C++:KMP字符串详解
kmp算法(Knuth-Morris-Pratt算法)是一种字符串匹配算法,可以在O(m+n)的时间复杂度内实现两个字符串的匹配。下面谈谈个人对于kmp算法浅陋的理解。
目录
- 一、原题
- 二、分析
- 三、KMP的具体实现
- 四、nxt的求解
- 五、题解
一、原题
给定一个字符串S,以及一个模式串P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串P在字符串S中多次作为子串出现。
求出模式串P在字符串S中所有出现的位置的起始下标。
输入格式
第一行输入整数 N ,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1≤N≤105
1≤M≤106
输入样例:
3
aba
5
ababa
输出样例:
0 2
二、分析
先看两个概念:
- 文本串(text):即需要搜索的文本范围。
- 模式串(pattren):即被搜索的内容。
本题的要求就是在一个文本串中找所有模式串的位置。先以一个正常人的思维去思考这个问题:直接用肉眼观察,当然这是十分愚蠢的。测试用例给出的虽然可以直接数出来,但假设有106个字,显然自己数是很愚蠢的,那么就要交给计算机来完成这项任务了。我们设置一个二重循环,第一层用来遍历文本串,第二层用来遍历模式串,即先从文本串第一个字开始,往下比,看看是否匹配,然后再从文本串第二个字开始,以此类推……我们假设文本串有m个字符,模式串有n个字符,那最坏的情况不难得出需要操作m×n次。回头看看题干,假设数据都给到最大,那最坏就是操作1011次(TLE警告)。
这样肯定不行呀,但是还要做题,那怎么办呢?当然这也不是我们需要考虑的问题,已经有三位大哥替我们考虑过了,也就是他们提出了KMP算法。我们先看一个丑陋的作图来有个大概的认识(因为本人不会制作动画,所以只能浅浅模拟一下了):
现在给出了文本串和模式串:

假设比较进行到了这里:
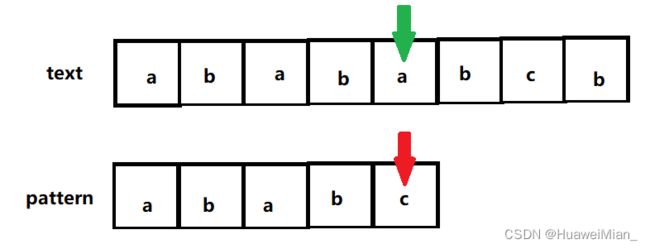
这俩不一样,那么Knuth、Morris和Pratt要怎么样呢?答案是这样:

我们观察一下可以发现:

被圈起来的部分是一样的。其中红色的叫一个前缀,黄色的叫一个后缀。假设用数组来存储模式串,我们可以说每一个元素都有其对应相等的前后缀(可能有点模糊,稍后会详细解释)。然后再从中断的位置开始:

继续比较下去,中断了再进行一样的操作。这就是KMP的大概思想。
我们对比一下愚蠢做法和KMP算法,假如用的是愚蠢的暴力算法,那么中断后上图的绿指针就回到text的第二个b处重新开始了,但是KMP避免了这种回溯,这也是KMP快的理由。下面就详细分析一下这个算法。
三、KMP的具体实现
上面提到了一个模糊的概念:前缀和后缀。这个是kmp里面最重要的概念,一定要搞清楚,下面来详细解释一下。
首先有一个长为n的字符串(下标从1开始),那么他长为 i 的子串为 s[1] ~ s[i],对于这个子串,它长为k的前缀为 s[1] ~ s[k],长为k的后缀为 s[i - k + 1] ~ s[i],举个例子:
字符串 a b c d e f g 长为6的子串是 a b c d e f ,这个子串长为2的前缀是 a b ,它长为2的后缀是 e f , 注意!!!后缀不是回文形式!!!就是正序!!!不是 g f 而是 f g !!!
我们再拿出上面的老图(懒得画新的了):
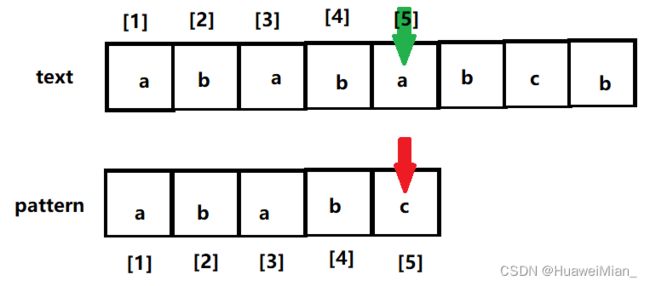
中断在模式串和文本串的5号位,那么进行操作:
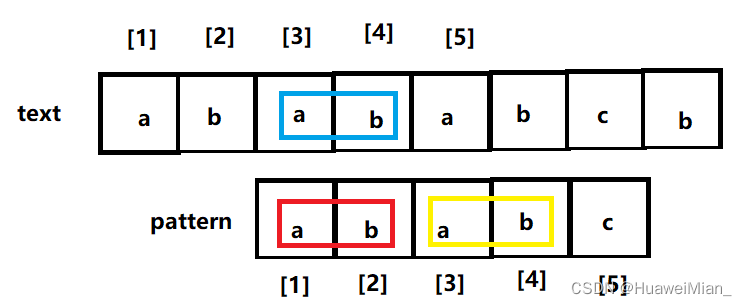
注意!!这一步是精髓,一定要看懂!!
因为中断在模式串的5号位,所以以5 - 1即4为子串,长度为4的这个子串最长相等的前后缀长度为2(一定要明白什么叫最长相等的前后缀)。为什么不是4呢(前缀abab,后缀abab),因为前后缀的长度都要小于子串,为什么呢,一会告诉你。

(为了说清楚,再搞一张图)本来在中断之前,蓝的部分是匹配上的(圈起来的长度就是长度为4的这个子串最长相等的前后缀长度,这句话有点绕,细品),因为我们定义的是相等的前后缀,所以直接把前缀搬过来:
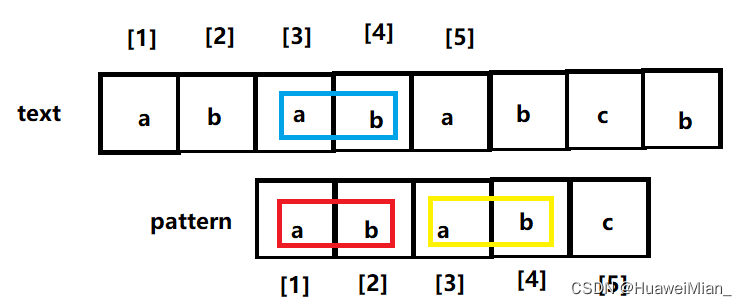
妙处来了:文本串的中断点前还是匹配的!所以现在只需要再从文本串的中断点(因为你要在文本串里找模式串,当然要从文本串断开的地方继续)开始比较就行了,而不是回溯到一开始去比较(这就是KMP的最妙之处)。插入一句:在这个例子中,如果最长相等前后缀是4,那么经过这绝妙的操作之后,你会发现位置没变,所以前后缀长度不能大于本身的长度。如果比较成功,那么就接着比下一位,如果不成功,那么就递归的去执行这个操作,直到什么时候呢,直到比到文本串的末尾或者成功匹配。
这样的一步跳跃可能会有人要说:假如跳过的文本串部分有正确答案怎么办?这是不可能的哈。细想一下,如果有,一定会在正确答案之前中断,那么就又来到了这个过程中,也就不会漏掉你所担心的正确答案了。
现在我们举一个具体的例子,正好展示一下上面说的递归处理是什么意思:
假设我们给出文本串 abababeabababc
然后我们给出模式串 abababc
现在开始展示:
首先开始匹配,匹配到这里中断:
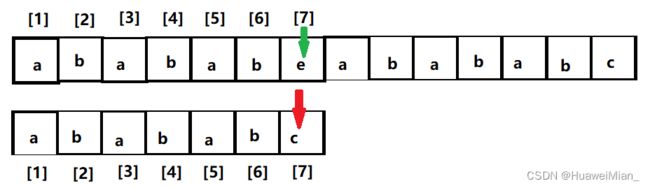
然后我们可以看到,7 - 1 = 6 这个子串最长相等前后缀是abab(不能是ababab,因为长度小于子串长度)所以下一步这样:
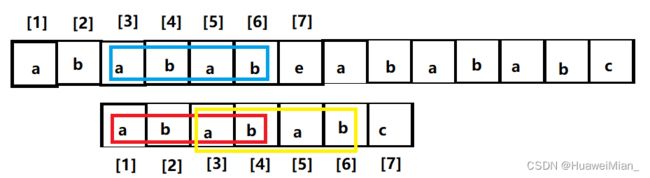
如我们上面说的,搬完了还是匹配的,而且最多只能搬这么多(这就是最长相等的前后缀的长度的意义所在)。下面从文本串的断点开始比:
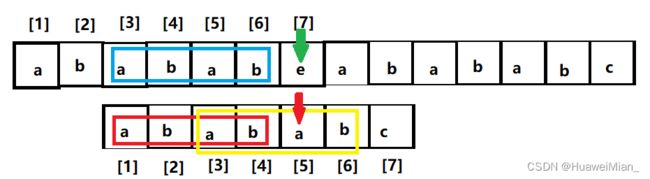
还是不匹配,那怎么办,接着执行一样的操作:中断在模式串的5号位,5 - 1 = 4 子串的最长相等前后缀是ab,那么操作显然就是:

这一步就体现了上面说的递归处理。那么继续,还是不匹配,3 - 1 = 2 子串的最长相等前后缀是,是啥,你会发现没有了,这时候要进行一个特殊操作,相当于是走投无路了,那只能把模式串的一号位和文本串的断点去比了:
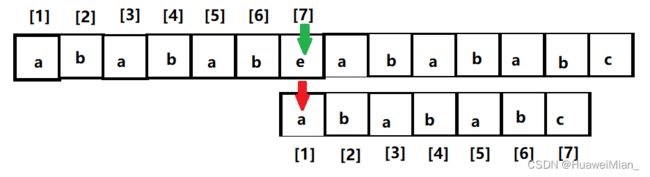
还是不行,这时候就不能在一棵树上吊死了。文本串一直用七号位吊着模式串,现在没希望了,那就和七号位说再见吧,去比八号位了:
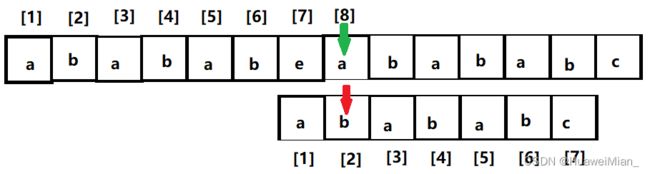
不一样,还是按部就班,断点在模式串的2,那么2 - 1 = 1子串没有相等的前后缀,所以执行特殊操作,拿模式串一号位和文本串断点去比:
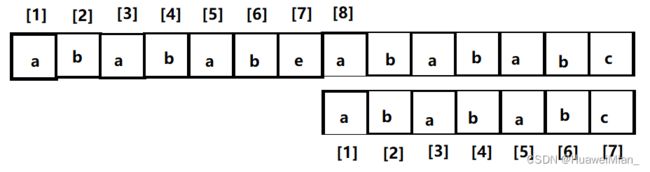
终于对上了,然后继续往下匹配,匹配成功。这样就在文本串里找到了一个匹配的串。下面看看实现匹配的代码(s是text,p是pattern):
for (int i = 1, j = 0; i <= m; i ++ )
{
while (j && s[i] != p[j + 1]) j = nxt[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == n)
//执行匹配成功的操作
}
为了清楚说明,我手抄了一份并且作了相应注释:
注意:这里先声明一点,j (即扫描模式串的“指针”,)和 i (扫描文本串的“指针”)是错开一位的。为什么要这样,因为通过推演上面的过程,我们可以发现,中断后寻找的是模式串中断点 - 1 的最长相等前后缀,为了方便,就错开一位,去比较 i 和 j + 1 。j = 0 的时候,就是没有相等前后缀的情况。
另外还有,我们发现,最长相等前后缀的长度就是挪动模式串后,待匹配前一位的下标(有点绕,细品),所以 j = nxt[j]。
nxt数组记录的是每一位对应最长相等前后缀的长度。

四、nxt的求解
为了记录这最长相等前后缀的长度,我们定义一个数组,就叫next吧,但是next可能和某些关键字冲突,所以记作nxt,ne都行,看个人喜好。nxt数组的具体意思是:以当前字符的下标(从1开始)为子串长度,该子串最长相等前后缀的长度。举个例子,nxt[5] 的意思就是:以5为长度的子串最长相等前后缀的长度。
下面看看怎么求。nxt[1]自然就是0,因为它没有相等的前后缀,那么长度就是0了(注意前后缀长度要小于子串长度)。其他的呢,我们可以暴力来做,那未免有点愚蠢,不妨递推一下:
假设 nxt[i] = j,现在要求 nxt[i+1]。
举个例子:

现在已经知道了 nxt[4] = 2,那么我们比较一下 p[j+1] 和 p[i+1] 即 p[3] 和 p[5],他们相等,这代表什么呢,这代表当前位置最长相等前后缀的长度可以在上一个位置的基础上加一(细品),所以 nxt[5] 就是 nxt[4] + 1,也就推出了第一个公式:
当 p[j+1] 和 p[i+1] 相等的时候,代入 nxt[i] = j ,即
当 p[nxt[i]+1] 和 p[i+1] 相等的时候,nxt[i+1] = nxt[i] + 1。
那么不相等的时候呢?还是举例:

现在知道 nxt[6] = 4,那看 nxt[7],按上面的方法,p[nxt[6]+1] 是 a ,p[6+1] 是 c ,不一样,那就退而求其次吧。怎么个退法呢,在长度为4的基础上不行,那就在长度为次最大的基础上试试,也就是这段:

同时我们发现,其实这两段也是相等的(他们是长度为4的相等前后缀的最后两位):

因此这两段也相等:
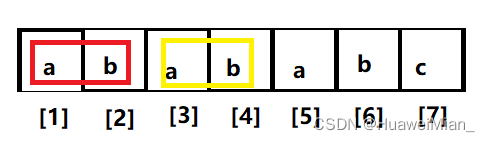
什么意思呢,就是我们想看红框框后一个和 p[7] 是不是相等。但是我们没有定义次最大相等的前后缀,我们发现,上图圈起来的部分是长度为4的子串(想想是怎么来的),然后又惊奇的发现:nxt[4] = 2!这是巧合吗?不这不是,这是三位伟人发现的伟大的规律。别急,我们继续,红框框后面是 a ,不匹配,那找次次最大的相等前后缀,然后发现,没了。那怎么办,那没办法了,那 nxt[7] 就等于 0 吧。所以我们可以看到这样一个过程:
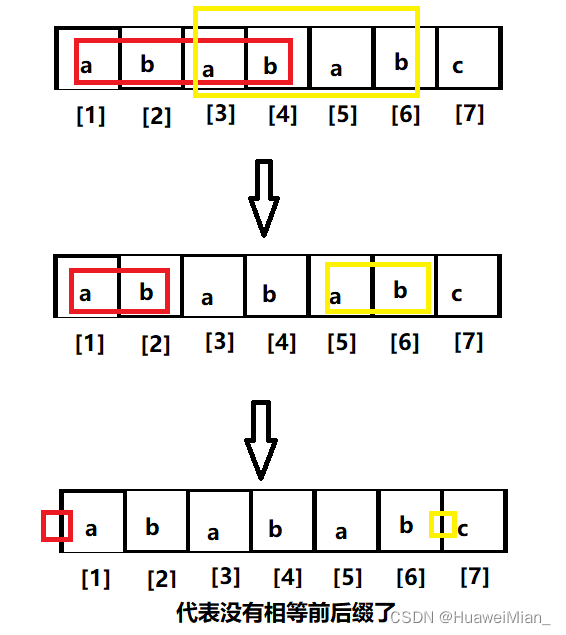
一个神奇的规律:长度为6的子串的最大相等前后缀的长度是4,次最大相等前后缀的长度是 nxt[nxt[6]],也就是 nxt[4] 也就是2,次次次最大相等前后缀的长度是 nxt[nxt[nxt[6]]] 也就是 nxt[2] 也就是0。这是巧合吗?不,这是伟人发现的规律。所以我们得到了不相等时候的公式:
当 p[nxt[i]+1] 和 p[i+1] 不相等的时候,去比较 p[nxt[nxt[i]]+1] 和 p[i+1]。
!!总结一下!!:
当 p[nxt[i]+1] 和 p[i+1] 相等的时候,nxt[i+1] = nxt[i] + 1;
当 p[nxt[i]+1] 和 p[i+1] 不相等的时候,去比较 p[nxt[nxt[i]]+1] 和 p[i+1],直到最后一层nxt的值为0或比较为真。
用代码实现就是:
注意,和上面说到的 i 和 j 错开的原因相似,这里也错开了。i 从2开始是因为 nxt[1] 就是0。
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && p[i] != p[j + 1]) j = nxt[j];
if (p[i] == p[j + 1]) j ++ ;
nxt[i] = j;
}
五、题解
将上面两端代码综合起来,答案为:
#include 由于本人初学算法,时空复杂度分析能力欠佳,欲深入了解者可参考大佬的文章KMP时间复杂度分析
希望对大家有帮助:)