小目标检测的现有方法--来自论文(Towards Large-Scale Small Object Detection: Survey and Benchmarks)
文章目录
-
- REVIEW ON SMALL OBJECT DETECTION
-
- 1.1 Problem Definition
- 1.2 Main Challenges
- 1.3 Review of Small Object Detection Algorithms
-
- 1.3.1 Sample-oriented methods
-
- Data-augmentation strategies
- Optimized label assignment
- 1.3.2 Scale-aware methods
-
- Scale-specific detectors
- Hierarchical feature fusion
- 1.3.3 Attention-based methods
- 1.3.4 Feature-imitation methods
-
- Similarity learning-based methods
- Super-resolution-based frameworks
- 1.3.5 Context-modeling methods
- 1.3.6 Focus-and-detect methods
REVIEW ON SMALL OBJECT DETECTION
1.1 Problem Definition
目标检测的目标是对目标实例进行分类和定位。小目标检测或微小目标检测,顾名思义,主要集中于检测那些尺寸有限的目标。在这个任务中,通常通过area threshold或length threshold来定义术语"tiny"(微小)和"small"(小)。以COCO数据集为例,占据面积小于等于1024像素的目标属于"small"类别
1.2 Main Challenges
Information loss 当前主流的目标检测器通常包括一个主干网络和一个检测头部,其中后者的决策依赖于前者输出的表示。这种模式被证明是有效的,并取得了前所未有的成功。然而,通用的特征提取器通常利用 sub-sampling操作来过滤嘈杂的activation并减少特征图的空间分辨率,从而不可避免地丢失了目标的信息。对于大尺寸或中等尺寸的目标,这种信息丢失可能不会显著影响性能,因为最终的特征仍然保留了足够的信息。然而,对于小目标而言,这是致命的,因为检测头部几乎无法在高度降采样的representations上进行准确的预测,其中小目标的weak signals几乎被抹掉了。
Noisy feature representation Discriminative features对于分类和定位任务至关重要。然而,小目标往往具有低分辨率和质量较差的外观,因此很难从它们 distorted structures中学习具有辨别力的representations。同时,小目标的regional features很容易被背景和其他目标污染,进一步引入噪声到学习的表示中。总之,小目标的特征表示容易受到噪声的影响,从而阻碍了后续的检测任务。
Low tolerance for bounding box perturbation 在大多数目标检测范式中,定位作为主要任务之一,被建模为回归问题。定位分支被设计为输出边界框的偏移量或目标的尺寸,通常采用交并比(IoU)指标来评估准确性。然而,对于小目标的定位比较困难。如图1所示,对于一个小目标,预测边界框的轻微偏差(沿对角线方向的6个像素)会导致IoU显著降低(从100%降至32.5%),而相比之下,对于中等和大尺寸目标,IoU分别为56.6%和71.8%。同时,更大的variance(例如12个像素)进一步加剧了这种情况,小目标的IoU降至极低的8.7%。这意味着与较大目标相比,小目标对于边界框的扰动容忍度较低,这使得回归分支的学习变得更加困难。

Inadequate samples for training 在训练高性能的检测器时,选择正样本和负样本是一个必不可少的步骤。然而,对于小目标而言,这一步骤变得更加困难。具体来说,小目标占据的区域相对较小,并且与先验框(锚点或点)的重叠有限。这对于传统的标签分配策略构成了巨大挑战,这些策略通常基于边界框或中心区域的overlaps来收集 pos/neg样本,在训练过程中导致小目标的正样本分配不足。
1.3 Review of Small Object Detection Algorithms
基于深度学习的通用目标检测方法可以分为两类:两阶段检测和单阶段检测。前者通过一个从粗到精的过程检测目标,而后者在一次检测中完成。两阶段检测方法首先使用设计良好的架构(如Region Proposal Network,RPN)产生高质量的候选框,然后detection heads分别对候选框进行分类和定位。与两阶段算法相比,单阶段方法在特征图上密集铺设锚点,并直接预测分类得分和坐标。由于不需要候选框,单阶段检测器在计算效率上具有优势,但通常在准确性方面稍逊一筹。
除了以上两类,近年来还出现了一些不依赖锚点的方法,它们舍弃了锚点的概念。此外,一些基于query的检测器,将检测任务形式化为一种集合预测任务,显示出了巨大的潜力。
为了解决前面提到的挑战性问题,现有的小目标检测方法通常将deliberate designs的策略引入到当前在通用目标检测中表现良好的强大范式中。接下来,我们将简要介绍这些方法,并在图2中概述所提出的解决方案。
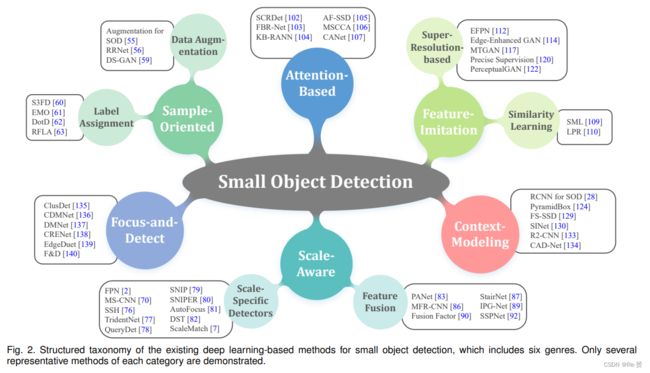
1.3.1 Sample-oriented methods
训练learningbased detector的一个最关键的步骤是采样(通常与 assignment同时存在),这在通用目标检测中取得了显著的进展。然而,对于小目标检测任务,通用的采样策略通常无法提供足够的正样本,从而影响最终的性能。这种困境源于两个方面:limited sizes的目标在当前数据集中只占很小一部分;由于小目标与先验框之间的overlaps有限,当前基于重叠的匹配方案对于采样足够的正锚点或点太rigorous。基于这两个观察结果,一系列的努力已经展开,可以分为两派:通过数据增强增加小目标数量或设计最优的分配策略来使网络学习获得足够的样本。
Data-augmentation strategies
Kisantal等人[55]采用了一种数据增强策略,通过复制一个小目标并将其带有随机变换粘贴到图像中的不同位置 。RrNet [56]引入了一种自适应增强策略,称为AdaResampling,其思想与[55]类似,主要区别在于使用先验分割图来引导合适的位置进行粘贴,同时对粘贴对象进行尺度变换以进一步减少尺度差异 。Zhang等人[57] 和Wang等人[58] 都采用了基于分割和缩放功能的操作来获取更多的小目标训练样本。在对象分割、图像修复和图像融合技术的基础上,DS-GAN [59] 设计了一种新颖的数据增强流程来生成高质量的小目标合成数据。
1.[55] Augmentation for small object detection
2.[56]Rrnet: A hybrid detector for object detection in drone-captured images ICCVW, 2019
3.[57] Dense and small object detection in uav vision based on cascade network ICCVW, 2019
4.[58] Towards efficient detection for small objects via attention-guided detection network and data augmentation
5.[59] A full data augmentation pipeline for small object detection based on generative adversarial networks
Optimized label assignment
遵循这一思路的方法旨在缓解由于基于重叠匹配策略和先验设计导致的sub-optimal采样结果。
通过设计scale compensation anchor matching strategy,S3FD [60]增加了与 tiny faces匹配的锚点,从而提高了召回率。Zhu等人[61]提出了期望最大重叠(EMO)得分,该得分在计算重叠时考虑了锚点的步幅,并为 tiny faces启发了更好的锚点设置。Xu等人[62]使用所提出的DotD(定义为两个边界框中心点之间的标准化欧氏距离)来替代常用的IoU。类似地,RFLA [63]在标签分配中测量每个特征点的高斯感受野与真实值之间的相似性,从而提升了主流检测器在小目标上的性能。
样本对于目标检测尤其是小目标检测非常重要。如果没有足够的正样本,在训练过程中,小目标的区域将无法得到充分优化,从而影响后续的分类和回归任务。无论是基于数据增强的方法还是设计的匹配策略和适当的先验设置,目标都是提供足够的正样本。然而,前者方法往往面临着性能改进不一致和迁移能力差的问题。同时,当前优化的标签分配方案容易引入低质量的样本,并且在尺寸极小的目标上仍然面临困难。
- [60]S3fd:Single shot scale-invariant face detector ICCV, 2017
- [61]Seeing small faces from robust anchor’s perspective CVPR, 2018
- [62]Dot distance for tiny object detection in aerial images CVPRW, 2021
- [63]Rfla: Gaussian receptive based label assignment for tiny object detection ECCV, 2022
1.3.2 Scale-aware methods
图像中的目标尺度通常是变化的,在交通场景和遥感图像中这种变化可能尤其严重,导致单个检测器在不同尺度的目标上面临不同的检测困难。之前的方法通常采用图像金字塔和滑动窗口方案来处理尺度变化问题。然而,基于手工设计特征的方法受到表示能力有限的限制,在小目标上表现非常差。早期基于深度模型的检测方法在检测小目标方面仍然困难,因为仅使用高级特征进行识别。为了解决这种paradigm的缺点,并受到其他视觉领域中跨多级别推理的成功启发,后续的工作主要沿着两个方向进行。一种是通过设计多分支架构或量身定制的训练策略来构建特定尺度的检测器,另一种是通过融合hierarchical features来获得强大的小目标representations。
Scale-specific detectors
这一方向的基本思路很简单:不同深度或层次的特征主要用于检测相应尺度的目标。例如,Yang等人利用尺度相关的池化(Scale-Dependent Pooling,SDP)选择适当的特征层用于小目标的池化操作。MS-CNN [70]在不同的中间层生成目标候选框,每个层次都专注于特定尺度范围内的目标,从而为小目标提供了最优的感受野。DSFD [71]通过特征增强模块连接两个检测器,用于检测不同尺度的人脸。YOLOv3 [45]通过添加并行分支进行多尺度预测,其中高分辨率特征负责小目标。Lin等人[2]提出了特征金字塔网络(Feature Pyramid Network,FPN),将不同尺度的实例分配给不同的金字塔层级,根据它们的尺寸。同时,不同深度特征之间的交互进一步保证了多尺度目标的适当表示。这个简单而有效的设计已经成为特征提取器中的一个重要组件,并启发了一系列显著的变体,如NAS-FPN [72]、Bi-FPN [73]和RecursiveFPN [74]。此外,将尺度特定的检测器组合用于多尺度检测也得到了广泛探索。例如,Li等人[75]构建了并行子网络,其中小尺寸子网络专门用于检测小行人。SSH [76]将尺度变体的人脸检测器组合起来,每个检测器专门针对特定尺度范围进行训练,以构建强大的多尺度检测器来处理尺度极大变化的人脸。TridentNet [77]构建了一个并行的多分支架构,每个分支具有不同尺度目标的最优感受野。QueryDet [78]设计了级联查询策略,避免对低层次特征进行冗余计算,从而在高分辨率特征图上高效地检测小目标。
- [70]“A unified multi-scale deep convolutional neural network for fast object detection ECCV, 2016
- [71]Dsfd: Dual shot face detector CVPR, 2019
- [2]Feature pyramid networks for object detection CVPR, 2017
- [75]Scale-aware fast r-cnn for pedestrian detection
- [76]Ssh:Single stage headless face detector ICCV, 2017
- [77]Scale-aware trident networks for object detection ICCV, 2019
- [78] Querydet: Cascaded sparse query for accelerating high-resolution small object detection CVPR, 2022
还有一些方法致力于开发特定的 data preparation strategies,以在训练过程中让检测器专注于特定尺度的实例。在通用的多尺度训练方案之上,Singh等人[79]设计了一种新的训练范式,称为尺度归一化图像金字塔(Scale Normalization for Image Pyramids,SNIP),它只将分辨率在所需尺度范围内的实例用于训练,其余的实例被简单地忽略。通过这种设置,可以在最合理的尺度上处理小实例,同时不影响中大尺度目标的检测性能。后来,Sniper [80]建议从多尺度图像金字塔中采样图像块进行高效训练。Najibi等人[81]提出了一种用于检测小目标的粗到细的流水线。考虑到之前的方法[2],[66],[77]中对数据准备和模型优化的协作研究不足,Chen等人[82]设计了一种反馈驱动的训练范式,动态地指导数据准备,并进一步平衡小目标的训练损失。Yu等人[7]引入了一种基于统计的匹配策略,用于尺度一致性检测。
- [79]An analysis of scale invariance in object detection-snip CVPR, 2018
- [80]Sniper: Efficient multi-scale training
- [81]Autofocus: Efficient multiscale inference
- [82]Dynamic scale training for object detection
- [7]Scale match for tiny person detection WACV, 2020,
Hierarchical feature fusion
深度CNN架构在不同空间分辨率上产生分层特征图,其中低层特征描述更细节和更多定位线索,而高层特征捕获更丰富的语义信息[13],[43],[77],[83],[84],[85]。在SOD任务中,深度特征可能难以应对小目标的disappeared response,而早期阶段的特征图容易受到光照、形变和目标姿态等变化的影响,使得分类任务更具挑战性。为了克服这个困境,许多方法采用特征融合的方式,将不同深度的特征进行整合,以获得更好的小目标表示。受FPN [2]中简单而有效的交互设计启发,PANet [83]使用双向路径丰富了特征层次结构,用准确的定位信号增强深层特征。Zhang等人[86]将ROI的池化特征在多个深度上与全局特征进行串联,以获得更稳健和判别性的交通小目标表示。Woo等人[87]提出了StairNet,其中使用反卷积扩大特征图,这种基于学习的上采样函数可以获得比传统的基于卷积核的上采样更精细的特征,并且允许不同金字塔层级的信息更高效地传播。Liu等人[89]引入了IPG-Net,使用图像金字塔[66]获得的一组不同分辨率的图像输入到设计的IPG变换模块,提取浅层特征来补充空间信息和细节。Gong等人[90]设计了一种基于统计的融合因子来控制相邻层的信息流。值得注意的是,在基于FPN的方法中遇到的梯度不一致问题会降低低层特征的表示能力[91],SSPNet [92]强调不同层的特定尺度特征,并利用FPN中相邻层的关系来实现适当的特征共享。
- [83]Path aggregation network for instance segmentation CVPR, 2018
- [86]Mfrcnn: Incorporating multi-scale features and global information for traffic object detection
- [87]Stairnet: Top-down semantic aggregation for accurate one shot detection
- [89]Ipg-net: Image pyramid guidance network for small object detection
- [92]Sspnet:Scale selection pyramid network for tiny person detection from uav images
特定尺度的架构致力于以最合理的尺度处理小目标,而融合型方法旨在弥合较低金字塔级别和较高金字塔级别之间的空间和语义差距,二者都努力实现小尺度目标和中大尺度目标的一致性性能提升。然而,前者以启发式方式将不同大小的目标映射到相应的尺度级别,这可能会使检测器产生困惑,因为单个层次的信息不足以进行准确的预测。另一方面,在网络内部的信息流并不总是有利于小目标的表示。我们的目标是不仅赋予低层特征更多的语义信息,而且还要防止深层信号对小目标的原始响应产生压倒性影响。然而,你不能两全其美,因此这个困境需要谨慎处理。
1.3.3 Attention-based methods
人类可以通过对整个场景进行一系列的局部瞥视,快速聚焦和区分对象,同时忽略那些不必要的部分。这种惊人的能力在我们的感知系统中通常被称为visual attention mechanism,它在我们的视觉系统中起着至关重要的作用[94]。毫不奇怪,这个强大的机制在之前的文献中得到了广泛的研究,并在许多视觉领域显示出了巨大的潜力。通过为特征图的不同部分分配不同的权重,注意模型确实强调了有价值的区域,同时抑制了那些不必要的区域。自然地,人们可以使用这种优越的方案来突出显示倾向于在图像中被背景和噪声模式主导的小目标。
SCRDet [102]设计了一个面向对象的检测器,其中像素注意力和通道注意力在监督方式下进行训练,以突出显示小目标区域并消除噪声干扰。FBR-Net [103]在提出的基于层级的注意力的基础上扩展了无锚点检测器FCOS [4],平衡了不同金字塔层级上的特征,并增强了在复杂情况下对小目标的学习。受到人类认知的启示,KB-RANN [104]利用长期和短期的注意力神经网络来关注图像特征的特定部分,增强小目标的检测。Lu等人[105]设计了一个双通道模块来突出显示小目标的关键特征并抑制非目标信息。通过用提出的增强通道注意力(ECA)块替换复杂的卷积组件,MSCCA [106]构建了一个轻量级的检测器,具有平衡的通道特征和较少的参数。Li等人[107]设计了一个跨层注意力模块来获得更强的小目标响应。
- [102]Scrdet: Towards more robust detection for small, cluttered and rotated objects ICCV, 2019
- [103]An anchor-free method based on feature balancing and refinement network for multiscale ship detection in sar images
- [104]Feature selective small object detection via knowledge-based recurrent attentive neural network
- [105]Attention and feature fusion ssd for remote sensing object detection
- [106]Lightweight oriented object detection using multiscale context and enhanced channel attention in remote sensing images
- [107]Crosslayer attention network for small object detection in remote sensing imagery
借鉴人类的认知机制,视觉注意力在现代视觉领域中扮演着重要角色,通过筛选关键部分并抑制噪声部分,实现高质量的特征表示。注意力系列方法因其灵活的嵌入设计而备受推崇,并且可以插入几乎所有的小目标检测架构中。然而,性能改进是以大量计算开销为代价的,因为涉及到相关操作,并且当前的注意力范式缺乏监督信号和显式优化。
1.3.4 Feature-imitation methods
SOD(小目标检测)面临的最大挑战之一是由于小目标信息有限而导致的低质量表示。对于那些尺寸极小的对象,这种情况可能会更加严重。与此同时,较大的对象通常具有清晰的视觉结构和更好的区分度。因此,缓解这种低质量问题的一种直接方法是通过模仿较大目标的区域特征来丰富小目标的特征。为此,已经提出了几种试探性方法,可以分为两种类型:similarity learning进行特征模仿和super-resolution-based的框架。
Similarity learning-based methods
这一方法的原理很简单:在通用目标检测器的训练中添加额外的相似性约束,从而弥合小目标和大目标之间的表示差距。Wu等人[109]提出了“自我模仿学习”方法,其中强制小尺寸行人的表示接近大尺寸行人的局部平均RoI特征。受人类视觉理解机制的记忆过程的启发,Kim等人[110]设计了一个大尺度嵌入学习框架,其中使用大尺度行人召回记忆(LPR Memory),并通过召回损失对整体架构进行优化,该损失旨在指导小尺度和大尺度行人特征的相似性。
- [109]Self-mimic learning for small-scale pedestrian detection
- [103]Robust small-scale pedestrian detection with cued recall via memory learning ICCV, 2021
Super-resolution-based frameworks
这一路线的方法旨在恢复小目标的 distorted structures,而不仅仅是放大它们的模糊外观。在使用反卷积和子像素卷积[111]的帮助下,Zhou等人[84]和Deng等人[112]获得了专门用于小目标检测的高分辨率特征。在自监督学习范式的指导下,Pan等人[113]提出了一个引导特征上采样模块,以学习带有细节信息的放大特征表示。生成对抗网络(GAN)[114]具有通过生成器和鉴别器之间的两个玩家最小最大游戏来生成视觉真实数据的显着能力,这自然地启发研究人员探索这个强大的范例来生成小目标的高质量表示。Rabbi等人[115]和Bashir等人[116]都使用GAN来对低分辨率的遥感图像进行超分辨率处理,其中前者在重构过程中筛选边缘细节,以避免高频信息丢失,而后者则将循环GAN和残差特征聚合结合在一起,以捕捉复杂的特征。考虑到直接操作整个图像在特征提取阶段会导致不可忽视的计算成本[112],MTGAN [117]使用生成器网络对RoIs的块进行超分辨率处理。Bai等人[118]将这种范例扩展到人脸检测任务,而Na等人[119]则将超分辨率方法应用于小的候选区域以获得更好的性能。尽管超分辨率目标块可以部分重建小目标的模糊外观,但这种方案忽略了在网络预测中起重要作用的上下文线索[120],[121]。为了解决这个问题,Li等人[122]设计了PerceptualGAN来挖掘和利用小尺度目标和大尺度目标之间的内在关联,其中生成器学习将小目标的弱表示映射到欺骗鉴别器的超分辨率表示。为了进一步推进,Noh等人[120]在超分辨率过程中引入了直接监督。
- [111]Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network CVPR, 2016
- [112]Extended feature pyramid network for small object detection
- [113]Self-supervised feature augmentation for large image object detection
- [114]Generative adversarial nets
- [115]Small-object detection in remote sensing images with end-toend edge-enhanced gan and object detector network
- [116]Small object detection in remote sensing images with residual feature aggregation-based superresolution and object detector network
- [117]Sod-mtgan: Small object detection via multi-task generative adversarial network
- [119]Object detection by a super-resolution method and a convolutional neural networks
- [120]Better to follow, follow to be better: Towards precise supervision of feature superresolution for small object detection
- [122]Perceptual generative adversarial networks for small object detection
通过在现有的检测器中添加额外的相似性损失或超分辨率架构,特征模仿方法使模型能够挖掘小尺度目标和大尺度目标之间的内在关联,从而增强小目标的语义表示。然而,无论是相似性学习方法还是超分辨率方法都必须避免塌陷问题并保持特征的多样性。此外,基于GAN的方法倾向于产生虚假的纹理和伪影,对检测产生负面影响。更糟糕的是,超分辨率架构的存在使得端到端的优化变得复杂。
1.3.5 Context-modeling methods
我们人类可以有效地利用环境与对象之间的关系或对象之间的关联来促进对对象和场景的识别。捕捉语义或空间关联的先验知识被称为上下文,它传递了超越对象区域的证据或线索。上下文信息不仅在人类的视觉系统中至关重要,而且在场景理解任务中也是如此,例如对象识别,语义分割和实例分割等。有趣的是,信息丰富的上下文有时可以提供比对象本身更多的决策支持,特别是在识别视觉质量较差的对象时。
为此,一些方法利用上下文线索来提升对小目标的检测。
Chen等人[28]使用包围候选区域的上下文区域的表示进行后续识别。Hu等人[128]研究了如何有效地编码目标范围之外的区域,并以尺度不变的方式建模局部上下文信息来检测微小的人脸。PyramidBox [124]充分利用上下文线索,以找到与背景难以区分的小而模糊的人脸。同样地,图像中的对象之间的内在关联也可以被视为上下文。FS-SSD [129]利用隐含的空间上下文信息,即类内和类间实例之间的距离,来重新检测置信度较低的对象。
假设原始的RoI池化操作会破坏小对象的结构,SINet [130]引入了一个上下文感知的RoI池化层来保持上下文信息。IONet [131]通过两个四方向IRNN结构[132]计算全局上下文特征,以更好地检测小而且严重遮挡的对象。R2-CNN [133]采用全局注意块来抑制误报并高效地检测大规模遥感图像中的小对象。Zhang等人[134]捕捉了对象与全局场景(全局上下文)之间以及对象与其相邻实例(局部上下文)之间的关联,以提高小对象的性能。
- [28]R-cnn for small object detection
- [128]Finding tiny faces CVPR, 2017
- [124]Pyramidbox: A contextassisted single shot face detector ECCV, 2018
- [129]Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis
- [130]Sinet: A scale-insensitive convolutional neural network for fast vehicle detection
- [133]R2-cnn: Fast tiny object detection in large-scale remote sensing images
- [134]Cad-net: A context-aware detection network for objects in remote sensing imagery
从信息论的角度来看,考虑更多类型的特征,可能会得到更高的检测准确性。受到这种共识的启发,上下文预处理已被广泛研究,以生成更具辨别力的特征,特别是对于缺乏线索的小目标,从而实现精确识别。然而,无论是整体上下文建模还是局部上下文预处理,都困惑于应该将哪些区域编码为上下文。换句话说,当前的上下文建模机制以一种启发式和经验的方式确定上下文区域,无法保证构建的表示对于检测来说足够可解释。
1.3.6 Focus-and-detect methods
在高分辨率图像中,小目标往往分布不均匀且稀疏[135],通常的分割和检测策略会在那些空白区域上消耗大量计算资源,导致推理过程的低效率。我们是否可以过滤掉那些没有目标的区域,从而减少无用的操作以提高检测性能?答案是肯定的!在这个领域的努力打破了处理高分辨率图像的通用流程。它们首先提取包含目标的区域,然后在这些区域上进行检测。
Yang等人[135]提出了一种聚类检测网络(ClusDet),充分利用目标之间的语义和空间信息来生成聚类片段,然后进行检测。在这一范例的引导下,Duan等人[136]和Li等人[137]都利用像素级监督进行密度估计,得到更准确的密度图,很好地描述了目标的分布。CRENet [138]设计了一个聚类算法来自适应地搜索聚类区域。使用平铺技术,Wang等人[139]开发了EdgeDuet来增强边缘设备上的小目标检测。F&S [140]引入了一个Focus&Detect框架,其中Focusing Network检测候选区域,然后将其裁剪和调整大小到更高的分辨率,实现了对小目标的准确检测。考虑到固定大小输入处理流程通常会导致对小目标的漏检,[141]采用平铺方法实时检测高分辨率航空图像中的行人和车辆。
- [135]Clustered object detection in aerial images ICCV, 2019
- [136]Coarse-grained density map guided object detection in aerial images
- [137]Density map guided object detection in aerial images
- [138]Object detection using clustering algorithm adaptive searching regions in aerial images
- [139]Edgeduet: Tiling small object detection for edge assisted autonomous mobile vision
- [140]Focus-and-detect: A small object detection framework for aerial images
- [141]The power of tiling for small object detection
与通用滑动窗口机制相比,聚焦检测方法赋予了自适应裁剪和灵活的缩放操作,即可以在更高的分辨率上处理较小的目标,同时可以在相对较低的分辨率上检测较大的目标,这在推理时显著节省了内存占用,并减少了背景干扰。按照这一路线的方法必须回答一个关键问题:在哪里聚焦?目前的方法要么依赖于手动添加额外注释,要么依赖于像分割网络或高斯混合模型这样的辅助架构,然而前者需要费时的标注,而后者会增加端到端优化的复杂性。