代码详解——Transformer
文章目录
- 整体架构
- Modules.py
-
- ScaledDotProductAttention
- SubLayers.py
-
- MultiHeadAttention
- PositionwiseFeedForward
- Layers.py
-
- EncoderLayer
- DecoderLayer
- Models.py
-
- get_pad_mask
- get_subsequent_mask
- PositionalEncoding
- Encoder
- Decoder
- Transformer
整体架构
源码地址(pytorch): https://github.com/jadore801120/attention-is-all-you-need-pytorch
论文地址:Attention is All You Need
✨✨✨强烈建议先去看《详解注意力机制和Transformer》 理解Transformer的机制后再去理解本篇中的代码。
项目的整体架构如下,其中Transformer 包下的文件是用于主要构建Transfomer模型的代码,包外的其他文件是Transfomer用于完成特定翻译任务的预处理文件和训练测试代码。
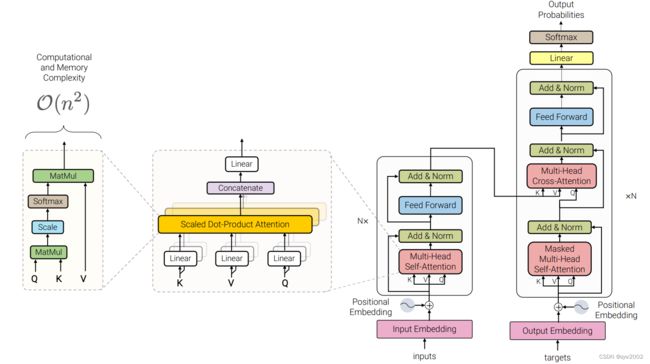
本文重点讲解红框内的代码(构建Transformer的核心代码), 即实现了下图所示的Transformer的架构。
因为Transformer经常被用到其他的任务中,所以这部分的核心代码也常被移植到其他的项目代码中。
Modules.py
Models.py文件主要就是定义了一个缩放点积注意力 (下图红框中的部分)

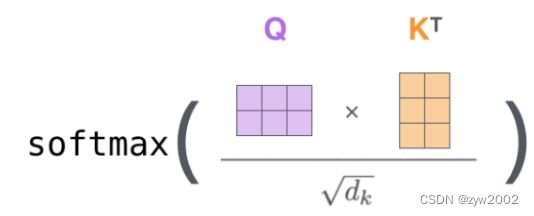
缩放点积的计算公式如下:
softmax ( Q K ⊤ d ) V ∈ R n × v . \operatorname{softmax}\left(\frac{\mathbf{Q } \mathbf{K}^{\top}}{\sqrt{d}}\right) \mathbf{V} \in \mathbb{R}^{n \times v} . softmax(dQK⊤)V∈Rn×v.
ScaledDotProductAttention
# 缩放点积注意力
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# q: [sz_b,n_head,len,d_q]
# k: [sz_b,n_head,len,d_k] -> transpose 后:[sz_b,n_head,d_k,len]
# v: [sz_b,n_head,len,d_v]
# 一般来说,d_q=d_k=d_v
attn = torch.matmul(q / self.temperature, k.transpose(2, 3)) # score= qk^T/tempreture
# attn: [sz_b,n_head,len,len]
if mask is not None: # 判断是否有mask
attn = attn.masked_fill(mask == 0, -1e9) # Mask
attn = self.dropout(F.softmax(attn, dim=-1)) # a=softmax(Score) 然后 dropout
output = torch.matmul(attn, v) # z=a*v
# output: [sz_b,n_head,len,d_v]
return output, attn
相关参数的含义:
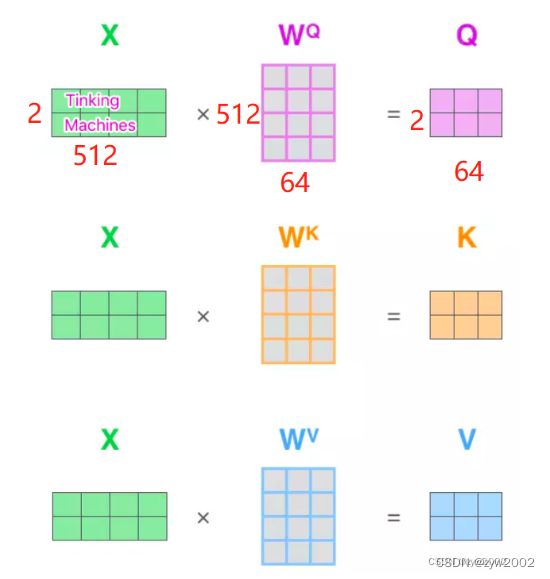
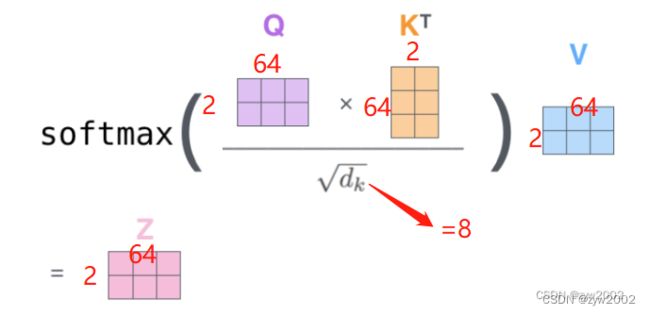
q,k,v分别表示的query,key,value, 对应下图中的QKV;它们的大小均是[sz_b,n_head,len,d_x](d_x代表d_q、d_v、d_k)sz_b表示batch sizen_head表示多头注意力的head 数量len表示单词的个数,如下图就是2。d_x表示特征的个数,如下图是64。
temperature就是的 d m o d e l \sqrt{d_model} dmodel, d m o d e l d_model dmodel表示的是特征个数的,用作是归一化。如下图中就是 64 = 8 \sqrt{64}=8 64=8mask表示是否传入mask,在Transformer中有两种mask,分别是padding mask和sequence mask
相关代码解读:
-
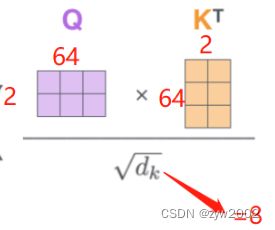
attn = torch.matmul(q / self.temperature, k.transpose(2, 3)): 就是计算注意力得分,并归一化 s c o r e = Q K ⊤ d score=\frac{\mathbf{Q } \mathbf{K}^{\top}}{\sqrt{d}} score=dQK⊤
k.transpose(2, 3)表示在k的后两个维度(len_q,d_q)进行转置。
根据矩阵乘法的原理,得到的attn的大小为[sz_b,n_head,len_q,len_k], 如下图就是[sz_b,n_head,2,2]
-
attn = attn.masked_fill(mask == 0, -1e9)然后判断是否传入的mask, 如果有mask (mask参数值不为None),则把mask为0的位置,将对应位置的attn的值设为无穷小的负数 − e 9 -e^{9} −e9
为什么要设置为无穷小呢?如下图展示了softmax函数,当x为无穷小时,softmax的输出趋近于0,attn的值就为0,就相当于是被mask掉了。

-
attn = self.dropout(F.softmax(attn, dim=-1))就是对刚才得到的注意力得分attn在d_q维度上进行softmax操作,把attn转换成一个值分布在[0,1]之间的 α概率分布矩阵
然后softmax后使用dropout操作防止过拟合。 -
output = torch.matmul(attn, v)最终得到的输出就把上述的attn和value相乘。最终的输出大小为[sz_b,n_head,len_q,d_v], 如下图就是[sz_b,n_head,2,64] 。可以发现得到的输出和输入的K,Q,V的大小相同。
SubLayers.py
MultiHeadAttention
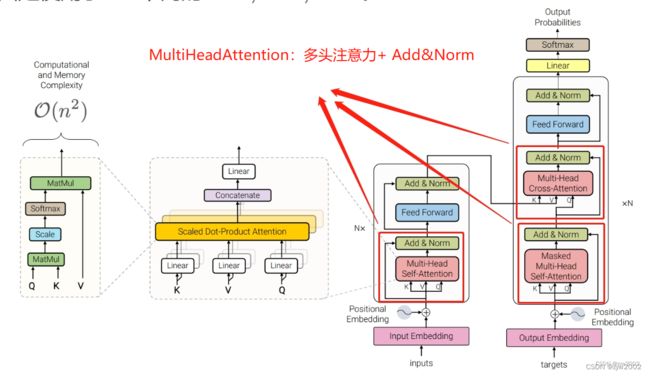
MultiHeadAttention定义了一个多头注意力和 Add&Norm。(下图中的红框部分)
可以实现如下三种多头注意力:
1)Multi-Head Self-Attention: K、Q、V的来源相同
2)Masked Multi-Head Self-Attention : 传入sequence mask 的mask参数,且K、Q、V的来源相同
3)Multi-Head Cross-Attention : K、V和Q的来源不同
# 多头注意力
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head # head数量
self.d_k = d_k # key 的维度
self.d_v = d_v # v 的维度
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False) # [sz_b,len_q,d_model]->[sz_b,len_q,n*d_k]
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5) # 缩放点积注意力
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# 原始输入 q/k/v:[sz_d,len,d_model]
# sz_b: batch_size
# len: 单词的个数 (一般来说:len=len_q=len_k=len_v)
# d_model:单词嵌入的维度 (一般来说:d_model=d_k=d_v)
# n_head : head的个数
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q # 残差连接
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
# w_qs后 [sz_b,len,d_model]->[sz_b,len,n*d_k]
# view 后拆分成n_head个 [sz_b,len_q,n_head,d_k]
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2) # [sz_b,n_head,len_q,d_k]
if mask is not None:
mask = mask.unsqueeze(1) # 多添加一个head维度,为了方便广播
#mask: [sz_b,len_q,len_k]-> [sz_b,1,len_q,len_k]
q, attn = self.attention(q, k, v, mask=mask) # 缩放点积注意力
# q: [sz_b,n_head,len_q,d_v]
# attn: [sz_b, n_head, len_q, len_k]
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
# [sz_b,len_q,n_head,d_v]-> [sz_b,len_q,n_head*d_v]
q = self.dropout(self.fc(q)) # [sz_b,len_q,n_head*d_v]-> [sz_b,len_q,d_model]
q += residual # 参差连接
q = self.layer_norm(q) # 层归一化
return q, attn # q: [sz_b,len_q,d_model] attn: [sz_b, n_head, len_q, len_k]
相关参数的含义:
- forward函数中初始传入的
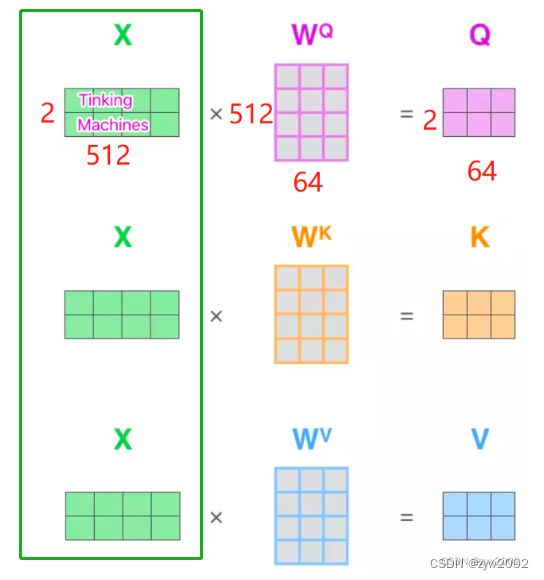
q,k,v, 注意这里并不是下图中的Q,K,V , 而是下图中的绿框内容(用于生成Q,K,V的原始输入) ,大小为[sz_d,len_q,d_model]sz_d: batch_sizelen_x: 单词的个数。 (len_x代表len_q、len_v、len_k) 如下图是2d_model: 单词嵌入的维度。如下图是512d_x: 特征的维度。 (d_x代表d_q、d_v、d_k) 如下图是 64
相关代码解读:
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)和k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)和v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)是从原始的输入中得到n_head 组Q,K,V。
w_qs是一个Linear层,输出大小从[sz_b,len,d_model]变为[sz_b,len,n*d_k]
然后通过view函数,输出大小变为[sz_b,len_q,n_head,d_k]q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)就是把n_head维度放在第二个维度上,输出大小变为[sz_b,n_head,len_q,d_k]
前两步就是完成了如下图所示的箭头内容,从原始输入,得到了n_head组 K , Q , V K,Q,V K,Q,V
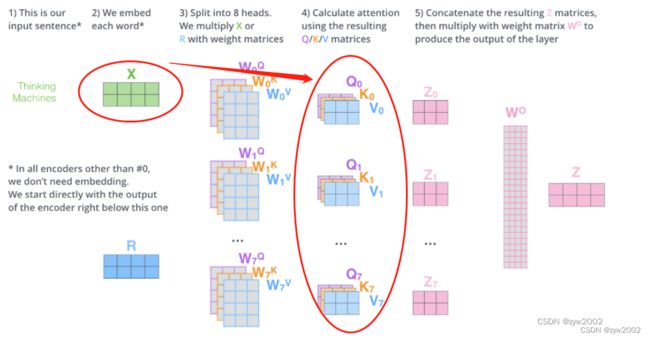
-
mask = mask.unsqueeze(1)如果mask不为None, 我们为Mask添加一个head上的维度(为了方便后续的广播)。 mask的大小从[sz_b,len_q,len_k]变为[sz_b,1,len_q,len_k] -
q, attn = self.attention(q, k, v, mask=mask)通过缩放点积注意力,输出得到的q的大小是[sz_b,n_head,len_q,d_v],attn的大小是[sz_b,n_head,len_q,len_k]
输出的q其实就是下图中的 Z 0 , Z 1 . . Z 7 Z_0,Z_1..Z_7 Z0,Z1..Z7
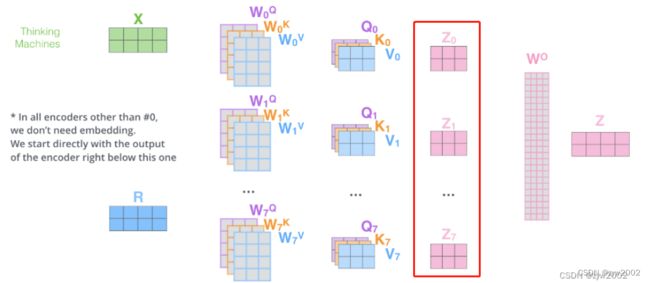
-
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)transpose后,大小变为[sz_b,len_q,n_head,d_v], 再通过view后,大小变为[sz_b,len_q,n_head*d_v]。
这个操作相当于沿着下图蓝线的方向,把 Z 0 , . . . Z 7 Z_0,...Z_7 Z0,...Z7 个输出连接起来得到 Z ′ Z' Z′。

-
q = self.dropout(self.fc(q))先通过一个fc层,大小从[sz_b,len_q,n_head*d_v]->[sz_b,len_q,d_model]。
这一步相当于把刚才得到的 Z ′ Z' Z′ 和 W O W^O WO相乘得到 Z Z Z
然后再通过一个dropout。 -
q += residual表示残差连接 -
q = self.layer_norm(q)表示层归一化
PositionwiseFeedForward
PositionwiseFeedForward 定义了一个Feed Forwad 和 Add &Norm 模块。(如下图中的红框)

class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x): # x: [sz_b,len_q,d_model]
residual = x # 残差
x = self.w_2(F.relu(self.w_1(x)))
# w_1: [sz_b,len_q,d_hid] w_2: [sz_b,len_q,d_model]
x = self.dropout(x)
x += residual # 残差连接
x = self.layer_norm(x) # 层归一化
return x # [sz_b,len_q,d_model]
相关参数的含义:
- forward输入的
x的大小是[sz_b,len_q,d_model]sz_b: batch sizelen_q: 单词的长度d_model:单词嵌入的维度
h_in: 全连接层的输入特征维度h_hid: 全连接层的输出特征维度
相关代码解读:
x = self.w_2(F.relu(self.w_1(x)))就是实现了feed forward层,如下是feed forward的计算公式。
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(\mathrm{x})=\max \left(0, \mathrm{xW}_1+\mathrm{b}_1\right) \mathrm{W}_2+\mathrm{b}_2 FFN(x)=max(0,xW1+b1)W2+b2
feed forward 一个两层的神经网络,x先通过w_1线性变换, 大小变为[sz_b,len_q,d_hid]; 然后ReLU非线性激活函数; 再通过w_2线性变换,大小变为[sz_b,len_q,d_model]。q += residual表示残差连接q = self.layer_norm(q)表示层归一化
Layers.py
EncoderLayer
EncoderLayer 定义了一个Encoder Block 模块。(如下图中的红框)

# Encoder Block
class EncoderLayer(nn.Module):
''' Compose with two layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None): # 输入的k,q,v都是 enc_input
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask) # 多头注意力机制
enc_output = self.pos_ffn(enc_output) # 前馈层
return enc_output, enc_slf_attn
# enc_output: [sz_b,len_q,d_model]
# enc_slf_attn: [sz_b, n_head, len_q, len_k]
相关参数的含义:
enc_input编码后的输入(就是对单词进行单词嵌入和位置编码后相加的结果) 大小为[sz_b,len_q,d_model]d_model:单词嵌入的维度len_q: 单词的个数sz_b: batch_size
d_x: 特征的维度。 (d_x代表d_q、d_v、d_k)slf_attn_mask: 掩码mask
相关代码解读:
enc_output, enc_slf_attn = self.slf_attn(enc_input, enc_input, enc_input, mask=slf_attn_mask)
先通过SubLayers.py文件中定义的MultiHeadAttention得到输出的大小不变,仍为[sz_b,len_q,d_model]enc_output = self.pos_ffn(enc_output),然后再把MultiHeadAttention的输出,送入到SubLayers.py文件中定义的PositionwiseFeedForward中,得到输出的大小不变,仍为[sz_b,len_q,d_model]
DecoderLayer
DecoderLayer 定义了一个Decoder Block 模块。(如下图中的红框)
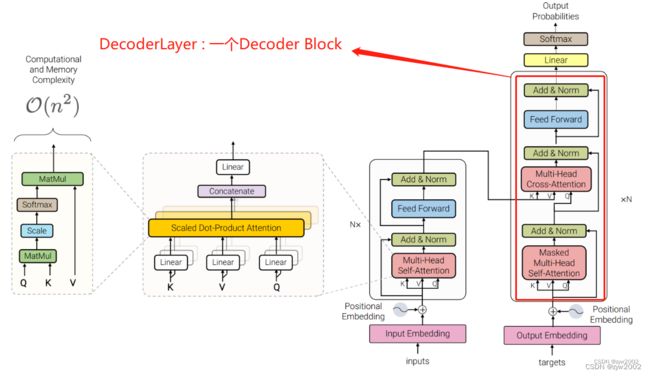
# Decoder Block
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
# dec_input: [sz_d,len_q,d_model]
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask) # 第一个多头注意力: Self attention
# 输入的q,k,v 均是dec_input
# dec_output: [sz_b,len_q,d_model]
# dec_slf_attn: [sz_b, n_head, len_q, len_k]
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask) # 第二个多头注意力: Cross Attention
# 输入的q是上一个Decoder中多头注意力的输出, k,v是Encoder的输出
dec_output = self.pos_ffn(dec_output) # 前馈网络
return dec_output, dec_slf_attn, dec_enc_attn
# dec_output: 最终编码器的输出 [sz_b,len_q,d_model]
# dec_slf_attn: 第一个多头注意力的attention score [sz_b, n_head, len_q, len_k]
# dec_enc_attn: 第二个多头注意力的attention score [sz_b, n_head, len_q, len_k]
相关参数的含义:
dec_input: 解码器的输入,大小为[sz_b,len_q,d_model]enc_output: 编码器的输入,[sz_b,len_q,d_model]slf_attn_mask: self-attention的掩码dec_enc_attn_mask: cross-attention 的掩码
相关代码解读:
dec_output, dec_slf_attn = self.slf_attn(dec_input, dec_input, dec_input, mask=slf_attn_mask)这里实现的是解码器中第一个Masked Multi-Head Self-Attentiion和Add&Norm层 (如蓝色框所示)。
q,k,v的输入都是dec_input (如下图红圈所示)。输出得到的dec_output大小为[sz_b,len_q,d_model]
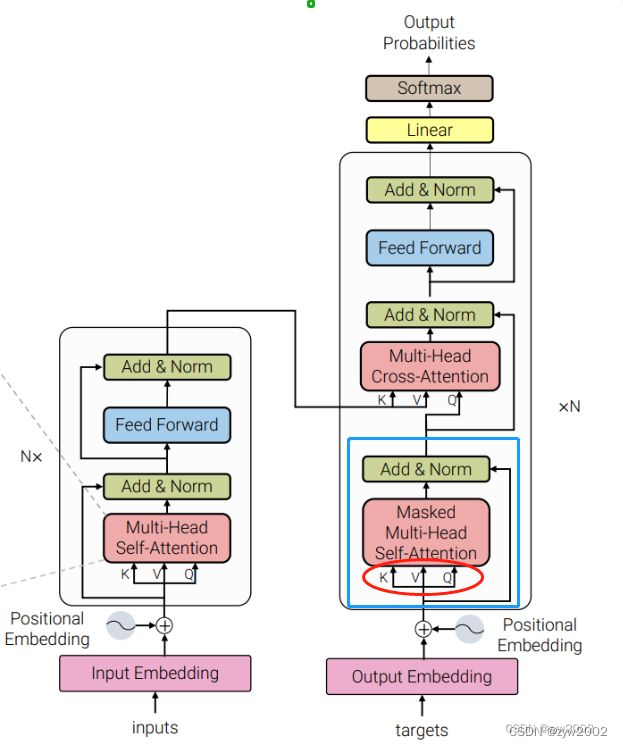
dec_output, dec_enc_attn = self.enc_attn(dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)实现的是解码器中第二个Multi-Head Cross-Attention和Add&Norm层。(如下图蓝色框所示)
q的输入来自于decoder_output (解码器上一个self-Attention 的输出,下图中的绿色圈); k,v的输入来自于enc_output(编码器的输出,下图中的红色圈)。 因为q和k,v的来源不同,所以这个多头注意力也叫做Cross-Attention。而当q,k,v的来源相同是,多头注意力就叫做Self-Attention。
输出得到的dec_output大小仍为[sz_b,len_q,d_model]
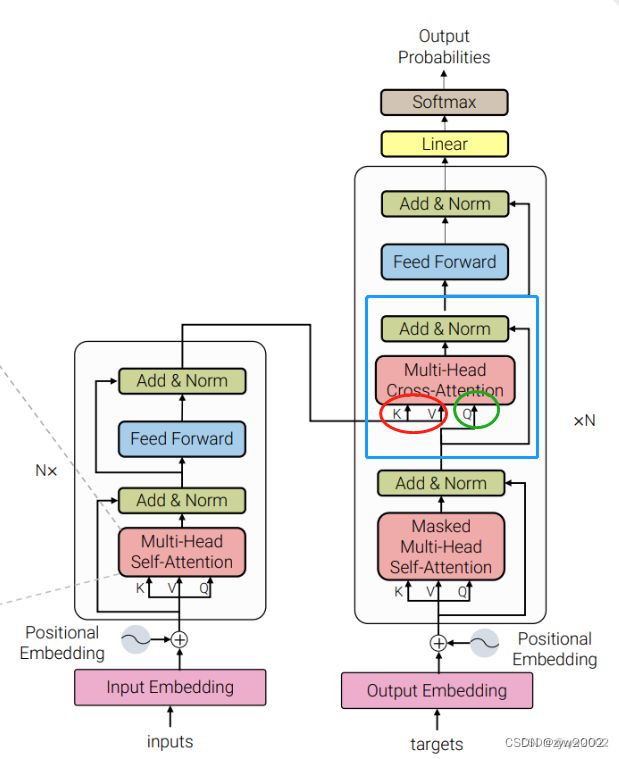
dec_output = self.pos_ffn(dec_output)就是通过Sublayers.py文件中定义的PositionwiseFeedForward得到解码器的最终的输出,大小仍为[sz_b,len_q,d_model]
Models.py
get_pad_mask
get_pad_mask实现了padding mask,因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐 。
# padding mask
def get_pad_mask(seq, pad_idx): # seq: [sz_b,len_q] pad_idx[sz_b,len_q]
return (seq != pad_idx).unsqueeze(-2) # [sz_b,1,len_q]
相关参数的含义:
seq: 输入的单词序列,pad_idx: 当单词索引所以为pad_idx时,单词嵌入用0填充。例如pad_idx=3
相关代码解读:
(seq != pad_idx).unsqueeze(-2)用来生成padding mask
假设现在有个字典,包含三个单词{0: ‘a’,1:‘b’,2:‘c’},且pad_idx=3
对于一个batch而言,输入的句子序列是“abc”对应的索引是[0,1,2] ,假设要求句子长度是5,则该序列被填充为[0,1,2,3,3]
seq!=pad_idx的输出[True,True,True,False,False]。其中为False的位置就是被mask掉的地方。
回到ScaledDotProductAttention,mask被调用的代码:attn = attn.masked_fill(mask == 0, -1e9)其中attn的大小为[sz_b, n_head, len_q, len_k]
因此对于多个batch而言,unsqueeze(-2)是为了生成head维度,输出的大小为[sz_b,1,len_q]。其中len_k的维度可以进行广播。
当mask的值为False的地方就被填充为负无穷小,softmax后就趋近于0,该区域的attn的值就被mask掉了。
get_subsequent_mask
get_subsequent_mask 用来生成sequence mask。
sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
# sequence mask
def get_subsequent_mask(seq):
sz_b, len_s = seq.size()
# sz_b: batch size l
# len_s: 句子中单词的个数
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()
''''
x= torch.ones (1, len_s, len_s) : 生成大小为[1,len_s,len_s] 全为1的矩阵
y= torch.triu(x,diagonal=1)后,y 的形状类似于:
011
001
000
1-y后:
100
110
111
然后再转换成bool值
'''
return subsequent_mask
相关参数的含义:
sz_b: batch_sizelen_s: 输入序列中单词的个数
相关代码解读:
x=torch.ones((1, len_s, len_s)用来生成大小为[1,len_s,len_s] 全为1的矩阵。
假设len_s为3,那么生成的x矩阵为
1 1 1
1 1 1
1 1 1y= torch.triu(x,diagonal=1)后,y的形状变成一个上三角矩阵
0 1 1
0 0 1
0 0 01-y后,变成了一个下三角矩阵,这个矩阵就是sequence mask
1 0 0
1 1 0
1 1 1
再结合ScaledDotProductAttention中的mask的讲解,其中mask中为0的数值,attn的内容被赋值为负无穷小,softmax后趋近于0。因此为0的内容就相当于mask掉了。
举个例子:

上图中的黄色矩形就相当于填充了0,绿色矩形相当于填充了1。
当 Decoder 的输入矩阵和 Mask 矩阵输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
PositionalEncoding
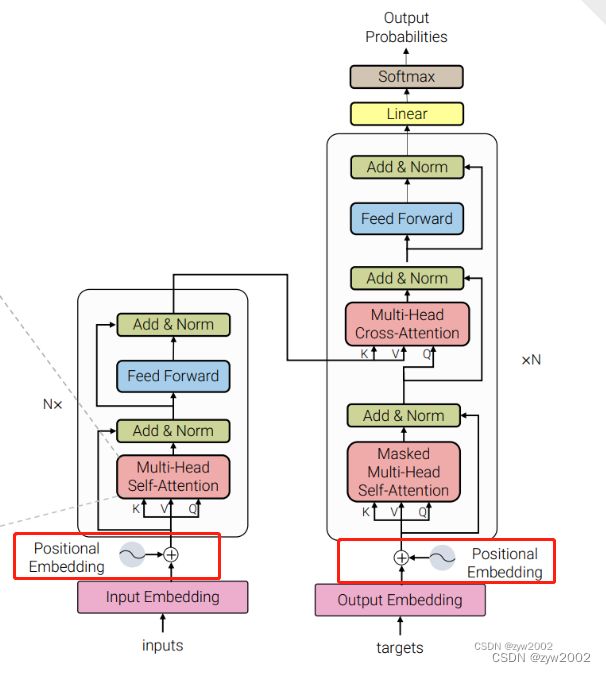
PositionalEncoding 就是对编码器和解码器输入的单词嵌入添加上位置编码。(如下图中的红框所示)
Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度一致。
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
# Not a parameter
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
''' Sinusoid position encoding table '''
# TODO: make it with torch instead of numpy
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2j
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2j+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
def forward(self, x):
# x: 单词embedding [sz_b,len_q,d_model]
# pos_table: 位置encoding
return x + self.pos_table[:, :x.size(1)].clone().detach()
相关参数的含义:
x: 输入的单词嵌入(input embedding) ,大小为[sz_b,len_q,d_model]sz_b: batch_sizelen_q: 单词的个数d_model: 单词嵌入的维度
pos_table: 生成的位置编码
相关代码解读:
_get_sinusoid_encoding_table函数就是用来生成位置编码的table
假设输入表示 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d包含一个序列中n个词元的 d 维嵌入表示。位置编码使用相同形状的位置嵌入矩阵 P ∈ R n × d \mathbf{P} \in \mathbb{R}^{n \times d} P∈Rn×d 输 出 X + P \mathbf{X}+\mathbf{P} X+P , 第 i i i行、第 2 j 2j 2j列和 2 j + 1 2j+1 2j+1列上的元素为:
p i , 2 j = sin ( i 1000 0 2 j / d ) p i , 2 j + 1 = cos ( i 1000 0 2 j / d ) . \begin{aligned} p_{i, 2 j} & =\sin \left(\frac{i}{10000^{2 j / d}}\right) \\ p_{i, 2 j+1} & =\cos \left(\frac{i}{10000^{2 j / d}}\right) . \end{aligned} pi,2jpi,2j+1=sin(100002j/di)=cos(100002j/di).
其中 i i i表示单词在句子中的绝对位置, i = 0 , 1 , 2 … i=0,1,2… i=0,1,2… 例如:Jerry在"Tom chase Jerry"中的 i = 2 i=2 i=2; d m o d e l d_{model} dmodel表示词向量的维度,在这里 d m o d e l = 512 d_{model}=512 dmodel=512; 2 j 2j 2j和 2 j + 1 2j+1 2j+1表示奇偶性, j j j表示词向量中的第几维,例如这里 d m o d e l = 512 d_{model}=512 dmodel=512,故 j = 0 , 1 , 2 … 255 j=0,1,2…255 j=0,1,2…255。
Encoder
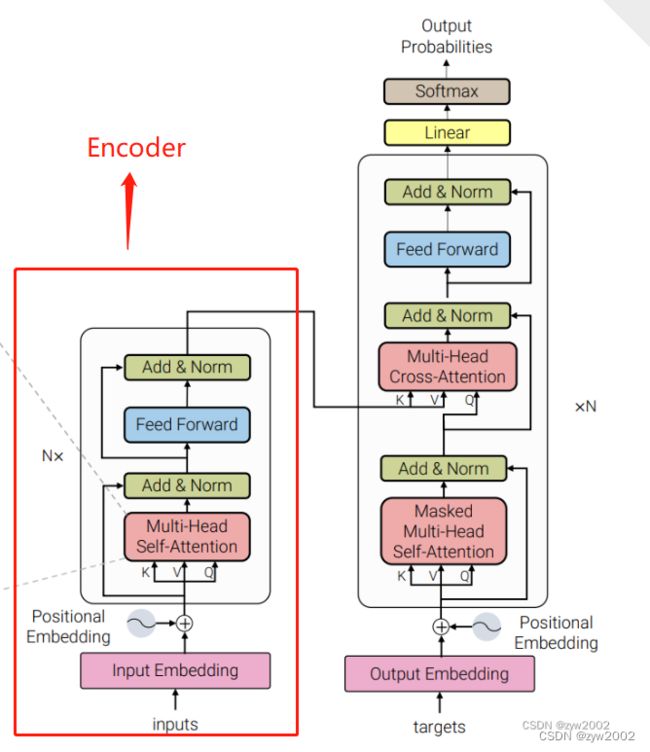
Encoder实现了如下图红框的部分。
# 编码器
class Encoder(nn.Module):
''' A encoder model with self attention mechanism. '''
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx) # 词嵌入
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) # 位置编码
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)]) # n_layers个encoder block
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
# -- Forward
enc_output = self.src_word_emb(src_seq) # 词嵌入[sz_b,len_q]-> [sz_b,len_q,d_model]
if self.scale_emb:
enc_output *= self.d_model ** 0.5 # 归一化
enc_output = self.dropout(self.position_enc(enc_output)) # 位置编码
enc_output = self.layer_norm(enc_output) # 层归一化
for enc_layer in self.layer_stack: # N 个Encoder Block
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
# enc_output: [sz_b,len_q,d_model]
# enc_slf_attn: [sz_b, n_head, len_q, len_k]
# enc_slf_attn_list 是n个encoder block产生的enc_slf_attn 构成的列表
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
相关参数的含义:
src_seq编码器输入的原始单词序列scale_emb控制是否进行缩放单词嵌入layer_stack是一个由 n_layers个encoder block 组成的ModelListn_src_vocab: nn.Embedding层定义的单词表中单词的总个数d_word_vec:nn.Embedding层输出的单词嵌入的特征维度, 相当于d_modelpadding_idx: 当单词表中的单词索引为padding_idx,输出的单词嵌入用0填充。
相关代码解读:
enc_output = self.src_word_emb(src_seq)通过单词嵌入得到的Input Embedding, 大小为[sz_b,len_q,d_model]enc_output *= self.d_model ** 0.5如果需要进行归一化,则对单词嵌入乘以 d m o d e l \sqrt{d_{model}} dmodelenc_output = self.dropout(self.position_enc(enc_output))先进行位置编码,然后和单词嵌入相加,再通过一个dropoutenc_output = self.layer_norm(enc_output)通过一个层归一化enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)然后遍历layer_stack这个ModelList,每次都把上一个EncoderBlock的输出输入到下一个EncoderBlock中,共串联经过n_layers个Encoder Block。最终输出的enc_output的大小为[sz_b,len_q,d_model]
Decoder
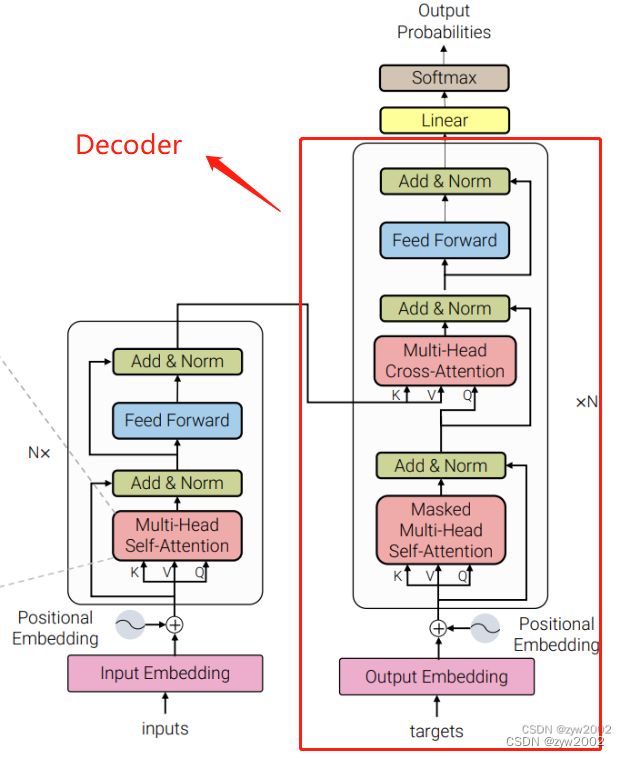
Decoder实现了下图中红框的部分。
# 解码器
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx) # 单词嵌入
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position) # 位置编码
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward
dec_output = self.trg_word_emb(trg_seq) # 单词嵌入 [sz_b,len_q,d_model]
if self.scale_emb:
dec_output *= self.d_model ** 0.5
dec_output = self.dropout(self.position_enc(dec_output)) # 位置编码
dec_output = self.layer_norm(dec_output) #层归一化
for dec_layer in self.layer_stack: # N个decoder block
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
# dec_output: [sz_b,len_q,d_model]
# dec_slf_attn: self-attention的attn[sz_b, n_head, len_q, len_k]
# dec_enc_attn: cross-attention的attn[sz_b, n_head, len_q, len_k]
# dec_slf_attn_list 是n个decoder block产生的enc_slf_attn 构成的列表
# dec_enc_attn_list 是n个decoder block产生的enc_enc_attn 构成的列表
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output,
相关参数的含义:
tar_seq解码器输入的原始单词序列scale_emb控制是否进行缩放单词嵌入layer_stack是一个由 n_layers个decoder block 组成的ModelList
相关代码解读:
dec_output = self.trg_word_emb(trg_seq)先对输入的单词序列进行单词嵌入,得到Input Embedding,大小为[sz_b,len_q,d_model]dec_output *= self.d_model ** 0.5如果需要进行归一化,则对单词嵌入乘以 d m o d e l \sqrt{d_{model}} dmodeldec_output = self.dropout(self.position_enc(dec_output))将单词嵌入添加上位置编码,并进行droupoutdec_output = self.layer_norm(dec_output)通过层归一化dec_output, dec_slf_attn, dec_enc_attn = dec_layer(dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)通过 n_layers个串联的decoder block, 最终得到的输出dec_output的大小为[sz_b,len_q,d_model]
Transformer
Transformer实现的就是整体的架构。(如下图红框中的内容)

# Transformer
class Transformer(nn.Module):
''' A sequence to sequence model with attention mechanism. '''
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,
scale_emb_or_prj='prj'):
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
# In section 3.4 of paper "Attention Is All You Need", there is such detail:
# "In our model, we share the same weight matrix between the two
# embedding layers and the pre-softmax linear transformation...
# In the embedding layers, we multiply those weights by \sqrt{d_model}".
#
# Options here:
# 'emb': multiply \sqrt{d_model} to embedding output
# 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output
# 'none': no multiplication
assert scale_emb_or_prj in ['emb', 'prj', 'none']
scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else False
self.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else False
self.d_model = d_model
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'
if trg_emb_prj_weight_sharing:
# Share the weight between target word embedding & last dense layer
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
if emb_src_trg_weight_sharing:
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
# src_seq (b_sz,len_q)
src_mask = get_pad_mask(src_seq, self.src_pad_idx) # 对于输入,padding mask
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq) # 对于输出:padding mask+ sequence mask
enc_output, *_ = self.encoder(src_seq, src_mask) # Encoder
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask) # Decoder
# enc_output: (b_sz,len_q,d_model)
# dec_output: (b_sz,len_q,d_model)
seq_logit = self.trg_word_prj(dec_output)
#seq_logit: (b_sz,len_q,n_trg_vocab)
if self.scale_prj:
seq_logit *= self.d_model ** -0.5
return seq_logit.view(-1, seq_logit.size(2)) # (b_sz*len_q,n_trg_vocab)
相关参数的含义:
src_seq编码器输入的原始单词序列trg_seq解码器输入的原始单词序列n_trg_vocab目标词汇表的长度
相关代码解读:
src_mask = get_pad_mask(src_seq, self.src_pad_idx)对于编码器的输入,需要进行padding mask, 为统一单词序列的长度trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)对于解码器的输入,不仅需要padding mask 统一单词序列的长度, 还需要sequence mask,使得预测的时候我们只能得到前一时刻预测出的输出,而看不到后面的单词。enc_output, *_ = self.encoder(src_seq, src_mask)首先先通过编码器dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)然后再通过解码器seq_logit = self.trg_word_prj(dec_output)通过一个线性层,把单词嵌入的维度映射到词汇表的维度,大小从(b_sz,len_q,d_model)变为(b_sz,len_q,n_trg_vocab)如下图红框所示
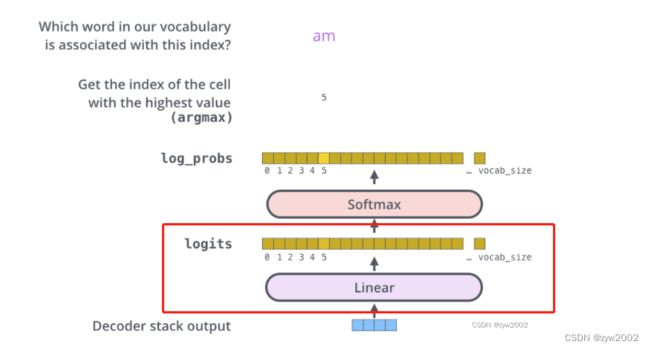
seq_logit *= self.d_model ** -0.5如果scale_prj为真,则对输出的seq_logic 乘以 d m o d e l \sqrt{d_{model}} dmodelseq_logit.view(-1, seq_logit.size(2))把seq_logit的前两个维度合并到一起,大小变成(b_sz*len_q,n_trg_vocab)