Transformer讲解(一)- NLP变形金刚-详细知识介绍
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)_哔哩哔哩_bilibili
视频123

1

2 Encoder 多个循环,结构相同,参数不同(非共享参数)(特别案例albert是参数共享)
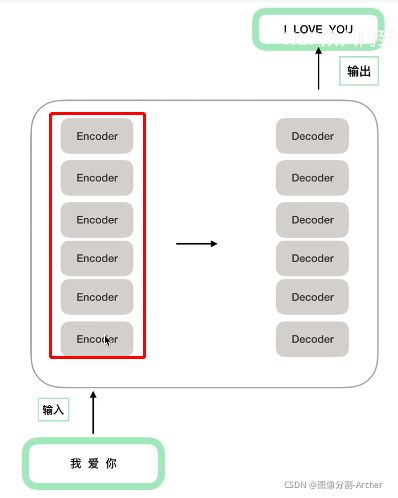
3.1 原论文图 xN (原论文6个encoders)

3.2 Encoder和Decoder区别
Decoder中多了
a 多一个交互层
b Masked(被掩码的多头注意力)
4 Encoder细节
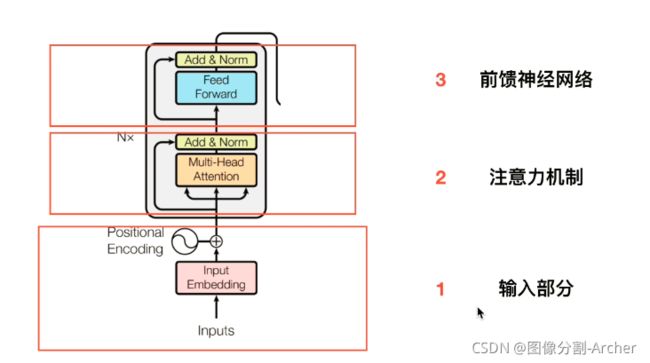
5 输入部分分为:Enbedding和位置编码
5.1 Enbedding
a 使用word to vec映射(每一个字'我'对应512维度向量)
b 也可以使用随机初始化(数据量很大)
5.2 位置编码
由RNN引入为什么位置编码:
U输入参数,W隐藏参数, V输出参数(这是一套参数,所有time steps的共享一套参数)
看右图是一套参数都是U,W,V他们是相同的。
RNN的梯度消失有什么不同?
RNN是总的梯度和,因此容易被近距离梯度主导,远距离梯度忽略(面试题)

Transformer是并行处理,而不是先处理“我”然后“爱”最后“你”,因此需要对位置进行编码。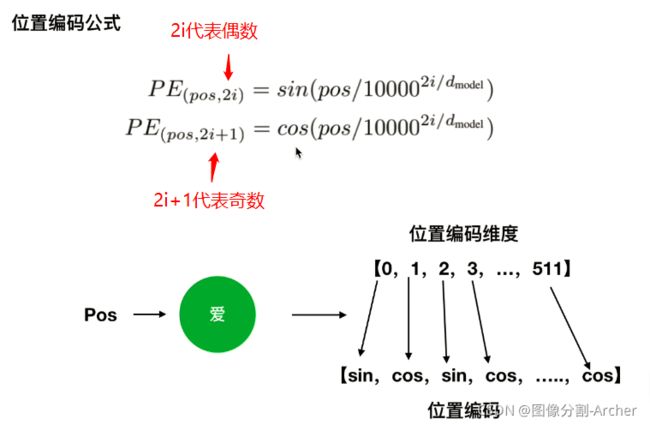
“爱 ”的向量为512维度,奇数偶数分别对应cos,sin(看下图)

将位置编码512维度和字向量512维度相加,得到新的512,作为输入。

公式(3)第一个公式:
假如:pos+k代表你,pos代表我,k代表爱
也就是说,你可以被pos我,k爱两个线性组合起来,也就是说绝对位置向量中蕴含了相对位置向量信息。(这些会在注意力机制中消失)
6 注意力机制

人:给了 “婴儿在干嘛”这句话之后 ,人会分析这句话与图中哪部分更加关联 ?
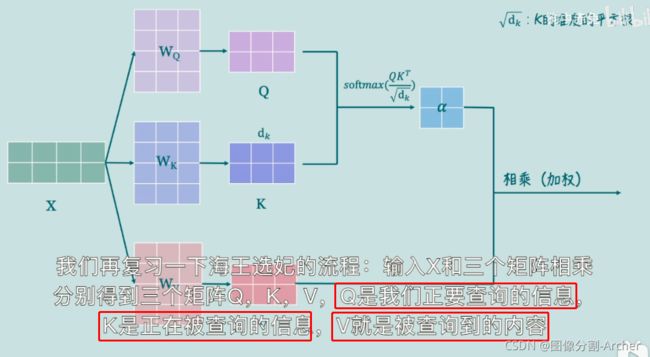
公式:

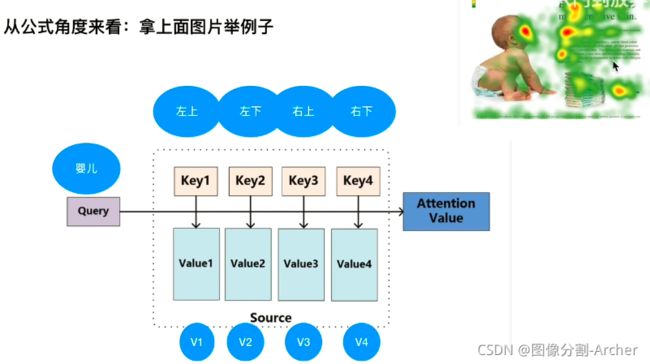
三个矩阵Q, K, V
Q分别和k1,k2,k3,k4相乘(点成),数值越大表示越关注,越相似,距离越相近(婴儿分别和不同区域对比)
QK再与V矩阵相乘,得到加权和

1 点乘法 ->s
2 softmax ->得到相似度 a
3 乘V
4 相加
得到注意力值
Transfermor中的注意力,如何获取QKV
1 矩阵参数的使用W

4维度向量x1,x1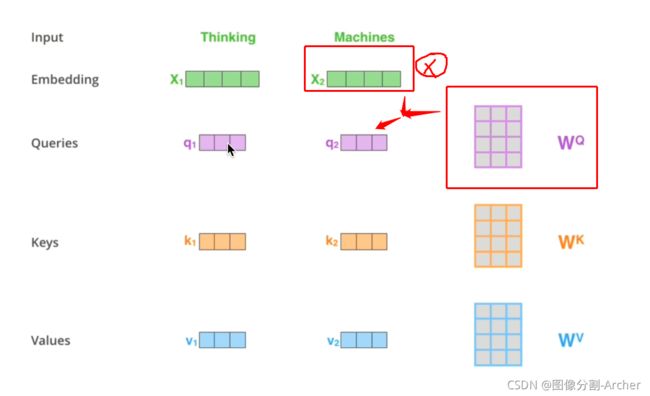
利用同一套矩阵参数WQ,
x1*WQ = q1
x2*WQ = q2
x3*WQ = q3
同理
x1*WK = k1
x2*WK = k2
x3*WK = k3
x1*WV = v1
x2*WV = v2
x3*WV = v3
2 计算注意力值
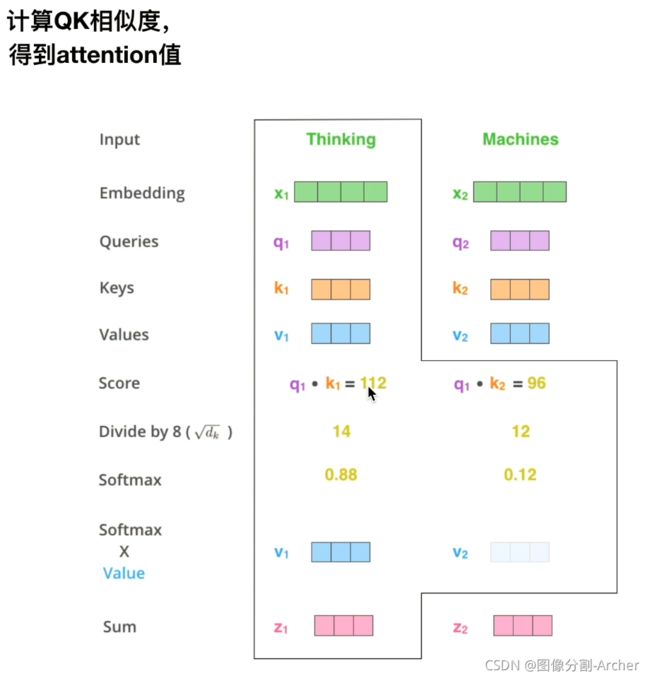
qk得到数值需要除8(根号k)
因为QK相乘数值很大得话,softmax的梯度很小,会梯度消失。
=在线激情讲解transformer&Attention注意力机制(上)_哔哩哔哩_bilibili=
====================》生动形象的模型介绍《========================
自注意力原理
====================》生动形象的模型介绍《========================


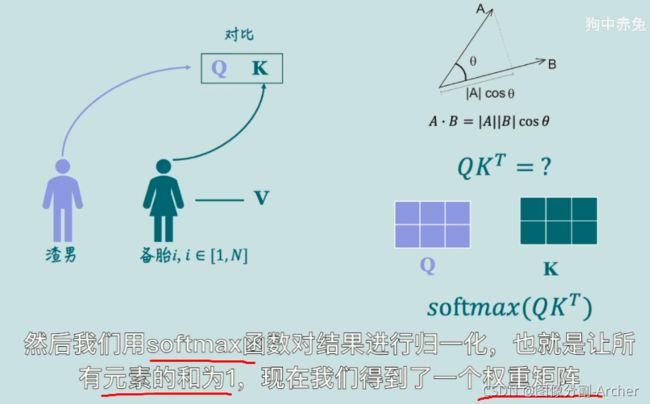



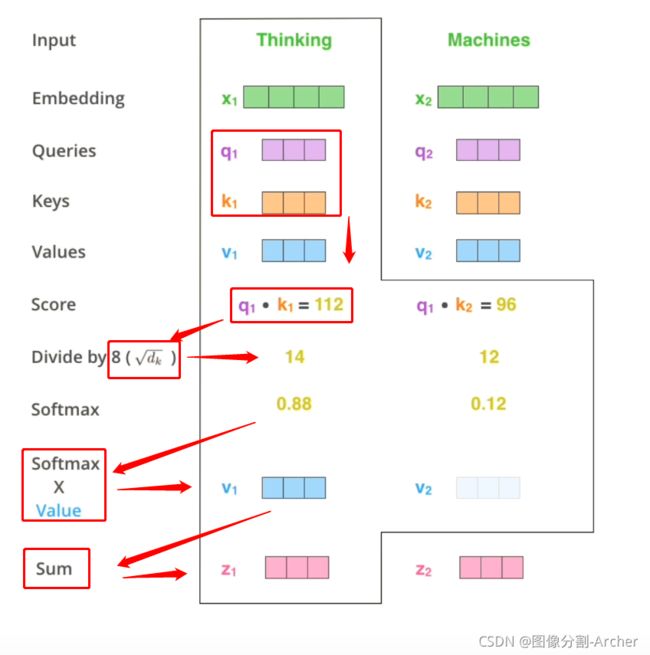
为何会得到0.88, 0.12??
3 实际操作中会使用矩阵,来方便并行,多个一起输入(x1, x2)

4 多头注意力
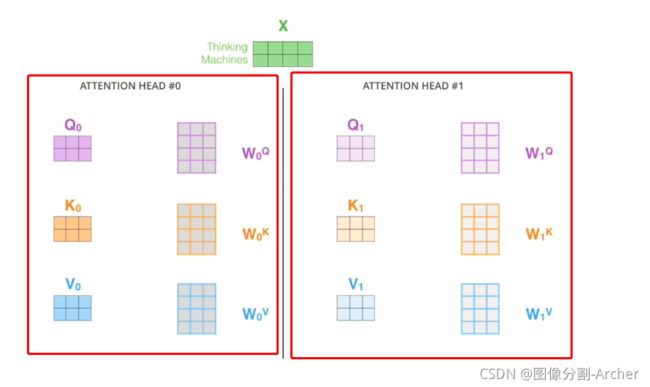
每个方框是一个空间,可以不同子空间合作
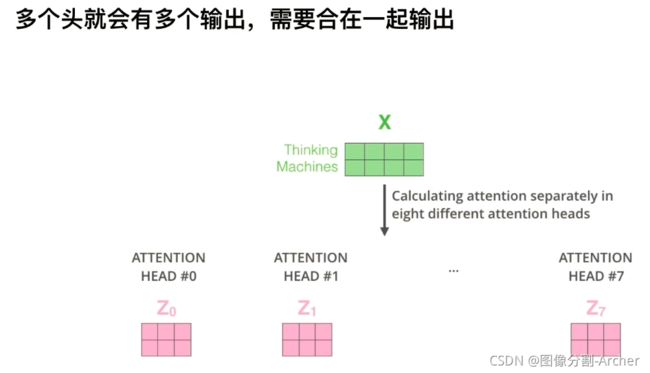
视频4

1 残差和layerNorm


X Z对位相加(残差)
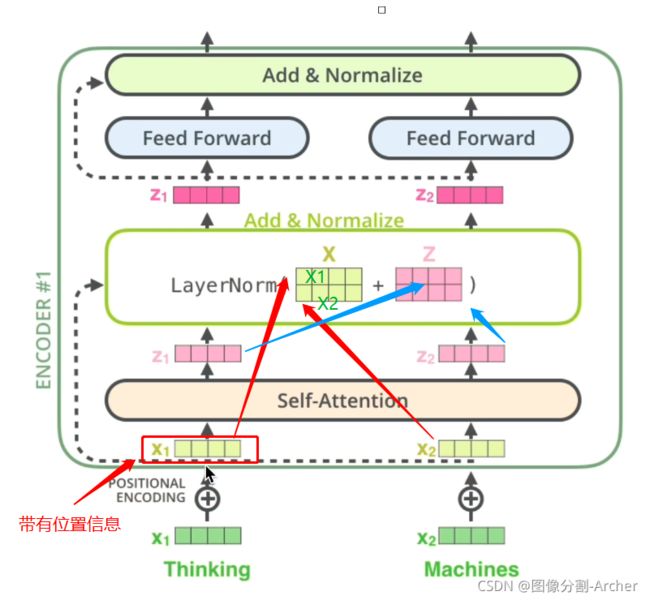
残差原理


对A的输出作链式求导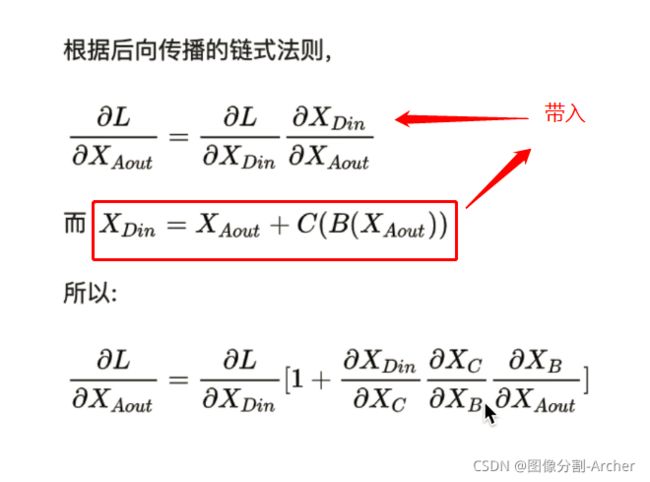
连乘会有梯度消失,因为有1 所以不会梯度消失
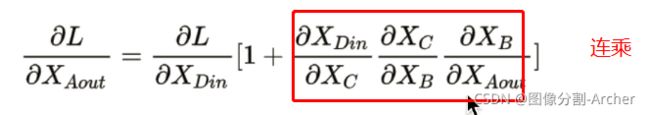
视频56 有时间再补充,这都是经验

视频7 解码器

1 masked掩盖的 2 用于交互
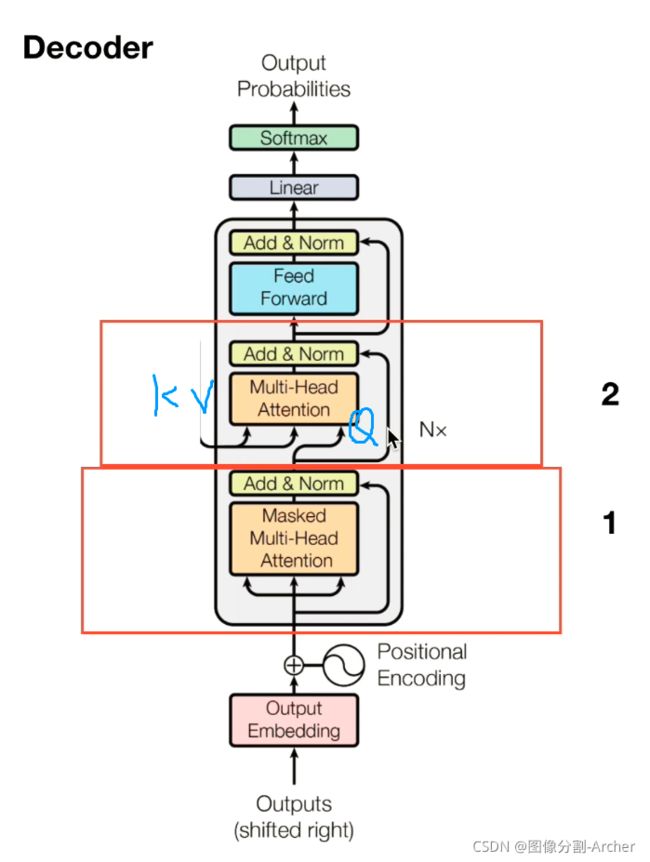
1 mask
mask作用:当前单词和之后的单词都抹掉不让看到
如果不抹掉,you会得到所有信息,
比如预测YOU,训练的时候能看到所有所有信息,而在测试阶段看不到

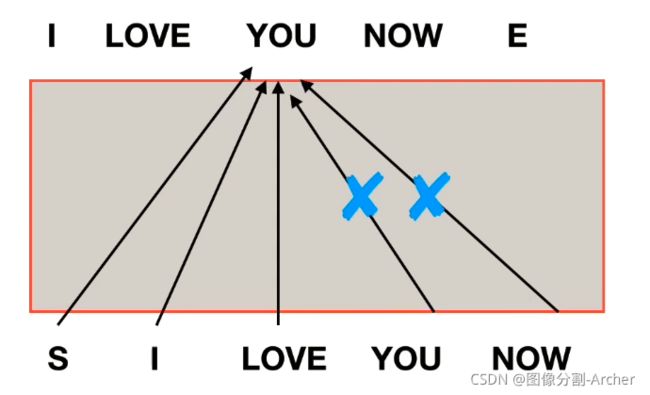
mask掉之后训练和测试都是相符的,有一致性

2 交互

没有mask
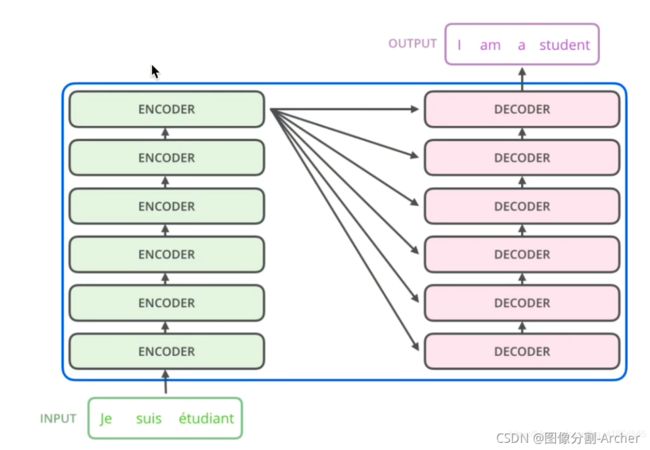
编码器的输出要和每一个解码器进行交互
具体交互如下:
Decoder生成Q矩阵
Encoder生成KV
