卷积神经网络
文章目录
- 概述
- 卷积层,池化层
-
- 卷积
- 池化层-pool
- 卷积神经网络
- 卷积神经网络实战--Cifar训练集
-
- 数据预处理--图像增强
- 常见的卷积神经网络
-
- Alexnet
概述
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种深度学习的算法,它在图像处理和语音识别等领域有很强的表现。CNN得名于其核心操作:卷积。卷积是一种数学运算,它可以将输入的信息(如图像)通过一个滤波器(或称为“内核”)进行处理,以生成新的特征映射。
CNN的主要组件包括卷积层、池化层(pooling layer)、全连接层(fully connected layer)和归一化层(如ReLU)。以下是这些层的简单描述:
- 卷积层:这是CNN的核心部分,其中执行卷积操作。卷积层通过应用许多不同的滤波器来分析输入数据的不同特性。这些滤波器可以学习和识别例如边缘、线条和色块等特性。
- 池化层:池化层的主要目的是降低数据的维度,同时保留最重要的信息。这有助于减少计算的复杂性,并且可以防止过拟合。
- 全连接层:在经过多个卷积和池化层之后,数据最终被传递到一个或多个全连接层。在这些层中,每个节点都与前一层的每个节点相连,就像在传统的神经网络中那样。
- ReLU(线性整流单元):ReLU函数用于添加非线性特性。它的输出是输入的正值,如果输入是负的,则输出为0。这个函数有助于CNN学习更复杂的模式和特性。
卷积层,池化层
卷积网络与前面实现的网络不同之处在于,它可以直接接受多维向量,而以前实现的网络只能接收一维向量。
下面是一个简单的卷积神经网络示意图:
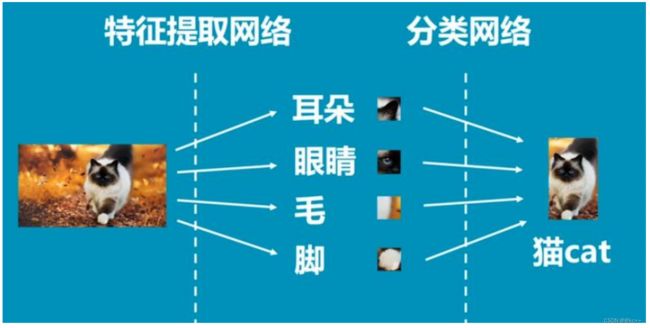
卷积
- 卷积操作,其实是把一张大图片分解成好多个小部分,然后依次对这些小部分进行识别。
- 通常我们会把一张图片分解成多个33或55的”小片“,然后分别识别这些小片段,最后把识别的结果集合在一起输出给下一层网络。
- 这种做法在图象识别中很有效。因为它能对不同区域进行识别,假设识别的图片是猫脸,那么我们就可以把猫脸分解成耳朵,嘴巴,眼睛,胡子等多个部位去各自识别,然后再把各个部分的识别结果综合起来作为对猫脸的识别。
池化层-pool

池化的作用:
卷积操作产生了太多的数据,如果没有max pooling对这些数据进行压缩,那么网络的运算量将会非常巨大,而且数据参数过于冗余就非常容易导致过度拟合。
卷积神经网络
当我们的图片(黑白图片厚度为1 ,彩色图片厚度为3)输入到神经网络后,我们会通过卷积神经网络将图片的长和宽进行压缩,然后把厚度增加。最后就变成了一个长宽很小,厚度很高的像素块。然后结果放入普通的神经网络(全连接)中处理,最后链接一个分类器(比如softmax),从而分辨出图片是什么。
卷积核
图片的采样器也可以叫做共享权值,用来在图片上采集信息。卷积核有自己的长宽,也可以定义自己的步长stride ,每跨多少步进行一次抽离信息,跨的步长越多就越容易丢失图片信息。然后对抽取的信息进行像素的加权求和得到Feature Map 增加了采集结果的厚度。
总而言之 卷积是用来不断的提取特征,每提取一个特征就会增加一个feature map,所以采集后的图片厚度不断变厚
我们学过高斯滤波、sobel滤波等等设定好卷积核的滤波方法
这时我们不禁要想,如果不是由人来设计一个滤波器,而是从一个随机滤波器开始,根据某种目标、用 某种方法去逐渐调整它,直到它接近我们想要的样子,可行么?
这就是卷积神经网络(Convolutional Neural Network, CNN)的思想了。
可调整的滤波器是CNN的“卷积”那部分;如何调整滤波器则是CNN的“神经网络”那部分(训练)。
把卷积滤波器和神经网络两个思想结合起来。
卷积滤波器无非就是一套权值。而神经网络也可以有 (除全连接外的)其它拓扑结构。

卷积神经网络实战–Cifar训练集
Cifar-10数据集包含10类共60000张32*32的彩色图片,每类6000张图。包括50000张训练图片和 10000张测试图片
Cifar10_data
#该文件负责读取Cifar-10数据并对其进行数据增强预处理
import os
import tensorflow as tf
num_classes=10
#设定用于训练和评估的样本总数
num_examples_pre_epoch_for_train=50000
num_examples_pre_epoch_for_eval=10000
#定义一个空类,用于返回读取的Cifar-10的数据
class CIFAR10Record(object):
pass
#定义一个读取Cifar-10的函数read_cifar10(),这个函数的目的就是读取目标文件里面的内容
def read_cifar10(file_queue):
result=CIFAR10Record()
label_bytes=1 #如果是Cifar-100数据集,则此处为2
result.height=32
result.width=32
result.depth=3 #因为是RGB三通道,所以深度是3
image_bytes=result.height * result.width * result.depth #图片样本总元素数量
record_bytes=label_bytes + image_bytes #因为每一个样本包含图片和标签,所以最终的元素数量还需要图片样本数量加上一个标签值
reader=tf.FixedLengthRecordReader(record_bytes=record_bytes) #使用tf.FixedLengthRecordReader()创建一个文件读取类。该类的目的就是读取文件
result.key,value=reader.read(file_queue) #使用该类的read()函数从文件队列里面读取文件
record_bytes=tf.decode_raw(value,tf.uint8) #读取到文件以后,将读取到的文件内容从字符串形式解析为图像对应的像素数组
#因为该数组第一个元素是标签,所以我们使用strided_slice()函数将标签提取出来,并且使用tf.cast()函数将这一个标签转换成int32的数值形式
result.label=tf.cast(tf.strided_slice(record_bytes,[0],[label_bytes]),tf.int32)
#剩下的元素再分割出来,这些就是图片数据,因为这些数据在数据集里面存储的形式是depth * height * width,我们要把这种格式转换成[depth,height,width]
#这一步是将一维数据转换成3维数据
depth_major=tf.reshape(tf.strided_slice(record_bytes,[label_bytes],[label_bytes + image_bytes]),
[result.depth,result.height,result.width])
#我们要将之前分割好的图片数据使用tf.transpose()函数转换成为高度信息、宽度信息、深度信息这样的顺序
#这一步是转换数据排布方式,变为(h,w,c)
result.uint8image=tf.transpose(depth_major,[1,2,0])
return result #返回值是已经把目标文件里面的信息都读取出来
def inputs(data_dir,batch_size,distorted): #这个函数就对数据进行预处理---对图像数据是否进行增强进行判断,并作出相应的操作
filenames=[os.path.join(data_dir,"data_batch_%d.bin"%i)for i in range(1,6)] #拼接地址
file_queue=tf.train.string_input_producer(filenames) #根据已经有的文件地址创建一个文件队列
read_input=read_cifar10(file_queue) #根据已经有的文件队列使用已经定义好的文件读取函数read_cifar10()读取队列中的文件
reshaped_image=tf.cast(read_input.uint8image,tf.float32) #将已经转换好的图片数据再次转换为float32的形式
num_examples_per_epoch=num_examples_pre_epoch_for_train
if distorted != None: #如果预处理函数中的distorted参数不为空值,就代表要进行图片增强处理
cropped_image=tf.random_crop(reshaped_image,[24,24,3]) #首先将预处理好的图片进行剪切,使用tf.random_crop()函数
flipped_image=tf.image.random_flip_left_right(cropped_image) #将剪切好的图片进行左右翻转,使用tf.image.random_flip_left_right()函数
adjusted_brightness=tf.image.random_brightness(flipped_image,max_delta=0.8) #将左右翻转好的图片进行随机亮度调整,使用tf.image.random_brightness()函数
adjusted_contrast=tf.image.random_contrast(adjusted_brightness,lower=0.2,upper=1.8) #将亮度调整好的图片进行随机对比度调整,使用tf.image.random_contrast()函数
float_image=tf.image.per_image_standardization(adjusted_contrast) #进行标准化图片操作,tf.image.per_image_standardization()函数是对每一个像素减去平均值并除以像素方差
float_image.set_shape([24,24,3]) #设置图片数据及标签的形状
read_input.label.set_shape([1])
min_queue_examples=int(num_examples_pre_epoch_for_eval * 0.4)
print("Filling queue with %d CIFAR images before starting to train. This will take a few minutes."
%min_queue_examples)
images_train,labels_train=tf.train.shuffle_batch([float_image,read_input.label],batch_size=batch_size,
num_threads=16,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples,
)
#使用tf.train.shuffle_batch()函数随机产生一个batch的image和label
return images_train,tf.reshape(labels_train,[batch_size])
else: #不对图像数据进行数据增强处理
resized_image=tf.image.resize_image_with_crop_or_pad(reshaped_image,24,24) #在这种情况下,使用函数tf.image.resize_image_with_crop_or_pad()对图片数据进行剪切
float_image=tf.image.per_image_standardization(resized_image) #剪切完成以后,直接进行图片标准化操作
float_image.set_shape([24,24,3])
read_input.label.set_shape([1])
min_queue_examples=int(num_examples_per_epoch * 0.4)
images_test,labels_test=tf.train.batch([float_image,read_input.label],
batch_size=batch_size,num_threads=16,
capacity=min_queue_examples + 3 * batch_size)
#这里使用batch()函数代替tf.train.shuffle_batch()函数
return images_test,tf.reshape(labels_test,[batch_size])
Cifar10
#该文件的目的是构造神经网络的整体结构,并进行训练和测试(评估)过程
import tensorflow as tf
import numpy as np
import time
import math
import Cifar10_data
max_steps=4000
batch_size=100
num_examples_for_eval=10000
data_dir="Cifar_data/cifar-10-batches-bin"
#创建一个variable_with_weight_loss()函数,该函数的作用是:
# 1.使用参数w1控制L2 loss的大小
# 2.使用函数tf.nn.l2_loss()计算权重L2 loss
# 3.使用函数tf.multiply()计算权重L2 loss与w1的乘积,并赋值给weights_loss
# 4.使用函数tf.add_to_collection()将最终的结果放在名为losses的集合里面,方便后面计算神经网络的总体loss,
def variable_with_weight_loss(shape,stddev,w1):
var=tf.Variable(tf.truncated_normal(shape,stddev=stddev))
if w1 is not None:
weights_loss=tf.multiply(tf.nn.l2_loss(var),w1,name="weights_loss")
tf.add_to_collection("losses",weights_loss)
return var
#使用上一个文件里面已经定义好的文件序列读取函数读取训练数据文件和测试数据从文件.
#其中训练数据文件进行数据增强处理,测试数据文件不进行数据增强处理
images_train,labels_train=Cifar10_data.inputs(data_dir=data_dir,batch_size=batch_size,distorted=True)
images_test,labels_test=Cifar10_data.inputs(data_dir=data_dir,batch_size=batch_size,distorted=None)
#创建x和y_两个placeholder,用于在训练或评估时提供输入的数据和对应的标签值。
#要注意的是,由于以后定义全连接网络的时候用到了batch_size,所以x中,第一个参数不应该是None,而应该是batch_size
x=tf.placeholder(tf.float32,[batch_size,24,24,3])
y_=tf.placeholder(tf.int32,[batch_size])
#创建第一个卷积层 shape=(kh,kw,ci,co)
kernel1=variable_with_weight_loss(shape=[5,5,3,64],stddev=5e-2,w1=0.0)
conv1=tf.nn.conv2d(x,kernel1,[1,1,1,1],padding="SAME")
bias1=tf.Variable(tf.constant(0.0,shape=[64]))
relu1=tf.nn.relu(tf.nn.bias_add(conv1,bias1))
pool1=tf.nn.max_pool(relu1,ksize=[1,3,3,1],strides=[1,2,2,1],padding="SAME")
#创建第二个卷积层
kernel2=variable_with_weight_loss(shape=[5,5,64,64],stddev=5e-2,w1=0.0)
conv2=tf.nn.conv2d(pool1,kernel2,[1,1,1,1],padding="SAME")
bias2=tf.Variable(tf.constant(0.1,shape=[64]))
relu2=tf.nn.relu(tf.nn.bias_add(conv2,bias2))
pool2=tf.nn.max_pool(relu2,ksize=[1,3,3,1],strides=[1,2,2,1],padding="SAME")
#因为要进行全连接层的操作,所以这里使用tf.reshape()函数将pool2输出变成一维向量,并使用get_shape()函数获取扁平化之后的长度
reshape=tf.reshape(pool2,[batch_size,-1]) #这里面的-1代表将pool2的三维结构拉直为一维结构
dim=reshape.get_shape()[1].value #get_shape()[1].value表示获取reshape之后的第二个维度的值
#建立第一个全连接层
weight1=variable_with_weight_loss(shape=[dim,384],stddev=0.04,w1=0.004)
fc_bias1=tf.Variable(tf.constant(0.1,shape=[384]))
fc_1=tf.nn.relu(tf.matmul(reshape,weight1)+fc_bias1)
#建立第二个全连接层
weight2=variable_with_weight_loss(shape=[384,192],stddev=0.04,w1=0.004)
fc_bias2=tf.Variable(tf.constant(0.1,shape=[192]))
local4=tf.nn.relu(tf.matmul(fc_1,weight2)+fc_bias2)
#建立第三个全连接层
weight3=variable_with_weight_loss(shape=[192,10],stddev=1 / 192.0,w1=0.0)
fc_bias3=tf.Variable(tf.constant(0.1,shape=[10]))
result=tf.add(tf.matmul(local4,weight3),fc_bias3)
#计算损失,包括权重参数的正则化损失和交叉熵损失
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=result,labels=tf.cast(y_,tf.int64))
weights_with_l2_loss=tf.add_n(tf.get_collection("losses"))
loss=tf.reduce_mean(cross_entropy)+weights_with_l2_loss
train_op=tf.train.AdamOptimizer(1e-3).minimize(loss)
#函数tf.nn.in_top_k()用来计算输出结果中top k的准确率,函数默认的k值是1,即top 1的准确率,也就是输出分类准确率最高时的数值
top_k_op=tf.nn.in_top_k(result,y_,1)
init_op=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
#启动线程操作,这是因为之前数据增强的时候使用train.shuffle_batch()函数的时候通过参数num_threads()配置了16个线程用于组织batch的操作
tf.train.start_queue_runners()
#每隔100step会计算并展示当前的loss、每秒钟能训练的样本数量、以及训练一个batch数据所花费的时间
for step in range (max_steps):
start_time=time.time()
image_batch,label_batch=sess.run([images_train,labels_train])
_,loss_value=sess.run([train_op,loss],feed_dict={x:image_batch,y_:label_batch})
duration=time.time() - start_time
if step % 100 == 0:
examples_per_sec=batch_size / duration
sec_per_batch=float(duration)
print("step %d,loss=%.2f(%.1f examples/sec;%.3f sec/batch)"%(step,loss_value,examples_per_sec,sec_per_batch))
#计算最终的正确率
num_batch=int(math.ceil(num_examples_for_eval/batch_size)) #math.ceil()函数用于求整
true_count=0
total_sample_count=num_batch * batch_size
#在一个for循环里面统计所有预测正确的样例个数
for j in range(num_batch):
image_batch,label_batch=sess.run([images_test,labels_test])
predictions=sess.run([top_k_op],feed_dict={x:image_batch,y_:label_batch})
true_count += np.sum(predictions)
#打印正确率信息
print("accuracy = %.3f%%"%((true_count/total_sample_count) * 100))
数据预处理–图像增强
由于深度学习对数据集的大小有一定的要求,若原始的数据集比较小,无法很好地满足网络模型的 训练,从而影响模型的性能,而图像增强是对原始图像进行一定的处理以扩充数据集,能够在一定 程度上提升模型的性能。
图像增强表示的是,在原始图像的基础上,对数据进行一定的改变,增加了数据样本的数量,但是 数据的标签值并不发生改变。

这里讲的图像增强指的是突出图像中感兴趣区域及特征。
图像增强分为两种:
- 增强“自我”:通过一定手段将感兴趣区域增强,直至从图像中脱颖而出的那种,也是正常思维下常 用的方法。
- 削弱“别人”:是增强“自我”的反方法,指的是通过一定手段将不感兴趣区域削弱,直至感兴趣区域 脱颖而出。
图像增强常用方法(包括但不限于):
- 翻转、平移、旋转、缩放
- 分离单个r、g、b三个颜色通道
- 添加噪声
- 直方图均衡化
- Gamma变换
- 反转图像的灰度
- 增加图像的对比度
- 缩放图像的灰度
- 均值滤波
- 中值滤波
- 高斯滤波
常见的卷积神经网络
Alexnet
AlexNet 是一种深度卷积神经网络 (CNN),它在 2012 年的 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 上取得了出色的表现,由此引起了人们对深度学习和 CNN 的广泛关注。这个网络是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 共同设计的,因此得名 AlexNet。
以下是 AlexNet 的主要特点和创新:
- 深度:AlexNet 有五个卷积层,接着是三个全连接层。这使得它当时比其它的大多数神经网络都要深。
- ReLU 激活函数:AlexNet 是第一个在大规模上使用 ReLU(线性整流单元)作为激活函数的网络。相比其他的激活函数,ReLU 可以加速训练的收敛速度,而且减少了训练深度模型时的问题。
- Dropout:为了避免过拟合,AlexNet 在全连接层中使用了 Dropout 技术。这是一种在训练时随机关闭一些神经元的技巧,可以防止模型在训练数据上过度拟合。
- 局部响应归一化:在某些卷积层之后,AlexNet 使用了局部响应归一化 (Local Response Normalization, LRN)。这种归一化可以提高模型的泛化能力,但在最新的模型中,它已经较少使用,因为后来的研究表明它的效果并不总是有益的。
- 重叠的最大池化:AlexNet 的池化层采用了重叠的策略,这可以避免平均池化时的模糊效果。
- 数据增强:为了进一步防止过拟合,AlexNet 使用了图像的各种随机裁剪、水平翻转和 RGB 色彩的变化等数据增强技巧。
- 双数据流的架构:由于 2012 年的 GPU 存储限制,AlexNet 的设计被分为两个并行的数据流,每个数据流在一个 GPU 上运行。
AlexNet 在 2012 年的 ImageNet 挑战赛上大幅领先于其他算法,标志着深度学习和卷积神经网络时代的开始。从此,许多其他的网络结构,如 VGG、GoogLeNet 和 ResNet,都进一步推进了深度学习在计算机视觉领域的应用。
Alexnet网络结构
- 一张原始图片被resize到(224,224,3);
- 使用步长为4x4,大小为11的卷积核对图像进行卷积,输出的特征层为96层, 输出的shape为(55,55,96);
- 使用步长为2的最大池化层进行池化,此时输出的shape为(27,27,96)
- 使用步长为1x1,大小为5的卷积核对图像进行卷积,输出的特征层为256层, 输出的shape为(27,27,256);
- 使用步长为2的最大池化层进行池化,此时输出的shape为(13,13,256);
- 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层, 输出的shape为(13,13,384);
- 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层, 输出的shape为(13,13,384);
- 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为256层, 输出的shape为(13,13,256);
- 使用步长为2的最大池化层进行池化,此时输出的shape为(6,6,256);
- 两个全连接层,最后输出为1000类
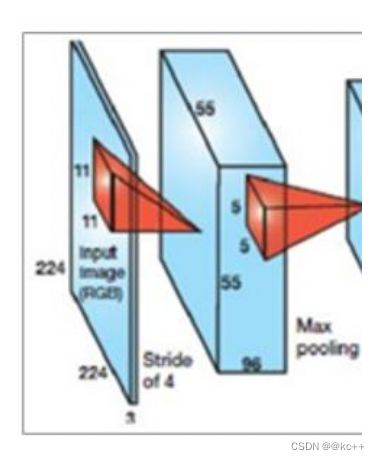
第一层
第一层输入数据为原始图像的2242243的图像,这个图像被11113(3代表 深度,例如RGB的3通道)的卷积核进行卷积运算,卷积核对原始图像的每次 卷积都会生成一个新的像素。 卷积核的步长为4个像素,朝着横向和纵向这两个方向进行卷积。 由此,会生成新的像素; 第一层有96个卷积核,所以就会形成555596个像素层。
pool池化层:这些像素层还需要经过pool运算(池化运算)的处理,池化运 算的尺度由预先设定为33,运算的步长为2,则池化后的图像的尺寸为: (55-3)/2+1=27。即经过池化处理过的规模为2727*96
train.py
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.utils import np_utils
from keras.optimizers import Adam
from model.AlexNet import AlexNet
import numpy as np
import utils
import cv2
from keras import backend as K
K.set_image_dim_ordering('tf')
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for b in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = cv2.imread(r".\data\image\train" + '/' + name)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = img/255
X_train.append(img)
Y_train.append(lines[i].split(';')[1])
# 读完一个周期后重新开始
i = (i+1) % n
# 处理图像
X_train = utils.resize_image(X_train,(224,224))
X_train = X_train.reshape(-1,224,224,3)
Y_train = np_utils.to_categorical(np.array(Y_train),num_classes= 2)
yield (X_train, Y_train)
if __name__ == "__main__":
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\dataset.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 建立AlexNet模型
model = AlexNet()
# 保存的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
batch_size = 128
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'last1.h5')
utils.py
import matplotlib.image as mpimg
import numpy as np
import cv2
import tensorflow as tf
from tensorflow.python.ops import array_ops
def load_image(path):
# 读取图片,rgb
img = mpimg.imread(path)
# 将图片修剪成中心的正方形
short_edge = min(img.shape[:2])
yy = int((img.shape[0] - short_edge) / 2)
xx = int((img.shape[1] - short_edge) / 2)
crop_img = img[yy: yy + short_edge, xx: xx + short_edge]
return crop_img
def resize_image(image, size):
with tf.name_scope('resize_image'):
images = []
for i in image:
i = cv2.resize(i, size)
images.append(i)
images = np.array(images)
return images
def print_answer(argmax):
with open("./data/model/index_word.txt","r",encoding='utf-8') as f:
synset = [l.split(";")[1][:-1] for l in f.readlines()]
print(synset[argmax])
return synset[argmax]
predict.py
import numpy as np
import utils
import cv2
from keras import backend as K
from model.AlexNet import AlexNet
K.set_image_dim_ordering('tf')
if __name__ == "__main__":
model = AlexNet()
model.load_weights("./logs/ep039-loss0.004-val_loss0.652.h5")
img = cv2.imread("./Test.jpg")
img_RGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img_nor = img_RGB/255
img_nor = np.expand_dims(img_nor,axis = 0)
img_resize = utils.resize_image(img_nor,(224,224))
#utils.print_answer(np.argmax(model.predict(img)))
print(utils.print_answer(np.argmax(model.predict(img_resize))))
cv2.imshow("ooo",img)
cv2.waitKey(0)
Alexnet.py
from keras.models import Sequential
from keras.layers import Dense,Activation,Conv2D,MaxPooling2D,Flatten,Dropout,BatchNormalization
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import Adam
def AlexNet(input_shape=(224,224,3),output_shape=2):
# AlexNet
model = Sequential()
# 使用步长为4x4,大小为11的卷积核对图像进行卷积,输出的特征层为96层,输出的shape为(55,55,96);
# 所建模型后输出为48特征层
model.add(
Conv2D(
filters=48,
kernel_size=(11,11),
strides=(4,4),
padding='valid',
input_shape=input_shape,
activation='relu'
)
)
model.add(BatchNormalization())
# 使用步长为2的最大池化层进行池化,此时输出的shape为(27,27,96)
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 使用步长为1x1,大小为5的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(27,27,256);
# 所建模型后输出为128特征层
model.add(
Conv2D(
filters=128,
kernel_size=(5,5),
strides=(1,1),
padding='same',
activation='relu'
)
)
model.add(BatchNormalization())
# 使用步长为2的最大池化层进行池化,此时输出的shape为(13,13,256);
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
# 所建模型后输出为192特征层
model.add(
Conv2D(
filters=192,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
# 所建模型后输出为192特征层
model.add(
Conv2D(
filters=192,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(13,13,256);
# 所建模型后输出为128特征层
model.add(
Conv2D(
filters=128,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为2的最大池化层进行池化,此时输出的shape为(6,6,256);
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 两个全连接层,最后输出为1000类,这里改为2类
# 缩减为1024
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(output_shape, activation='softmax'))
return model
预测结果
