【译】Privacy and machine learning: two unexpected allies
关键是一个称为教师集合私人聚合 (PATE)的算法家族。 除了它的名字之外,关于PATE框架的一个伟大的事情是,任何知道如何训练监督ML模型(例如神经网络)的人现在都可以贡献于机器学习的差别隐私研究。 PATE框架通过仔细协调几种不同ML模型的活动来实现私人学习。 只要您遵循PATE框架指定的程序,整体结果模型将具有可衡量的隐私保证。 每个单独的ML模型都使用普通的监督式学习技术进行培训,我们的许多读者可能熟悉从ImageNet分类或许多其他更传统的ML追求中熟悉的技术。
如果任何人都可以为PATE使用的任何单个模型设计更好的架构或更好的训练算法,那么他们也可以改进本身的监督学习(即非私人分类)。 事实上,不同的隐私可以被认为是一个正规化者,能够解决从业者经常遇到的一些问题 - 即使在隐私不是要求的情况下也是如此。 这包括过度配合。 我们在这篇文章中详细阐述了隐私和学习之间的这些愉快的协同作用。 特别是,我们介绍了PATE最近的一个扩展,它改进了如何协调不同的ML模型,以同时提高由PATE框架产生的模型的准确性和隐私性。 这表明如何将差异隐私的目标与追求一般化良好的学习模型相结合。
为什么我们需要私人机器学习算法?
机器学习算法通过研究大量数据并更新其参数来编码数据中的关系。 理想情况下,我们希望这些机器学习模型的参数能够编码一般模式(“吸烟患者更可能患有心脏疾病的患者”),而不是关于特定培训例子的事实(“Jane Smith患有心脏病”)。 不幸的是,机器学习算法默认不学习忽略这些细节。 如果我们想用机器学习来解决一个重要的任务,比如制作一个癌症诊断模型,那么当我们发布这个机器学习模型时(例如,为全世界的医生制作一个开源癌症诊断模型),我们也可能会无意中透露有关训练集的信息。 恶意攻击者可能能够检查已发布的模型并学习Jane Smith的私人信息[SSS17]。 这是有差别的隐私进来的地方。
我们如何定义和保证隐私?
科学家们提出了许多方法来分析数据时提供隐私。 例如,在分析数据之前匿名化数据是非常流行的,通过移除私人细节或用随机值替换数据。 通常匿名的细节常见例子包括电话号码和邮政编码。 然而,匿名数据并不总是足够的,它提供的隐私会随着攻击者获取关于数据集中表示的个人的辅助信息而迅速降低。 着名的是,这一策略允许研究人员在发布给Netflix奖的参与者的电影评级数据集中取消匿名化,当时个人还在互联网电影数据库(IMDb)上公开分享了他们的电影评级[NS08]。 如果Jane Smith已经在Netflix Prize数据集中公布了相同的评级给电影A,B和C并公开在IMDb上,那么研究人员可以在两个数据集之间链接对应Jane的数据。 这将使他们有能力恢复Netflix奖但不包括在IMDb中的评级。 这个例子显示了定义和保证隐私是多么的困难,因为很难估计可用于敌手的知识范围 - 关于个人。
差别隐私是评估由旨在保护隐私的机制提供的保证的框架。 由Cynthia Dwork,Frank McSherry,Kobbi Nissim和Adam Smith发明[DMNS06],它解决了像k-匿名之类的先前方法的许多局限性。 基本思想是随机化部分机制的行为来提供隐私。 在我们的例子中,所考虑的机制始终是一种学习算法,但差分隐私框架可以用于研究任何算法。
将随机性引入学习算法的直觉是使得很难判断学习参数定义的模型的哪些行为方面来自随机性,哪些来自训练数据。 如果没有随机性,我们可以提问如下问题:“当我们在这个特定数据集上训练时,学习算法选择了什么参数?”在学习算法中使用随机性,我们会问如下问题:“学习算法会在这组可能的参数中选择参数,当我们在这个特定的数据集上进行训练时?“
我们使用差分隐私的版本,要求如果我们更改训练集中的单个训练样例,学习任何特定参数集的概率保持大致相同。 这可能意味着添加训练示例,删除训练示例,或更改一个训练示例中的值。 直觉是,如果单个患者(Jane Smith)不影响学习成果,那么该患者的记录就不会被记住,并且她的隐私受到尊重。 在这篇文章的其余部分,我们经常把这个概率称为隐私预算 。 较小的隐私预算对应于更强的隐私保证。

在上面的例子中,当敌手不能根据三个用户中的两个用户的数据从基于所有三个用户的数据的相同算法返回的答案中区分随机算法产生的答案时,我们实现差分隐私。
PATE背后的直觉是什么?
我们的PATE方法为机器学习提供差分隐私是基于一个简单的直觉:如果两个不同的分类器在两个不同的数据集上训练,没有训练样例的共同点,就如何分类一个新的输入示例达成一致,那么这个决定不会揭示有关任何单个培训示例的信息。 这个决策可能是在没有任何单一训练的情况下进行的,因为用这个例子训练的模型和没有这个例子训练的模型都得出了相同的结论。
那么假设我们有两个模型在不同的数据上进行训练。 当他们对意见达成一致时,似乎我们可以发布他们的决定。 不幸的是,当他们不同意时,不知道该怎么做。 我们不能单独发布每个模型的类输出,因为每个模型预测的类可能会泄漏其训练数据中包含的一些私人信息。 例如,假设Jane Smith只对两个模型中的一个模型的训练数据作出了贡献。 如果该模型预测,与Jane's记录非常相似的患者患有癌症,而另一个模型预测相反,则可以揭示Jane的隐私信息。 这个简单的例子说明了为什么为算法添加随机性是确保它提供任何有意义的隐私保证的要求。
PATE如何工作?
现在让我们逐步了解PATE框架如何以此观察为基础,从私人数据中负责任地学习。 在PATE中,我们首先将私有数据集划分为数据子集。 这些子集是分区,因此任何分区对中包含的数据之间不会有重叠。 如果Jane Smith的记录位于我们的私人数据集中,那么它只包含在其中一个分区中。 我们在每个分区上训练一个称为教师的ML模型。 教师如何接受培训没有任何限制。 这实际上是PATE的主要优点之一:对于用于创建教师模型的学习算法是不可知的。 所有的老师都解决了相同的机器学习任务,但他们都是独立进行的。 也就是说,只有一位老师在培训期间分析了简史密斯的记录。 这里是这个框架的一部分的例子。

我们现在有一套独立训练的教师模型,但没有任何隐私保证。 我们如何使用这个集合进行尊重隐私的预测? 在PATE中,我们增加了噪音,同时汇总了每位教师单独进行的预测,以形成一个单一的常见预测。 我们计算每个班级投票的教师数量,然后通过添加从拉普拉斯或高斯分布采样的随机噪声来扰乱计数。 熟悉差别隐私文献的读者将认识到噪声最大化机制。 当两个输出类别从老师那里得到相等(或准等于)的选票数量时,噪音将确保具有最多选票数量的班级成为随机选择的这两个班级中的一个。 另一方面,如果大多数教师同意在同一个班上,在投票中增加噪音并不会改变这个班得到最多选票的事实。 这种微妙的协调为嘈杂的聚合机制所做的预测提供了正确性和隐私 - 只要教师之间的共识足够高。 下图描述了聚合机制是教师之间达成共识的一个设置:将随机噪声添加到投票计数并不会改变候选人的标签。
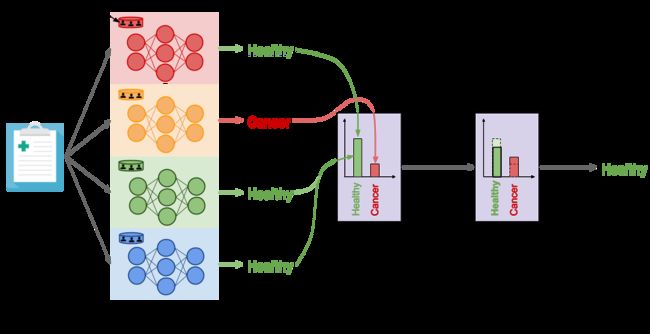
为了清楚起见,我们用二元医学诊断任务说明了聚合,但机制延伸到大量类别 。 现在,让我们分析这个机制的结果,如果简史密斯患有癌症。 红色模型 - 对包含Jane Smith数据的分区进行培训的唯一教师 - 现在已经了解到,与Jane's相似的记录是患有癌症的患者的特征,并因此改变了其对测试输入的预测(类似于简的)到“癌症”。 现在有两位老师为“巨蟹座”投票,而另外两位老师投票赞成“健康”。 在这些情况下,加在两个投票计数上的随机噪音可以防止聚合的结果反映任何教师的投票以保护隐私:嘈杂聚合的结果同样可能是“健康”或“癌症”。
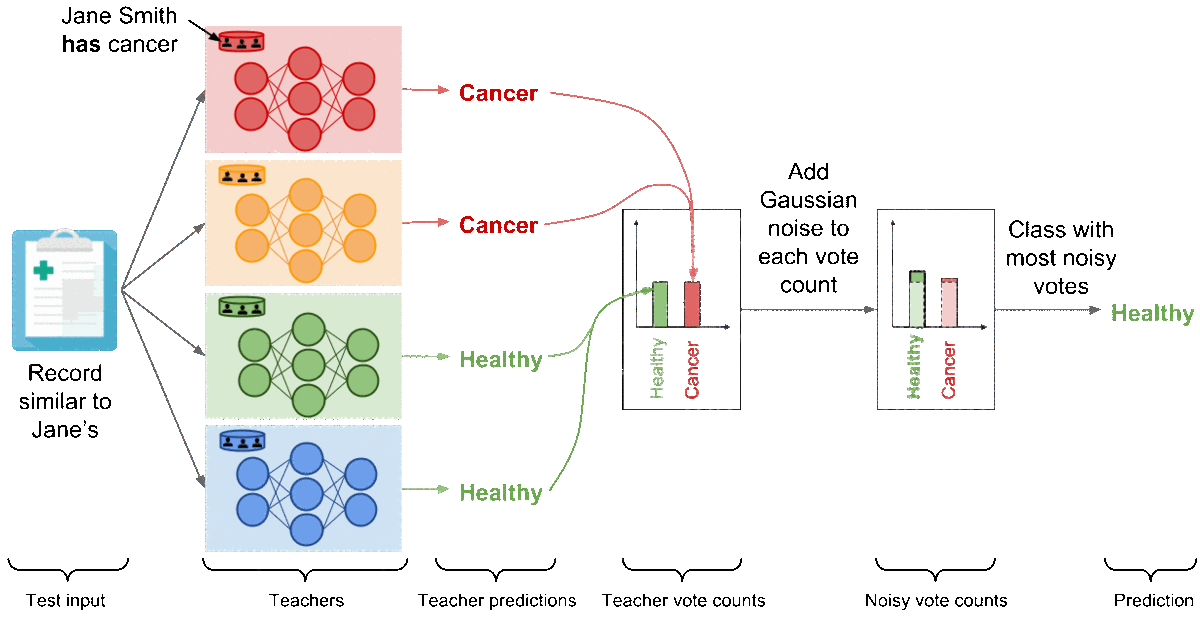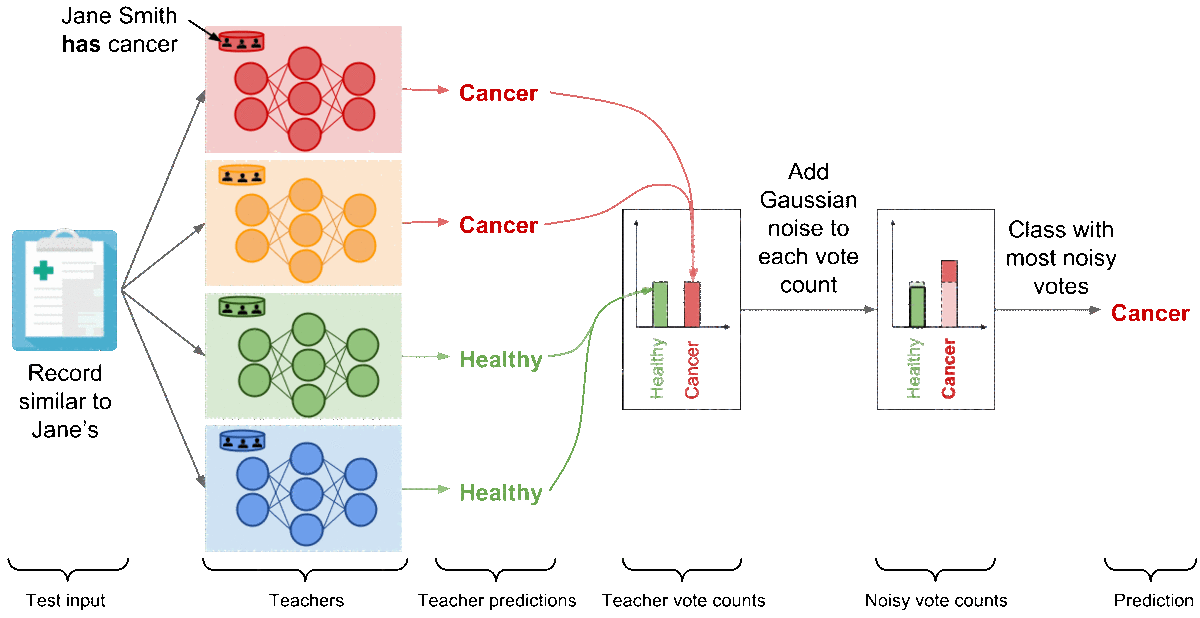
在这一点上,PATE提供了可以被认为是不同的私有API:通过噪声聚合机制预测的每个标签都带有严格的差分隐私保证,从而限制隐私预算用于标记该输入。 在我们的示例中,我们可以限制标签预测受到我们培训教师的任何个人记录影响的概率,包括Jane Smith的例子。 我们应用称为Moments Accountant [ACG16]和Renyi Differential Privacy [M17]的两种技术中的一种来计算该边界。 使用每个查询的投票直方图,我们估计聚合结果的概率因注入噪声而改变。 然后我们将这些信息汇总到所有查询中。 在实践中,隐私预算主要取决于教师之间的共识以及增加了多少噪音。 教师之间的较高一致意见,如分配给一个班级的最多票数所表达的,往往赞成较小的隐私预算。 在某些情况下,在计算教师分配的投票数之前增加大量的噪音也会产生较小的隐私预算。 回想一下,较小的隐私预算对应于更强的隐私保证。
但是,框架在这一点上面临两个限制。 首先,由汇总机制进行的每个预测都会增加总隐私预算。 这意味着,当许多标签被预测时,总的隐私预算最终变得太大 - 在这一点上,所提供的隐私保证变得毫无意义。 因此,API必须对所有用户施加最大数量的查询,并获得一组新数据以在达到该上限时学习新的教师集合。 其次,我们不能公开发布教师模型的集合。 否则,对手可以检查已发布教师的内部参数,以了解他们接受培训的私人数据。 出于这两个原因,PATE中有一个额外的步骤:创建一个学生模型。
学生通过以保护隐私的方式转移教师集体获得的知识来进行培训。 当然,嘈杂的聚合机制对此是至关重要的工具。 学生从一组未标记的公共数据中选择输入,并将这些输入提交给教师集体以标记它们。 嘈杂的聚合机制会回应私人标签,学生会用这些标签来训练模型。 在我们的工作中,我们尝试了两种变体:PATE只在标记的输入上(以受监督的方式)训练学生,而PATE-G训练学生有标记和未标记的输入(以半监督方式使用生成敌对网络或虚拟敌对训练)。

学生模型是PATE的最终产品。 它被部署来响应来自最终用户的任何预测查询。 在这一点上,私人数据和教师模型可以安全地被丢弃:学生是用于推断的唯一模型。 观察上述确定的缺陷现在如何解决。 首先,一旦学生完成培训,整个隐私预算现在就被固定为一个固定值。 其次,能够访问学生内部参数的对手可以在最坏的情况下恢复学生所接受的私人标签。 这种保证源于噪音聚集机制。
隐私和学习与PATE令人愉快的协同作用
您可能已经注意到,隐私保证和由汇总机制预测的标签的正确性源于教师之间的强烈共识。 事实上,当大多数教师对预测达成一致时,增加噪音不太可能会改变得到最多教师投票的班级。 这为聚合机制提供了非常强大的隐私保证。 同样地,许多同意标签的教师表示对该预测的正确性充满信心,因为这些教师模型是独立于不同的数据分区进行训练的。 这直观地说明了为什么PATE能够利用隐私和学习之间的一些愉快的协同作用。
这可能令人惊讶。 事实上,将差别隐私作为一种很好的财产呈现是很常见的,但它会带来性能上的必要折衷。 但是,机器学习的情况有所不同。 差分隐私实际上与机器学习的目标完全一致。 例如,记住一个特定的训练点,如Jane Smith的病历,在学习过程中是对隐私的侵犯。 这也是一种过度拟合的形式,并且损害了医疗记录类似Jane's的患者的模型的泛化性能。 此外,差别隐私意味着某种形式的稳定性(但相反情况并非一定如此)。
这个观察推动了我们在最近的论文中对PATE的一个精炼的聚合机制的设计,跟随了原始的工作。 这种新机制 - 自信聚合者 - 是有选择性的 :教师只回答学生提出的一些问题。 当老师提问时,我们首先检查教师之间的共识是否足够高。 如果分配给教师中最受欢迎的标签的投票数大于阈值,我们接受学生的查询。 如果不是,我们拒绝它。 阈值本身是随机的,以便在选择过程中提供隐私。 一旦选择了一个查询,我们就会继续使用原始的噪声聚合机制:我们为每个标签对应的每个投票计数添加噪音,并返回票数最多的标签。 这个过程如下所示(在一个任务中有6个类,以避免在二进制情况下误导人物的简化)。
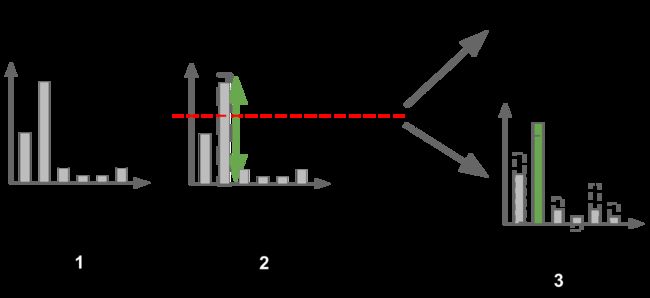
实际上,这意味着我们的隐私预算现在花在两件事上:选择和回答查询。 但是,由于我们选择回答的问题具有教师之间高度一致的特点,所以需要回答的预算非常少。 换句话说,我们可以将Confident Aggregator作为一种机制,将原始机制中消耗大部分隐私预算的查询过滤掉。 因此,在相同的学生表现水平下,自信聚合者提供的隐私预算总额要小于最初的嘈杂聚合机制。 下图显示了这种改进是当使用依赖于数据的(数据dep)分析时,原始机制(简单GNMax)和改进机制(Confident GNMax)回答的(学生)查询数量的函数通过应用Moments会计师或Renyi差异隐私。

ML研究人员如何为PATE改进模型?
两个因素主要影响我们的方法提供的隐私保证的强度:
- 教师之间的共识 :当这个共识很强时,意味着几乎所有的教师都做出了相同的标签预测,减少了输出相应标签时所花费的隐私预算。 这直观地对应于所做的预测是所有教师所学习的普遍性的情景,即使他们是在不相交的数据集上进行训练的。
- 学生查询的数量 :每次学生在培训期间对教师进行标签查询时,教师花费在制作该标签上的预算将被添加到总隐私成本中。 因此,用尽可能少的教师查询来培训学生会加强所提供的隐私保证。
这两点都可以从纯粹的ML角度来解决。 加强教师共识要求可以为每位教师提供很少的数据。 改善这些模型的个体准确性和泛化性很可能有助于改进共识。 与完全监督的教师培训不同,减少学生查询的数量是一个半监督学习问题。 例如,MNIST和SVHN的最先进的隐私保护模型是用PATE-G进行培训的,PATE-G是使用生成敌对网络以半监督方式培训学生的框架变体。 学生可以使用相对较大的未标记输入,并且必须尽可能少地接受教师的监督。
为了帮助刺激这些努力,PATE框架是开源的,并作为TensorFlow模型库的一部分提供。 为了简单起见,代码使用公开可用的图像分类数据集,如MNIST和SVHN。 您可以克隆它并在UNIX机器上适当地设置PYTHONPATH变量,如下所示:
cd git clone https://github.com/tensorflow/models cd models export PYTHONPATH=$(pwd):$PYTHONPATH cd research/differential_privacy/multiple_teachers
然后,PATE的第一步是培训教师模型。 在这个演示中,我们使用MNIST数据集和250名教师的集合(请参阅PATE论文来讨论为什么这是一个不错的选择)。
python train_teachers.py --nb_teachers=250 --teacher_id=0 --dataset=mnist python train_teachers.py --nb_teachers=250 --teacher_id=1 --dataset=mnist ... python train_teachers.py --nb_teachers=250 --teacher_id=248 --dataset=mnist python train_teachers.py --nb_teachers=250 --teacher_id=249 --dataset=mnist
这将为250名教师节省检查点。 现在,我们可以加载这些教师并运用汇总机制来监督学生的培训。
python train_student.py --nb_teachers=250 --dataset=mnist --stdnt_share=1000 --lap_scale=20 --save_labels=True
这将使用来自测试集的前1000个输入来训练学生,使用我们的250名老师标记,并采用拉普拉斯等级1/20噪声聚合机制。 这还将保存一个文件/tmp/mnist_250_student_clean_votes_lap_20.npy其中包含教师制作的所有标签,我们用这些标签评估学生的私密程度。
要了解我们学生模型保证的差异隐私边界的价值,我们需要运行分析脚本。 这将使用培训学生时保存的有关教师共识的信息来执行隐私分析。 这里, noise_eps参数应该设置为2/lap_scale 。
python analysis.py --counts_file=/tmp/mnist_250_student_clean_votes_lap_20.npy --max_examples=1000 --delta=1e-5 --noise_eps=0.1 --input_is_counts
该设置使用原始噪声聚合机制再现了PATE框架。 对使用我们最近的论文中介绍的Confident Agggregator机制感兴趣的读者可以在这里找到相关的代码。
更多PATE资源
- ICLR 2017的原始PATE文件和ICLR 口头记录
- ICLR 2018将PATE缩放为大量类别和不平衡数据的论文。
- PATE的 GitHub 代码回购
- GitHub 代码回购,用于对PATE进行完善的隐私分析
结论
在机器学习中,隐私可以被认为是一个盟友而不是敌人。 随着技术的提高,差别隐私很可能成为一种有效的正规化者,可以产生更好的行为模式。 在PATE的框架内,机器学习研究人员还可以在不担任这些担保背后的正式分析专家的情况下,为改善差异性隐私保证做出重大贡献。
致谢
感谢我们的合作者对本文中提供的材料的贡献。 特别感谢Ilya Mironov和ÚlfarErlingsson对本文稿的反馈意见。
参考
[ACG16] Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016, October). Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (pp. 308-318). ACM.
[DMNS06] Dwork, C., McSherry, F., Nissim, K., & Smith, A. (2006, March). Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference (pp. 265-284). Springer, Berlin, Heidelberg.
[M17] Mironov, I. (2017, August). Renyi differential privacy. In Computer Security Foundations Symposium (CSF), 2017 IEEE 30th (pp. 263-275). IEEE.
[NS08] Narayanan, A., & Shmatikov, V. (2008, May). Robust de-anonymization of large sparse datasets. In Security and Privacy, 2008. SP 2008. IEEE Symposium on (pp. 111-125). IEEE.
[SSS17] Shokri, R., Stronati, M., Song, C., & Shmatikov, V. (2017, May). Membership inference attacks against machine learning models. In Security and Privacy (SP), 2017 IEEE Symposium on (pp. 3-18). IEEE.