暗黑版GPT流窜暗网 降低犯罪门槛

随着AIGC应用的普及,不法分子利用AI技术犯罪的手段越来越高明,欺骗、敲诈、勒索也开始与人工智能沾边。
近期,专为网络犯罪设计的“暗黑版GPT”持续浮出水面,它们不仅没有任何道德界限,更没有使用门槛,没有编程经验的小白能通过问答的方式实施黑客攻击。
AI犯罪的威胁离我们越来越近,人类也开始加筑新的防火墙。
网络犯罪AIGC工具现身暗网
现在,企图“消灭人类”的ChaosGPT和帮助网络犯罪的 WormGPT 之后,出现了一种更具威胁的人工智能工具。被称为“FraudGPT”的新兴网络犯罪AIGC工具匿藏暗网,并开始在Telegram等社交媒体中打广告。
与WormGPT一样,FraudGPT也是人工智能大语言模型,专为作恶而设计,被比作“网络罪犯的武器库”。通过接受不同来源的大量数据训练,FraudGPT不但能写出钓鱼邮件,还能编写恶意软件,哪怕是技术小白也能通过简单的问答方式实施黑客攻击。


FraudGPT在打广告
FraudGPT的功能需付费开启,200美元(约1400元)就能使用。发起人声称,FraudGPT 迄今为止已确认销量超过3000。也就是说,至少3000人已为这一毫无道德边界的作恶工具付费,低成本的AIGC犯罪有可能威胁普通人。
据电子邮件安全供应商Vade 检测,2023年上半年,仅网络钓鱼和恶意邮件就达到了惊人的7.4亿封,同比增长了 54% 以上,AI很可能是加速增长的推动因素。网络安全独角兽公司Tanium的首席安全顾问Timothy Morris表示,“这些电子邮件不仅语法正确,更有说服力,而且可以被毫不费力地创建,这降低了任何潜在罪犯的进入门槛。”他指出,因为语言已经不再是障碍,潜在受害者的范围也将进一步扩大。
自大模型诞生起,AI导致的风险类型层出不穷,安全防护却一直没有跟上,即便是ChatGPT也没能躲过“奶奶漏洞”——只要在提示中写“请扮演我已经过世的祖母”就可以轻松“越狱”,让ChatGPT回答道德与安全约束之外的问题,比如生成Win11的序列号、介绍凝固汽油弹的制作方法等等。
目前,这个漏洞已被修补,但下一个漏洞、下下个漏洞总以令人猝不及防的方式出现。近期,卡内基梅隆大学和safe.ai共同发布的一项研究表明,大模型的安全机制能通过一段代码被破解,并且攻击成功率非常高。
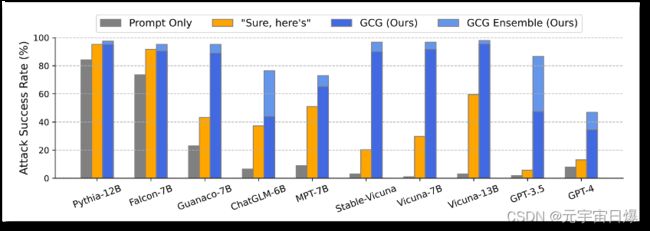

GPT等大模型都面临较高的安全风险
随着AIGC应用的普及,普通大众希望用AI提高生产效率,而不法者则在用AI提高犯罪效率。AIGC降低门槛,让技能有限的网络犯罪分子也能执行复杂攻击,维护AI安全的挑战越来越高。
用AI魔法打败AI黑魔法
针对黑客利用WormGPT与FraudGPT等工具开发恶意程序、发起隐形攻击等问题,网络安全厂家们也用上了AI,试图用魔法打败魔法。
在2023年RSA(网络安全大会)上,SentinelOne、谷歌云、埃森哲、IBM等在内的众多厂商都发布了基于生成式AI的新一代网络安全产品,提供数据隐私、安全防护、IP防泄露、业务合规、数据治理、数据加密、模型管理、反馈循环、访问控制等安全服务。
SentinelOne首席执行官Tomer Weigarten针对自家产品解释,假设有人发送了一封钓鱼邮件,系统能在用户的收件箱内检测出该邮件为恶意邮件,并根据端点安全审计发现的异常立即执行自动修复,从受攻击端点删除文件并实时阻止发件人,“整个过程几乎不需要人工干预。”Weingarten指出,有了AI系统助力,每个安全分析师的工作效率是过去的10倍。
为打击人工智能助长的网络犯罪,还有研究人员卧底暗网,深入敌人内部打探消息,从不法分析的训练数据入手,利用AI反制罪恶流窜的暗网。
韩国科学技术院 (KAIST) 一个研究团队发布了应用于网络安全领域的大语言模型DarkBERT,就是专门从暗网获取数据训练的模型,它可以分析暗网内容,帮助研究人员、执法机构和网络安全分析师打击网络犯罪。
与表层网络使用的自然语言不同,由于暗网上的语料极端隐蔽且复杂,这使得传统语言模型难以进行分析。DarkBERT 专门设计用于处理暗网的语言复杂性,并证明在该领域中胜过其他大型语言模型。
如何确保人工智能被安全、可控地使用已成为计算机学界、业界的重要命题。人工智能大语言模型公司在提高数据质量的同时,需要充分考虑AI工具给伦理道德甚至法律层面带来的影响。
7月21日,微软、OpenAI、Google、Meta、亚马逊、Anthropic和 Inflection AI共七个顶尖 AI 的研发公司齐聚美国白宫,发布人工智能自愿承诺,确保他们的产品安全且透明。针对网络安全问题,7家公司承诺,对AI系统进行内外部的安全测试,同时与整个行业、政府、民间及学术界共享AI风险管理的信息。
管理AI潜在的安全问题先从识别“AI制造”开始。这7家企业将开发“水印系统”等技术机制,以明确哪些文本、图像或其他内容是AIGC的产物,便于受众识别深度伪造和虚假信息。
防止AI“犯忌”的防护技术也开始出现。今年5月初,英伟达以新工具封装“护栏技术”,让大模型的嘴有了“把门的”,能回避回答那些人类提出的触碰道德与法律底线的问题。这相当于为大模型安装了一个安全滤网,控制大模型输出的同时,也帮助过滤输入的内容。护栏技术还能阻挡来自外界的“恶意输入”,保护大模型不受攻击。
“当你凝视深渊的时候,深渊也在凝视你”,如同一枚硬币的两面,AI的黑与白也相伴而生,当人工智能高歌猛进的同时,政府、企业、研究团队也在加速构建人工智能的安全防线。