论文阅读 Distant Vehicle Detection Using Radar and Vision
Distant Vehicle Detection Using Radar and Vision
Abstract
自动驾驶需要精准的探测车辆间的距离,使用CNN的物体检测在例如KITTI等数据集上得到了很好的结果。但是在检测小目标时这些检测效果大幅下降,本文使用了融合雷达数据的方法来解决这样的问题,并且还介绍了一种有效的自动化方法(使用不同焦距的相机)生成数据集。
1. INTRODUCTION
在自动驾驶领域物体检测至关重要,但是在某些情况下,由于车辆之间的接近速度快,因此有必要在相当远的距离上检测物体,这样的车辆在图片中可能只有几个像素点。物体检测领域表现出色的CNN在这样的情况下表现不好。
雷达提供了物体的距离速度信息,但无法提供物体的大小并且有着很多的杂讯(clutter)。因此将两者的结合表现高于单单使用一种设备。
为了展示融合的方法,本文通过使用现有的探测器并结合多个摄像头的检测结果自动标记数据从而得到了自己的数据集。
2. RELATED WORK
略过
3. DATASET CREATION AND AUTOMATIC LABELLING
为了创建数据集,使用两个配置为立体相机对的相机收集数据,第三个配置为长焦距镜头,位于左侧立体相机的旁边。3个相机收集的都是1280x960的RGB图像,频率为30Hz,雷达使用的是:a Delphi ESR 2.5 pulse Doppler cruise control radar
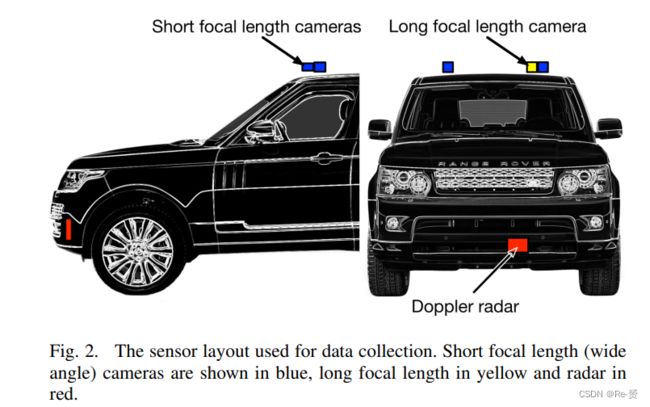
3.1 Object detector
为产生数据集,使用了在KITTI数据集上训练好的YOLO目标检测算法。从单一图像的未修改的目标检测结果是不够准确的,尤其是远距离条件下,为了增加准确度我们把多个摄像头的检测结果进行结合。
3.2 Combining labels using multiple focal lengths
为了产生数据集,使用了两种焦距的摄像头。第一个相机A具有广角镜头(短焦距),相机B有一个更长的焦距并安装时尽可能接近第一个相机,这样他们的光轴是近似对齐的。通过这样一种近距离安装的方法,相机B可以转换到相机A而不需要知道物体的距离。
具体来说,得到相机A和B的内参矩阵(intrinsic matrices),如果两个相机安装在一起,使相机中心可以近似地重合,那么一个相机的图像点[u, v]可以在另一个相机上重绘如下:

两个相机共用一个相机中心会在转移到新图像的点上引起一个误差

由于要求两个相机的视场尽可能地重叠,所以两个相机观察到的是一个联合图像区域,因此有的物体可能被两个摄像机同时检测到,我们使用分辨率更高的B相机的探测结果。在两个摄像机重合的边界处,我们丢弃短焦相机A中与边界框IOU小于某个阈值的探测结果。
3.3 Radar
每个获得的雷达点包含了距离range,方位bearing,径向速度range rate和广度amplitude。为了处理大量的目标,我们将雷达目标投影到相机A中,得到两个额外的图像通道——距离range和距离速率range rate。为了简化学习过程,在进行投影之前从每个目标的距离速率测量中减去了帧间运动ego-motion,为了计算帧间运动使用了传统的 stereo visual odometry系统。
雷达点到图片的投影如下:

通过对range rate通道的缩放使得0值对应于127的像素值
3.4 Sub-sampling
由于连续图像帧高度相关,所以包含所有帧的话收益不高。我们只选择那些雷达和图像时间戳在一个小的时间偏移范围内的帧(我们选择10ms)然后以五倍的倍数进行子采样,从原始雷达频率得到大约1:10的总体子采样。
3.5 Final dataset
标记的结果是一个图像和雷达的数据集,每个图像中有车辆和行人的边界框。我们将数据集分为17553, 2508 和5015作为训练,验证和测试集。
4. DETECTION NETWORK
我们基于SSD目标检测框架进行网络架构,实验了2种融合雷达的策略
1.通过为雷达输入添加额外的分支,并且在第二个图像ResNet块后连接特征
2.通过添加相同的额外分支,但没有最大池化,并使用element-wise addition来融合第一个图像ResNet块的特征
我们实验了一个组合的五通道输入图像,第一种分支结构的配置被证明是最好的,可以各自发展雷达和RGB的特征

我们使用与标准SSD相同的损失函数,在分类输出上使用交叉熵损失,在边界框回归上使用平滑的L1损失。最后使用阈值为0.45的非极大值抑制(NMS)对最终输出进行细化。
5. EXPERIMENTAL SETUP
我们使用ADAM优化器训练所有模型,使用L2权重衰减为0.01,训练50k次迭代其中batch大小为16,使用图像增强来减少过拟合,数据以0.5的概率从左到右翻转,然后以0.5的概率在全图像尺寸的0.6-1.0之间进行裁剪,如果数据被裁剪,则在使用前将其调整为完整的图像大小。我们还随机修改RGB图像的色调和饱和度。
6. EXPERIMENTAL RESULTS
略过
7. CONCLUSIONS AND FURTHER WORK
We have introduced a process for automatically labelling a new dataset by combining detections from multiple cameras. We have also demonstrated how that can be used to train a network which fuses radar scans with camera images to improve detection performance. In addition we have shown that by learning from a combined set of detections we are able to exceed the performance of the original detector.
In future work there are a number of avenues that we intend to explore. First, the image-like radar representation used in this work is very simple and there may be other representations that might be better suited to the sparsityof the radar data. Secondly, there may be benefits to using consecutive frames both to filter noisy labels and to reduce the impact of radar noise. Finally, given that our labels are automatically generated, they will contain some noise. While [24] showed that, given enough examples, deep learning is sufficiently robust to learn an accurate model despite large amounts of label noise, there have been a number of methods proposed for handling such noise (e.g. [25]) that would be worth exploring.