【后端-监控系统】2、prometheus、exporter、grafana、alertmanager 生态超详细介绍
文章目录
- 一、拓扑架构
- 二、exporter
-
- 2.1 node_exporter
-
- 2.1.1 部署
-
- 2.1.1.1 配置、启动
- 2.1.1.2 prometheus 采集数据
- 2.1.1.3 grafana dashboard 配置
- 2.1.2 plugin
-
- 2.1.2.1 用 textfile 集成 shell 的指标
- 2.2 postgres_exporter
- 2.3 redis_exporter
- 2.4 服务内存、CPU监控
- 2.5 golang 用 promauto 暴露变量
- 2.6 漏洞:basic auth
-
- 2.6.0 用 iptables 隔离 exporter
- 2.6.1 用 basic auth 设置 prometheus
-
- 2.6.1.1 创建密码
- 2.6.1.2 新建 web.yml
- 2.6.1.3 启动脚本
- 2.6.1.4 验证登录
- 2.6.1.5 验证 prometheus 的 Targets 可访问到各 exporter
- 2.6.2 grafana 配置 data source 的 basic auth
- 2.6.3 alertmanager 配置 basic auth
- 2.7 blackbox_exporter
- 2.8 pyroscope
- 三、prometheus
-
- 3.1 目录结构
- 3.2 配置文件
- 3.3 启停
-
- 3.3.1 启动
- 3.3.2 重新加载配置文件
- 3.4 运行效果
- 3.5 配置 Targets
-
- 3.5.1 手动配置
- 3.5.2 file_sd
- 3.5.3 http_sd
- 3.6 设置 alert rules
-
- 3.6.1 alert manager
-
- 3.6.1.1 Grouping(聚合)
- 3.6.1.2 Inhibition(抑制)
- 3.6.1.3 Silences(静音)
- 3.6.2 alertmanager 配置
-
- 3.6.2.1 配置文件
- 3.6.2.2 模板文件
- 3.6.2.3 运维API
- 3.6.2.4 鉴权
- 四、grafana
-
- 4.1 部署
- 4.2 配置数据源
-
- 4.2.1 explore view
- 4.3 配置 dash board
- 4.4 配置 panel
-
- 4.4.1 设置数据
-
- 4.4.1.1 Query
- 4.4.1.2 Transform
- 4.4.1.3 Alert
- 4.4.2 设置图表
- 五、alertmanager
- 六、prometheusAlert
- 七、pushgateway
一、拓扑架构

整体生态有四个组件
- exporter 服务,抓取需要的统计数据,并对外提供 http server 来暴露指标
- prometheus 服务,在配置文件中配置各 exporter 的地址 和 抓取时间间隔,其会定期通过 http get 请求获取 exporter 的指标,并存入其内嵌的 TSDB 数据库组件。
- grafana 服务,是一套前端界面,在界面配置 prometheus 数据源,其调用 prometheus 后端提供的 http 接口,展示 prometheus 数据库中的数据到图表组件上。
- alertManager 服务,用于做报警推送
整体架构如下:一个 prometheus 可能对应多个 exporter。
+-----------------------------------------------------------------------------------------------+
| grafana |
+-----------------------------------------------------------------------------------------------+
+-----------------------------------------------------------------------------------------------+
| prometheus |
+-----------------------------------------------------------------------------------------------+
+-----------------+ +----------------+ +------------------+ +------------------+
| node_exporter| | postgres_exporter1 | postgres_exporter2 | app1_exporter |
+-----------------+ +----------------+ +------------------+ +------------------+
二、exporter
2.1 node_exporter
NodeExporter 是 Prometheus 提供的一个可以采集到主机信息的应用程序,它能采集到机器的 CPU、内存、磁盘等信息
2.1.1 部署
2.1.1.1 配置、启动
目录结构如下:
# wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
# root@ubuntu:~/node_exporter/latest# ll -h
total 20M
-rw-r--r-- 1 1001 1002 12K Jul 17 20:15 LICENSE
-rwxr-xr-x 1 1001 1002 20M Jul 17 20:11 node_exporter* # 可看到只有一个二进制文件
-rw-r--r-- 1 1001 1002 463 Jul 17 20:15 NOTICE
启动方式和效果:
root@db:/home/ubuntu/node_exporter-1.1.2.linux-amd64# ./node_exporter --web.listen-address 192.168.2.99:9199 # 注意此处不要写127.0.0.1否则虽能启动但浏览器访问不到http://192.168.2.99:9199/metrics页面
level=info ts=2021-07-07T05:25:03.777Z caller=node_exporter.go:178 msg="Starting node_exporter" version="(version=1.1.2, branch=HEAD, revision=b597c1244d7bef49e6f3359c87a56dd7707f6719)"
level=info ts=2021-07-07T05:25:03.777Z caller=node_exporter.go:179 msg="Build context" build_context="(go=go1.15.8, user=root@f07de8ca602a, date=20210305-09:29:10)"
level=warn ts=2021-07-07T05:25:03.777Z caller=node_exporter.go:181 msg="Node Exporter is running as root user. This exporter is designed to run as unpriviledged user, root is not required."
level=info ts=2021-07-07T05:25:03.778Z caller=filesystem_common.go:74 collector=filesystem msg="Parsed flag --collector.filesystem.ignored-mount-points" flag=^/(dev|proc|sys|var/lib/docker/.+)($|/)
level=info ts=2021-07-07T05:25:03.778Z caller=filesystem_common.go:76 collector=filesystem msg="Parsed flag --collector.filesystem.ignored-fs-types" flag=^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$
level=info ts=2021-07-07T05:25:03.779Z caller=node_exporter.go:106 msg="Enabled collectors"
level=info ts=2021-07-07T05:25:03.779Z caller=node_exporter.go:113 collector=arp
level=info ts=2021-07-07T05:25:03.779Z caller=node_exporter.go:113 collector=cpu
...
level=info ts=2021-07-07T05:25:03.779Z caller=node_exporter.go:113 collector=timex
level=info ts=2021-07-07T05:25:03.779Z caller=node_exporter.go:113 collector=zfs
ts=2023-07-30T00:45:31.254Z caller=tls_config.go:274 level=info msg="Listening on" address=192.168.100.172:9199
ts=2023-07-30T00:45:31.254Z caller=tls_config.go:277 level=info msg="TLS is disabled." http2=false address=192.168.2.99:9199
访问 http://192.168.2.99:9199/metrics 就可以看到如下界面:

每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode. 即 cpu0 上 idle 进程占用 CPU 的总时间,是一个只增不减的度量指标,从类型中也可以看出 node_cpu 的数据类型是计数器(counter)
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average. 即当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge)
# TYPE node_load1 gauge
node_load1 3.0703125
还有如下监控指标:
node_boot_time:系统启动时间
node_cpu:系统CPU使用量
nodedisk*:磁盘IO
nodefilesystem*:文件系统用量
node_load1:系统负载
nodememeory*:内存使用量
nodenetwork*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
2.1.1.2 prometheus 采集数据
为了让 Prometheus Server 能从当前 node exporter 获取到监控数据,需改 prometheus.yml 并在scrape_configs节点下添加以下内容:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'pushgetway'
static_configs:
- targets: ['192.168.100.99:9099']
- job_name: 'node_exporter'
static_configs:
- targets: ['192.168.100.99:9199']
采集到的效果如下:
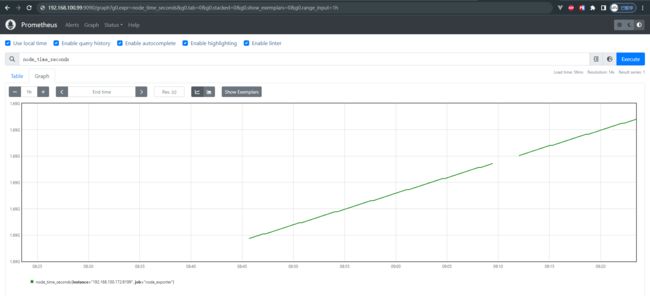
2.1.1.3 grafana dashboard 配置
设置 grafana 看板:在 google 能看到很多样例:

例如这个 dash board,将其导出为 JSON 文件
然后在 grafana 中导入此 JSON,如下图:
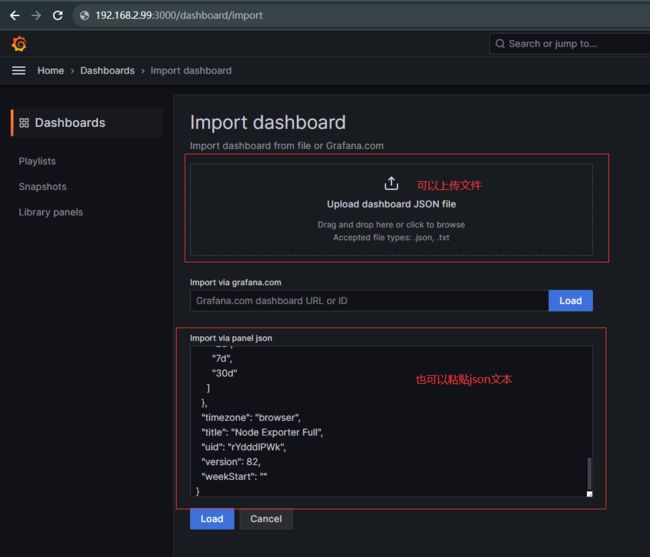
配置后效果如下:
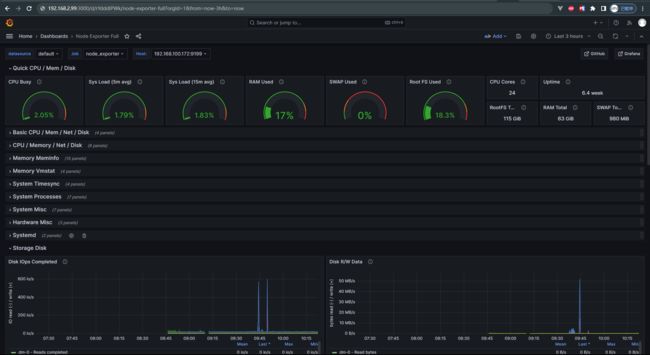
2.1.2 plugin
2.1.2.1 用 textfile 集成 shell 的指标
https://github.com/prometheus/node_exporter

使用方式
2.2 postgres_exporter
下载链接
在启动脚本中通过 DATA_SOURCE_NAME 填写数据库地址:
cat start_postgres_exporter.sh
DATA_SOURCE_NAME="user=postgres dbname=mydb host=192.168.2.99 port=5432 password=postgres sslmode=disable" ./postgres_exporter --web.listen-address=":9287" --extend.query-path="queries.yaml" --log.level=error
运行效果如下:
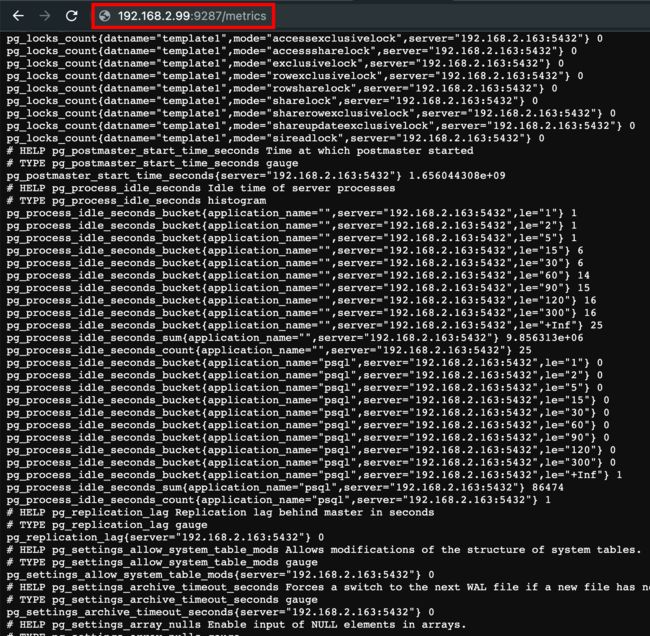
我们可以在 queries.yml 中添加自定义的查询 sql,让 exporter 暴露出来,最终在 grafana 界面添加图表并写 PromQL 即可展示,例如如下 sql:
pg_replication:
query: "SELECT CASE WHEN NOT pg_is_in_recovery() THEN 0 ELSE GREATEST (0, EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))) END AS lag"
master: true
metrics:
- lag:
usage: "GAUGE"
description: "Replication lag behind master in seconds"
pg_postmaster:
query: "SELECT pg_postmaster_start_time as start_time_seconds from pg_postmaster_start_time()"
master: true
metrics:
- start_time_seconds:
usage: "GAUGE"
description: "Time at which postmaster started"
2.3 redis_exporter
在启动脚本中写连接地址
./redis_exporter --redis-addr 192.168.2.99 --redis.password myredispasswd
2.4 服务内存、CPU监控
下载链接

2.5 golang 用 promauto 暴露变量
promauto变量必须被router引用,才能在http接口中暴露出来,有如下2种方式
- 在main.go或router.go中用到了
// metrics/metric.go
package metrics
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
)
var ReqCount = promauto.NewCounter(prometheus.CounterOpts{
Namespace: "app",
Subsystem: "marathon",
Name: "http_request_total",
Help: "total count of http requests",
})
// routers/router.go
var (
a = metrics.ReqCount
)
func NewRouter() *gin.Engine {
gin.DisableConsoleColor()
gin.SetMode(gin.ReleaseMode)
router := gin.New()
router.Use(middlewares.Logger())
router.Use(gin.Recovery())
router.Use(gzip.Gzip(gzip.DefaultCompression))
router.Use(static.ServeRoot("/", "static"))
{
router.GET("/ping", func(ctx *gin.Context) { ctx.String(http.StatusOK, "PONG") })
router.GET("/time", func(ctx *gin.Context) { ctx.String(http.StatusOK, time.Now().Format(time.RFC3339)) })
router.GET("/version", func(ctx *gin.Context) { ctx.String(http.StatusOK, Commit) })
}
pprof.Register(router)
router.GET("/metrics", gin.WrapH(promhttp.Handler()))
api := router.Group("/api")
apiV1 := api.Group("/v1")
biz(apiV1)
return router
}
- 在router的handleFunc中被使用了
// routers/router.go
func biz(r *gin.RouterGroup) {
r.POST("/login", middlewares.Login)
r.POST("/logout", middlewares.LoginAuth, middlewares.Logout)
r.Group("/user").
Use(middlewares.LoginAuth).
GET("", controllers.GetUser)
}
// middlewares/authenticator.go
func LoginAuth(ctx *gin.Context) {
metrics.ReqCount.Inc()
// 获取token
tokenData := ctx.Request.Header.Get("Authorization")
if tokenData == "" {
ctx.Abort()
controllers.Error403(ctx, errors.New("empty authorization"), false)
return
}
}
2.6 漏洞:basic auth
背景:如果系统被部署在甲方,可能常被第三方网络工具扫描到漏洞
方案:给 prometheus 加授权,详见 prometheus 的 basic-auth
2.6.0 用 iptables 隔离 exporter
iptables
2.6.1 用 basic auth 设置 prometheus
详见 iptables 设置
2.6.1.1 创建密码
- 选一个用户名,例如用 admin(当然也可以是任意其他)
- 生成 bcrpy 密码(注意,同样的原文,每次生成的密文可能不同,可用下述网站校验原文与密文是否匹配)
- 方式1:在 bcrypt 网站 生成并检查,如下图
- 方式2:用
python3-bcrypt包生成哈希密码,可以
# apt install python3-bcrypt 安装 python 包
import getpass
import bcrypt
password = getpass.getpass("password: ")
hashed_password = bcrypt.hashpw(password.encode("utf-8"), bcrypt.gensalt())
print(hashed_password.decode())
# python3 gen-pass.py 运行效果如下
# password:
# $2a$12$0ZzhI8c93fqR33XRzw0Yz.4d4TKWiqkolaoL4VY4n5Lr9hfITwNLC

2.6.1.2 新建 web.yml
basic_auth_users:
admin: $2a$12$0ZzhI8c93fqR33XRzw0Yz.4d4TKWiqkolaoL4VY4n5Lr9hfITwNLC # 原文为admin
校验配置文件的合法性:
./promtool check web-config web.yml
web.yml SUCCESS
2.6.1.3 启动脚本
#!/bin/bash
./prometheus --web.config.file="web.yml" --web.listen-address="0.0.0.0:9090" --config.file="./prometheus.yml" --web.max-connections=512 --storage.tsdb.retention.size=500GB --storage.tsdb.path="/data" --log.level=error --web.enable-lifecycle
2.6.1.4 验证登录
再次登录 http://192.168.2.163:9090 即可用 basic auth 访问

- 可在 http://192.168.2.163:9090/graph 看到图表
- 可在 http://192.168.2.163:9090/metrics 看到指标(文本形式)
2.6.1.5 验证 prometheus 的 Targets 可访问到各 exporter
prometheus.yml 配置文档
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
basic_auth:
username: admin
password: admin
static_configs:
- targets: ['localhost:9100', '192.168.2.99:9100']
2.6.2 grafana 配置 data source 的 basic auth
如果改配置的话,grafana 打开 data source 时会报错,如下图所示:

- 如果 grafana 的 prometheus 数据源是手动加的,直接在页面改,如下图

- 如果是通过配置文件加的,就改grafana 配置文件
- 若手动安装则改
conf/provisioning/datasources/sample.yaml - 若apt或yum安装则改
/etc/grafana/provisioning/datasources/sample.yaml
- 若手动安装则改
# 不使用basic auth的配置如下:
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://localhost:9090 # 根据具体的配置修改
# 使用basic auth的配置如下:
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://localhost:9090 # 根据具体的配置修改
user: admin # 根据具体的配置修改(明文)
secureJsonData:
password: admin # 根据具体的配置修改(明文)
最终 grafana 的 dashboard 图表即可如下图正常展示了:

2.6.3 alertmanager 配置 basic auth
一个华人讲解 prometheus 鉴权配置的视频
先按照 alertmanager 的 basic auth 配置 添加 web.yml(内容和上文 prometheus 的 web.yml 内容相同)
再重启 alertmanager:
./alertmanager --config.file=alertmanager.yml --web.config.file=web.yml
再给 prometheus 的 prometheus.yml 配置文件的 alerting 部分 添加 alertmanager 的 basic auth 密码,文档详见prometheus.yml 的 alerting 设置,配置例子如下图左侧部分:

注意:prometheusAlert 不需要配置 鉴权
2.7 blackbox_exporter
blackbox_exporter:The blackbox exporter allows blackbox probing of endpoints over HTTP, HTTPS, DNS, TCP, ICMP and gRPC
2.8 pyroscope
pyroscope:实时分析内存和 cpu
三、prometheus
下载链接
3.1 目录结构
root@db:/home/ubuntu/prometheus-2.28.1.linux-amd64# ll -hS
total 178M
-rwxr-xr-x 1 3434 3434 94M Jul 1 23:22 prometheus*
-rwxr-xr-x 1 3434 3434 84M Jul 1 23:25 promtool*
-rw-r--r-- 1 3434 3434 12K Jul 2 00:29 LICENSE
drwxr-xr-x 4 3434 3434 4.0K Jul 2 00:32 ./
drwxr-xr-x 3 root root 4.0K Jul 7 12:45 ../
drwxr-xr-x 2 3434 3434 4.0K Jul 2 00:29 console_libraries/
drwxr-xr-x 2 3434 3434 4.0K Jul 2 00:29 consoles/
-rw-r--r-- 1 3434 3434 3.6K Jul 2 00:29 NOTICE
-rw-r--r-- 1 3434 3434 926 Jul 2 00:29 prometheus.yml
3.2 配置文件
其中 global.scrape_interval 配置了默认抓取时间间隔为 15s,并在 scrape_configs.job_name 和 scrape_configs.job_name.static_configs.targets 设置了监控数据源的名称和地址,配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'pushgetway'
static_configs:
- targets: ['192.168.2.99:9099']
- job_name: 'postgresqlmy'
static_configs:
- targets: ['192.168.2.99:9287']
- job_name: 'redis_exporter'
static_configs:
- targets: ['192.168.2.99:9121']
- job_name: 'push_gateway' # 非必要组件
static_configs:
- targets: ['192.168.2.99:9099']
3.3 启停
3.3.1 启动
# 设置端口为9090端口
root@db:/home/ubuntu/prometheus-2.28.1.linux-amd64# cat start_prometheus.sh
./prometheus --web.listen-address="0.0.0.0:9090" --config.file="./prometheus.yml" --web.max-connections=512 --storage.tsdb.retention.size=500GB --storage.tsdb.path="/data" --log.level=error --web.enable-lifecycle
3.3.2 重新加载配置文件
kill -HUP 1234 或 curl --location --request POST 'http://192.168.100.99:9090/-/reload'
参考
在浏览器的 http://192.168.2.99:9090/config 可看到配置是否生效
3.4 运行效果
root@db:/home/ubuntu/prometheus-2.28.1.linux-amd64# ./start_prometheus.sh
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:389 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:443 msg="Starting Prometheus" version="(version=2.28.1, branch=HEAD, revision=b0944590a1c9a6b35dc5a696869f75f422b107a1)"
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:448 build_context="(go=go1.16.5, user=root@2915dd495090, date=20210701-15:20:10)"
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:449 host_details="(Linux 4.4.0-131-generic #157-Ubuntu SMP Thu Jul 12 15:51:36 UTC 2018 x86_64 db47 (none))"
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:450 fd_limits="(soft=1024, hard=4096)"
level=info ts=2021-07-07T04:47:52.077Z caller=main.go:451 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2021-07-07T04:47:52.081Z caller=web.go:541 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-07-07T04:47:52.082Z caller=main.go:824 msg="Starting TSDB ..."
level=info ts=2021-07-07T04:47:52.085Z caller=tls_config.go:191 component=web msg="TLS is disabled." http2=false
level=info ts=2021-07-07T04:47:52.089Z caller=head.go:780 component=tsdb msg="Replaying on-disk memory mappable chunks if any"
level=info ts=2021-07-07T04:47:52.089Z caller=head.go:794 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=4.35µs
level=info ts=2021-07-07T04:47:52.089Z caller=head.go:800 component=tsdb msg="Replaying WAL, this may take a while"
level=info ts=2021-07-07T04:47:52.090Z caller=head.go:854 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2021-07-07T04:47:52.090Z caller=head.go:860 component=tsdb msg="WAL replay completed" checkpoint_replay_duration=46.305µs wal_replay_duration=711.241µs total_replay_duration=815.791µs
level=info ts=2021-07-07T04:47:52.092Z caller=main.go:851 fs_type=EXT4_SUPER_MAGIC
level=info ts=2021-07-07T04:47:52.092Z caller=main.go:854 msg="TSDB started"
level=info ts=2021-07-07T04:47:52.092Z caller=main.go:981 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2021-07-07T04:47:52.093Z caller=main.go:1012 msg="Completed loading of configuration file" filename=prometheus.yml totalDuration=951.082µs remote_storage=2.216µs web_handler=401ns query_engine=987ns scrape=414.253µs scrape_sd=45.16µs notify=36.377µs notify_sd=21.834µs rules=1.881µs
level=info ts=2021-07-07T04:47:52.093Z caller=main.go:796 msg="Server is ready to receive web requests."
# 通过ps查看到端口是9090
root@db:/home/ubuntu/pgexp/postgres_exporter/latest# ps -ef | grep prome
nobody 4129 4111 0 11:15 ? 00:00:01 /bin/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus --web.console.libraries=/usr/share/prometheus/console_libraries --web.console.templates=/usr/share/prometheus/consoles
root 4367 1 0 11:16 ? 00:00:00 /bin/bash -c cd /opt/Aegis/prometheus/latest && bash start_prometheus.sh
root 4371 4370 3 11:16 ? 00:01:27 ./prometheus --web.listen-address=0.0.0.0:9090 --config.file=./prometheus.yml --web.max-connections=512 --storage.tsdb.retention.size=500GB --storage.tsdb.path=/data --log.level=error --web.enable-lifecycle
启动后,即可在prometheus的web界面看到个exporter的状态,如下图所示:

最终,在prometheus的web界面可看到,prometheus 已定期抓取指标,并存储在数据库中。效果如下:
- 可以用 prometheus 的 UI 查看 Table 形式的指标:

- 可以用 prometheus 的 UI 查看 Graph 形式的曲线图

重要的是可以用 PromQL 定制化查询,其语法和 SQL 类似。
3.5 配置 Targets
每个 targets 都可以有很多 labels,例如下文的每个 target 都有 type=“box”、boxname=“第一个盒子”、code=“a”、ip=“192.168.100.1” 等四个标签,还会有默认的 job=”box" 标签
3.5.1 手动配置
prometheus.yml 如下
- job_name: 'box'
metrics_path: "/proxy/node_exporter/metrics"
static_configs:
- targets:
- "192.168.100.1:8899"
labels:
type: "box"
boxname: "第一个盒子"
code: "a"
ip: "192.168.100.1"
- "192.168.100.2:8899"
labels:
type: "box"
boxname: "第二个盒子"
code: "b"
ip: "192.168.100.2"
- job_name: 'other_app'
3.5.2 file_sd
prometheus.yml 如下:
- job_name: 'box'
scrape_interval: 2m
metrics_path: "/proxy/node_exporter/metrics"
file_sd_configs:
- files:
- adir/*.yml
- job_name: 'other_app'
并新建 adir/a.yml 和 adir/b.yml 等文件如下(一个机器一个yaml文件,放到这个目录里):
- targets:
- "192.168.100.1:8899"
labels:
type: "box"
boxname: "第一个盒子"
code: "a"
ip: "192.168.100.1"
3.5.3 http_sd
prometheus 支持多种 service discovery 方式,例如可通过 http 接口获取各 exporter 的地址
例如某 a 服务提供 GET 类型的 http 接口(http://192.168.2.a:2112/roles),响应体如下:
[
{
"targets":[
"http://192.168.2.99:8000/api/proxy/metrics"
],
"labels":{
"role_of_machine":"manager"
}
},
{
"targets":[
"http://192.168.2.100:8000/api/proxy/metrics"
],
"labels":{
"role_of_machine":"worker"
}
},
{
"targets":[
"http://192.168.2.101:8000/api/proxy/metrics"
],
"labels":{
"role_of_machine":"just a candidate"
}
}
]
在 prometheus.yml 配置如下 http_sd,则会定时拉取各 exporter 信息(例如上文的 http://192.168.2.99:8000/api/proxy/metrics、http://192.168.2.100:8000/api/proxy/metrics、http://192.168.2.101:8000/api/proxy/metrics):
- job_name: httpsd
metrics_path: api/proxy/metrics
http_sd_configs:
- url: "http://192.168.2.a:2112/roles"
然后,可在 prometheus 的前端界面看到 http_sd 已生效(如下图),其会从各 exporter pull 指标:
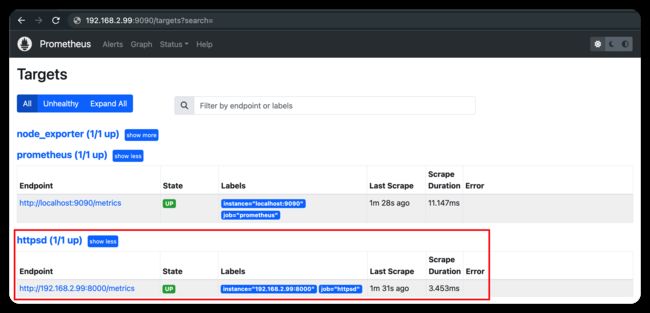
3.6 设置 alert rules
在 prometheus/rules/下放置各 yml文件,可根据采集到的指标,做运算并产生 alert。详见alert rules 文档
整体架构如下:
- prometheus 根据 alert rules 生成 alerts,并发给 alertManager
- alertManager 管理这些 alerts,负责 silencing(静音)、inhibition(抑制)、aggregation(聚合)等操作,并发通知(如email、飞书、钉钉等)
需要如下设置:
- 启动、配置 alertmanager
- 给 prometheus 配 alertmanager 的地址
- 给 prometheus 配 alerting rules
3.6.1 alert manager
alert manager 文档
alert manager 接收 prometheus 的 alerts,做 deduplicating(去重)、grouping(分组)、routing(路由),并发送通知(如email、飞书、钉钉等)
其简要概念如下:详见配置文档
3.6.1.1 Grouping(聚合)
对相似的 alerts 分类(例如大量机器同时宕机,可将几百个消息 group 为一个)。
例如:如果有100个机器组成的集群,突然网络断了,导致都连不上 database 了。而 prometheus 的 alert rules 设置为每当任意 service 连不上 databasse 时均发 alert,就会导致几百个报警。
而对用户来说,需求是有一个页面看到哪些机器宕机了,因此可把 alertmanager 配置为对 alerts 的 cluster_name(集群名)做 group(聚合)。
Grouping of alerts, timing for the grouped notifications, and the receivers of those notifications are configured by a routing tree in the configuration file.
3.6.1.2 Inhibition(抑制)
如果已经产生 alert 了,抑制同类再次产生。
例如:正在触发警报,通知无法访问整个群集。可以将AlertManager配置为在触发特定警报时将「与此群集有关的所有其他警报」静音。这可以防止通知数百或数千个与实际问题无关的触发警报。
在 alertmanager 的配置文件配置。
3.6.1.3 Silences(静音)
alertmanager 对收到的每个 alert 判断是否符合相等或正则表达式,若将此 alert 丢弃。在 alertmanager 的配置文件配置。
3.6.2 alertmanager 配置
alertmanager 配置
通过命令行和配置文件配置,其中命令行标志配置不可变的系统参数,而配置文件定义禁止规则、通知路由和通知接收器。
alert manager routing tree visual editor 可以在线校验配置。
通过给 alertmanager 发 SIGHUP 信号或 POST /-/reload 可以重新加载配置。
3.6.2.1 配置文件
./alertmanager --config.file=alertmanager.yml 指定配置文件,下面是一些常用的占位符:

valid example file 是用法示例。
在 alertmanager/template/email.tmpl 设置如下模板:
{{ define "email.html" }}
receiver: {{ .Receiver }}
开始时间
总结
描述
{{ range .Alerts }}
{{ .StartsAt }}
{{ .Annotations.summary }}
{{ .Annotations.description }}
{{ end }}
{{ end }}
配置示例:
# 全局配置项
global:
resolve_timeout: 5m #处理超时时间,默认为5min
smtp_smarthost: 'smtp.exmail.qq.com:587' # 邮箱smtp服务器代理
smtp_from: '[email protected]' # 发送邮箱名称
smtp_auth_username: '[email protected]' # 邮箱名称
smtp_auth_password: 'xxxxxx' # 授权码
# 定义模板信息
templates:
- 'template/*.tmpl'
# 将报警, 按规则路由到 receivers
route:
group_by: [ 'alertname' ]
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'developer-email'
routes:
- matchers:
- alertname="P3:还有30天到期" # 各matchers按顺序匹配,均支持正则表达式
receiver: 'site-manager-email'
group_interval: 3d
- matchers:
- alertname="P2:还有7天到期"
receiver: 'site-manager-email'
group_interval: 1d
- matchers:
- alertname="P1:还有3天到期"
receiver: 'site-manager-email'
group_interval: 6h
- matchers:
- alertname="P1:还有1天到期"
receiver: 'site-manager-email'
group_interval: 1h
- matchers:
- alertname="^P1|^P2"
group_interval: 5m
repeat_interval: 1h
- matchers:
- alertname="^P3"
group_interval: 5m
repeat_interval: 24h
# 定义 receivers
receivers:
- name: 'developer-email' # 警报
email_configs: # 邮箱配置
- to: '[email protected],[email protected]' # 接收警报的email配置,多个邮箱用“,”分隔
html: '{{ template "email.html" . }}' # 设置邮箱内容模板, 内容见上一节
headers: { Subject: "[WARN] 业务报警邮件 {{.GroupLabels.alertname}}" }# 接收邮件的标题
webhook_configs:
- url: 'http://localhost:8080/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/d39b14dc-5128-4db5-b809-708ff63765c6' # 产生报警时POST调用此下游接口, 下游即会产生飞书报警
# The HTTP client's configuration.
# [ http_config: | default = global.http_config ]
# The maximum number of alerts to include in a single webhook message. Alerts
# above this threshold are truncated. When leaving this at its default value of
# 0, all alerts are included.
# [ max_alerts: | default = 0 ]
- name: 'site-manager-email'
email_configs:
- to: '[email protected],[email protected]'
html: '{{ template "email.html" . }}'
headers: { Subject: "[WARN] 业务报警邮件 {{.GroupLabels.alertname}}" }
webhook_configs:
- url: 'http://localhost:8080/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/d39b14dc-5128-4db5-b809-708ff63765c6'
inhibit_rules:
3.6.2.2 模板文件
模板文件规则
模板文件示例
3.6.2.3 运维API
运维API
3.6.2.4 鉴权
鉴权
四、grafana
4.1 部署
官网下载地址
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.3.linux-amd64.tar.gz
tar -zxvf grafana-enterprise-10.0.3.linux-amd64.tar.gz
root@ubuntu:/home/ubuntu/grafana/latest# du -sh ./*
128M ./bin
200M ./public # 前端页面
216K ./conf
12K ./LICENSE
60K ./plugins-bundled
root@ubuntu:/home/ubuntu/grafana/latest# ll -h bin
total 128M
-rwxr-xr-x 1 root root 125M Jul 26 03:57 grafana*
-rwxr-xr-x 1 root root 1.5M Jul 26 03:57 grafana-cli*
-rwxr-xr-x 1 root root 1.5M Jul 26 03:57 grafana-server*
root@ubuntu:/home/ubuntu/grafana/latest# ll -h conf
total 160K
-rw-r--r-- 1 root root 74K Jul 26 03:57 defaults.ini
-rw-r--r-- 1 root root 1.1K Jul 26 03:57 ldap_multiple.toml
-rw-r--r-- 1 root root 3.0K Jul 26 03:57 ldap.toml
drwxr-xr-x 8 root root 4.0K Jul 26 03:57 provisioning/
-rw-r--r-- 1 root root 72K Jul 26 03:57 sample.ini
root@ubuntu:/home/ubuntu/grafana/latest# ll plugins-bundled/
total 4
drwxr-xr-x 3 root root 4096 Jul 26 03:57 internal/
grafana 配置文件路径
- 启动日志
root@ubuntu:/home/ubuntu/grafana/latest# bin/grafana server web
Grafana server is running with elevated privileges. This is not recommended
INFO [07-30|09:49:20] Starting Grafana logger=settings version=10.0.3 commit=eb8dd72637 branch=HEAD compiled=2023-07-26T01:55:59+08:00
WARN [07-30|09:49:20] "sentry" frontend logging provider is deprecated and will be removed in the next major version. Use "grafana" provider instead. logger=settings
INFO [07-30|09:49:20] Config loaded from logger=settings file=/home/ubuntu/grafana/latest/conf/defaults.ini
INFO [07-30|09:49:20] Target logger=settings target=[all]
INFO [07-30|09:49:20] Path Home logger=settings path=/home/ubuntu/grafana/latest
INFO [07-30|09:49:20] Path Data logger=settings path=/home/ubuntu/grafana/latest/data
INFO [07-30|09:49:20] Path Logs logger=settings path=/home/ubuntu/grafana/latest/data/log
INFO [07-30|09:49:20] Path Plugins logger=settings path=/home/ubuntu/grafana/latest/data/plugins
INFO [07-30|09:49:20] Path Provisioning logger=settings path=/home/ubuntu/grafana/latest/conf/provisioning
INFO [07-30|09:49:20] App mode production logger=settings
INFO [07-30|09:49:20] Connecting to DB logger=sqlstore dbtype=sqlite3
INFO [07-30|09:49:20] Creating SQLite database file logger=sqlstore path=/home/ubuntu/grafana/latest/data/grafana.db
INFO [07-30|09:49:20] Starting DB migrations logger=migrator
INFO [07-30|09:49:20] Executing migration logger=migrator id="create migration_log table"
INFO [07-30|09:49:20] Executing migration logger=migrator id="create user table"
INFO[07-07|14:02:50] External plugins directory created logger=plugins directory=/home/ubuntu/grafana/grafana-8.0.4/data/plugins
INFO [07-30|09:49:40] starting logger=ticker first_tick=2023-07-30T09:49:50+08:00
INFO [07-30|09:49:40] HTTP Server Listen logger=http.server address=[::]:3000 protocol=http subUrl= socket=
INFO [07-30|09:49:40] Update check succeeded logger=plugins.update.checker duration=525.67157ms
4.2 配置数据源
旧版本(8.x.x)配置页面如下:

新版本(10.x.x)配置页面如下:


配置成功后会提示如下,再配置 dash board 或 explore view(简单查询)均可:

4.2.1 explore view
例如 explore view 效果如下,只需填 metric、instance,即可将时段内、该指标的曲线展示为如下效果:

4.3 配置 dash board
在 google 搜 grafana dashboard example 找例子:
或在 grafana dashboard 中找 example:

grafana 8.x.x 可用如下模板
DashBoard 是由若干 Panel 图表组成的:

如果导入了 grafana 的 JSON 监控模板,但曲线图却无数据,一定是 PromQL 未成功,可以从两方面排查:
- 排查思路1:在 prometheus 中查看 PromQL 是否成功,例如下图即为在 prometheus 中查看 pg_stat_database_tup_fetched,若能查出结果才正常
- 排查思路2:在 DashBoard 的 Settings => Variables,查看环境变量是否有值。如下图中的 host 变量,若能在 preview of values 中有值则说明正常。

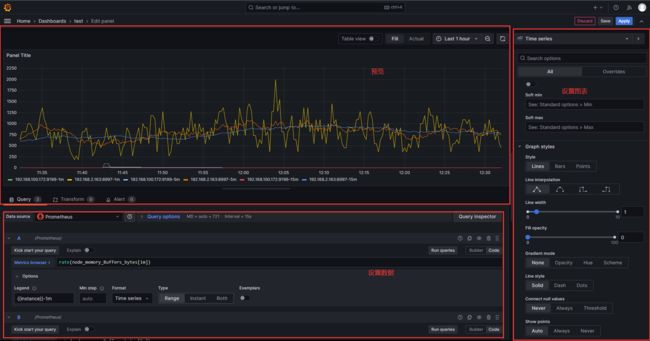
4.4 配置 panel
anel(图表)是 Prometheus 中数据呈现的最小单元,我们看到的面板数据,都是由一个个图表构成的。图表(Panel)的设置区域分为预览、设置数据、设置图表三个区域:
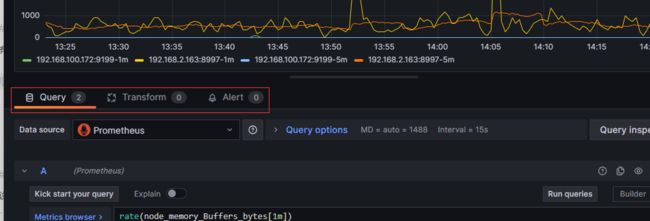
4.4.1 设置数据
有 Query、Transform、Alert 三种配置:
4.4.1.1 Query
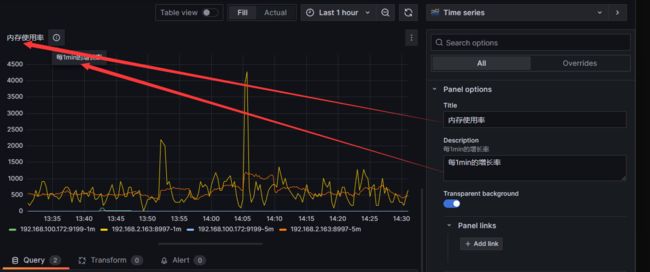
设置效果如下图,包括如下配置项:
- Metrics 指标名称:例如 rate(node_memory_bytes[1m]) 即每分钟的增长率,可用 builder 或 code 配置
- Legend 图例:例如可设置 {{instance}}-1m 标识最近 1min、{{instance}}-5m 标识最近 5min
- MinStep 最小步长:即图中两点的最小间隔
- Format 数据源的格式:Time series 是时序数据、Table 是表格数据、Heap Map 是热力图数据

4.4.1.2 Transform
4.4.1.3 Alert
4.4.2 设置图表
有很多种类图表:

panel options 可设置图表名称:
tooltip:当鼠标悬浮时,all 显示所有线,single 只显示一条线。


legend:控制图例

Axis:设置横纵轴

Graph style:设置曲线的形状,是否展示点

Standard options:设置纵轴标准化到什么单位

Threshold:设置阈值,如下图三条阈值虚线和背景色

五、alertmanager
alertmanager 和 prometheus 交互的流程
在 alertmanager 的配置文件,可发 email,也可调用 prometheusAlert 的 飞书/钉钉 webhook
六、prometheusAlert
prometheusAlert
用于发送飞书/钉钉等 现代方式报警
参考prometheus官网文档
参考文章
七、pushgateway
The Prometheus Pushgateway exists to allow ephemeral(短暂) and batch jobs to expose their metrics to Prometheus. Since these kinds of jobs may not exist long enough to be scraped, they can instead push their metrics to a Pushgateway. The Pushgateway then exposes these metrics to Prometheus
官网