Stream流式运算原理与使用详解
Stream流式运算
一、Stream的定义
Java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的 Lambda ,给我们操作集合(Collection)提供了极大的便利。
那么什么是Stream?
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
二、对流的操作
Stream可以由数组或集合创建,对流的操作分为两种:
- 中间操作,每次返回一个新的流,可以有多个。
- 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
另外,Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
可以理解为:一次性流
三、一次性的流
流和迭代器类似,只能迭代一次。
Stream<String> stream = list.stream().map(Person::getName).sorted().limit(10);
List<String> newList = stream.collect(Collectors.toList());
List<String> newList2 = stream.collect(Collectors.toList());
上面代码中第三行会报错,因为第二行已经使用过这个流,这个流已经被消费掉了。
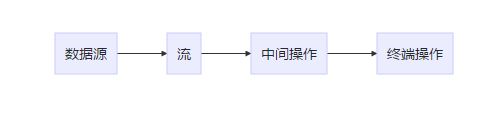
整个流操作就是一条流水线,将元素放在流水线上一个个地进行处理。所以可以理解为叫做流。
其中数据源便是原始集合,然后将如 List 的集合转换为 Stream 类型的流,并对流进行一系列的中间操作,比如过滤保留部分元素、对元素进行排序、类型转换等;最后再进行一个终端操作,可以把 Stream 转换回集合类型,也可以直接对其中的各个元素进行处理,比如打印、比如计算总数、计算最大值等等。
很重要的一点是,很多流操作本身就会返回一个流,所以多个操作可以直接连接起来,我们来看看一条 Stream 操作的代码:

如果是以前,进行这么一系列操作,你需要做个迭代器或者 foreach 循环,然后遍历,一步步地亲力亲为地去完成这些操作;但是如果使用流,你便可以直接声明式地下指令,流会帮你完成这些操作。
四、Stream与SQL语言类似
1.均为声明式方式
Stream 中文称为 “流”,通过将集合转换为这么一种叫做 “流” 的元素序列,通过声明式方式,能够对集合中的每个元素进行一系列并行或串行的流水线操作。
换句话说,你只需要告诉流你的要求,流便会在背后自行根据要求对元素进行处理,而你只需要 “坐享其成”。
就像 SQL 语句一样,只要直接声明式地下指令,SQL语句就会完成操作。例如: select username from user where id = 1,你只要说明:“我需要 id 是 1 (id = 1)的用户(user)的用户名(username )”,那么就可以得到自己想要的数据,而不需要自己亲自去数据库里面循环遍历查找。
2.均可操作
并且SQL可以操作的,而一般流式计算也可以操作的。比如筛选、映射、统计等操作,都是和SQL语句十分相似的。
五、Stream 和集合的差异
1.计算时间不同
Stream 和集合的其中一个差异在于什么时候进行计算。
一个集合,它会包含当前数据结构中所有的值,你可以随时增删,但是集合里面的元素毫无疑问地都是已经计算好了的。
流则是按需计算,你可以想象一个水龙头,假设你需要一个奇数流,从 1 开始,那么这个水龙头会源源不断地流出你需要的数据,假设你只需要 10 个,那么这个流便会按需生成 10 个奇数,换句话来说,就是在用户要求的时候才会计算值,只要你需要,你便可以打开这个水龙头。
又比方说我们通过搜索引擎进行搜索,搜索出来的条目并不是全部呈现出来的,而且先显示最符合的前 10 条或者前 20 条,只有在点击 “下一页” 的时候,才会再输出新的 10 条。
再比方在线观看电影和你硬盘里面的电影,也是差不多的道理。
2.迭代不同
外部迭代和内部迭代
Stream 和集合的另一个差异在于迭代。
我们可以把集合比作一个工厂的仓库,一开始工厂比较落后,要对货物作什么修改,只能工人亲自走进仓库对货物进行处理,有时候还要将处理后的货物放到一个新的仓库里面。在这个时期,我们需要亲自去做迭代,一个个地找到需要的货物,并进行处理,这叫做外部迭代。
后来工厂发展了起来,配备了流水线作业,只要根据需求设计出相应的流水线,然后工人只要把货物放到流水线上,就可以等着接收成果了,而且流水线还可以根据要求直接把货物输送到相应的仓库。这就叫做内部迭代,流水线已经帮你把迭代给完成了,你只需要说要干什么就可以了(即设计出合理的流水线)。
Java 8 引入 Stream 很大程度是因为,流的内部迭代可以自动选择一种合适你硬件的数据表示和并行实现;而以往程序员自己进行 foreach 之类的时候,则需要自己去管理并行等问题。
六、Optional 类
Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
NullPointerException 可以说是每一个 Java 程序员都非常讨厌看到的一个词,针对这个问题, Java 8 引入了一个新的容器类 Optional,可以代表一个值存在或不存在,这样就不用返回容易出问题的 null。之前文章的代码中就经常出现这个类,也是针对这个问题进行的改进。
Optional 类比较常用的几个方法有:
- isPresent() :值存在时返回 true,反之 flase
- get() :返回当前值,若值不存在会抛出异常
- orElse(T) :值存在时返回该值,否则返回 T 的值
Optional 类还有三个特化版本 OptionalInt,OptionalLong,OptionalDouble,在后面的数值流中的 max 方法返回的类型便是这个。
八、Stream的使用
案例中使用的员工类:
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
personList.add(new Person("Anni", 8200, "female", "New York"));
personList.add(new Person("Owen", 9500, "male", "New York"));
personList.add(new Person("Alisa", 7900, "female", "New York"));
class Person {
private String name; // 姓名
private int salary; // 薪资
private int age; // 年龄
private String sex; //性别
private String area; // 地区
// 构造方法
public Person(String name, int salary, int age,String sex,String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
// 省略了get和set,请自行添加
}
1.遍历forEach()
返回结果为 void,很明显我们可以通过它来干什么了,比方说:
//打印各个元素:
list.stream().forEach(System.out::println);
12
再比如说 MyBatis 里面访问数据库的 mapper 方法:
//向数据库插入新元素:
list.stream().forEach(PersonMapper::insertPerson);
Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。
2.发现Find()
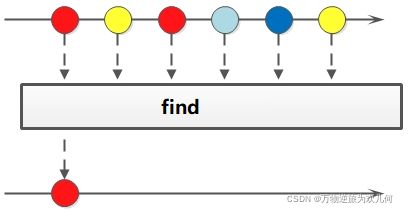
2.1 findAny() 和 findFirst()
- findAny():找到其中一个元素 (使用 stream() 时找到的是第一个元素;使用 parallelStream()并行时找到的是其中一个元素)
- findFirst():找到第一个元素
值得注意的是,这两个方法返回的是一个 Optional 对象,它是一个容器类,能代表一个值存在或不存在。
3.匹配Match
3.1 anyMatch(T -> boolean)
流中是否有一个元素匹配给定的 T -> boolean 条件
是否存在一个 person 对象的 age 等于 20:
boolean b = list.stream().anyMatch(person -> person.getAge() == 20);
3.2 allMatch(T -> boolean)
流中是否所有元素都匹配给定的 T -> boolean 条件
boolean result = list.stream().allMatch(Person::isStudent);
3.3 noneMatch(T -> boolean)
流中是否没有元素匹配给定的 T -> boolean 条件
boolean result = list.stream().noneMatch(Person::isStudent);
案例
// import已省略,请自行添加,后面代码亦是
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x > 6);
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("是否存在大于6的值:" + anyMatch);
}
}
4.筛选filter(T -> boolean)
filter(T -> boolean):保留 boolean 为 true 的元素。
筛选,是按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。
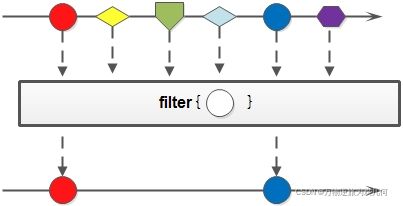
案例一:筛选出Integer集合中大于7的元素,并打印出来
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
Stream<Integer> stream = list.stream();
stream.filter(x -> x > 7).forEach(System.out::println);
}
}
预期结果:
8 9
案例二: 筛选员工中工资高于8000的人,并形成新的集合。 形成新集合依赖collect(收集),后文有详细介绍。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
List<String> fiterList = personList.stream().filter(x -> x.getSalary() > 8000).map(Person::getName)
.collect(Collectors.toList());
System.out.print("高于8000的员工姓名:" + fiterList);
}
}
运行结果:
高于8000的员工姓名:[Tom, Anni, Owen]
5.聚合(max/min/count)
max、min、count这些字眼你一定不陌生,没错,在mysql中我们常用它们进行数据统计。Java stream中也引入了这些概念和用法,极大地方便了我们对集合、数组的数据统计工作。

案例一:获取String集合中最长的元素。
public class StreamTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd");
Optional<String> max = list.stream().max(Comparator.comparing(String::length));
System.out.println("最长的字符串:" + max.get());
}
}
输出结果:
最长的字符串:weoujgsd
案例二:获取Integer集合中的最大值。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 9, 4, 11, 6);
// 自然排序
Optional<Integer> max = list.stream().max(Integer::compareTo);
// 自定义排序
Optional<Integer> max2 = list.stream().max(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
System.out.println("自然排序的最大值:" + max.get());
System.out.println("自定义排序的最大值:" + max2.get());
}
}
输出结果:
自然排序的最大值:11
自定义排序的最大值:11
案例三:获取员工工资最高的人。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
Optional<Person> max = personList.stream().max(Comparator.comparingInt(Person::getSalary));
System.out.println("员工工资最大值:" + max.get().getSalary());
}
}
输出结果:
员工工资最大值:9500
案例四:计算Integer集合中大于6的元素的个数。
import java.util.Arrays;
import java.util.List;
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 6, 4, 8, 2, 11, 9);
long count = list.stream().filter(x -> x > 6).count();
System.out.println("list中大于6的元素个数:" + count);
}
}
输出结果:
list中大于6的元素个数:4
6.映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
6.1 map(T -> R)
将流中的每一个元素 T 映射为 R(类似类型转换)
List<String> newlist = list.stream().map(Person::getName).collect(Collectors.toList());
newlist 里面的元素为 list 中每一个 Person 对象的 name 变量。
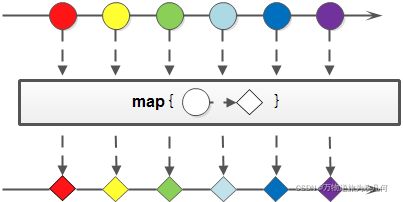
6.2 flatMap(T -> Stream)
将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
List<String> list = new ArrayList<>();
list.add("aaa bbb ccc");
list.add("ddd eee fff");
list.add("ggg hhh iii");
list = list.stream().map(s -> s.split(" ")).flatMap(Arrays::stream).collect(toList());
上面例子中,我们的目的是把 List 中每个字符串元素以” “分割开,变成一个新的 List。
首先 map 方法分割每个字符串元素,但此时流的类型为 Stream。
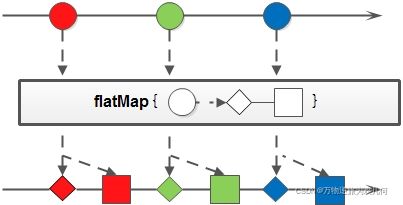
案例一:英文字符串数组的元素全部改为大写。整数数组每个元素+3。
public class StreamTest {
public static void main(String[] args) {
String[] strArr = { "abcd", "bcdd", "defde", "fTr" };
List<String> strList = Arrays.stream(strArr).map(String::toUpperCase).collect(Collectors.toList());
List<Integer> intList = Arrays.asList(1, 3, 5, 7, 9, 11);
List<Integer> intListNew = intList.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println("每个元素大写:" + strList);
System.out.println("每个元素+3:" + intListNew);
}
}
输出结果:
每个元素大写:[ABCD, BCDD, DEFDE, FTR]
每个元素+3:[4, 6, 8, 10, 12, 14]
案例二:将员工的薪资全部增加1000。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
// 不改变原来员工集合的方式
List<Person> personListNew = personList.stream().map(person -> {
Person personNew = new Person(person.getName(), 0, 0, null, null);
personNew.setSalary(person.getSalary() + 10000);
return personNew;
}).collect(Collectors.toList());
System.out.println("一次改动前:" + personList.get(0).getName() + "-->" + personList.get(0).getSalary());
System.out.println("一次改动后:" + personListNew.get(0).getName() + "-->" + personListNew.get(0).getSalary());
// 改变原来员工集合的方式
List<Person> personListNew2 = personList.stream().map(person -> {
person.setSalary(person.getSalary() + 10000);
return person;
}).collect(Collectors.toList());
System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());
System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());
}
}
输出结果:
一次改动前:Tom–>8900
一次改动后:Tom–>18900
二次改动前:Tom–>18900
二次改动后:Tom–>18900
案例三:将两个字符数组合并成一个新的字符数组。
public class StreamTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
}
}
输出结果:
处理前的集合:[m-k-l-a, 1-3-5]
处理后的集合:[m, k, l, a, 1, 3, 5]
7.归约(reduce)
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
7.1 reduce((T, T) -> T) 和 reduce(T, (T, T) -> T)
归约是将集合中的所有元素经过指定运算,折叠成一个元素输出,如:求最值、平均数等,这些操作都是将一个集合的元素折叠成一个元素输出。
在流中,reduce函数能实现归约。
reduce函数接收两个参数:
- 初始值
- 进行归约操作的Lambda表达式
用于组合流中的元素,如求和,求积,求最大值等
int age = list.stream().reduce(0, (person1,person2)->person1.getAge()+person2.getAge());
//计算年龄总和:
int sum = list.stream().map(Person::getAge).reduce(0, (a, b) -> a + b);
//与之相同:
int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum);
其中,reduce 第一个参数 0 代表起始值为 0,lambda (a, b) -> a + b 即将两值相加产生一个新值
同样地:
//计算年龄总乘积:
int sum = list.stream().map(Person::getAge).reduce(1, (a, b) -> a * b);
当然也可以
Optional<Integer> sum = list.stream().map(Person::getAge).reduce(Integer::sum);
即不接受任何起始值,但因为没有初始值,需要考虑结果可能不存在的情况,因此返回的是 Optional 类型。
案例一:求Integer集合的元素之和、乘积和最大值。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
// 求和方式1
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
// 求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
// 求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
// 求乘积
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
// 求最大值方式1
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
// 求最大值写法2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
System.out.println("list求积:" + product.get());
System.out.println("list求和:" + max.get() + "," + max2);
}
}
输出结果:
list求和:29,29,29
list求积:2112
list求和:11,11
案例二:求所有员工的工资之和和最高工资。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
// 求工资之和方式1:
Optional<Integer> sumSalary = personList.stream().map(Person::getSalary).reduce(Integer::sum);
// 求工资之和方式2:
Integer sumSalary2 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(),
(sum1, sum2) -> sum1 + sum2);
// 求工资之和方式3:
Integer sumSalary3 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);
// 求最高工资方式1:
Integer maxSalary = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
Integer::max);
// 求最高工资方式2:
Integer maxSalary2 = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),
(max1, max2) -> max1 > max2 ? max1 : max2);
System.out.println("工资之和:" + sumSalary.get() + "," + sumSalary2 + "," + sumSalary3);
System.out.println("最高工资:" + maxSalary + "," + maxSalary2);
}
}
输出结果:
工资之和:49300,49300,49300
最高工资:9500,9500
8.收集(collect)
collect,收集方法,我们很常用的是 collect(toList()),当然还有 collect(toSet()) 等,参数是一个收集器接口。收集方法可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
coollect 方法作为终端操作,接受的是一个 Collector 接口参数,能对数据进行一些收集归总操作。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
8.1 归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,即把流中所有元素收集到一个 List, Set 或 Collection 中,另外还有toCollection、toConcurrentMap等复杂一些的用法。
下面用一个案例演示toList、toSet和toMap:
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);
List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());
Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000)
.collect(Collectors.toMap(Person::getName, p -> p));
System.out.println("toList:" + listNew);
System.out.println("toSet:" + set);
System.out.println("toMap:" + map);
}
}
运行结果:
toList:[6, 4, 6, 6, 20]
toSet:[4, 20, 6]
toMap:{Tom=mutest.Person@5fd0d5ae, Anni=mutest.Person@2d98a335}
9.统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
- 计数:
count。返回流中元素个数,结果为 long 类型。 - 平均值:
averagingInt、averagingLong、averagingDouble - 最值:
maxBy、minBy - 求和:
summingInt、summingLong、summingDouble - 统计以上所有:
summarizingInt、summarizingLong、summarizingDouble
案例:统计员工人数、平均工资、工资总额、最高工资。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 求总数
Long count = personList.stream().collect(Collectors.counting());
// 求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + count);
System.out.println("员工平均工资:" + average);
System.out.println("员工工资总和:" + sum);
System.out.println("员工工资所有统计:" + collect);
}
}
运行结果:
员工总数:3
员工平均工资:7900.0
员工工资总和:23700
员工工资所有统计:DoubleSummaryStatistics{count=3, sum=23700.000000,min=7000.000000, average=7900.000000, max=8900.000000}
10.groupingBy 分组
groupingBy 用于将数据分组,最终返回一个 Map 类型
Map<Integer, List<Person>> map = list.stream().collect(groupingBy(Person::getAge));
例子中我们按照年龄 age 分组,每一个 Person 对象中年龄相同的归为一组。
Map<String,List<Person>> result = list.stream()
.collect(Collectors.groupingby((person)->{
if(person.getAge()>60)
return "老年人";
else if(person.getAge()>40)
return "中年人";
else
return "青年人";
}));
另外可以看出,Person::getAge 决定 Map 的键(Integer 类型),list 类型决定 Map 的值(List 类型)
10.1多级分组
groupingBy 可以接受一个第二参数实现多级分组:
Map<Integer, Map<T, List<Person>>> map = list.stream().collect(groupingBy(Person::getAge, groupBy(...)));
其中返回的 Map 键为 Integer 类型,值为 Map
10.2按组收集数据
Map<Integer, Integer> map = list.stream().collect(groupingBy(Person::getAge, summingInt(Person::getAge)));
该例子中,我们通过年龄进行分组,然后 summingInt(Person::getAge)) 分别计算每一组的年龄总和(Integer),最终返回一个 Map
groupingBy(Person::getAge)
其实等同于:
groupingBy(Person::getAge, toList())
11.partitioningBy 分区
分区与分组的区别在于,分区是按照 true 和 false 来分的,因此partitioningBy 接受的参数的 lambda 也是 T -> boolean。
//根据年龄是否小于等于20来分区
Map<Boolean, List<Person>> map = list.stream()
.collect(partitioningBy(p -> p.getAge() <= 20));
//打印输出
{
false=[Person{name='mike', age=25}, Person{name='tom', age=30}],
true=[Person{name='jack', age=20}]
}
同样地 partitioningBy 也可以添加一个收集器作为第二参数,进行类似 groupBy 的多重分区等等操作。
11.1分组与分区对比
- 分区:将
stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。 - 分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
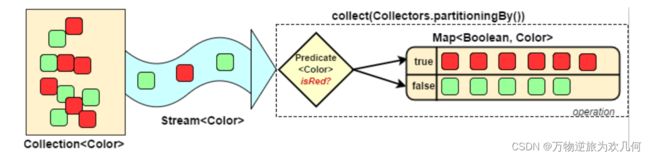
案例:将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
personList.add(new Person("Anni", 8200, "female", "New York"));
personList.add(new Person("Owen", 9500, "male", "New York"));
personList.add(new Person("Alisa", 7900, "female", "New York"));
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
}
}
输出结果:
员工按薪资是否大于8000分组情况:{false=[mutest.Person@2d98a335, mutest.Person@16b98e56, mutest.Person@7ef20235], true=[mutest.Person@27d6c5e0, mutest.Person@4f3f5b24, mutest.Person@15aeb7ab]}
员工按性别分组情况:{female=[mutest.Person@16b98e56, mutest.Person@4f3f5b24, mutest.Person@7ef20235], male=[mutest.Person@27d6c5e0, mutest.Person@2d98a335, mutest.Person@15aeb7ab]}
员工按性别、地区:{female={New York=[mutest.Person@4f3f5b24, mutest.Person@7ef20235], Washington=[mutest.Person@16b98e56]}, male={New York=[mutest.Person@27d6c5e0, mutest.Person@15aeb7ab], Washington=[mutest.Person@2d98a335]}}
12.接合(joining)
joining 连接字符串,也是一个比较常用的方法,对流里面的字符串元素进行连接,其底层实现用的是专门用于字符串连接的 StringBuilder。
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
String s = list.stream().map(Person::getName).collect(joining());
//结果:jackmiketom
String s = list.stream().map(Person::getName).collect(joining(","));
//结果:jack,mike,tom
joining 还有一个比较特别的重载方法:
String s = list.stream().map(Person::getName).collect(joining(" and ", "Today ", " play games."));
//结果:Today jack and mike and tom play games.
即 Today 放开头,play games. 放结尾,and 在中间连接各个字符串。
案例:
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
String names = personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names);
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
}
}
运行结果:
所有员工的姓名:Tom,Jack,Lily
拼接后的字符串:A-B-C
13.归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 每个员工减去起征点后的薪资之和(这个例子并不严谨,但一时没想到好的例子)
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 5000)));
System.out.println("员工扣税薪资总和:" + sum);
// stream的reduce
Optional<Integer> sum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
System.out.println("员工薪资总和:" + sum2.get());
}
}
运行结果:
员工扣税薪资总和:8700
员工薪资总和:23700
14.排序(sorted)
sorted,中间操作。有两种排序:【sorted() / sorted((T, T) -> int)】
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):Comparator排序器自定义排序
注意:如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted() 方法对元素进行排序,如 Stream。反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口
首先我们先创建一个 Person 泛型的 List
List<Person> list = new ArrayList<>();
list.add(new Person("jack", 20));
list.add(new Person("mike", 25));
list.add(new Person("tom", 30));
Person 类包含年龄和姓名两个成员变量
private String name;
private int age;
比如:根据年龄大小来比较:
list = list.stream()
.sorted((p1, p2) -> p1.getAge() - p2.getAge())
.collect(Collectors.toList());
// private int age;
当然这个可以简化为
list = list.stream()
.sorted(Comparator.comparingInt(Person::getAge))
.collect(Collectors.toList());
14.1 数字排序
/**
* 数字排序
*/
public static void testIntegerSort() {
List<Integer> list = Arrays.asList(4, 2, 5, 3, 1);
System.out.println(list);//执行结果:[4, 2, 5, 3, 1]
//升序
list.sort((a, b) -> a.compareTo(b.intValue()));
System.out.println(list);//执行结果:[1, 2, 3, 4, 5]
//降序
list.sort((a, b) -> b.compareTo(a.intValue()));
System.out.println(list);//执行结果:[5, 4, 3, 2, 1]
}
14.2 字符串排序
/**
* 字符串排序
*/
public static void testStringSort() {
List<String> list = new ArrayList<>();
list.add("aa");
list.add("cc");
list.add("bb");
list.add("ee");
list.add("dd");
System.out.println(list);//执行结果:aa, cc, bb, ee, dd
//升序
list.sort((a, b) -> a.compareTo(b.toString()));
System.out.println(list);//执行结果:[aa, bb, cc, dd, ee]
//降序
list.sort((a, b) -> b.compareTo(a.toString()));
System.out.println(list);//执行结果:[ee, dd, cc, bb, aa]
}
14.3字符串排序
/**
* 字符串排序
*/
public static void testStringSort() {
List<String> list = new ArrayList<>();
list.add("aa");
list.add("cc");
list.add("bb");
list.add("ee");
list.add("dd");
System.out.println(list);//执行结果:aa, cc, bb, ee, dd
//升序
list.sort((a, b) -> a.compareTo(b.toString()));
System.out.println(list);//执行结果:[aa, bb, cc, dd, ee]
//降序
list.sort((a, b) -> b.compareTo(a.toString()));
System.out.println(list);//执行结果:[ee, dd, cc, bb, aa]
}
14.4 对象字段排序
class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* 对象串排序
*/
public void testObjectSort() {
List<Person> list = new ArrayList<>();
list.add(new Person("三炮", 48));
list.add(new Person("老王", 35));
list.add(new Person("小明", 8));
list.add(new Person("叫兽", 70));
System.out.println(list); //执行结果:[Person{name='三炮', age=48}, Person{name='老王', age=35}, Person{name='小明', age=8}, Person{name='叫兽', age=70}]
//按年龄升序
list.sort((a, b) -> Integer.compare(a.age, b.getAge()));
System.out.println(list);//执行结果:[Person{name='小明', age=8}, Person{name='老王', age=35}, Person{name='三炮', age=48}, Person{name='叫兽', age=70}]
//按年龄降序
list.sort((a, b) -> Integer.compare(b.age, a.getAge()));
System.out.println(list);//执行结果:[Person{name='叫兽', age=70}, Person{name='三炮', age=48}, Person{name='老王', age=35}, Person{name='小明', age=8}]
//如果按姓名排序,其实就是按字符串排序一样
}
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
public class StreamTest {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Sherry", 9000, 24, "female", "New York"));
personList.add(new Person("Tom", 8900, 22, "male", "Washington"));
personList.add(new Person("Jack", 9000, 25, "male", "Washington"));
personList.add(new Person("Lily", 8800, 26, "male", "New York"));
personList.add(new Person("Alisa", 9000, 26, "female", "New York"));
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream() .sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);
}
}
运行结果:
按工资升序排序:[Lily, Tom, Sherry, Jack, Alisa]
按工资降序排序:[Sherry, Jack, Alisa, Tom, Lily]
先按工资再按年龄升序排序:[Lily, Tom, Sherry, Jack, Alisa]
先按工资再按年龄自定义降序排序:[Alisa, Jack, Sherry, Tom, Lily]
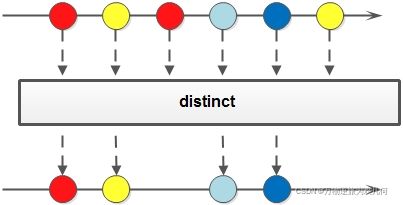
15.去重:distinct()
去除重复元素,这个方法是通过类的 equals 方法来判断两个元素是否相等的。如例子中的 Person 类,需要先定义好 equals 方法,不然类似[Person{name='jack', age=20}, Person{name='jack', age=20}] 这样的情况是不会处理的。
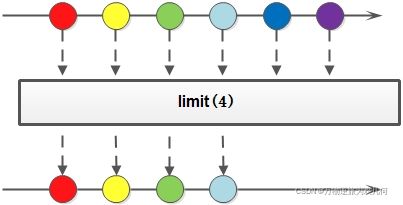
16.限制:limit(long n)
返回前 n 个元素
list = list.stream()
.limit(2)
.collect(Collectors.toList());
//打印输出 [Person{name='jack', age=20}, Person{name='mike', age=25}]
17.去除(跳过)skip(long n)
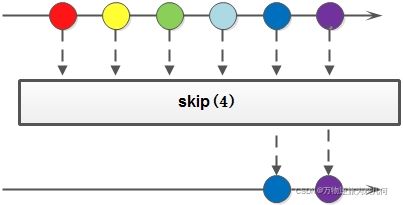
去除前 n 个元素
list = list.stream()
.skip(2)
.collect(Collectors.toList());
//打印输出 [Person{name='tom', age=30}]
tips:
- skip(m)用在 limit(n) 前面时,先去除前 m 个元素再返回剩余元素的前 n 个元素。
- limit(n) 用在 skip(m) 前面时,先返回前 n 个元素再在剩余的 n 个元素中去除 m 个元素。
list = list.stream()
.limit(2)
.skip(1)
.collect(Collectors.toList());
//打印输出 [Person{name='mike', age=25}]
案例:
public class StreamTest {
public static void main(String[] args) {
String[] arr1 = { "a", "b", "c", "d" };
String[] arr2 = { "d", "e", "f", "g" };
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据
List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据
List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("流合并:" + newList);
System.out.println("limit:" + collect);
System.out.println("skip:" + collect2);
}
}
运行结果:
流合并:[a, b, c, d, e, f, g]
limit:[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
skip:[3, 5, 7, 9, 11]
好,以上就是全部内容,能坚持看到这里,你一定很有收获,那么动一动拿offer的小手,点个赞再走吧,听说这么做的人2021年都交了好运!
18.无序unordered()
还有这个比较不起眼的方法,返回一个等效的无序流,当然如果流本身就是无序的话,那可能就会直接返回其本身。
九、数值流
前面介绍的如
int sum = list.stream().map(Person::getAge).reduce(0, Integer::sum); 计算元素总和的方法其中暗含了装箱成本,map(Person::getAge) 方法过后流变成了 Stream 类型,而每个 Integer 都要拆箱成一个原始类型再进行 sum 方法求和,这样大大影响了效率。
针对这个问题 Java 8 有良心地引入了数值流 IntStream, DoubleStream, LongStream,这种流中的元素都是原始数据类型,分别是 int,double,long。
9.1流与数值流的转换
(1)流转换为数值流
- mapToInt(T -> int) : return IntStream
- mapToDouble(T -> double) : return DoubleStream
- mapToLong(T -> long) : return LongStream
IntStream intStream = list.stream().mapToInt(Person::getAge);
1
当然如果是下面这样便会出错
LongStream longStream = list.stream().mapToInt(Person::getAge);
1
因为 getAge 方法返回的是 int 类型(返回的如果是 Integer,一样可以转换为 IntStream)
(2)数值流转换为流
很简单,就一个 boxed
Stream<Integer> stream = intStream.boxed();
1
9.2数值流方法
下面这些方法作用不用多说,看名字就知道:
- sum()
- max()
- min()
- average() 等…
9.3数值范围
IntStream 与 LongStream 拥有 range 和 rangeClosed 方法用于数值范围处理。
- IntStream : rangeClosed(int, int) / range(int, int)
- LongStream : rangeClosed(long, long) / range(long, long)
这两个方法的区别在于一个是闭区间,一个是半开半闭区间:
- rangeClosed(1, 100) :[1, 100]
- range(1, 100) :[1, 100)
我们可以利用 IntStream.rangeClosed(1, 100) 生成 1 到 100 的数值流。
//求 1 到 10 的数值总和:
IntStream intStream = IntStream.rangeClosed(1, 10);
int sum = intStream.sum();
十、Stream的创建
之前我们得到一个流是通过一个原始数据源转换而来,其实我们还可以直接构建得到流。
10.1值创建流
- Stream.of(T…) : Stream.of(“aa”, “bb”) 生成流
//生成一个字符串流
Stream<String> stream = Stream.of("aaa", "bbb", "ccc");
Stream可以通过集合数组创建。
Stream.empty() : 生成空流。
10.2数组创建流
根据参数的数组类型创建对应的流:
- Arrays.stream(T[ ])
- Arrays.stream(int[ ])
- Arrays.stream(double[ ])
- Arrays.stream(long[ ])
值得注意的是,还可以规定只取数组的某部分,用到的是Arrays.stream(T[], int, int)
// 只取索引第 1 到第 2 位的:
int[] a = {1, 2, 3, 4};
Arrays.stream(a, 1, 3).forEach(System.out :: println);
// 打印 2 ,3
10.3集合创建流
通过 java.util.Collection.stream() 方法用集合创建流。
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
10.4文件生成流
Stream<String> stream = Files.lines(Paths.get("data.txt"));
每个元素是给定文件的其中一行。
10.5函数生成流
两个方法(均为静态方法):
- iterate : 依次对每个新生成的值应用函数
- generate :接受一个函数,生成一个新的值
Stream.iterate(0, (x) -> x + 3).limit(4);
//生成流,首元素为 0,之后依次加 3,取前4位
Stream.generate(Math :: random)
//生成流,为 0 到 1 的随机双精度数
Stream.generate(() -> 1)
//生成流,元素全为 1
十一、汇总
1.counting
用于计算总和:
(推荐第二种)
long l = list.stream().collect(counting());
没错,你应该想到了,下面这样也可以:
long l = list.stream().count();
2.summingInt ,summingLong ,summingDouble
summing,没错,也是计算总和,不过这里需要一个函数参数
计算 Person 年龄总和:
(推荐第二种)
int sum = list.stream().collect(summingInt(Person::getAge));
当然,这个可以也简化为:
int sum = list.stream().mapToInt(Person::getAge).sum();
除了上面两种,其实还可以:
int sum = list.stream().map(Person::getAge).reduce(Interger::sum).get();
1
由此可见**,函数式编程通常提供了多种方式来完成同一种操作**。
3.averagingInt,averagingLong,averagingDouble
看名字就知道,求平均数
Double average = list.stream().collect(averagingInt(Person::getAge));
当然也可以这样写
OptionalDouble average = list.stream().mapToInt(Person::getAge).average();
不过要注意的是,这两种返回的值是不同类型的。
4.summarizingInt,summarizingLong,summarizingDouble
这三个方法比较特殊,比如 summarizingInt 会返回 IntSummaryStatistics 类型
IntSummaryStatistics l = list.stream().collect(summarizingInt(Person::getAge));
IntSummaryStatistics 包含了计算出来的平均值,总数,总和,最值,可以通过下面这些方法获得相应的数据

十二、取最值
maxBy,minBy 两个方法,需要一个 Comparator 接口作为参数
Optional<Person> optional = list.stream().collect(maxBy(comparing(Person::getAge)));
我们也可以直接使用 max 方法获得同样的结果
Optional<Person> optional = list.stream().max(comparing(Person::getAge));
十三、并行流parallelStream
我们通过 list.stream() 将 List 类型转换为流类型,我们还可以通过 list.parallelStream() 转换为并行流。
并行流就是把内容分成多个数据块,使用不同的线程分别处理每个数据块的流。这也是流的一大特点,要知道,在 Java 7 之前,并行处理数据集合是非常麻烦的,你得自己去将数据分割开,自己去分配线程,必要时还要确保同步避免竞争。
Stream 让程序员能够比较轻易地实现对数据集合的并行处理,但要注意的是,不是所有情况的适合,有些时候并行甚至比顺序进行效率更低,而有时候因为线程安全问题,还可能导致数据的处理错误,因此并行的性能问题非常值得我们思考。
比方说下面这个例子
int i = Stream.iterate(1, a -> a + 1).limit(100).parallel().reduce(0, Integer::sum);
我们通过这样一行代码来计算 1 到 100 的所有数的和,我们使用了 parallel 来实现并行。
但实际上是,这样的计算,效率是非常低的,比不使用并行还低!一方面是因为装箱问题,这个前面也提到过,就不再赘述,还有一方面就是 iterate 方法很难把这些数分成多个独立块来并行执行,因此无形之中降低了效率。
13.1 流的可分解性
这就说到流的可分解性问题了,使用并行的时候,我们要注意流背后的数据结构是否易于分解。比如众所周知的 ArrayList 和 LinkedList,明显前者在分解方面占优。
我们来看看一些数据源的可分解性情况
| 数据源 | 可分解性 |
|---|---|
| ArrayList | 极佳 |
| LinkedList | 差 |
| IntStream.range | 极佳 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
13.2 顺序性
除了可分解性,和刚刚提到的装箱问题,还有一点值得注意的是一些操作本身在并行流上的性能就比顺序流要差,比如:limit,findFirst,因为这两个方法会考虑元素的顺序性,而并行本身就是违背顺序性的,也是因为如此 findAny 一般比 findFirst 的效率要高。
13.3 stream和parallelStream
stream和parallelStream的简单区分: stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
十四、编程语言与SQL语言
SQL语言也属于是一种编程语言,而变成语言大体可分为四种:命令式,对象式,并发式还有声明式。
1.命令式编程语言
命令式编程语言是最像“编程语言”的语言。
命令式编程语言是几乎所有编程语言所采用的,在命令式编程语言中,程序是若干指令组成的语句。程序员要告知电脑如何运行。
我们学的汇编,C语言这些都是命令式的编程语言。也就所谓的冯•诺伊曼机运行机制,从内存中获取指令和数据,然后一条一条的执行。
类似于命令电脑:先走A,再走B,碰到C以后再返回B……
2.声明式编程语言
声明式语言只描述了程序应该完成的任务,至于如何做,并不管。比如SQL就是这样一种语言,看下面这条语句。
SELECT id FROM qqgroup WHERE driving > 50
这条语句的意思是从QQ群中选出开车次数大于50的人来。只描述了一个任务,至于怎么选,声明式语言并不关心。以结果为导向。
这和我们普通人首次接触的命令式编程语言有非常大的区别。于是,很多人认为SQL语言不是编程语言,或者是一种很奇怪的编程语言。
其实,SQL语句只是声明式编程语言中的一小部分,往细了分,声明式编程语言可以分为以Lisp家庭为代表的函数式编程语言和以Prolog为代表的逻辑式编程语言。
不仅如此,在Java中的annotation和XDoclet库中,采用的也是具有声明式特征的编程。假以时日,也许命令式和声明式语言会互相渗透,尤其是在声明式语言的大本营:人工智能领域,符号处理领域,数理逻辑领域越来越被人重视以后。
SQL语言执行不按顺序来
比如说,SQL查询的时候,一般是这样写:
SELECT + FROM + WHERE + GROUP BY + HAVING + UNION + ORDER BY
但是在执行的过程中,和命令式不一样,执行的顺序又变了
FROM + WHERE + GROUP BY + HAVING + SELECT + UNION + ORDER BY
在写SQL的时候,一定要记住,写的顺序和执行的顺序没什么关系。这一点和命令式编程也有非常大的不同。
3.对象式编程语言
OOP (Object-Oriented Programming),翻译成面向对象其实非常不好,可能是个单身汉翻译的。
我认为我前面讲的命令式语言,声明式语言(包括声明式与逻辑式)想比,OOP并不能单独存在,如果说这三个可以平行并能自成一体独挡一面的话,OOP是与这三者相交的一种编程范式。
命令式和声明式语言,都能融合OOP的范式。C++和Java都是在命令式的基础上发展了OOP,其核心思想是:以数据为中心,将系统划分为相互作用的对象集合。这个思想不仅仅能运用在命令式语言上,也可以运用在函数式语言上和逻辑式语言上,只是将命令式语言中的过程换成函数式语言中的函数,或者逻辑式语言中的断言。
那OOP能和SQL这种声明式语言结合么?
答案是:当然可以!
SQL如何和OOP结合起来?
这种方法叫ORM(Object-Relational Mapping),对象关系映射,这是是一种为了解决OOP与关系数据库存在的互不匹配的现象的技术。
我们都知道,OOP会让编程相对来说更易于理解。
使用了ORM以后,我们可以不用操作表,不用写SQL语句,可以在程序中用面向对象的思路,直接操作对象即可。
几乎所有大型的web框架都实现了ORM,在Ruby on Rails中,实现的方法叫做ActiveRecord。虽然名字各有区别,但是,里面的原理是一样的。