大数据离线数仓开发项目详细教程
目录
一、数据准备/opt/eventdata
二、环境准备
三、创建Kafka的topic主题
四、使用Flume将文件采集到Kafka
(一)在/opt/soft/flume190/conf/目录下创建events文件夹,并创建5个conf文件
(二)events.conf
(三)ea.conf
1.ea.conf脚本内容:
2开启flume
3.复制文件到指定目录
4.查看event_attendees_raw主题的消息数量
(四)users.conf
1.users.conf脚本内容:
2.开启flume
3.复制文件到指定目录
4.查看users主题的消息数量
(五)uf.conf
1.uf.conf脚本内容:
2.开启flume
3.复制文件到指定目录
4.查看user_friends_raw主题的消息数量
(六)train.conf
1.train.conf脚本内容:
2.开启flume
3.复制文件到指定目录
4.查看train主题的消息数量
五、使用java对Kafka中的消息进行清洗,传入Kafka中
六、将Kafka清洗后的数据存入HBase中
七、建立Hive表,映射HBase的数据
(一)DWD层
1.dwd_events库
2.users表
3.events表
4.user_friend表
5.event_attendee表
6.train表
7.locale表
8.time_zone表
9.dwd_events中的表
(二)DWS层——Hive实现
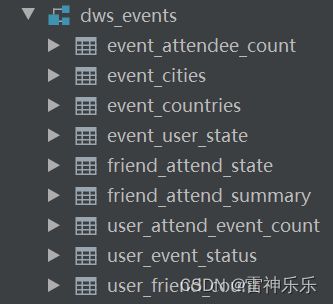
1.dws_events库
2.user_friend_count表——每个用户的朋友的数量
3.event_attendee_count表——每个事件发生后的出席情况
4.event_user_state表——每个事件邀请的朋友的应邀情况
5.user_event_status表——event_user_state表的数据梳理
6.user_attend_event_count表——查看每个用户分别对事件的邀请参加、不参加的数量的统计
7.friend_attend_state表——统计应邀情况
8.friend_attend_summary表——求用户朋友中针对某一件事情的状态数量 多少人被邀请,多少人参加,多少人不参加,多少人可能去参加
9.event_cities表——找出事件发生最多的前32个的城市
10.event_countries表——找出事件发生最多的前8个国家
11.dws层的表
(三)DWS层——spark实现
1.环境搭建
2.user_friend_count表——每个用户的朋友的数量
3.event_attendee_count表———每个用户的朋友的数量
4.event_user_state表——每个事件邀请的朋友的应邀情况
5.user_event_status表——event_user_state表的数据梳理
6.user_attend_event_count表——查看每个用户分别对事件的邀请参加、不参加的数量的统计
7.friend_attend_state表——统计应邀情况
8.friend_attend_summary表——求用户朋友中针对某一件事情的状态数量 多少人被邀请,多少人参加,多少人不参加,多少人可能去参加
9.event_cities表——找出事件发生最多的前32个的城市
10.event_countries表——找出事件发生最多的前8个国家
11.验证是否存入成功
(四)DM层——宽表明细层
1.dm_events库
2.user_event_1表——每个事件发生的国家、城市等信息
一、数据准备/opt/eventdata

二、环境准备
开启hadoop、hive、mysql、zookeeper、kafka、hbase
三、创建Kafka的topic主题
➢ Users
kafka-topics.sh --zookeeper lxm147:2181 --create --topic users --partitions 1 -replication-factor 1
➢ User_Friends
kafka-topics.sh --zookeeper lxm147:2181 --create --topic user_friends --partitions 1 -replication-factor 1
➢ user_friends_raw
kafka-topics.sh --zookeeper lxm147:2181 --create --topic user_friends_raw --partitions 1 --replication-factor 1
➢ Events
kafka-topics.sh --zookeeper lxm147:2181 --create --topic events --partitions 1 --replication-factor 1
➢ Event_Attendees
kafka-topics.sh --zookeeper lxm147:2181 --create --topic event_attendees --partitions 1 --replication-factor 1
➢ event_attendees_raw
kafka-topics.sh --zookeeper lxm147:2181 --create --topic event_attendees_raw --partitions 1 --replication-factor 1
➢ Train
kafka-topics.sh --zookeeper lxm147:2181 --create --topic train --partitions 1 -replication-factor 1
➢ Test
kafka-topics.sh --zookeeper lxm147:2181 --create --topic test --partitions 1 --replication-factor 1四、使用Flume将文件采集到Kafka
(一)在/opt/soft/flume190/conf/目录下创建events文件夹,并创建5个conf文件
[root@lxm147 events]# pwd
/opt/soft/flume190/conf/events
[root@lxm147 events]# ls
ea.conf events.conf train.conf uf.conf users.conf(二)events.conf
参考文章:《Flume采集数据到Kafka操作详解》
后面的采集任务与该篇博文中的方法是一样的!
(三)ea.conf
1.ea.conf脚本内容:
ea.sources=eaSource
ea.channels=eaChannel
ea.sinks=eaSink
ea.sources.eaSource.type=spooldir
ea.sources.eaSource.spoolDir=/opt/flumelogfile/ea
ea.sources.eaSource.deserializer=LINE
ea.sources.eaSource.deserializer.maxLineLength=320000
ea.sources.eaSource.includePattern=ea_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
ea.sources.eaSource.interceptors=head_filter
ea.sources.eaSource.interceptors.head_filter.type=regex_filter
ea.sources.eaSource.interceptors.head_filter.regex=^event*
ea.sources.eaSource.interceptors.head_filter.excludeEvents=true
ea.channels.eaChannel.type=file
ea.channels.eaChannel.checkpointDir=/opt/flumelogfile/checkpoint/ea
ea.channels.eaChannel.dataDirs=/opt/flumelogfile/data/ea
ea.sinks.eaSink.type=org.apache.flume.sink.kafka.KafkaSink
ea.sinks.eaSink.batchSize=640
ea.sinks.eaSink.brokerList=LINE
ea.sinks.eaSink.brokerList=192.168.180.147:9092
ea.sinks.eaSink.topic=event_attendees_raw
ea.sources.eaSource.channels=eaChannel
ea.sinks.eaSink.channel=eaChannel
2开启flume
[root@lxm147 flume190]# ./bin/flume-ng agent --name ea --conf ./conf/ --conf-file ./conf/events/ea.conf -Dflume.root.logger=INFO,console3.复制文件到指定目录
cp /opt/eventdata/event_attendees.csv /opt/flumelogfile/events/ea_2023-04-01.csv4.查看event_attendees_raw主题的消息数量
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list lxm147:9092 --topic event_attendees_raw
event_attendees_raw:0:24144(四)users.conf
1.users.conf脚本内容:
users.sources=usersSource
users.channels=usersChannel
users.sinks=userSink
users.sources.usersSource.type=spooldir
users.sources.usersSource.spoolDir=/opt/flumelogfile/users
users.sources.usersSource.deserializer=LINE
users.sources.usersSource.deserializer.maxLineLength=320000
users.sources.usersSource.includePattern=user_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
users.sources.usersSource.interceptors=head_filter
users.sources.usersSource.interceptors.head_filter.type=regex_filter
users.sources.usersSource.interceptors.head_filter.regex=^user_id*
users.sources.usersSource.interceptors.head_filter.excludeEvents=true
users.channels.usersChannel.type=file
users.channels.usersChannel.checkpointDir=/opt/flumelogfile/checkpoint/users
users.channels.usersChannel.dataDirs=/opt/flumelogfile/data/users
users.sinks.userSink.type=org.apache.flume.sink.kafka.KafkaSink
users.sinks.userSink.batchSize=640
users.sinks.userSink.brokerList=192.168.180.147:9092
users.sinks.userSink.topic=users
users.sources.usersSource.channels=usersChannel
users.sinks.userSink.channel=usersChannel2.开启flume
[root@lxm147 flume190]# ./bin/flume-ng agent --name users --conf ./conf/ --conf-file ./conf/events/users.conf -Dflume.root.logger=INFO,console3.复制文件到指定目录
cp /opt/eventdata/users.csv /opt/flumelogfile/events/users_2023-04-01.csv4.查看users主题的消息数量
[root@lxm147 events]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list lxm147:9092 --topic users
users:0:38209
(五)uf.conf
1.uf.conf脚本内容:
userfriends.sources=userfriendsSource
userfriends.channels=userfriendsChannel
userfriends.sinks=userfriendsSink
userfriends.sources.userfriendsSource.type=spooldir
userfriends.sources.userfriendsSource.spoolDir=/opt/flumelogfile/uf
userfriends.sources.userfriendsSource.deserializer=LINE
userfriends.sources.userfriendsSource.deserializer.maxLineLength=320000
userfriends.sources.userfriendsSource.includePattern=uf_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
userfriends.sources.userfriendsSource.interceptors=head_filter
userfriends.sources.userfriendsSource.interceptors.head_filter.type=regex_filter
userfriends.sources.userfriendsSource.interceptors.head_filter.regex=^user*
userfriends.sources.userfriendsSource.interceptors.head_filter.excludeEvents=true
userfriends.channels.userfriendsChannel.type=file
userfriends.channels.userfriendsChannel.checkpointDir=/opt/flumelogfile/checkpoint/uf
userfriends.channels.userfriendsChannel.dataDirs=/opt/flumelogfile/data/uf
userfriends.sinks.userfriendsSink.type=org.apache.flume.sink.kafka.KafkaSink
userfriends.sinks.userfriendsSink.batchSize=640
userfriends.sinks.userfriendsSink.brokerList=192.168.180.147:9092
userfriends.sinks.userfriendsSink.topic=user_friends_raw
userfriends.sources.userfriendsSource.channels=userfriendsChannel
userfriends.sinks.userfriendsSink.channel=userfriendsChannel2.开启flume
[root@lxm147 flume190]# ./bin/flume-ng agent --name userfriends --conf ./conf/ --conf-file ./conf/events/uf.conf -Dflume.root.logger=INFO,console3.复制文件到指定目录
cp /opt/eventdata/user_friends.csv /opt/flumelogfile/events/uf_2023-04-01.csv4.查看user_friends_raw主题的消息数量
[root@lxm147 flumelogfile]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list lxm147:9092 --topic user_friends_raw
user_friends_raw:0:38202(六)train.conf
1.train.conf脚本内容:
train.sources=trainSource
train.channels=trainChannel
train.sinks=trainSink
train.sources.trainSource.type=spooldir
train.sources.trainSource.spoolDir=/opt/flumelogfile/train
train.sources.trainSource.deserializer=LINE
train.sources.trainSource.deserializer.maxLineLength=320000
train.sources.trainSource.includePattern=train_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
train.sources.trainSource.interceptors=head_filter
train.sources.trainSource.interceptors.head_filter.type=regex_filter
train.sources.trainSource.interceptors.head_filter.regex=^user*
train.sources.trainSource.interceptors.head_filter.excludeEvents=true
train.channels.trainChannel.type=file
train.channels.trainChannel.checkpointDir=/opt/flumelogfile/checkpoint/train
train.channels.trainChannel.dataDirs=/opt/flumelogfile/data/train
train.sinks.trainSink.type=org.apache.flume.sink.kafka.KafkaSink
train.sinks.trainSink.batchSize=640
train.sinks.trainSink.brokerList=LINE
train.sinks.trainSink.brokerList=192.168.180.147:9092
train.sinks.trainSink.topic=train
train.sources.trainSource.channels=trainChannel
train.sinks.trainSink.channel=trainChannel2.开启flume
[root@lxm147 flume190]# ./bin/flume-ng agent --name train --conf ./conf/ --conf-file ./conf/events/train.conf -Dflume.root.logger=INFO,console3.复制文件到指定目录
cp /opt/eventdata/train.csv /opt/flumelogfile/events/train_2023-04-01.csv4.查看train主题的消息数量
[root@lxm147 flumelogfile]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list lxm147:9092 --topic train
train:0:15398
五、使用java对Kafka中的消息进行清洗,传入Kafka中
参考博文《KafkaStream——Spark对Kafka的数据进行清洗(java语言编写)》
六、将Kafka清洗后的数据存入HBase中
参考博文《日志项目之——将kafka数据存入hbase中》
七、建立Hive表,映射HBase的数据
(一)DWD层
1.dwd_events库
create database if not exists dwd_events;
use dwd_events;
// 开启动态分区
// 基本的优化配置
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.optimize.sort.dynamic.partition=true;
// 关闭map端优化
set hive.auto.convert.join=false;2.users表
// hive 外部表映射HBase
drop table if exists hb_users;
create external table hb_users
(
userid string,
birthyear int,
gender string,
locale string,
location string,
timezone string,
joinedat string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with SERDEPROPERTIES
('hbase.columns.mapping' =
':key,profile:birthyear,profile:gender,region:locale,region:location,region:timezone,registration:joinedAt')
tblproperties ('hbase.table.name' = 'events_db:users');
// 创建一个内部表,存放格式为orc格式
create table users stored as orc as select * from hb_users;
drop table if exists hb_users;
select * from users;
3.events表
drop table if exists hb_events;
create external table hb_events
(
eventid string,
userid string,
starttime string,
city string,
state string,
zip string,
country string,
lat float,
lng float,
commonwords string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with SERDEPROPERTIES
('hbase.columns.mapping' =
':key,creator:userid,schedule:starttime,location:city,location:state,location:zip,location:country,location:lat,location:lng,remark:commonwords')
tblproperties ('hbase.table.name' = 'events_db:events');
set mapreduce.framework.name=local;
set hive.exec.mode.local.auto=true;
create table if not exists events stored as orc as select * from hb_events;
select * from events;
drop table if exists hb_events;

4.user_friend表
drop table if exists hb_user_friend;
create external table if not exists hb_user_friend
(
rowkey string,
userid string,
friendid string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with SERDEPROPERTIES
('hbase.columns.mapping' =
':key,uf:user_id,uf:friend_id')
tblproperties ('hbase.table.name' = 'events_db:user_friend');
create table if not exists user_friend stored as orc as select * from hb_user_friend;
select count(*) from user_friend;// 30279525
select * from hb_user_friend;
drop table if exists hb_user_friend;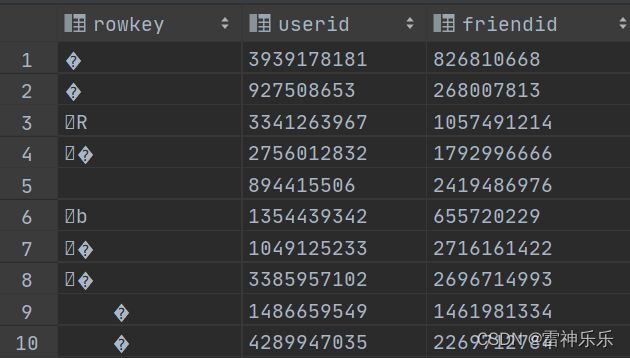
5.event_attendee表
drop table if exists hb_event_attendee;
create external table hb_event_attendee
(
rowkey string,
eventid string,
friendid string,
attendtype string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with SERDEPROPERTIES
('hbase.columns.mapping' =
':key,euat:eventid,euat:friendid,euat:state')
tblproperties ('hbase.table.name' = 'events_db:event_attendee');
create table event_attendee stored as orc as select * from hb_event_attendee;
select * from event_attendee;
drop table if exists hb_event_attendee;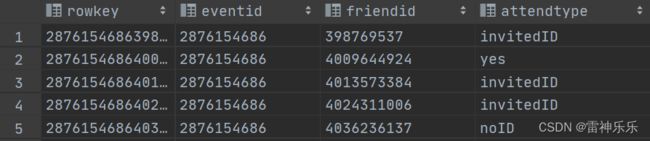
6.train表
drop table if exists hb_train;
create external table if not exists hb_train
(
rowkey string,
userid string,
eventid string,
invited string,
`timestamp` string,
interested string
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with SERDEPROPERTIES
('hbase.columns.mapping' =
':key,eu:user,eu:event,eu:invited,eu:timestamp,eu:interested')
tblproperties ('hbase.table.name' = 'events_db:train');
create table train stored as orc as select * from hb_train;
select count(*) from train;// 15398
drop table if exists hb_train;
select * from train;
7.locale表
create external table locale(
locale_id int,
locale string
)row format delimited fields terminated by '\t'
location '/events/ods/data/locale';
select * from locale;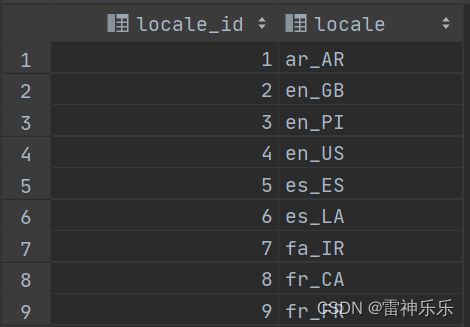
8.time_zone表
create external table time_zone(
time_zone_id int,
time_zone string
)row format delimited fields terminated by ','
location '/events/ods/data/timezone';
select * from time_zone;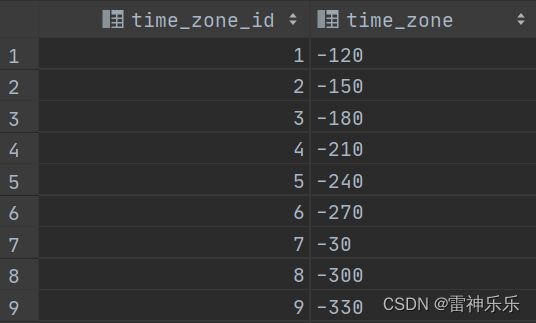
9.dwd_events中的表
(二)DWS层——Hive实现
注意:事务表必须用orc格式。
1.dws_events库
-- 用户兴趣取向分析
-- 用户userid 事件eventid 用户是否某一事件感兴趣/不感兴趣
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.optimize.sort.dynamic.partition=true;
set hive.auto.convert.join=false;
create database if not exists dws_events;
use dws_events;2.user_friend_count表——每个用户的朋友的数量
-- 计算每一个用户朋友的数量是多少
-- user_friend 得到每一个用户朋友的数量
create table user_friend_count stored as orc as
select userid,
count(friendid) friendcount
from dwd_events.user_friend
where friendid is not null
and trim(friendid) != ''
group by userid;
select *
from user_friend_count
limit 10;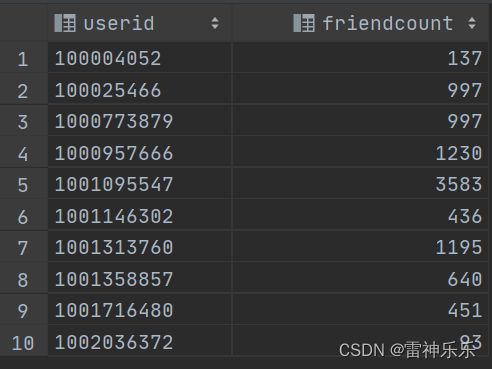
3.event_attendee_count表——每个事件发生后的出席情况
create table event_attendee_count stored as orc as
select eventid,
attendtype,
count(friendid) attendCount
from dwd_events.event_attendee
group by eventid, attendtype;
select *
from event_attendee_count
limit 10;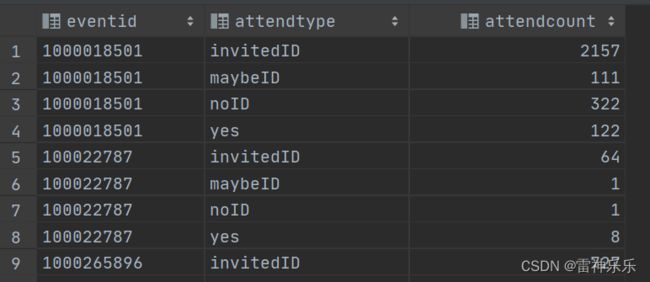
接下来,要改变表的形式:
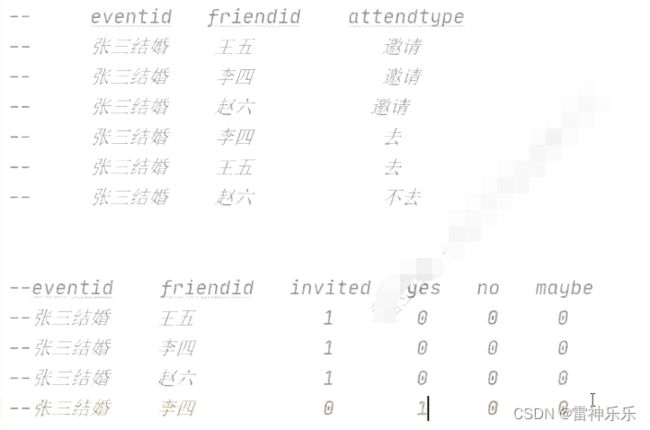
4.event_user_state表——每个事件邀请的朋友的应邀情况
create table if not exists dws_events.event_user_state
stored as orc as
select eventid,
friendid,
case when attendtype = 'invitedID' then 1 else 0 end as invited,
case when attendtype = 'yes' then 1 else 0 end as yes,
case when attendtype = 'noID' then 1 else 0 end as no,
case when attendtype = 'maybeID' then 1 else 0 end as maybe
from dwd_events.event_attendee;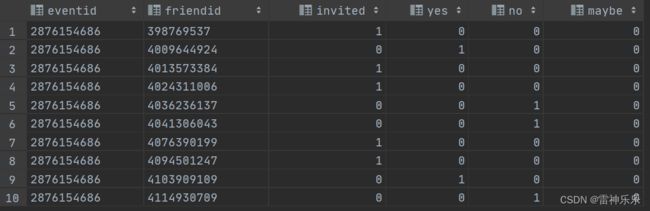
5.user_event_status表——event_user_state表的数据梳理
create table if not exists user_event_status stored as orc as
select t1.friendid attend_userid,
t1.eventid,
max(t1.invited) invited,
max(t1.yes) attended,
max(t1.no) not_attended,
max(t1.maybe) maybe_attended
from event_user_state t1
group by t1.eventid, t1.friendid;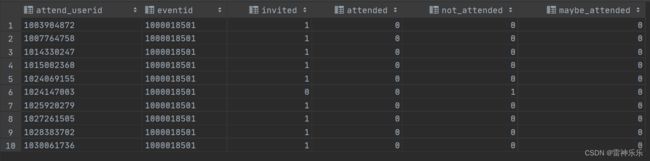
6.user_attend_event_count表——查看每个用户分别对事件的邀请参加、不参加的数量的统计

create table if not exists user_attend_event_count stored as orc as
select attend_userid,
sum(invited) as invited_count,
sum(attended) as attended_count,
sum(not_attended) as not_attended_count,
sum(maybe_attended) as maybe_attended_count
from user_event_status
group by attend_userid;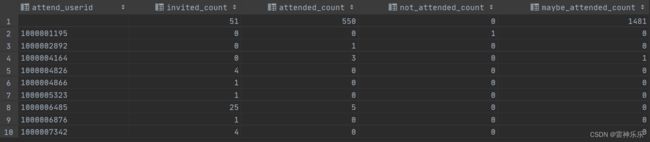
7.friend_attend_state表——统计应邀情况
dwd_events.user_friend表:
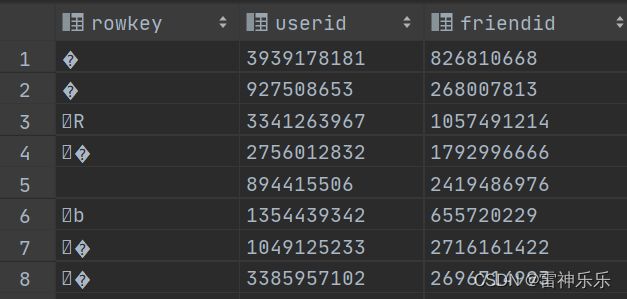
dws_events.user_event_status表:

上述两表关联,统计应邀情况
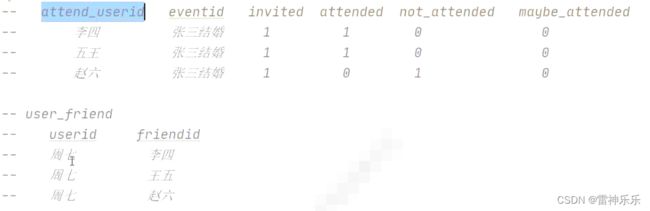
create table if not exists friend_attend_state stored as orc as
select uf.userid,
uf.friendid,
ues.eventid,
case when ues.invited > 0 then 1 else 0 end as invited,
case when ues.attended > 0 then 1 else 0 end as attended,
case when ues.not_attended > 0 then 1 else 0 end as not_attended,
case when ues.maybe_attended > 0 then 1 else 0 end as maybe_attended
from dwd_events.user_friend uf
left join dws_events.user_event_status ues on ues.attend_userid = uf.friendid;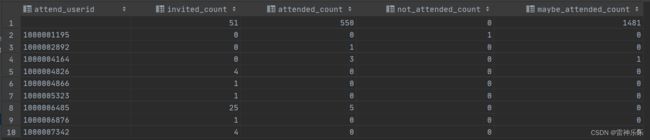
8.friend_attend_summary表——求用户朋友中针对某一件事情的状态数量 多少人被邀请,多少人参加,多少人不参加,多少人可能去参加
create table if not exists friend_attend_summary stored as orc as
select userid,
eventid,
sum(invited) invited_friends_count,
sum(attended) attended_friends_count,
sum(not_attended) not_attended_friends_count,
sum(maybe_attended) maybe_attended_friends_count
from friend_attend_state
where eventid is not null
group by userid, eventid;
9.event_cities表——找出事件发生最多的前32个的城市
create table if not exists event_cities stored as orc as
select case when t.city <> '' then t.city else 'nocity' end city,
-- if(t.city <> '', t.city, 'nocity'),
t.count,
row_number() over (order by t.count desc ) as level
from (
select city,
count(*) count
from dwd_events.events
-- where city is not null and city != ''
group by city
order by count desc
limit 32) t;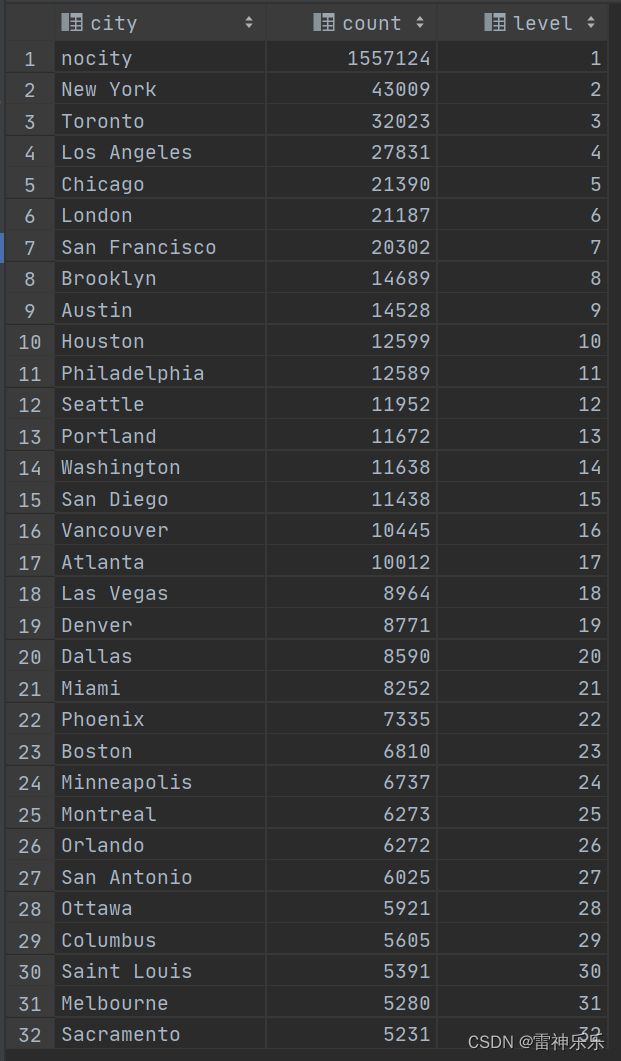
10.event_countries表——找出事件发生最多的前8个国家
create table if not exists event_countries stored as orc as
select case when t.country <> '' then t.country else 'nocountry' end as country,
t.count,
row_number() over (order by t.count desc ) level
from (
select country,
count(*) count
from dwd_events.events
group by country
order by count desc
limit 8) t;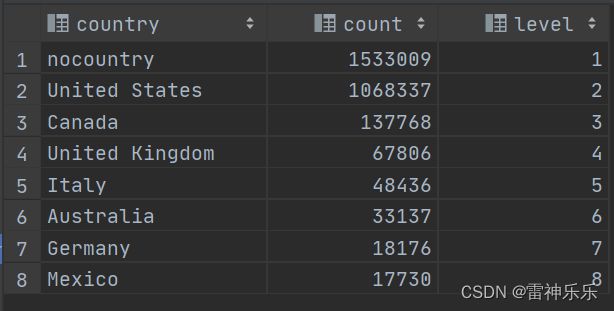
11.dws层的表
(三)DWS层——spark实现
1.环境搭建
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object SparkToHive {
def main(args: Array[String]): Unit = {
// spark读取hive表
val spark: SparkSession = SparkSession.builder().appName("sparkhive")
.master("local[*]")
.config("hive.metastore.uris", "thrift://192.168.180.147:9083")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
spark.close()
}
}2.user_friend_count表——每个用户的朋友的数量
val user_friend: DataFrame = spark.table("dwd_events.user_friend")
user_friend.show(10, false)
/*
+------+----------+----------+
|rowkey|userid |friendid |
+------+----------+----------+
| � |3939178181|826810668 |
| � |927508653 |268007813 |
| R |3341263967|1057491214|
| � |2756012832|1792996666|
| |894415506 |2419486976|
| b |1354439342|655720229 |
| � |1049125233|2716161422|
| � |3385957102|2696714993|
| � |1486659549|1461981334|
| � |4289947035|2269712784|
+------+----------+----------+ */
val user_friend_count: DataFrame = user_friend
.where(col("friendid").isNotNull and trim($"friendid") =!= "")
.groupBy("userid")
.agg(count("friendid").as("friendcount"))
.select($"userid", $"friendcount")
user_friend_count.show(10)
/*
+----------+-----------+
| userid|friendcount|
+----------+-----------+
|1890034372| 4211|
|1477282294| 1057|
| 59413733| 1341|
|2490509127| 1874|
|2264585544| 4655|
|3490623651| 2841|
|3711871763| 814|
|3292982761| 1855|
|1072430432| 2047|
|1194867611| 2526|
+----------+-----------+*/
// 检验是否正确
user_friend_count.filter("userid==2490509127").show()
// todo 将user_friend_count表存入hive
user_friend_count.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.user_friend_count")
println("user_friend_count存入成功!")3.event_attendee_count表———每个用户的朋友的数量
val event_attendeeDF: DataFrame = spark.table("dwd_events.event_attendee")
event_attendeeDF.show(10, false)
val event_attendee_count: DataFrame = event_attendeeDF
.groupBy("eventid", "attendtype")
.agg(count("friendid").as("attendCount"))
.select($"eventid", $"attendtype", $"attendCount")
event_attendee_count.show(10)
/*
+----------+----------+-----------+
| eventid|attendtype|attendCount|
+----------+----------+-----------+
|2889060532| yes| 142|
|2892429018| noID| 24|
|2897294049| yes| 32|
|2905904014| invitedID| 744|
|2907906052| yes| 19|
| 291670090| yes| 16|
|2920583393| maybeID| 9|
| 292137502| invitedID| 22|
|2923173603| noID| 1|
| 292829502| yes| 26|
+----------+----------+-----------+*/
// 检验是否正确
// event_attendee_count.filter("eventid==100022787").show()
// todo 将event_attendee_count表存入hive
event_attendee_count.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.event_attendee_count")
println("event_attendee_count存入成功!")4.event_user_state表——每个事件邀请的朋友的应邀情况
val event_attendee: DataFrame = spark.table("dwd_events.event_attendee")
event_attendee.show(10, false)
/*
+-----------------------------+----------+----------+----------+
|rowkey |eventid |friendid |attendtype|
+-----------------------------+----------+----------+----------+
|2876154686398769537invitedID |2876154686|398769537 |invitedID |
|28761546864009644924yes |2876154686|4009644924|yes |
|28761546864013573384invitedID|2876154686|4013573384|invitedID |
|28761546864024311006invitedID|2876154686|4024311006|invitedID |
|28761546864036236137noID |2876154686|4036236137|noID |
|28761546864041306043noID |2876154686|4041306043|noID |
|28761546864076390199invitedID|2876154686|4076390199|invitedID |
|28761546864094501247invitedID|2876154686|4094501247|invitedID |
|28761546864103909109yes |2876154686|4103909109|yes |
|28761546864114930709noID |2876154686|4114930709|noID |
+-----------------------------+----------+----------+----------+*/
val event_user_state: DataFrame = event_attendee
.select("eventid", "friendid", "attendtype")
.withColumn("invited", when(col("attendtype") === "invitedID", 1).otherwise(0))
.withColumn("yes", when(col("attendtype") === "yes", 1).otherwise(0))
.withColumn("no", when(col("attendtype") === "noID", 1).otherwise(0))
.withColumn("maybe", when(col("attendtype") === "maybeID", 1).otherwise(0))
.drop("attendtype")
event_user_state.show(10, false)
/*
+----------+----------+-------+---+---+-----+
|eventid |friendid |invited|yes|no |maybe|
+----------+----------+-------+---+---+-----+
|2876154686|398769537 |1 |0 |0 |0 |
|2876154686|4009644924|0 |1 |0 |0 |
|2876154686|4013573384|1 |0 |0 |0 |
|2876154686|4024311006|1 |0 |0 |0 |
|2876154686|4036236137|0 |0 |1 |0 |
|2876154686|4041306043|0 |0 |1 |0 |
|2876154686|4076390199|1 |0 |0 |0 |
|2876154686|4094501247|1 |0 |0 |0 |
|2876154686|4103909109|0 |1 |0 |0 |
|2876154686|4114930709|0 |0 |1 |0 |
+----------+----------+-------+---+---+-----+*/
// todo 将event_user_state表存入hive
event_user_state.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.event_user_state")
println("event_user_state存入成功!")5.user_event_status表——event_user_state表的数据梳理
val user_event_status: DataFrame = event_user_state
.groupBy("eventid", "friendid")
.agg(max("invited").as("invited"),
max("yes").as("attended"),
max("no").as("not_attended"),
max("maybe").as("maybe_attended"))
.select($"friendid".as("attend_userid"), $"eventid", $"invited", $"attended", $"not_attended", $"maybe_attended")
user_event_status.show(10, false)
/*
+-------------+----------+-------+--------+------------+--------------+
|attend_userid|eventid |invited|attended|not_attended|maybe_attended|
+-------------+----------+-------+--------+------------+--------------+
|4121945394 |2876154686|0 |0 |0 |1 |
|141447478 |2876312334|1 |0 |0 |0 |
|1540745136 |2876312334|1 |0 |0 |0 |
|1602785576 |2876312334|1 |0 |0 |0 |
|1954378660 |2876312334|1 |0 |0 |0 |
|2467890010 |2876312334|1 |0 |0 |0 |
|3854249513 |2876312334|1 |0 |0 |0 |
|3900944627 |2876312334|1 |0 |0 |0 |
|99137438 |2876312334|1 |0 |0 |0 |
|2653177815 |2876474895|1 |0 |0 |0 |
+-------------+----------+-------+--------+------------+--------------+*/
// todo 将user_event_status表存入hive
user_event_status.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.user_event_status")
println("user_event_status存入成功!")6.user_attend_event_count表——查看每个用户分别对事件的邀请参加、不参加的数量的统计
val user_attend_event_count: DataFrame = user_event_status.
groupBy("attend_userid")
.agg(
sum("invited").as("invited_count"),
sum("attended").as("attended_count"),
sum("not_attended").as("not_attended_count"),
sum("maybe_attended").as("maybe_attended_count"))
.select($"attend_userid", $"invited_count", $"attended_count", $"not_attended_count", $"maybe_attended_count")
user_attend_event_count.show(10, false)
// user_attend_event_count.filter(col("invited_count").isNull).show()
/*
+-------------+-------------+--------------+------------------+--------------------+
|attend_userid|invited_count|attended_count|not_attended_count|maybe_attended_count|
+-------------+-------------+--------------+------------------+--------------------+
|855128455 |6 |0 |0 |0 |
|1298918693 |70 |13 |0 |1 |
|973498510 |3 |0 |0 |0 |
|3733456205 |1 |0 |0 |0 |
|3924756713 |0 |0 |0 |1 |
|2049233271 |1 |0 |0 |0 |
|1544040576 |572 |4 |1 |0 |
|198353704 |5 |0 |0 |0 |
|1042939212 |53 |2 |1 |0 |
|989774136 |15 |0 |1 |0 |
+-------------+-------------+--------------+------------------+--------------------+*/
// todo 将user_attend_event_count表存入hive
user_attend_event_count.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.user_attend_event_count")
println("user_attend_event_count存入成功!")7.friend_attend_state表——统计应邀情况
// user_friend.show(10,false)
// user_event_status.show(10,false)
// 通过friendid=attend_userid相关联
val friend_attend_state: DataFrame = user_friend.as("uf")
.join(
user_event_status.as("ues"),
$"uf.friendid" === $"ues.attend_userid",
"left")
.select(
$"uf.userid",
$"uf.friendid",
$"ues.eventid",
when(col("ues.invited") > 0, 1).otherwise(0).as("invited"),
when(col("ues.attended") > 0, 1).otherwise(0).as("attended"),
when(col("ues.not_attended") > 0, 1).otherwise(0).as("not_attended"),
when(col("ues.maybe_attended") > 0, 1).otherwise(0).as("maybe_attended")
)
friend_attend_state.show(10, false)
/*
+----------+----------+----------+-------+--------+------------+--------------+
|userid |friendid |eventid |invited|attended|not_attended|maybe_attended|
+----------+----------+----------+-------+--------+------------+--------------+
|700005400 |1000000082|null |0 |0 |0 |0 |
|3182595870|1000061907|2025801575|0 |0 |1 |0 |
|3182595870|1000061907|2662605961|0 |0 |1 |0 |
|105163661 |1000159243|null |0 |0 |0 |0 |
|3241009765|1000174727|null |0 |0 |0 |0 |
|4146824251|1000174727|null |0 |0 |0 |0 |
|2041077011|1000174727|null |0 |0 |0 |0 |
|713793505 |1000174727|null |0 |0 |0 |0 |
|4152340748|1000177128|null |0 |0 |0 |0 |
|3189616067|1000225963|null |0 |0 |0 |0 |
+----------+----------+----------+-------+--------+------------+--------------+*/
// todo 将friend_attend_state表存入hive
friend_attend_state.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.friend_attend_state")
println("friend_attend_state存入成功!")8.friend_attend_summary表——求用户朋友中针对某一件事情的状态数量 多少人被邀请,多少人参加,多少人不参加,多少人可能去参加
val friend_attend_summary: DataFrame = friend_attend_state
.where(col("eventid").isNotNull)
.groupBy("userid", "eventid")
.agg(
sum("invited").as("invited_friends_count"),
sum("attended").as("attended_friends_count"),
sum("not_attended").as("not_attended_friends_count"),
sum("maybe_attended").as("maybe_attended_friends_count")
)
.select($"userid", $"eventid", $"invited_friends_count", $"attended_friends_count",
$"not_attended_friends_count", $"maybe_attended_friends_count")
friend_attend_summary.show(10, false)
/*
+----------+----------+---------------------+----------------------+--------------------------+----------------------------+
|userid |eventid |invited_friends_count|attended_friends_count|not_attended_friends_count|maybe_attended_friends_count|
+----------+----------+---------------------+----------------------+--------------------------+----------------------------+
|139333642 |2153037761|1 |0 |0 |0 |
|3965867052|2693701979|542 |9 |19 |15 |
|570405433 |844053363 |1 |0 |0 |0 |
|3600799019|3480624055|63 |13 |5 |11 |
|220900628 |1684651848|24 |0 |0 |0 |
|4076593100|1902753965|73 |0 |0 |0 |
|3098511794|843844488 |27 |0 |0 |1 |
|212275010 |1900273727|1 |0 |0 |0 |
|484625739 |623506969 |136 |0 |2 |0 |
|2678093681|1486124986|136 |0 |0 |0 |
+----------+----------+---------------------+----------------------+--------------------------+----------------------------+*/
// todo 将friend_attend_summary表存入hive
friend_attend_summary.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.friend_attend_summary")
println("friend_attend_summary存入成功!")9.event_cities表——找出事件发生最多的前32个的城市
val events: DataFrame = spark.table("dwd_events.events")
events.show(10, false)
/*
+----------+----------+------------------------+---------+-------+-----+--------------+------+-------+-----------+
|eventid |userid |starttime |city |state |zip |country |lat |lng |commonwords|
+----------+----------+------------------------+---------+-------+-----+--------------+------+-------+-----------+
|2926425690|596548160 |2012-06-09T05:00:00.000Z|Charlotte|NC | |United States |35.238|-80.819|8 |
|2926430949|2924318367|2012-10-18T19:00:00.003Z| | | | |null |null |1 |
|2926432319|3488255249|2012-11-11T17:30:00.003Z| | | | |null |null |0 |
|2926434242|4104060347|2012-11-15T05:00:00.003Z| | | | |null |null |1 |
|2926434816|458628699 |2012-12-24T03:00:00.003Z|Vernon |BC | |Canada |50.262|-119.27|8 |
|2926434921|4161455361|2012-11-14T00:00:00.003Z| | | | |null |null |1 |
|292643510 |4236892345|2012-11-21T19:00:00.002Z|London |England| |United Kingdom|null |null |0 |
|2926435519|2028324284|2012-12-02T02:30:00.003Z| | | | |null |null |1 |
|2926438764|1025231184|2012-09-23T00:00:00.003Z| | | | |null |null |13 |
|2926439286|3578613806|2012-11-09T00:00:00.001Z|Omaha |NE |68102|United States |41.257|-95.936|2 |
+----------+----------+------------------------+---------+-------+-----+--------------+------+-------+-----------+*/
val event_cities: DataFrame = events
.groupBy("city")
.agg(count("*").as("count"))
.orderBy(col("count").desc)
.limit(32)
.withColumn("city_1", when($"city" =!= "", $"city").otherwise("nocity"))
.drop("city")
.withColumnRenamed("city_1", "city")
.selectExpr("city", "count", "row_number() over(order by count desc) as level")
event_cities.show(32)
/*
+-------------+-------+-----+
| city| count|level|
+-------------+-------+-----+
| nocity|1557124| 1|
| New York| 43009| 2|
| Toronto| 32023| 3|
| Los Angeles| 27831| 4|
| Chicago| 21390| 5|
| London| 21187| 6|
|San Francisco| 20302| 7|
| Brooklyn| 14689| 8|
| Austin| 14528| 9|
| Houston| 12599| 10|
| Philadelphia| 12589| 11|
| Seattle| 11952| 12|
| Portland| 11672| 13|
| Washington| 11638| 14|
| San Diego| 11438| 15|
| Vancouver| 10445| 16|
| Atlanta| 10012| 17|
| Las Vegas| 8964| 18|
| Denver| 8771| 19|
| Dallas| 8590| 20|
| Miami| 8252| 21|
| Phoenix| 7335| 22|
| Boston| 6810| 23|
| Minneapolis| 6737| 24|
| Montreal| 6273| 25|
| Orlando| 6272| 26|
| San Antonio| 6025| 27|
| Ottawa| 5921| 28|
| Columbus| 5605| 29|
| Saint Louis| 5391| 30|
| Melbourne| 5280| 31|
| Sacramento| 5231| 32|
+-------------+-------+-----+*/
// todo 将event_cities表存入hive
event_cities.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.event_cities")
println("event_cities存入成功!")10.event_countries表——找出事件发生最多的前8个国家
val event_countries: DataFrame = events
.groupBy("country")
.agg(count("*").as("count"))
.orderBy(col("count").desc)
.limit(8)
.withColumn("country_1", when($"country" =!= "", $"country").otherwise("nocountries"))
.drop("country")
.withColumnRenamed("country_1", "country")
.selectExpr("country", "count", "row_number() over(order by count desc) as level")
event_countries.show()
/*
+--------------+-------+-----+
| country| count|level|
+--------------+-------+-----+
| nocountries|1533009| 1|
| United States|1068337| 2|
| Canada| 137768| 3|
|United Kingdom| 67806| 4|
| Italy| 48436| 5|
| Australia| 33137| 6|
| Germany| 18176| 7|
| Mexico| 17730| 8|
+--------------+-------+-----+*/
// todo 将event_countries表存入hive
event_countries.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("spark_hive.event_countries")
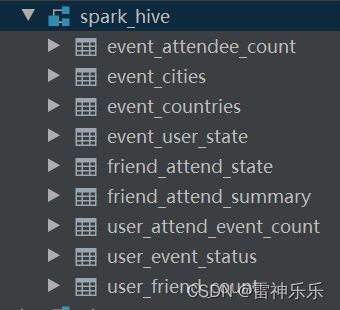
println("event_countries存入成功!")11.验证是否存入成功
(四)DM层——宽表明细层
1.dm_events库
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.optimize.sort.dynamic.partition=true;
set hive.auto.convert.join=false;
set hive.exec.mode.local.auto=true;
create database if not exists dm_events;
use dm_events;2.user_event_1表——每个事件发生的国家、城市等信息
create table user_event_1 stored as orc as
select t.userid,
t.eventid,
t.invited user_invited,
t.interested,
e.eventid event_creator,
if(e.city <> '', e.city, 'nocity') event_city,
e.state event_state,
`if`(e.country <> '', e.country, 'nocountry') event_country,
e.lat,
e.lng
from dwd_events.train t
inner join dwd_events.events e
on t.eventid = e.eventid;