异步fifo知识点
1.格雷码
(1)二进制码转换成格雷码,其法则是保留二进制码的最高位作为格雷码的最高位,而次高位格雷码为二进制码的高位与次高位相异或(异或:两个数相同为0,不同为1),而格雷码其余各位与次高位的求法相类似。

(2)格雷码转换成二进制码,其法则是保留格雷码的最高位作为自然二进制码的最高位,而次高位自然二进制码为高位自然二进制码与次高位格雷码相异或,而自然二进制码的其余各位与次高位自然二进制码的求法相类似。

异步FIFO的写指针和读指针分属不同时钟域,这样指针在进行同步过程中很容易出错,比如写指针在从0111到1000(一般来说地址都是顺序往上加的)跳变时4位同时改变,这样读时钟在进行写指针同步后得到的写指针可能是0000-1111的某个值,一共有2^4个可能的情况,而这些都是不可控制的,并不能确定会出现哪个值,那出错的概率非常大(导致系统异常,亚稳态问题),怎么办呢?
到了格雷码发挥作用的时候了,而格雷码的编码特点是相邻位每次只有 1 位发生变化, 这样在进行指针同步的时候,只有两种可能出现的情况:1.指针同步正确,正是我们所要的;2.指针同步出错。举例假设格雷码写指针从000->001,将写指针同步到读时钟域同步出错,出错的结果只可能是000->000,因为相邻位的格雷码每次只有一位变化,这个出错结果实际上也就是写指针没有跳变保持不变,那么这个错误会不会导致读空判断出错?答案是不会,最多是让空标志在FIFO不是真正空的时候产生,而不会出现空读的情形(本来应该写入一个数据了,但是格雷码出错,还是000不变,这时候就会表现出虚空,但是这样只会带来写操作的延迟,不会对逻辑产生影响)。所以gray码保证的是同步后的读写指针即使在出错的情形下依然能够保证FIFO功能的正确性。

如何写格雷码?
格雷码的性质:当第N位从0变到1的时候,之后的数的N-1位会关于前半段轴对称,而比N位高的位是相同的。
我们看一下8bit格雷码的前四位的例子。示意图如下:
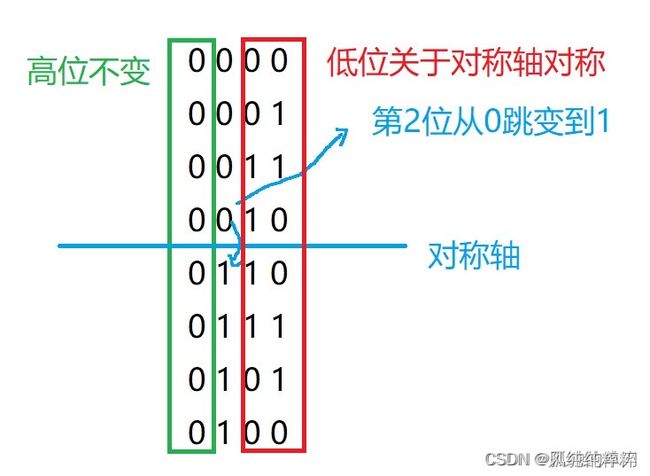
后4位就是关于第四位镜像对称,然后再高一位改为1即可,后面可以这样类推。
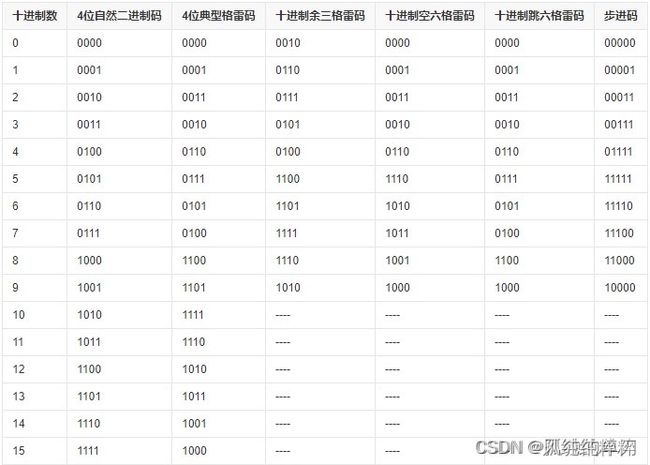
2、
对于异步FIFO而言,这里会引入一个新的问题,就是读写指针位于不同的时钟域,二者需要同步后才可以比较,同步的过程有两个:
(1)将读时钟域的读指针同步到写时钟域,将同步后的读指针与写时钟域的写指针进行比较产生写满信号;
读指针同步到写时钟域需要时间T,在经过T时间后,可能原来的读指针会增加或者不变,也就是说同步后的读指针一定是小于等于原来的读指针的。写指针也可能发生变化,但是写指针本来就在这个时钟域,所以是不需要同步的,也就意味着进行对比的写指针就是真实的写指针。
现在来进行写满的判断:也就是写指针超过了同步后的读指针一圈。但是原来的读指针是大于等于同步后的读指针的,所以实际上这个时候写指针其实是没有超过读指针一圈的,也就是说这种情况是“假写满”。那么“假写满”是一种错误的设计吗?答案是NO。前面我们说过异步FIFO设计的关键点是产生合适的“写满”和“读空”信号,那么何谓“合适”?该报的时候没报算合适吗?当然不算合适。不该报的时候报了算不算合适?答案是算。可以想象一下,假设一个深度为100的FIFO,在写到第98个数据的时候就报了“写满”,会引起什么后果?答案是不会造成功能错误,只会造成性能损失(2%),大不了FIFO的深度我少用一点点就是的。事实上这还可以算是某种程度上的保守设计(安全)。
接着进行读空的判断:也就是同步后的读指针追上了写指针。但是原来的读指针是大于等于同步后的读指针的,所以实际上这个时候读指针实际上是超过了写指针。这种情况意味着已经发生了“读空”,却仍然有错误数据读出。所以这种情况就造成了FIFO的功能错误。
(2)将写时钟域的写指针同步到读时钟域,将同步后的写指针与读时钟域的读指针进行比较产生读空信号;
现在来进行写满的判断:也就是同步后的写指针超过了读指针一圈。但是原来的写指针是大于等于同步后的写指针的,所以实际上这个时候写指针已经超过了读指针不止一圈,这种情况意味着已经发生了“写满”,却仍然数据被覆盖写入。所以这种情况就造成了FIFO的功能错误。
接着进行读空的判断:也就是读指针追上了同步后的指针。但是原来的写指针是大于等于同步后的写指针的,所以实际上这个时候读指针其实还没有追上写指针,也就是说这种情况是“假读空”。那么“假读空”是一种错误的设计吗?答案是NO。前面我们说过异步FIFO设计的关键点是产生合适的“写满”和“读空”信号,那么何谓“合适”?该报的时候没报算合适吗?当然不算合适。不该报的时候报了算不算合适?答案是算。可以想象一下,假设某个FIFO,在读到还剩2个数据的时候就报了“读空”,会引起什么后果?答案是不会造成功能错误,只会造成性能损失(2%),大不了我先不读了,等数据多了再读就是的。事实上这还可以算是某种程度上的保守设计(安全)。
所以:读时钟的读指针同步到写时钟域进行写满信号判断;写时钟的写指针同步到读时钟域进行读空判断。
3、使用gray码同时也带来另一个问题,即在格雷码域如何判断空与满。对于“空”的判断依然同异步二者完全相等(就是读写指针一样,为读空);
而对于“满”的判断,如下图,由于gray码除了最高位外,具有镜像对称的特点,当读指针指向7,写指针指向8时,除了最高位,其余位皆相同,(7的格雷码是0100 8的格雷码是1100 ) 这样如果用我们之前判断同步fifo来就会出现满错误。

因此不能单纯的只检测最高位了,在gray码上判断为满必须同时满足以下3条:
(1)读指针和写指针的最高位不相等
(2)读指针和写指针的次高位也不相等
(3)剩下的其余位完全相等。如图中位置7(读指针)和位置15(写指针)(位置7对应的满状态是15,以fifo深度为8来算),转化为二进制对应的是0111和1111
4、
将读指针同步到写时钟域来判断满;将写指针同步到读时钟域来判断空。既然是异步FIFO,那么读写时钟域的信号是不一致的,其中一个的频率快,另一个的频率这慢。那么在两次同步过程中,一定是一次慢时钟采快时钟和一次快时钟采慢时钟。快时钟采慢时钟是不会有问题的,因为这符合采样定理。但是慢时钟采快时钟则会有问题,因为采样过程不符合采样定理。
那么会造成什么问题?答案是漏采。某些数值可能会被漏掉。例如原本是连续的0--1--2---3的信号,从快时钟同步到慢时钟后,就变成了离散的0--3,其中的1、2被漏掉了。那么这样一种现象会导致空、满的判断是准确的吗?答案是不准确,但没关系。
设想读慢写快与读快写慢两种情况:
读慢写快:
进行写满判断的时候需要将读指针同步到写时钟域,因为读慢写快,所以不会有读指针遗漏,同步消耗时钟周期,所以同步后的读指针滞后(小于等于)当前读地址,所以可能写满会提前产生,并非真写满。
进行读空判断的时候需要将写指针同步到读指针 ,因为读慢写快,所以当读时钟同步写指针的时候,必然会漏掉一部分写指针,我们不用关心那到底会漏掉哪些写指针,我们在乎的是漏掉的指针会对FIFO的读空产生影响吗?比如写指针从0写到10,期间读时钟域只同步捕捉到了3、5、8这三个写指针而漏掉了其他指针。当同步到8这个写指针时,真实的写指针可能已经写到10 ,相当于在读时钟域还没来得及觉察的情况下,写时钟域可能写了数据到FIFO去,这样在判断它是不是空的时候会出现不是真正空的情况,漏掉的指针也没有对FIFO的逻辑操作产生影响。
读快写慢:
进行读空判断的时候需要将写指针同步到读指针 ,因为读快写慢,所以不会有写指针遗漏,同步消耗时钟周期,所以同步后的写指针滞后(小于等于)当前写地址,所以可能读空会提前产生,并非真读空。
进行写满判断的时候需要将读指针同步到写时钟域,因为读快写慢,所以当写时钟同步读指针的时候,必然会漏掉一部分读指针,我们不用关心那到底会漏掉哪些读指针,我们在乎的是漏掉的指针会对FIFO的写满产生影响吗?比如读指针从0读到10,期间写时钟域只同步捕捉到了3、5、8这三个读指针而漏掉了其他指针。当同步到8这个读指针时,真实的读指针可能已经读到10 ,相当于在写时钟域还没来得及觉察的情况下,读时钟域可能从FIFO读了数据出来,这样在判断它是不是满的时候会出现不是真正满的情况,漏掉的指针也没有对FIFO的逻辑操作产生影响。
现在我们会发现,所谓的空满信号实际上是不准确的,在还没有空、满的时钟就已经输出了空满信号,这样的空满信号一般称为假空、假满。假空、假满信号本质上是一种保守设计,想象一下,一个深度为16的异步FIFO,在其写入14个数据时,即输出了写满(假满)标志,这会对我们的设计造成影响吗?会,会削弱我们的效率,我们实际使用的FIFO深度成了14,但是会使得我们的设计产生错误吗?显然不会。同样的,在FIFO深度仍有2时即输出了读空(假空)标志,也不会使得我们的设计出错,但是会降低效率,因为我们使用的FIFO深度又少了2。
5、
既然有假满、假空,那么有没有真满、真空?
还真有,但是没意义。既然我们可以将读指针同步到写时钟域来判断假满;将写指针同步到读时钟域来判断假空。那么对应地,可以读指针同步到写时钟域来判断空;将写指针同步到读时钟域来判断满。
在写时钟域判断空:
读指针被同步过来的信号(同步后读指针)是滞后于真实读指针的信号,当同步后读指针等于写指针时,真实读指针实际上早就等于写指针了,也就是说此时的空一定是空,甚至已经空了一段时间了。这样的空标志显然是没有使用意义的,因为会造成对FIFO的过读操作,你来来回回读个空FIFO有什么意义呢?也就是说真空能实现,但是没实际使用意义。
在读时钟域判断满:
写指针被同步过来的信号(同步后写指针)是滞后于真实写指针的信号,但同步后写指针超过读指针一圈时,真实写指针实际上早就超过读指针一圈了,也就是说此时的满一定是满,甚至已经满了一段时间了。这样的满标志显然是没有使用意义的,因为会造成对FIFO的过写操作,你来来回回写个满FIFO有什么意义呢?也就是说真满也能实现,但是同样没实际使用意义。
6、
非2次幂深度的FIFO如何设计?
在第1点关于格雷码的性质中,我们阐述了:
在一组数的编码中,若任意两个相邻的代码只有一位二进制数不同,则称这种编码为格雷码
当第N位从0变到1的时候,之后的数的N-1位会关于前半段轴对称,而比N位高的位是相同的。
由这两点,我们发现格雷码都可以关于某条对称轴对称。所以只有当FIFO深度为2的幂次方时,才能做到格雷码绕一圈后,回到初始位置仍然只有1bit变化,如15(1000)----0(0000)。当FIFO深度不为2的幂次方时,显然从最尾端跳转到开头端,变化的就不止一个bit了。比如FIFO深度为7,显然,从13(1011)----0(0000),变化了可不止1bit。这样的话在这一次跳变就失去了格雷码存在的意义了,所以得想点其他办法解决。
前面说过,格雷码相邻每位只变化1bit,而且关于中轴对称的。那么我们可以这样编码:针对深度为7的FIFO,从1(0001)开始,一直到(14个数表示7深度,高位区分状态)14(1001),1(0001)与14(1001)是关于中轴对称的(高位为变化位),所以也只有1bit的跳变。同样的如果深度为6的FIFO,就从2(0011)开始,到13(1011),同样只跳变1bit。

首先介绍下自己,个人是材料专业转行IC验证,去年秋招也面试了许多场面试,最近临近毕业,想着有空分享一下自己的面试经验。个人面试经验来看面试官基本都会针对异步FIFO进行提问,虽然异步FIFO较为简单,但其实深挖的知识点还是非常多的。
首先是关于异步FIFO的描述,我的简历以及我给面试官介绍异步FIFO这个项目,基本上都是围绕着以下几点进行介绍。
一、理解异步FIFO设计代码:主要侧重于设计要点(格雷码+俩寄存器同步),代码要看懂
二、制定验证计划、提取验证功能点:(接口方面、功能方面、异常方面)
三、搭建验证平台:主要描述验证平台结构以及数据流方向
四、跑仿真:主要验证了什么
五、收集覆盖率:代码覆盖率和功能覆盖率情况
其中关于第一点(理解异步FIFO设计代码),这块问到的知识点主要有以下:
(1)什么是异步FIFO?与同步FIFO有何不同?异步FIFO的设计理念和设计要点是什么?同步FIFO和异步FIFO的应用场景分别是什么?
很多时候面试官的问题是顺着你的答案进行提问,比如你回答了异步FIFO的设计要点是如何得出空满状态位(读写指针采用格雷码编码,并且经过俩级寄存器同步后进行指针对比得出空满状态位),他就会顺着你的答案继续问。
(2)空满状态位是怎么得出的?为什么要用格雷码编码而不用二进制编码和独热码编码?为什么要经过俩级寄存器的同步再进行指针的对比(涉及到亚稳态)?
(3)亚稳态相关问题:什么是CDC(跨时钟与传输问题)?CDC为什么会产生亚稳态?建立时间和保持时间的概念?如何尽可能降低亚稳态的发生概率?单bit数据怎么进行跨时钟域的传输以及多bit如何进行跨时钟域的传输?
其中关于第二点(验证计划和验证功能点)
(1)关于这块面试官通常让你介绍一下你的验证功能点
验证计划其实就是模块级别的验证,主要用sv语言搭建了验证平台进行验证。验证功能点也相对简单,最最重要的验证点就是功能(异步FIFO的读和写功能),除此之外就是验证接口这块,主要包含时钟和复位,比如验证读写时钟不一致的情况,比如写时钟快,读时钟慢,又或者写时钟慢,读时钟快,以及同时读写,先写再读等情况。异常情况就是FIFO的写满和读空。
其中关于第三点(搭建验证平台)
关于验证环境这块,大部分面试官只会问验证框架是怎么样的,数据流是怎么样的?极少部分让讲你的某个class具体代码是如何实现的。
(1)介绍你的验证环境是怎么样的?
一般来说,从最顶层Top层向下一层一层介绍你的验证环境,比如top里面例化了DUT、interface、env等等。然后env里面又例化了比如driver、monitior等等。
(2)介绍你的数据流向(读操作和写操作具体怎么进行的)?
比如写操作:driver产生数据后通过interface发送给DUT(具体发送到哪个端口?),以及monitior从DUT的哪个端口读取数据(读操作)?
(3)你的环境中的scoreboard是怎么对比数据的? 不同组件(class)之间是用什么进行通信的(mailbox)?
其中关于第四点(跑仿真验证)
(1)你是怎么跑仿真的?
(2)你写了几个case?
(3)都验证了那些情况?你写scoreboard了吗?scoreboard是怎么实现的?
(4)采取的定向测试还是随机化测试?你的driver是怎么实现随机化的?
其中关于第五点(覆盖率)
(1)你是怎么样衡量你的验证完善程度?
覆盖率
(2)代码覆盖率有哪几种?分别讲讲你的代码覆盖率情况?
(3)功能覆盖率怎么实现?你写了哪些covergroup和coverpoint?最终功能覆盖率的情况如何?
(4)如果你的代码覆盖率低该怎么改善?功能覆盖率低该怎么改善?