机器学习&&深度学习——常见循环神经网络结构(RNN、LSTM、GRU)
作者简介:一位即将上大四,正专攻机器学习的保研er
上期文章:机器学习&&深度学习——RNN的从零开始实现与简洁实现
订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
常见循环神经网络结构(RNN、LSTM、GRU)
- 引言
- RNN
- LSTM
-
- 门控记忆元
-
- 输入门、输出门和遗忘门
- 候选记忆元
- 记忆元
- 隐状态
- LSTM的简洁实现
- GRU
-
- 结构详解
- GRU的简洁实现
- 常用应用方式
引言
之前已经实现讲解并实现过了RNN模型,而LSTM可以弥补RNN的一些缺点,GRU是LSTM的简化版本,这里我们就回顾一下RNN模型,接着循序渐进讲解LSTM和GRU。
CNN和全连接网络的数据表示能力已经很强了,但是我们为啥还需要循环神经网络呢?这是因为现实的问题更复杂,很多数据的输入顺序对于结果都是有很大影响的。如文本数据(尤其是字母和文字的组合),先后顺序具有非常重要的意义,如果打乱,就会无法正确表示原始信息。而相比其他网络,循环神经网络因为具有记忆能力,所以更有效。
RNN
RNN循环神经网络使用torch.nn.RNN()来构建,如下图所示:

针对t时刻的隐状态,可以由下面公式计算:
h t = φ ( W i h x t + b i h + W h h h t − 1 + b h h ) = φ ( W i h x t + W h h h t − 1 + b h ) 其中: h t 是 t 时刻的隐藏状态; h t − 1 是 t − 1 时刻的隐藏状态 W i h 是输入到隐藏层的权重; W h h 是隐藏层到隐藏层的权重; b i h 是输入到隐藏层的偏置; b h h 是隐藏层到隐藏层的偏置; h_t=φ(W_{ih}x_t+b_{ih}+W_{hh}h_{t-1}+b_{hh})\\ =φ(W_{ih}x_t+W_{hh}h_{t-1}+b_{h})\\ 其中:h_t是t时刻的隐藏状态;h_{t-1}是t-1时刻的隐藏状态\\ W_{ih}是输入到隐藏层的权重;W_{hh}是隐藏层到隐藏层的权重;\\ b_{ih}是输入到隐藏层的偏置;b_{hh}是隐藏层到隐藏层的偏置; ht=φ(Wihxt+bih+Whhht−1+bhh)=φ(Wihxt+Whhht−1+bh)其中:ht是t时刻的隐藏状态;ht−1是t−1时刻的隐藏状态Wih是输入到隐藏层的权重;Whh是隐藏层到隐藏层的权重;bih是输入到隐藏层的偏置;bhh是隐藏层到隐藏层的偏置;
激活函数可以使用ReLU或tanh。
虽然在对序列数据进行建模时,RNN有一定记忆能力,但单纯的RNN会随着递归次数的增加,出现权重指数级爆炸或消失的问题,从而难以捕捉长时间关联,并导师训练时收敛困难。
LSTM
LSTM称为长短期记忆网络,是一种特殊的RNN,主要用于解决长序列训练过程中的梯度消失和爆炸问题,能在长序列中获得更好的分析效果。
门控记忆元
记忆元的目的是为了记录附加的信息,要控制记忆元,我们需要下面的几个门:
1、输出门:用来从单元中输出条目
2、输入门:决定何时将数据读入单元
3、遗忘门:重置单元的内容
接下来来看看如何工作的:
输入门、输出门和遗忘门
当前时间步的输入和前一个时间步的隐状态作为数据送入长短期记忆网络的门中,如下图:
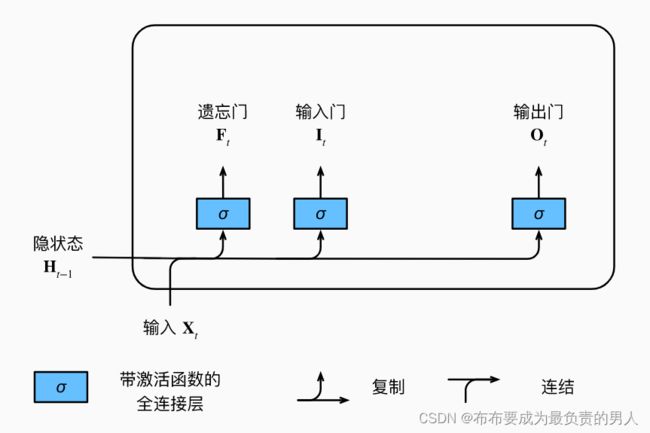
上图的σ是代表由sigmoid激活函数的全连接层处理,因此三个门的值都在(0,1)范围内,显然计算方法如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) O t = σ ( X t W x o + H t − 1 W h o + b o ) F t = σ ( X t W x f + H t − 1 W h f + b f ) I_t=\sigma(X_tW_{xi}+H_{t-1}W_{hi}+b_i)\\ O_t=\sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o)\\ F_t=\sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f) It=σ(XtWxi+Ht−1Whi+bi)Ot=σ(XtWxo+Ht−1Who+bo)Ft=σ(XtWxf+Ht−1Whf+bf)
候选记忆元
其计算与上面类似,但是使用tanh来作为激活函数,函数范围为(-1,1),计算方式为:
G t = t a n h ( X t W x g + H t − 1 W h g + b g ) G_t=tanh(X_tW_{xg}+H_{t-1}W_{hg}+b_g) Gt=tanh(XtWxg+Ht−1Whg+bg)
如图所示:

记忆元
在LSTM中,有两个门用于实现一种输入和遗忘的机制:输入门控制采用多少来自候选记忆元的新数据,而遗忘门控制保留多少过去的记忆元的内容。使用按元素乘法,得出:
C t = F t ⨀ C t − 1 + I t ⨀ G t C_t=F_t \bigodot C_{t-1}+I_t \bigodot G_t Ct=Ft⨀Ct−1+It⨀Gt
若遗忘门始终为1且输入门始终为0,则过去的记忆元 将随时间被保存并传递到当前时间步。
引入这种设计是为了缓解梯度消失问题, 并更好地捕获序列中的长距离依赖关系。
如下图所示:

隐状态
最后是计算隐状态,这里就是输出门的作用了。LSTM中,它是记忆元的tanh的门控版本,确保了隐状态的值在(-1,1)之间:
H t = O t ⨀ t a n h ( C t ) H_t=O_t \bigodot tanh(C_t) Ht=Ot⨀tanh(Ct)
只要输出门接近1,就能有效将所有记忆换递给预测部分,对于输出门接近0,我们只保留记忆元内的所有信息,而不需要更新隐状态。
那么整体的LSTM图示如下所示:

LSTM的简洁实现
使用高级API,我们可以直接实例化LSTM模型。这段代码的运行速度要快得多, 因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节:
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
d2l.plt.show()
运行结果:
perplexity 1.1, 48684.5 tokens/sec on cpu
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
运行图片:

GRU
结构详解
LSTM对很多需要“长期记忆”的任务来说效果显著。但是门控状态太多,导致需要训练更多的参数,使得训练难度加大。因此提出循环门控单元GRU,GRU通过将遗忘门和输入门组合在一起,减少了门的数量,并做了其他改变,在保证记忆能力同时,提升网络训练效率。其组成如下所示:
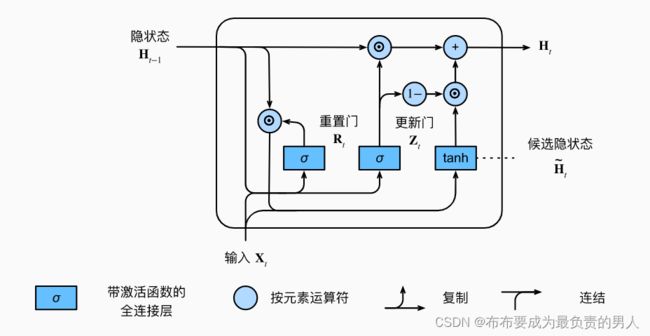
而每个GRU单元针对输入进行下面函数的计算:
R t = σ ( X t W x r + H t − 1 W h r + b r ) Z t = σ ( X t W x z + H t − 1 W h z + b z ) 候选隐状态 H t ′ = t a n h ( X t W x h + ( R t ⨀ H t − 1 ) W h h + b h ) 其中 R t ⨀ H t − 1 可以减少以往遗忘状态的影响: 每当 R t 接近 1 时,我们恢复一个传统 R N N 网络; R t 接近 0 时,候选隐状态是以 X t 作为输入的多层感知机的结果 H t = Z t ⨀ H t − 1 + ( 1 − Z t ) ⨀ H t ′ Z t 接近 1 时,模型倾向于保留旧状态; Z t 接近 0 时,倾向于候选隐状态 R_t=\sigma(X_tW_{xr}+H_{t-1}W_{hr}+b_r)\\ Z_t=\sigma(X_tW_{xz}+H_{t-1}W_{hz}+b_z)\\ 候选隐状态H_t^{'}=tanh(X_tW_{xh}+(R_t \bigodot H_{t-1})W_{hh}+b_h)\\ 其中R_t \bigodot H_{t-1}可以减少以往遗忘状态的影响:\\ 每当R_t接近1时,我们恢复一个传统RNN网络;\\ R_t接近0时,候选隐状态是以X_t作为输入的多层感知机的结果\\ H_t=Z_t \bigodot H_{t-1}+(1-Z_t) \bigodot H_t^{'}\\ Z_t接近1时,模型倾向于保留旧状态;Z_t接近0时,倾向于候选隐状态 Rt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)候选隐状态Ht′=tanh(XtWxh+(Rt⨀Ht−1)Whh+bh)其中Rt⨀Ht−1可以减少以往遗忘状态的影响:每当Rt接近1时,我们恢复一个传统RNN网络;Rt接近0时,候选隐状态是以Xt作为输入的多层感知机的结果Ht=Zt⨀Ht−1+(1−Zt)⨀Ht′Zt接近1时,模型倾向于保留旧状态;Zt接近0时,倾向于候选隐状态
总之,GRU有以下显著特征:
1、重置门有助于捕获序列中的短期依赖关系
2、更新门有助于捕获序列中的长期依赖关系
GRU的简洁实现
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
d2l.plt.show()
运行结果:
perplexity 1.0, 12581.5 tokens/sec on cpu
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
运行图片:
常用应用方式
循环神经网络中的不同的输入输出对应情况都有不同的应用方式。其中,一对多的网络结构可以用于图像描述(根据输入的一张图像,自动使用文字描述图像内容);多对一的网络结构可用于文本分类;多对多的网络结构可用于语言翻译。
比如,我们可以用RNN来做手写体分类,可以用LSTM来做中文新闻分类,可以用GRU来进行情感分类等等。