近日,极狐GitLab 邀请新一代的异构大数据即时分析平台厂商——炎凰数据做客 TechTalk 直播间,炎凰数据技术副总裁路铭昊从痛点、解法、案例与共创 4 个模块出发,分享了初创公司在 DevOps 上的探索实践,揭秘 Case 数 10 倍增长、多产品线的情况下,如何实现 Pipeline 执行从 30 分钟到 5 分钟的提速经验。
以下内容整理自本次直播,你也可以点击此处观看视频回放或下载 PPT。Enjoy~
痛点:工具链复杂、功能少、网不好,太 EMO!
在我的工作经历中,无论是大公司还是初创公司,在研发工具链上都面临一些痛点。
大公司业务复杂,不同 BU 或者产品线对工具链的需求或者偏好不同,对应的生产工具种类繁多。例如之前在某家公司,需求管理用 Jira,测试用例用 TestLink,代码管理用 Bitbucket,代码检测用 FishEye,持续集成用 Jenkins、Bamboo 等,复杂工具链导致:
- 学习成本高:仅仅从了解到能够熟练使用这些工具,就要花非常多的时间。根据之前的经验,在大公司里培养一个新人工程师发第一个 MR(PR)需要 4~8 周,可见整体学习周期之长;
- 集成、运维复杂:打通各个系统需要花费更多时间和精力。举个例子,曾经我们在升级 CI/CD 工具版本时,为了让新版本与工具链上的其他工具相互适配,足足花了 3 个月时间才把整体链路打通。在复杂工具链中,一个版本升级带来的额外工作量是巨大的;
- 效率低下:当时我们使用的测试用例工具每次都需要复制一个新的环境实例进行发布和测试。频繁复制新环境的方式,降低了团队的研发和测试效率,还增加了发布部署的风险。
对于初创公司,通常一开始选择免费工具支持研发团队协同工作。随着团队规模扩大和产品复杂度的提升,功能不足以及协同效率低下的问题逐渐显现。
另外,国外软件的网络问题也是普遍痛点。
解法:All in one,一个平台串联需求→开发→发布
以上痛点激发了我们对一站式研发平台的强烈需求。随着极狐GitLab 在国内落地,更贴合本土用户的产品功能和技术服务等优势,推动我们迅速迁移至极狐GitLab。
极狐GitLab 非常好的满足了炎凰数据的需求。经过了两年的应用,我们总结如下几个非常欣赏的亮点,分享给大家。
代码、CI/CD 一站式服务
极狐GitLab 一体化 DevOps 平台提供了从项目管理、源代码管理、CI/CD 等一站式服务,不需要在多个系统之间来回切换;也不用花费额外的时间去熟悉、维护和打通不同系统,可以高效投入到核心的产品开发工作中,这一点是我们非常看重的。
现在,代码提交 → 创建 MR → Code Review → CI/CD → 自动化测试 → 部署上线的链路十分顺畅,这是之前无法实现的。基于极狐GitLab,我们真正做到了快速开发、快速测试、快速部署。
还有一个巨大的加分项:在极狐GitLab 中,整个研发流程可观测、可追溯。例如测试失败了,可通过极狐GitLab 追溯了解是哪一个测试用例组或具体测试用例失败:直接点击触发测试失败的测试作业,下钻到导致失败的具体测试用例,通过查看上下文来了解失败的原因。若发布失败,也能以同样的方式追溯原因。
需求、Story、Bug 一站式管理
- 以 Issue 统一管理
在极狐GitLab 中,不仅做到了代码管理,还实现了 Issue 管理,把 Epic → User Story → Task 这条链路用 Issue 连接起来,实现一站式的需求管理。
- 看板功能强大
极狐GitLab 提供看板功能去追踪每个 Story 的状态,包括初始化( Initialize)→ 设计中(Design)→ 开发中(Develop)→ 代码评审(Code Review)→ 测试(Test)→ 部署(Deploy)→ 完成(Done)整条链路。
同时还可以自定义创建标签对任务进行分类。比如创建“优先级”标签,根据优先级对 Issue 进行排序,在过滤栏里可以把优先级高的 Issue 过滤出来。
另外,极狐GitLab 的 Issue 有一个 Weight(权重)字段,可以对 Story point 进行标记,方便需求的敏捷化管理。
- 关联代码
实时关联代码即 Issue、需求和代码在同一套系统里面,相互关联。比如我创建了一个 MR,该 MR 服务于某一个 Bug 或 Story,就可以把它们关联起来。在 Merge 之后,自动关闭 Bug 或 Story 或推送给相对应的测试人员进行测试。

极狐GitLab 一体化 DevOps 平台提供的一站式服务,对于我们非常适用和受益,接下来通过几个具体案例来看极狐GitLab 如何助力我们的研发工作。
案例:3 个具体使用场景见真章
1. 灵活自定义 Pipeline:从买杯咖啡到听首歌,Pipeline 执行时长缩短 6 倍
炎凰数据成立初期,整体 Case 数量在 100 个左右,跑 Pipeline 的元素也比较简单,即部署环境 → 测试 → 回收环境这样一个标准的 CI/CD 流程。那时所有 Case 都用一个 Job 去运行,百来个 Case 跑完需要 30 分钟,大概出门喝杯咖啡的时间,可以接受。

初期 100 个Case 左右,Pipeline 时间约 30 分钟
随着公司日益壮大,人员增加,产品功能需求增加,整体代码量提升,Case 数量也逐渐增多到几千个,此时一个 Job 就力不从心了,30 分钟变成 300 分钟,这个时间是无法接受的。此时,我们通过极狐GitLab 自定义 Pipeline 来解决。
因为极狐GitLab YAML 文件支持对不同的测试用例组进行配置,所以通过如下设置,我们实现了在 Case 数增加的情况下,总时长大幅缩短:
- 将关联性较弱的 Case,拆分成多个组并行运行;
- 保留部分串行组,运行一些不希望被其他 Case 干扰的 Case。
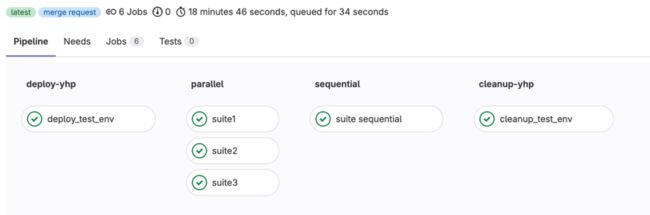
几百至上千个 Case,应用极狐GitLab Pipeline 时间仅 18 分钟
随着业务快速发展,不仅是 Case 数量增加,产品线也变多了,我们既有 ToB 炎凰数据平台,还推出了 ToC 的鸿鹄平台。
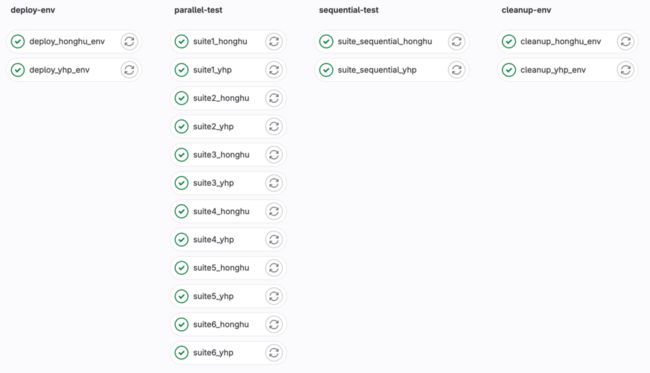
多了一个产品线怎么办呢?极狐GitLab 可以同时支持多个产品线,只需要在 YAML 文件中多定义一个部署环境,如下图所示,我们把每个产品线拆分成 6 个不同测试用例组并行运行,整体时间缩短了 6 倍,以前需要30分钟,现在仅需3~5分钟,大概听首歌的时间。

另外,还可以设置关键字按需运行,如按优先级运行 P0 级别的测试用例,或者全量回归测试。
2. 作业依赖:Upstream 和 Downstream 实现动态标签分配机制与测试结果统一概览
但前文的应用方式无法创建动态 Runner,好在极狐GitLab Upstream、Downstream 功能解决了这个问题。
在极狐GitLab 中,Upstream job 有一个运行测试步骤,在这里计算出哪些用例需要运行,需要多少台机器,随后把这些机器都创建出来,打上动态标签即可。通过 Upstream 和 Downstream 的联系,从 Upstream 把动态标签发给 Downstream ,Downstream 拿到这些动态标签之后,再去实际运行测试的 Runner 上进行绑定。换言之,所有的 Runner 标签都是动态创建出来的。
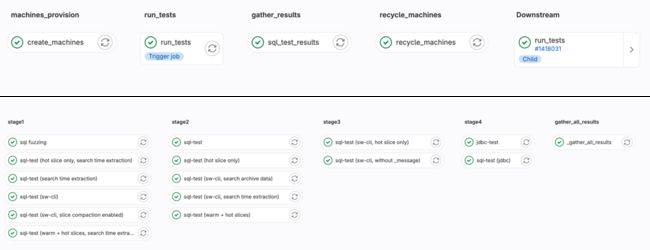
运行完成后,Downstream 的结果如何返回到 Upstream 呢?极狐GitLab 也提供了简便的方法——自定义作业依赖,可以在 YAML 文件中添加一段自定义代码,把 Downstream 运行完成的 Case 测试结果全部收集汇总,发回到 Upstream。这样就不需要到每一个 Downstream job 中去查看结果,而可以在 Upstream job 中查看所有测试结果汇总,这给研发人员带来了极大的便利。

另外,极狐GitLab 还可以根据合并请求中的代码改动,动态选择需要运行的测试用例组(如并行、顺序运行或全局运行),节省资源成本。

3. 灵活可变的脚本配置:让 CI/CD 执行更贴合实际需求
- 根据 Code diff 来计算需要跑的 Case
无论是测试人员还是研发人员,通常只希望运行修改过的 Case,而不是每次都运行全量回归。极狐GitLab 灵活可变的脚本配置,支持根据 MR 中的代码差异来计算需要运行的 Case,进而节省时间和资源。
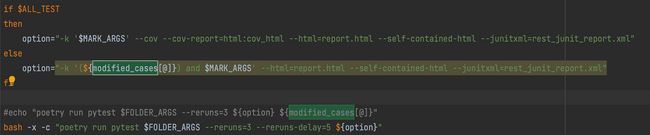
- run_full_test:创建 MR 时可通过自带关键字告知 CI 如何跑 case
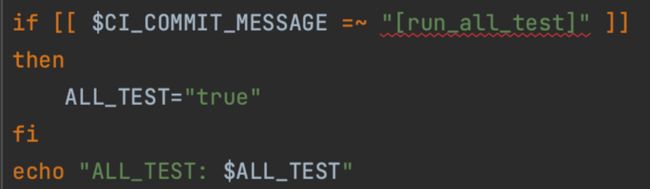
如需要运行全量测试用例,可以在 MR 的 Commit message 里带一个自定义的关键字,只要脚本里面能够去识别就可以,非常灵活。如下图我们用“ run all test”:
- 灵活定义已部署环境的生命周期及回收机制
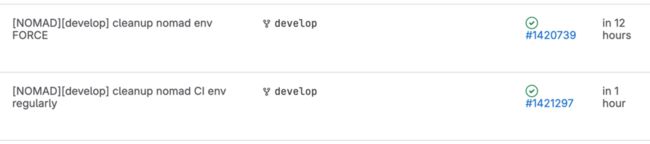
炎凰数据每天运行 CI job,通常能够自动回收。但存在一些极端情况,比如 Job 卡死、Debug 忘记回收、网络问题或者其他故障导致没有运行到回收的流程,那么这个环境就变成一个“孤儿”存在在系统里了。但我们不希望资源被浪费,因此利用极狐GitLab 时间表功能,创建了两个时间表:
- 每 3 个小时去清理一遍所有已部署环境;
- 每天23:00 清理环境,为 00:00 时运行产品的完整功能版本测试,预备充足的资源。
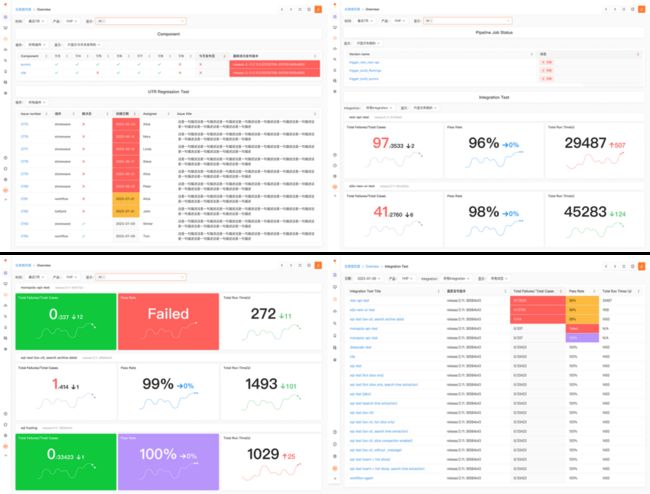
火花:炎凰数据+极狐GitLab,实现研发数据实时可视化展示和分析
如前文所说,我们每晚零点会进行产品完整功能版本测试。之前,每天的测试结果在次日早上以 Email 方式发送,存在不直观、有延迟、无法定向筛选和灵活数据对比等缺点。
炎凰数据本身是异构大数据即时分析平台,极狐GitLab 拥有强大的 API ,我们将炎凰数据强大的数据分析能力与极狐GitLab 相结合,实现了研发数据的实时可视化展示和分析,通过挖掘数据价值,增强对研发效能的观察和研究,赋能研发工作。
以上是炎凰数据与极狐GitLab 摩擦出的一些火花,我们将持续探索基于极狐GitLab 的精英研发效能。欢迎了解炎凰数据+极狐GitLab 的更多故事。
炎凰数据
上海炎凰数据科技有限公司是一家拥有自主知识产权,专注于异构大数据分析平台的初创公司,提供从数据导入、存储、查询分析、告警和仪表板等一系列服务的新一代异构大数据即时分析平台,帮助客户更快的从海量数据中定位问题以及提供解决方案,从而更好的完成在这个新的信息化时代下的数字化转型。