目标检测与跟踪 (3)- TensorRT&YOLO V8性能优化与部署测试
系列文章目录
目标检测与跟踪 (1)- 机器人视觉与YOLO V8_Techblog of HaoWANG的博客-CSDN博客
目标检测与跟踪 (2)- YOLO V8配置与测试_Techblog of HaoWANG的博客-CSDN博客
目录
系列文章目录
前言
YOLO v8
TensorRT
一、TensorRT
1.1 原理
1.2 架构
1.3 功能
1.4 性能
1.5 GPU并行计算
二、安装&配置
1.下载
2.安装
3. 测试导出YOLO V8
4. 部署测试
前言
YOLO v8
YOLOv8 算法的核心特性和改动可以归结为如下:
1. 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
2. Backbone:
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。
YOLO (You Only Look Once) is a real-time object detection system that is widely used in various applications such as self-driving cars, surveillance systems, and facial recognition software. YOLO V8 is the latest version of YOLO, released in 2022.
Here are some key features of YOLO V8:
- Improved accuracy: YOLO V8 has improved object detection accuracy compared to its predecessors, especially for objects with complex shapes and sizes.
- Real-time performance: YOLO V8 is designed for real-time object detection and can process images and videos at high frame rates.
- Multi-scale features: YOLO V8 uses multi-scale features to detect objects of different sizes and shapes.
- Improved bounding box regression: YOLO V8 has improved bounding box regression, which helps to more accurately detect the location and size of objects.
- New algorithms: YOLO V8 includes several new algorithms, such as spatial pyramid pooling and a new loss function, that improve object detection accuracy and speed.
- Support for multiple platforms: YOLO V8 can be run on a variety of platforms, including Windows, Linux, and Android.
If you're interested in using YOLO V8 for a specific project, you can find more information and resources on the YOLO website, including documentation, tutorials, and sample code.
TensorRT
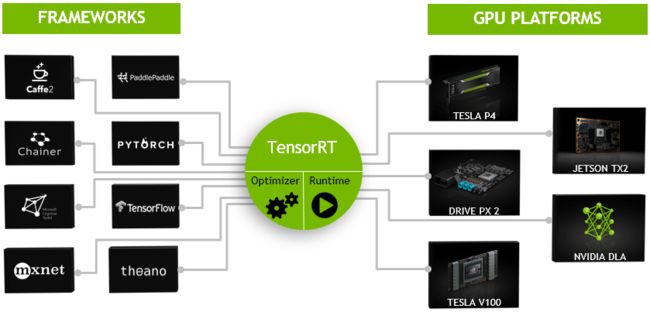
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
一、TensorRT
TensorRT(TensorRT™)是英伟达(NVIDIA)开发的一个高性能推理优化器,旨在加速深度学习模型的推理过程。它针对英伟达GPU进行了优化,利用深度神经网络(DNN)推理的并行计算能力,提供了快速且高效的推理解决方案。下面我将详细介绍TensorRT的原理、架构、功能和性能。
(TensorRT(1)-介绍-使用-安装 | arleyzhang)
1.1 原理
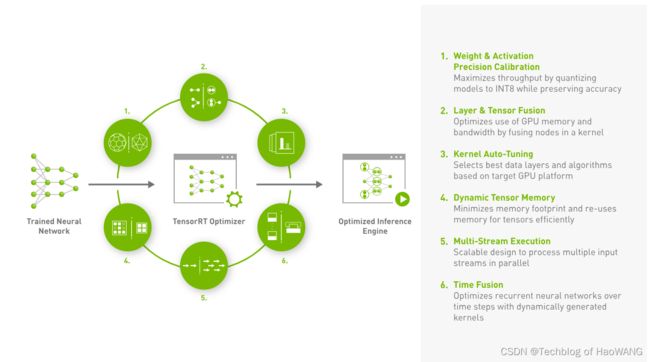
TensorRT的核心原理是通过优化和精简深度学习模型,以提高推理的速度和效率。它使用了三个关键技术:
- 网络层融合(Layer Fusion):TensorRT通过将多个网络层融合成一个更大的层,减少了内存访问和计算的开销。这种融合可以消除层之间的中间结果,从而减少了内存传输和存储需求,提高了推理的速度。
- 精确度校准(Precision Calibration):TensorRT可以通过在模型推理之前对模型进行精确度校准,将浮点数参数转换为定点数参数,从而降低了内存带宽和计算的需求。这种定点计算可以在保持模型精度的同时,提高推理的速度。
- 动态张量内存(Dynamic Tensor Memory):TensorRT根据模型的需求动态分配内存,避免了不必要的内存分配和拷贝操作。这种动态内存管理减少了内存开销,提高了推理的效率。
1.2 架构
TensorRT的架构可以分为四个主要组件:
- 解析器(Parser):解析器负责将训练好的深度学习模型从常见的模型格式(如Caffe、TensorFlow、ONNX等)加载到TensorRT中进行优化和推理。
- 优化器(Optimizer):优化器是TensorRT的核心组件,它通过网络层融合、精确度校准和动态张量内存等技术对深度学习模型进行优化。优化器会分析模型的结构,并根据硬件特性和性能要求对模型进行优化,以提高推理的速度和效率。
- 推理引擎(Inference Engine):推理引擎是TensorRT的推理核心,它将优化后的模型转换为可在GPU上执行的计算图。推理引擎使用GPU的并行计算能力对模型进行高效的推理,实现快速的预测。
- 插件(Plugin):插件是TensorRT的可扩展组件,它允许用户自定义和添加额外的层、操作或功能。用户可以根据自己的需求编写插件,并将其集成到TensorRT中,以扩展其功能。
1.3 功能
TensorRT提供了丰富的功能,用于优化和加速深度学习模型的推理过程,包括:
- 网络优化:TensorRT可以自动优化和精简深度学习模型,减少模型的计算和存储需求,提高推理的速度和效率。
- 精确度控制:TensorRT支持定点计算和混合精度计算,可以在保持模型精度的同时提高推理的速度。
- 动态形状支持:TensorRT可以处理具有动态形状(Dynamic Shapes)的模型,适用于一些需要在运行时根据输入数据进行形状变化的场景。
1.4 性能
TensorRT在推理性能方面表现出色,具有以下特点:
- 高速推理:TensorRT通过使用GPU的并行计算能力和优化的推理引擎,实现了快速的推理速度。相比于传统的深度学习框架,TensorRT可以显著提高模型的推理性能。
- 低延迟:TensorRT通过优化和精简模型的计算图,减少了内存访问和计算的开销,从而降低了推理的延迟。这对于实时应用和对延迟敏感的任务非常重要。
- 高吞吐量:TensorRT可以充分利用GPU的并行计算能力,实现高吞吐量的推理。这意味着可以同时处理多个输入数据,并获得更高的推理效率。
总而言之,TensorRT是一个针对深度学习模型推理优化的高性能引擎。它通过网络层融合、精确度校准和动态张量内存等技术,提供了快速、高效的推理解决方案。TensorRT在加速推理速度、降低延迟和提高吞吐量方面具有显著优势,特别适用于对性能要求较高的应用场景。
1.5 GPU并行计算
TensorRT的推理引擎充分利用了GPU的并行计算能力,以实现高效的推理。下面是TensorRT推理引擎如何利用GPU并行计算能力的几个关键方面:
- 并行计算图: TensorRT将优化后的模型转换为适用于GPU并行计算的计算图。在这个计算图中,不同的操作可以并行执行,以最大程度地利用GPU的多个计算单元。这样可以实现高效的并行推理,提高推理速度。
- 流水线并行: TensorRT推理引擎利用计算和数据传输之间的时间差异,实现流水线并行。它将不同的计算任务划分为多个阶段,并同时执行这些阶段。这种流水线并行可以减少计算和数据传输之间的等待时间,提高GPU的利用率,从而加速推理过程。
- 批处理并行: TensorRT推理引擎支持批处理并行,即同时处理多个输入数据。在批处理中,多个输入数据可以并行地在GPU上进行计算,从而实现更高的吞吐量。这种并行计算可以大大提高推理效率,特别是对于具有大量输入数据的场景。
- 权重共享: 在某些情况下,多个模型层可以共享相同的权重。TensorRT推理引擎利用这一特性,通过共享权重来减少计算和内存访问的开销。共享权重可以减少冗余计算,提高推理速度。
- Tensor核心计算: TensorRT推理引擎使用专门的Tensor核心计算单元,在GPU上执行高效的张量操作。这些Tensor核心计算单元可以同时处理多个数据元素,实现高度并行的计算,从而提高推理速度。
通过这些并行计算技术,TensorRT推理引擎能够充分发挥GPU的并行计算能力,实现高效的推理。并行计算图、流水线并行、批处理并行、权重共享以及Tensor核心计算等方法的结合,可以显著提高模型的推理性能,并满足对于实时性、低延迟和高吞吐量的要求。
二、安装&配置
1.下载
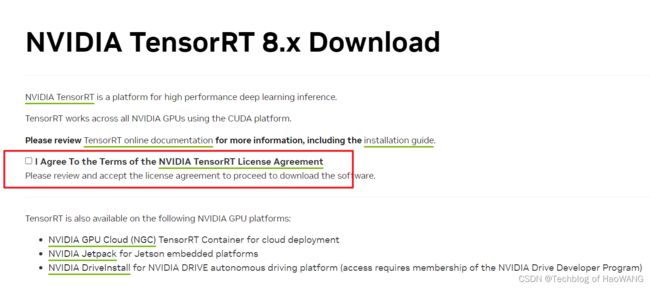
TensorRT SDK | NVIDIA DeveloperHelps developers to optimize inference, reduce latency, and deliver high throughput for inference applications.https://developer.nvidia.com/tensorrt
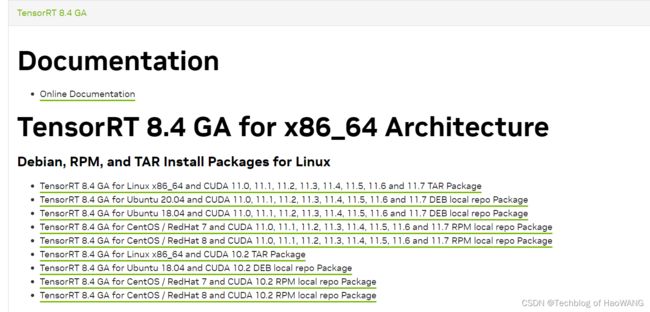
最新版本为tensorRT8 GA,根据系统下载适合的tensorRT版本:
https://developer.nvidia.com/nvidia-tensorrt-download
2.安装
1、 解压缩
tar xzvf TensorRT-X2、 安装TensorRT wheel 文件,根据python版本选择,这里是python3.7
cd TensorRT-X/python
pip install tensorrt-X.whl3、 安装graphsurgeon wheel文件
cd TensorRT-X/python
pip install graphsurgeon-X.whl4、 配置环境变量
export PATH=$PATH:/usr/local/cuda-11.1/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.1/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-11.1/lib64
source /etc/profile5、有时需要设置
export LD_LIBRARY_PATH=/home/XX/TensorRT-X/lib:$LD_LIBRARY_PATH
source ~/.bashrc3. 测试导出YOLO V8
安装依赖
pip install onnx==1.12.0
pip install onnx-simplifier==0.4.0
pip install coloredlogs==15.0.1
pip install humanfriendly==10.0
pip install onnxruntime-gpu==1.12.0
pip isntall onnxsim-no-ort==0.4.0
pip install opencv-python==4.5.2.52(注意cv2一定不能用4.6.0)
pip install protobuf==3.19.4
pip install setuptools==63.2.0
导出测试:
yolo export model=yolov8n.pt format=engine device=0 # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
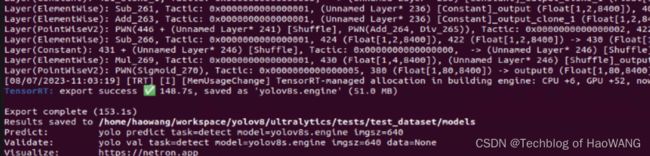
4. 部署测试
模型1:yolov8l.pt
TRT模型:yolov8l.engine
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8l.engine')
# Open the video file
video_path = "path/to/your/video/file.mp4"
cap = cv2.VideoCapture(0)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
对比: watch -n 1 nvidia-smi
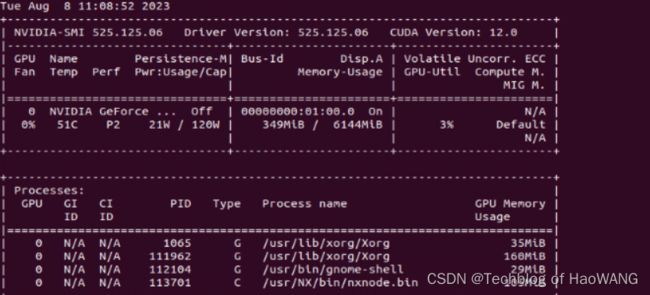
结果
模型加载速度和检测效果有较大程度提升,并且帧率和占用也维持在合理水平,TensorRT模型优化和部署性能优异。