ELMO模型
ELMo
Paper: https://arxiv.org/pdf/1802.05365.pdf
《Deep Contextualized Word Representations》是来自华盛顿大学的一篇论文,该论文在NAACL上获得了最佳论文。
论文大致内容
- 介绍了一种新的词向量表征可以解决词语义特征和语境特征。
- 向量是在大规模语料通过bidirectional language model学习到的。
- elmo模型在各项nlp下游任务中都表现得良好。
- 暴露预训练的深层内部是至关重要的,允许下游模型混合不同类型的半监督信号。
不同与Word2Vec方法中固定的词向量表示,ELMo通过双向LSTM,同时考虑了上下文的信息,从而较好地解决了多义词的表示问题。
ELMo基本结构

可以看出,ELMo本质是一个双向LSTM结构的语言模型,对于一个含有N个单词的序列 t 1 , t 2 , t 3 , . . . t N t_1, t_2, t_3,...t_N t1,t2,t3,...tN,前向LSTM语言模型通过单词 t k t_k tk的”上文“ ( t 1 , t 2 , . . . , t k − 1 ) (t_1, t_2, ..., t_{k-1}) (t1,t2,...,tk−1)计算概率:
p ( t 1 , t 2 , . . . t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . t k − 1 ) p(t_1, t_2,...t_{N})=\prod_{k=1}^{N}p(t_k|t_1,t_2,...t_{k-1}) p(t1,t2,...tN)=k=1∏Np(tk∣t1,t2,...tk−1)
前向LSTM语言模型在第j层,k时刻的输出向量定义为 h k , j L M → \overrightarrow{h^{LM}_{k,j}} hk,jLM,其中 j = 1 , 2 , . . . , L j=1,2,...,L j=1,2,...,L。经过LSTM之后,第L层的输出为 h k , L L M → \overrightarrow{h^{LM}_{k,L}} hk,LLM,再通过SoftMax层,即可进行下一个词的预测。
后向LSTM语言模型则通过单词 t k t_k tk的”下文“ t k + 1 , t k + 2 . . . , t N t_{k+1}, t_{k+2}...,t_N tk+1,tk+2...,tN计算当前单词的概率:
p ( t 1 , t 2 . . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p(t_1, t_2....,t_N)=\prod_{k=1}^{N}p(t_k|t_{k+1},t_{k+2},...,t_N) p(t1,t2....,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)
同样地,后向LSTM语言模型在第j层,k时刻的输出向量定义为 h k , j L M ← \overleftarrow{h^{LM}_{k,j}} hk,jLM,其中 j = 1 , 2 , . . . , L j=1,2,...,L j=1,2,...,L,经过LSTM之后,第L层的输出为KaTeX parse error: Expected '}', got 'EOF' at end of input: …ow{h^{LM}_{k,j},再通过Softmax层,即可进行下一词的预测。
而双向语言模型,整合了词 t k t_k tk的”上文“和”下文“的信息,最大化了以下对数似然概率:
∑ k = 1 n ( l o g p ( t k ∣ t 1 , t 2 , . . . . , t k − 1 , Θ x , Θ → L S T M , Θ s ) + l o g p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) , Θ x , Θ ← L S T M , Θ s ) \sum_{k=1}^{n}(log p(t_k|t_1,t_2,....,t_{k-1},\Theta_x,\overrightarrow{\Theta}_{LSTM}, \Theta_s)+logp(t_k|t_{k+1}, t_{k+2},...,t_N),\Theta_x,\overleftarrow{\Theta}_{LSTM}, \Theta_s) k=1∑n(logp(tk∣t1,t2,....,tk−1,Θx,ΘLSTM,Θs)+logp(tk∣tk+1,tk+2,...,tN),Θx,ΘLSTM,Θs)
其中, Θ → L S T M \overrightarrow{\Theta}_{LSTM} ΘLSTM表示前向LSTM语言模型的网络参数, Θ ← L S T M \overleftarrow{\Theta}_{LSTM} ΘLSTM表示后向LSTM语言模型参数。 Θ x , Θ s \Theta_x, \Theta_s Θx,Θs表示两个网络的共享参数,其中 Θ x \Theta_x Θx表示将单词映射为词向量的参数, Θ s \Theta_s Θs表示Softmax层的网络参数。
对于每个单词 t k t_k tk,一个L层的双向语言模型需要计算2L+1个表征:
R k = { X k L M , h k , j L M → , h k , j L M ← ∣ j = 1 , 2.... , L } = { h k , j L M ∣ j = 0 , 1 , . . . , L } R_k=\{X_{k}^{LM}, \overrightarrow{h^{LM}_{k,j}}, \overleftarrow{h^{LM}_{k,j}}|j=1,2....,L\}=\{h^{LM}_{k,j}|j=0,1,...,L\} Rk={XkLM,hk,jLM,hk,jLM∣j=1,2....,L}={hk,jLM∣j=0,1,...,L}
其中, X k L M X_{k}^{LM} XkLM是单词 t k t_k tk的向量表示,对于每一层的双向LSTM语言模型, h k , j L M = [ h k , j L M → , h k , j L M ← ] h^{LM}_{k,j}=[\overrightarrow{h^{LM}_{k,j}}, \overleftarrow{h^{LM}_{k,j}}] hk,jLM=[hk,jLM,hk,jLM],即每一层有一个向前LSTM的输出拼接一个后向LSTM的输出。当j=0时,也就是第一层, h k , 0 L M h^{LM}_{k,0} hk,0LM代表了输入向量层。再模型的下游, R x R_x Rx被压缩为一个向量,表示为 E L M o k = E ( R k ; Θ e ) ELMo_k=E(R_k;\Theta_e) ELMok=E(Rk;Θe)。
那么,如何得到最后的词向量表示呢?一个简单的方法是将最上层的向量输出,即 E ( R k ) = h k , L L M E(R_k)=h^{LM}_{k,L} E(Rk)=hk,LLM,针对不同的任务,考虑到每一层LSTM学到的信息不同,每一层的向量重要性也会有区别,这里需要给每一层的向量添加一个权重,可以写成
E L M o k t a s k = E ( R k ; Θ t a s k ) = γ t a s k ∑ j = 0 L s j t a s k h k , L L M ELMo_k^{task}=E(R_k;\Theta^{task})=\gamma^{task}\sum_{j=0}^{L}s_j^{task}h_{k,L}^{LM} ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtaskhk,LLM
上式中,将每一层的向量乘以一个权重s^{task},相加之后,再乘以一个缩放系数 γ t a s k \gamma^{task} γtask,就得到了ELMo模型的词向量。
ELMo模型的词向量 E L M o k t a s k ELMo_{k}^{task} ELMoktask该如何使用呢? 在自然语言处理下游任务的过程中,由于大多数监督模型在底层的结构大致相同,可以用统一的方式来添加ELMo词向量。举例说明,对于一个含有N个单词的序列 t 1 , t 2 , . . . t N t_1, t_2,...t_N t1,t2,...tN,其上下文无关的嵌入式表示 x k L M x_k^{LM} xkLM与 E L M o k t a s k ELMo_k^{task} ELMoktask进行拼接,最后得到单词的最终词向量。这也是为什么上一个公式中需要有一个缩放系数 γ t a s k \gamma^{task} γtask的原因。
如下图所示
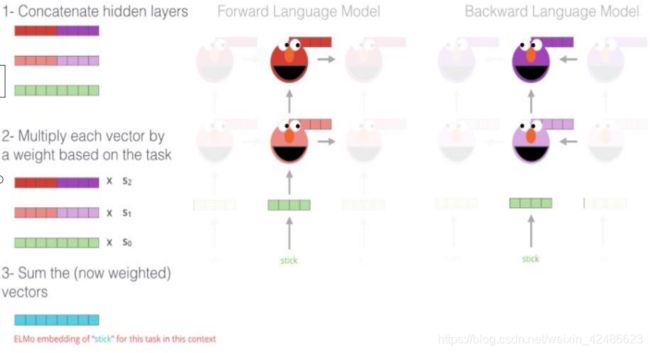
(1)将每层的forward和backward的hideen layer进行concat[batch_size,max_length,hidden_units]
(2)将concat后的vector乘以学习到的weight
(3)将weight后的向量进行求和得到最终的结果向量
代码实现
有三种方法可以使用预训练好的elmo模型。
- elmo官方allenNLP发布的基于pytorch实现的版本allenNLP;
- elmo官方发布的基于tensorflow实现的版本tensorflow;
- tensorflow-hub中google基于tensorflow实现的elmo的版本tensorflow-hub。
注意
(1)在big data中训练elmo模型,获取想要的embedding结果缺点:耗时耗力。不推荐(https://github.com/allenai/bilm-tf)
(https://github.com/HIT-SCIR/ELMoForManyLangs)
(2)直接加载训练好的预训练模型和文件,在小数据集上训练获得最终的结果。
推荐
(https://github.com/allenai/bilm-tf)tensorflow实现
(https://github.com/strongio/keras-elmo/blob/master/Elmo%20Keras.ipynb)keras实现
https://github.com/allenai/allennlp/blob/9a6962f00d2b0d30b81900b4e9764ddc3433f400/tutorials/how_to/elmo.md)pytorch实现
tensorflow-hub实现
import tensorflow_hub as hub
# 加载模型
elmo = hub.Module("https://tfhub.dev/google/elmo/2", trainable=True)
# 输入的数据集
texts = ["the cat is on the mat", "dogs are in the fog"]
embeddings = elmo(
texts,
signature="default",
as_dict=True)["default"]
参考
《预训练语言模型》邵浩
ELMo原理解析及简单上手使用 https://zhuanlan.zhihu.com/p/51679783
欢迎关注公众号:
