Wiz 如何使用 Amazon ElastiCache 提高性能和降低成本

这是由 Wiz 高级软件工程师 Sagi Tsofan
与亚马逊云科技共同撰写的特约文章。
在 Wiz,一切都与规模有关。我们的平台每天摄取数百亿种云资源的元数据和遥测数据。我们的无代理扫描程序收集了大量数据,我们需要非常高效地处理这些数据。随着公司的发展,我们在如何有效维护和扩大规模方面面临重大挑战。在这篇文章中,我们描述了有关使用 Amazon ElastiCache 的技术挑战和解决方案,它不仅提高了我们的业务效率,而且增加了我们为客户创造的价值。
![]()
在 Wiz 于 2020 年成立时,我们着手帮助安全团队降低其云风险。我们在短时间内取得了长足的进步,打破了融资、估值和 ARR 记录,成为了有史以来发展最快的软件即服务(SaaS)公司,并达到了 1 亿美元的 ARR 里程碑。
Wiz 平台向客户展示了其云环境状态的最新视图。这意味着,Wiz 平台上将尽快反映每项更改,无论是创建新的云资源、更改现有云资源还是删除现有云资源。
下图显示了 Wiz 平台中客户的云账户的当前视图。

为了向我们的客户提供此视图,我们实施了无代理扫描程序,该扫描程序会频繁扫描客户的云账户。该扫描程序的主要任务是,为它在客户的云帐户中看到的所有云资源编写目录。将记录从 Amazon Elastic Compute Cloud(Amazon EC2)实例到 Amazon Identity and Access Management(IAM)角色,再到 Amazon Virtual Private Cloud(Amazon VPC)网络安全组等的一切资源。
扫描结果将记录在 Wiz 后端,所有这些云资源都将通过数据管道进行摄取。下图中显示了我们引入 Amazon ElastiCache 之前的此过程中的步骤。

管道由以下阶段组成:
云扫描程序服务按计划触发,并开始对客户账户进行新的扫描。
此扫描程序将枚举客户云账户中的所有云资源,然后通过 Amazon Simple Notification Service(Amazon SNS)主题将有关这些资源的信息发布到 Amazon Simple Queue Service(Amazon SQS)。
之后,摄取程序负责使用这些来自 SQS 队列的消息。
对于每条消息,将使用相关的云资源元数据对执行程序组件进行远程过程调用(RPC)。
执行程序的责任是将云资源更新插入到 Amazon Aurora PostgreSQL 兼容版数据库中,更新整个云资源元数据(包括其上次看到的时间戳和当前扫描运行 ID),我们稍后将使用这些数据来删除客户账户中不再显示的云资源。
挑战
当我们考虑同时运行的并发客户、云提供商、账户、订阅、工作负载和数千个并发扫描的数量时,就会出现挑战。
Wiz 平台每天摄取数百亿次云资源更新。以前,我们会在每次扫描后更新每项云资源的记录,即使该资源自上次扫描以来未发生变化。我们之所以这样做,是因为我们需要通过更新资源记录中的上次查看和运行 ID 值,来记住需要在步骤 5 中从数据库中删除哪些资源。这给我们的数据库额外带来了大量负载。
我们需要考虑通过一种更有效的方法来计算每次扫描后需要删除哪些云资源,并减少对数据库的写入次数。
下图显示了按状态分组的更新插入的云资源总量。对于此客户,90% 的云资源尚未发生更改。

目标
在过去的几个月里,我们实施了一项变更来优化我们的摄取管道。我们的主要目标是通过避免在云资源保持不变时进行更新,从而显著减少数据库写入次数。这有助于我们实现以下目标:
消除来自数据库的压力,这将提高查询性能并减少查询延迟
减少 PostgreSQL 事务 ID 的使用量,并减小 autovacuum 频率以避免事务 ID 回卷
减少 CPU、读取、写入、吞吐量和 IO 的使用量
适当调整数据库实例类型的大小以优化成本
Amazon ElastiCache 前来相助
Amazon ElastiCache for Redis 是一项完全托管的亚马逊云科技服务。它是一种高度可扩展、安全的内存中缓存服务,可支持需要亚毫秒级响应时间的最苛刻的应用程序。它还提供了内置的安全性、备份与恢复以及跨区域复制功能。
我们决定利用 Redis 的内置功能和对数据结构的原生服务器端支持,来存储和计算每次扫描程序运行后需要删除的云资源。
我们发现,可以通过使用 Set 数据模型来实现此目标,该模型是唯一字符串的无序集合,可以在其中添加或删除数据,也可以将它与其他集合进行比较。
当扫描程序观察一个云资源时,都会将其唯一标识符添加(使用 SADD 命令)到当前扫描运行集合中,以便每次扫描运行都会填充自己的集合密钥,该密钥最终将包含当前扫描运行期间观察到的所有云资源 ID。
当扫描程序完成并且该计算应删除哪些云资源时,我们(使用 SDIFF 命令)与上一个扫描运行集合进行比较。此比较的输出是一组需要从数据库中删除的云资源 ID。通过使用 ElastiCache 对 Set 数据类型的原生支持,我们可以将整个比较过程从数据库转至 ElastiCache 引擎。
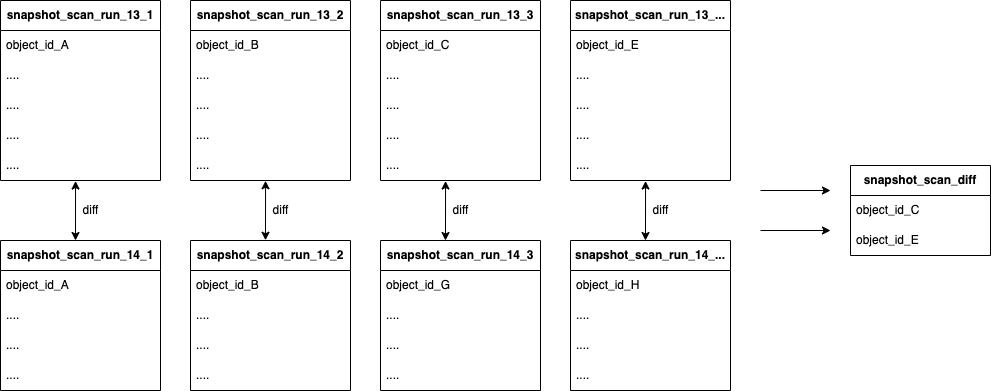
让我们来看一个基本示例:
扫描 13 将五个(新)云资源发布到集合中:A、B、C、D 和 E
扫描 14 将四个(一部分是新的,一部分是现有的)云资源发布到集合中:A、B、G 和 H
这两个扫描之间的区别将是 C、D 和 E,这意味着,这些是需要从数据库中删除的云资源,因为它们不再存在
将填充 Redis 中的集合,如下所示。在这篇文章中,我们说明了如何使用 Redis CLI 填充和比较集合。
> sadd snapshot_scan_run_13 A B C D E
(integer) 5
> sadd snapshot_scan_run_14 A B G H
(integer) 4
> smembers snapshot_scan_run_13
1) "D"
2) "C"
3) "B"
4) "A"
5) "E"
> smembers snapshot_scan_run_14
1) "H"
2) "B"
3) "G"
4) "A"
> sdiff snapshot_scan_run_13 snapshot_scan_run_14
1) "D"
2) "C"
3) "E"左滑查看更多
我们需要向摄取管道添加两个新步骤(下图中用红色显示):
扫描程序在 ElastiCache 中将观察到的云资源 ID 填充到集合中
仅当我们识别出自上次扫描以来的实际云资源更改时,执行程序才会将云资源更新插入到数据库中
现在,生成的架构如下图所示。

在扫描程序完成账户发现后,它会通过 Amazon SNS 和 Amazon SQS 发送“完成”消息。然后,执行程序开始使用 Redis 中的 SDIFF 命令计算扫描之间的差异,然后从数据库中删除生成的 ID。下图展示了删除流程架构。

结果
在将整个更改部署到生产环境后,我们就立即发现数据库有所改进。CPU 和内存使用量显著降低,这使我们能够适当调整数据库实例的大小。
现在,90% 的云资源将被跳过,而根本不会写入到数据库中!
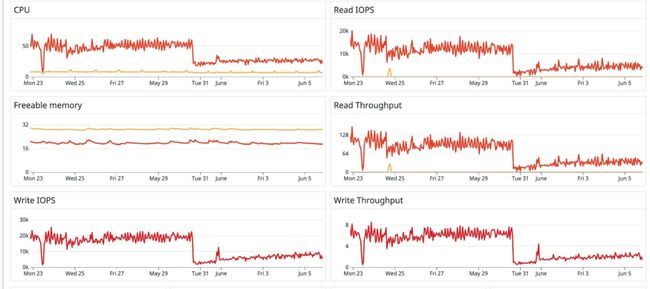
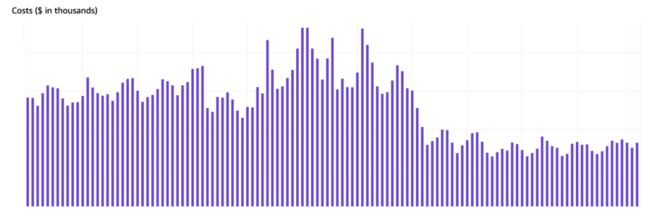
我们还观察到,在做出更改后,IO 和成本也相应地降低了,如以下 Amazon Cost Explorer 成本管理服务图表中所示。
挑战和经验教训
在这次重大基础设施更改期间,我们遇到了许多挑战,其中的大多数挑战是扩展问题。
逻辑分片
我们的扫描程序每次扫描都会枚举数亿个云资源。每个 Redis 集合最多可容纳 40 亿个项目。但是,在两个非常大的集合上运行 SDIFF 命令将占用大量 CPU 和内存。在我们的示例中,在条目过多的集合上运行 SDIFF 会导致我们的工作流程在比较完成前超时。
根据 ElastiCache 服务团队的建议,我们决定对我们的集合进行逻辑分片。我们不使用一个包含数亿个条目的巨大集合,而是利用 ElastiCache 的分布式特性将它拆分为多个小型集合,每个集合均包含云资源 ID 的一部分。ElastiCache 服务团队建议我们在每个集合中输入的条目不要超过约 150 万个。这为我们的工作负载提供了可接受的运行时。
删除流程现在需要合并多个分片集合并计算它们的差异。下图展示了 ElastiCache 中的分片集合结构:两次扫描迭代,其中每次扫描均在多个集合上对观察到的云资源 ID 进行分片。
现在,我们必须保证始终比较相同的分片集合,并将每个云资源存储在同一个分片上。否则,我们的比较将导致差异结果损坏,这会导致不必要的云资源删除。我们通过确定性地为每个云资源计算一个分片来实现这一点。
已启用集群模式
由于我们进行了大量扫描,因此我们便也有大量的集合,每个集合包含数百万个项目。无法将如此多的数据放入一个 ElastiCache 节点,因为我们很快就会达到最大内存大小。
我们需要通过一种方式将集合分布在不同的分片上,并且能够不时扩展内存,而无需更改 ElastiCache 实例类的类型。
我们已决定迁移到已启用集群模式(CME)的 ElastiCache,这使我们能够在需要更多内存时轻松地将新的分片添加到集群中。
从“已禁用集群模式”到“已启用集群模式”的迁移过程包括使用新的 SDK 库,以及标记缓存密钥以控制密钥组在同一分片中的位置。
管道
Redis 管道用于通过一次性运行多条命令来提高性能,而无需等待每条单独的命令的响应。
我们采用管道机制在扫描期间存储和批处理命令,这些命令将发送到 ElastiCache 以减少客户端-服务器的往返。
这可让我们减少每秒在 ElastiCache 集群上执行的操作数。
总结
通过在 Amazon Aurora PostgreSQL 兼容版数据库前添加 ElastiCache,我们提高了整体应用程序性能,减小了数据库上的压力,能够适当调整数据库实例的大小,节省了 TCO,同时扩大了规模并处理了更多客户负载。
在将最终结果存储在 Amazon Aurora PostgreSQL 兼容版本数据库之前,我们使用 ElastiCache 消除了大批数据库更新。在此过程中,我们利用了每个数据库引擎的长处。Redis 是用于存储高速数据的绝佳工具,而 PostgreSQL 更适合长期存储和分析。
ElastiCache 是我们的摄取管道中的关键组件。它使我们能够显著扩展,从而能够处理更多的扫描和云资源摄取。通过这样做,我们设法提高了数据库性能,减少了实例类型,并将总成本降低了 30%(包括 ElastiCache 成本)。此外,我们使用 ElastiCache 预留节点进一步降低了成本。
Original URL:
https://aws.amazon.com/blogs/database/how-wiz-used-amazon-elasticache-to-improve-performance-and-reduce-costs/
本篇作者

Sagi Tsofan 是 Wiz 工程团队的软件工程师,主要关注产品基础设施和扩展领域。他在构建大规模分布式系统方面拥有超过 15 年的经验,并且在为 Wiz、Wix、XM Cyber 和 IDF 等公司开发和构建高度可扩展的解决方案方面有深度的理解和丰富的经验。当不在屏幕前时,他喜欢打网球、旅行以及与朋友和家人共度时光。

Tim Gustafson 是亚马逊云科技的首席数据库解决方案架构师,专注于开源数据库引擎和 Aurora。当不在Amazon Website Service上帮助客户处理数据库时,他喜欢花时间在 Amazon Website Service上开发自己的项目。


听说,点完下面4个按钮
就不会碰到bug了!
