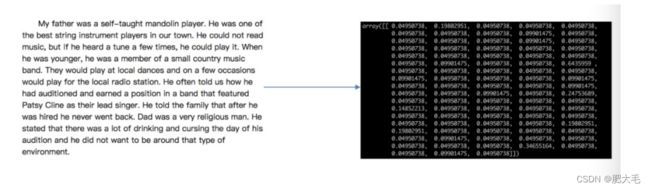
2.3.1 特征提取
即将任意数据转换为可用于机器学习的数字特征
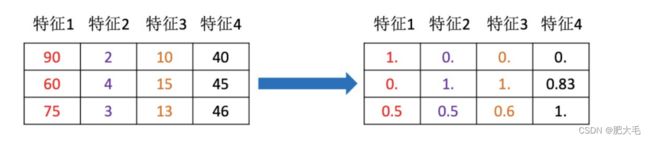
2.3.2 特征预处理
通过一些转换函数将特征数据转换为更加适合机器学习算法的特征数据的过程。
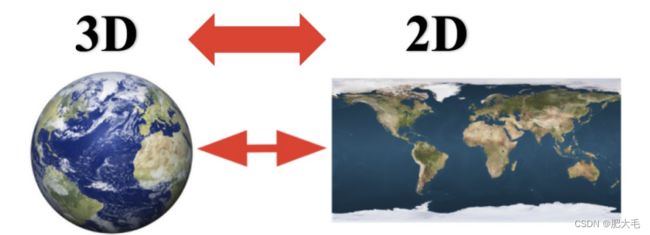
2.3.3 特征降维
指的是在某些条件下,降低随机变量的特征的个数,得到一组“不相关”的主变量的个数。
2.4 机器学习
即选择适合的算法对模型进行训练
2.5 模型评估
对训练好的模型进行评估
3.机器学习的算法分类
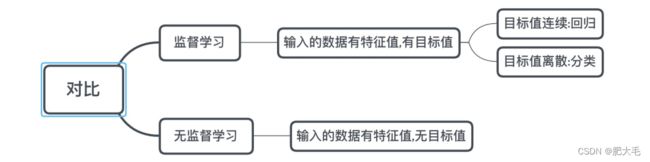
在机器学习中,根据数据集的组成不同,可以将机器学习算法分为:
监督学习
无监督学习
半监督学习
强化学习
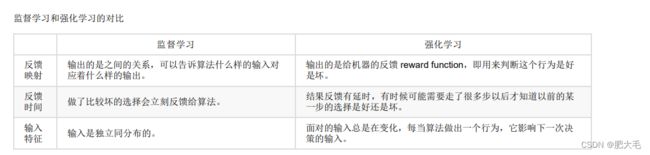
3.1 监督学习
在监督学习中,计算机通过示例学习。它从过去的数据中学习,并将学习的结果应用到当前的数据中,以预测未来的事件。在这种情况下,输入和期望的输出数据都有助于预测未来事件。
监督学习的定义为:
根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。
也就是说,在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。监督学习可以分为回归和分类两种
3.1.1 回归问题
例如:预测房价,根据样本集拟合出一条连续曲线
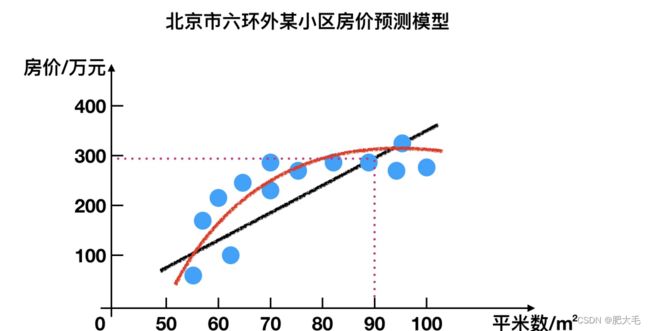
回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
3.1.2 分类问题
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。
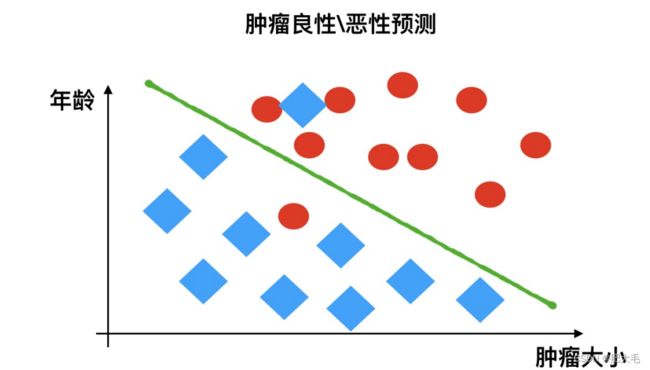
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
和回归最大的区别在于,分类是针对离散型的,输出的结果是有限的。
监督学习的应用:
医疗诊断和预测:监督学习在医疗领域中有着广泛的应用。例如,在医学影像诊断中,通过标记了疾病或异常的图像数据,可以训练模型来帮助医生自动识别和诊断病变。此外,监督学习还可以用于疾病预测,通过医学数据的训练,模型可以预测患者是否有可能患上某种疾病,帮助医生进行早期干预和预防。
3.2 无监督学习
不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。可以这么说,比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(label)的。
输入数据是由输入特征值组成,没有目标值
输入数据没有被标记,也没有确定的结果。样本数据类别未知;
需要根据样本间的相似性对样本集进行类别划分。
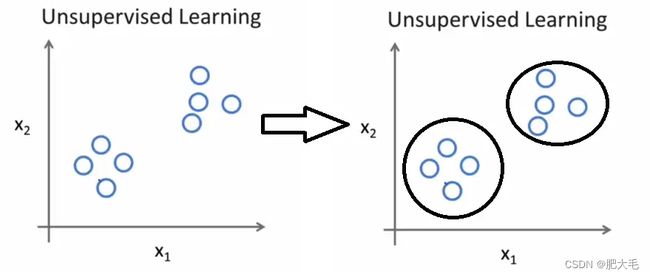
无监督学习的应用:
Google新闻按照内容结构的不同分成财经,娱乐,体育等不同的标签,这就是无监督学习中的聚类。
3.3 半监督学习
半监督学习是一种特殊的机器学习方法,它试图充分利用有标签数据和无标签数据的优势。 在很多情况下,获取有标签数据可能非常昂贵或耗时,但我们可能能够获得大量的无标签数据。半监督学习的目标就是通过这些有限的有标签数据和大量的无标签数据来提高机器学习模型的性能。
这是一个生活中的类比:假设你正在学习认识动物,但你只有少数几本书上有动物的名字和图片。现在,你朋友给了你一大堆没有标签的动物图片。半监督学习的任务就是,通过这些有标签的书籍和无标签的图片,让你更好地辨认未见过的新动物。
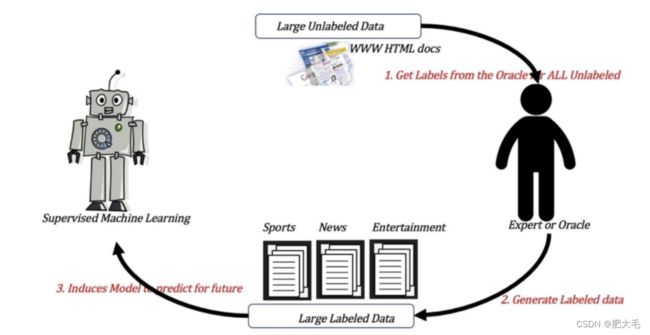
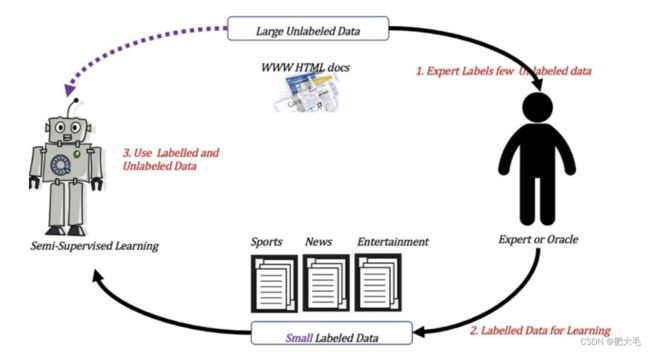
**半监督学习的主要优点是能够在有限的有标签数据上构建更好的模型,从而节省数据标注的成本。**然而,它也可能面临一些挑战,例如无标签数据质量的问题,以及在某些情况下,过度依赖伪标签可能导致错误的预测。因此,在应用半监督学习时,需要谨慎选择合适的方法,并根据具体情况进行调整。
3.4 强化学习
强化学习就像是在教一只聪明的小宠物怎么玩游戏一样。你是这个小宠物的导师,它试图在一个陌生的游戏世界中获得最高的分数。但是,开始时,它对游戏一无所知,所以它必须通过尝试和错误来学习。
在强化学习中,有三个主要的角色:
智能体(Agent):就是我们的小宠物,它在游戏中行动,并试图通过选择不同的动作来达到最好的结果。
环境(Environment):就是游戏的世界,它会根据智能体的动作给予不同的反馈,比如给予奖励(reward)或者惩罚(penalty)。智能体的目标是通过与环境的交互来最大化总的奖励。
动作(Action):就是智能体在游戏中可以选择的不同的举动或策略。
整个过程就像是一个训练过程:智能体在游戏中进行动作,然后根据环境给予的奖励或惩罚来调整自己的策略。通过反复的试错和学习,它会逐渐学会什么样的动作可以得到更多的奖励,从而在游戏中表现得越来越好。
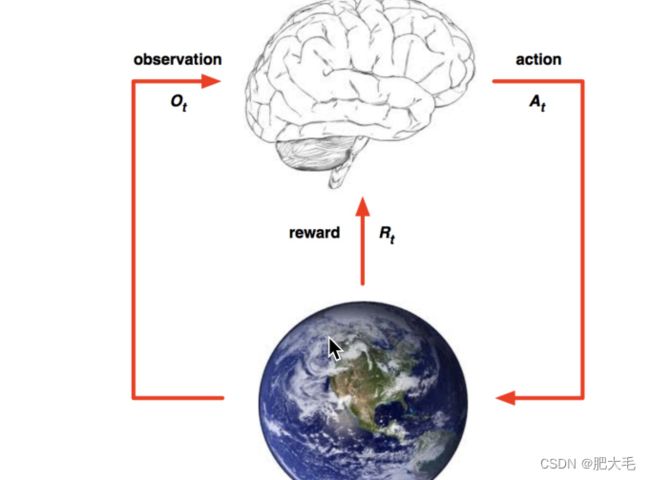
强化学习的一个典型例子就是训练一个机器人玩赛车游戏。机器人开始时可能会碰壁、撞车,但随着时间的推移,它会学会如何转弯、避开障碍物,并逐渐变得越来越擅长在赛道上驾驶。这种学习过程类似于我们学习新技能或游戏一样,通过不断尝试,我们变得越来越熟练。
总结一下,强化学习是一种让智能体通过与环境交互,并根据奖励和惩罚来学习优化策略的机器学习方法。类似于训练一只聪明的小宠物在陌生的游戏世界中变得越来越好。强化学习的目标就是获得最多的累计奖励。
3.5 总结