【CV with Pytorch】第 3 章 : 构建目标检测模型
目标检测是当今最抢手的技能之一。一个图像可以有多个类。此外,对对象进行分类只能解决部分问题。另一部分在于对象的定位。对象检测有助于识别带有边界框的图像的类别位置。可以针对各种子任务进一步处理边界框。例如,想一想交通摄像头需要什么来检测和识别汽车。
交通摄像头需要检测汽车和车牌,然后从车牌上读取号码以识别车主。这不是一个简单的问题。我们需要带注释的注册数据。一个简单的分类卷积神经网络模型是行不通的。我们需要获取车牌的边界框并搜索字母数字字符,使用一系列数据清理、去噪和超分辨率步骤。
最近在目标检测领域取得了很大的进步。在众多的目标检测方法中,我们可以将旅程分为 pre-2012 时代或 pre AlexNet 时代和 post-2012 时代。2012 年之前的时代包括多种目标检测算法,例如 HOG、Haar 级联、SIFT 的一些变体、SURF 等。2012 年之后的时代包括 RCNN、Fast RCNN、Faster RCNN、YOLO、Single Shot Detector 等。
我们将简要介绍 2012 年之前的 Haar Cascades,以建立基于机器学习的对象检测技术的背景。从 Haar Cascades 开始,我们需要使用图像中的特征而不是更细粒度的像素。Haar Cascades 于 2001 年推出,尽管它已经老化,但它仍然是最快的之一。
使用提升级联进行目标检测
提升级联最初是为检测人脸而构建的,但它也可以用于其他物体检测任务。它包含三个部分——积分图像、用于选择特征的增强算法和级联分类器。
首先,需要将输入图像转换为我们所说的积分图像。可以使用简单的计算来计算积分图像。
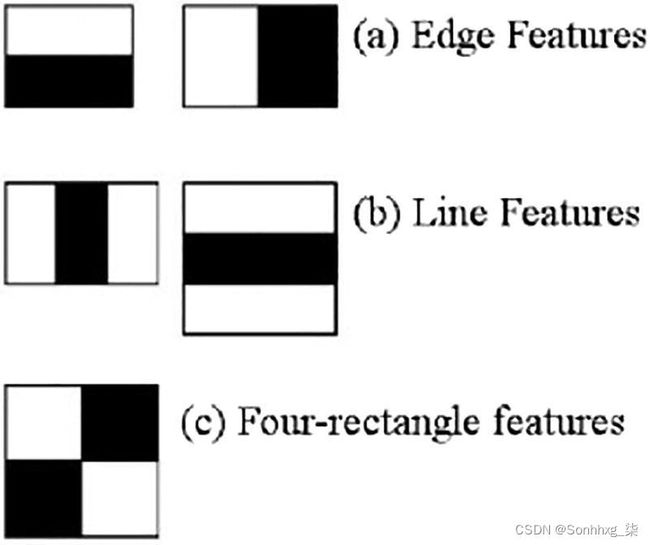
图 3-1 特征提取器的例子
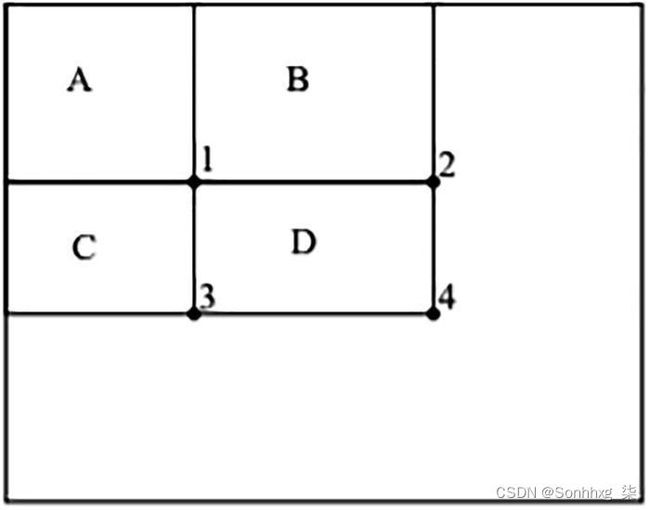
图 3-2 中间步骤
图3-1中的图像显示了三种主要类型的特征提取器。第一个是边缘提取器,然后是线和矩形特征提取器。使用这些提取器,需要选择特征,增强算法有助于选择必要的特征。自适应增强算法提供了一组重要特征,有助于更快地进行面部识别。
积分图像是进行特征提取的中间步骤;它是通过对计算像素值的点上方和左侧的像素求和来完成的,如图3-2所示。
积分图像的计算过程如下:
位置 1 = A 矩形中的像素总和(考虑左侧和上方)
位置 2 = 像素总和 A + B
位置 3 = 像素总和 A(上)+ C(左)
位置 4 = 像素总和 (4 +1) – 总和 (2+3)
提取的特征针对正样本和负样本绘制,最终选择最佳特征。正负图像集的训练分类器由较弱的分类器形成。对于人脸检测,从高达 16 万个特征中,一系列弱分类器的增强算法有助于识别 6,000 个有用的特征。最终,级联分类器有助于检测类别。
他们称之为注意力级联,有助于减少计算时间并提高检测器的效率。图像被分成多个子窗口,顺序弱分类器作用于它们。每个分类器使用选定的特征,尝试检查对象的存在。如果在任何时候分类器失败,所有后续分类器都会停止,序列将移至下一个子窗口,依此类推。如果所有分类器都可以对所需对象的存在进行投票并获得边界框,则检测成功。
让我们通过一系列 Python 代码来使用现有模型来检测面部和眼睛。
导入包如下:
import cv2
import gc以下函数将从相机获取输入帧并针对模型进行缩放。由于彩色图像不会产生任何影响,因此考虑使用灰度图像。首先,检测人脸,然后对于每张脸,在另一个眼睛检测器的帮助下定位眼睛。
这是处理面部和眼睛级联的功能:
def detect_face_eye(frame):
## 归一化并将颜色转换为灰度
frame_to_gray = cv2.equalizeHist(cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY))
## 应用程序应该能够处理不同比例的图像
detected_faces = face_cascade.detectMultiScale(frame_to_gray)
for (x,y,w,h) in detected_faces:
center_face = (x + w//2, y + h//2)
## draw an ellipse
frame = cv2.ellipse(frame, center_face, (w//2, h//2), 0, 0, 360, (125, 125, 125), 6)
face_regionofinterest = frame_to_gray[y:y+h,x:x+w]
#detect eyes - 对于每张检测到的脸
## 类似的多尺度操作
detected_eyes = eyes_cascade.detectMultiScale(face_regionofinterest)
for (x2,y2,w2,h2) in detected_eyes:
center_eye = (x + x2 + w2//2, y + y2 + h2//2)
radius = int(round((w2 + h2)*0.25))
## 画一个圆圈
frame = cv2.circle(frame, center_eye, radius, (255, 255, 255 ), 4)
cv2.imshow('--Face Detection--', frame)
这些模型可以在open-cv版主提供的 GitHub 存储库中找到,网址为https://github.com/opencv/opencv/tree/master/data/haarcascades。此代码使用两种模型,一种用于检测人脸,另一种用于检测眼睛。但是,存储库中还有其他模型可供您试验。该功能还将访问连接到系统的相机外围设备,并使用它们扫描面部。
运行函数以启用面部和眼睛感应过程:
## 保存的xml路径
face_cascade_name = r' ..\chapter 3\frontal_face_alt.xml'
eyes_cascade_name = r' ..\chapter 3\eye_cascade_model.xml'
## 初始化级联检测
face_cascade = cv2.CascadeClassifier()
eyes_cascade = cv2.CascadeClassifier()
## 加载级联面部,然后加载眼睛
face_cascade.load(cv2.samples.findFile(face_cascade_name))
eyes_cascade.load(cv2.samples.findFile(eyes_cascade_name))
camera_device = 0
## 启用视频处理
capture_cam_img = cv2.VideoCapture(camera_device)
## 启用分类器对人脸进行操作
if capture_cam_img.isOpened :
while True:
ret, frame = capture_cam_img.read()
detect_face_eye(frame)
## 按下ESC时关闭cv视频感应
if cv2.waitKey(10) == 27:
cv2.destroyAllWindows()
gc.collect()
break现在我们对结构化对象检测有了一些了解,我们可以转向另一种高级对象检测技术,称为R-CNN。
R-CNN
长期以来,物体都是通过图像分割来分离的。最终,图像的分层性质对开发人员造成了瓶颈。考虑一下我们是否试图在车流中定位一个人。可以使用穷举搜索机制来扫描每辆汽车以准确找到该人所在的位置,但计算要求太高而无用。
在所有这些问题中,题为“Selective Search for Object Recognition”的论文试图解决生成对象位置的问题。它利用了两全其美的技术——分段和详尽搜索。以下步骤显示了选择性搜索机制的工作原理。
该算法的工作原理如下:
该算法使用有效的基于图形的分割来生成初始区域。
第二阶段尝试对相似区域进行分组以在输入图像中生成片段。对于创建的所有区域,计算所有相邻元素的相似性分数。将两个最相似的区域组合在一起并重新计算分数。重复这个过程,直到整个图像都被操作覆盖。
选拔过程曲折。它使用多种策略将相似的区域放在一起。如果合并两个区域,则可以通过层次结构传播区域的特征。
选择标准取决于互补色空间,它沉迷于各种空间中的分层分组算法,包括寻找互补色空间。总的来说,四种快速高效的策略有助于算法。
该算法的主要目标是根据其策略找到不同但互补的特征以对区域进行分组。
物体检测领域的前驱体有HOG(定向梯度直方图)和SIFT。当承认视觉任务的复杂性时,开发了一种不同的方法。
区域提案网络
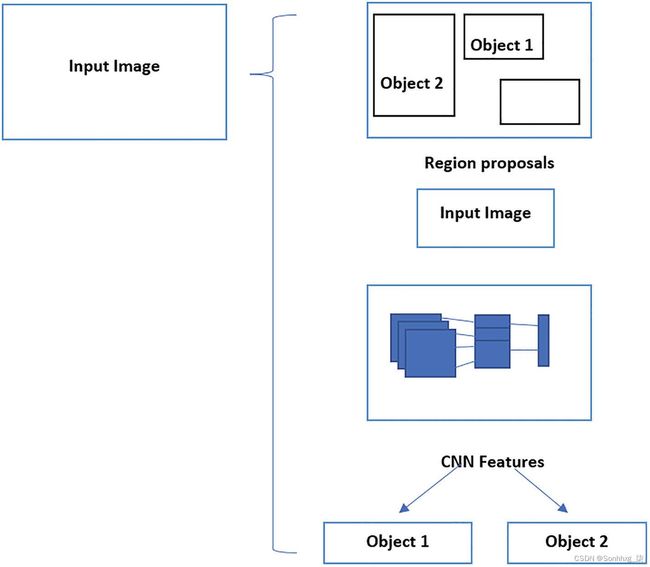
图 3-3 通过区域建议进行目标检测
图3-3描述了区域提议网络中目标检测的各个步骤。让我们来看看重要的步骤:
生成分割和多个候选区域。
使用贪心学习算法递归地将相似区域组合成更大的区域。
将带有建议的图像发送到用于对对象进行分类的卷积神经网络架构。
在标准 R-CNN 中使用的 AlexNET 的情况下,使用 227 x 227 作为图像的形状。
大约 2000 个区域被发送到 AlexNET,并传递了 4096 个向量。
提取的特征根据在特定类别中训练的 SVM 进行评估。
在对所有区域进行评分后,对分类区域运行非最大抑制。它消除了具有 IOU 的区域,为大于阈值和更高区域覆盖率的区域铺平了道路。
有趣的是,当该算法定位 2000 个感兴趣区域时,它会从建议的区域生成扭曲的图像内容。由于卷积块需要固定尺寸,因此信息在空间中扭曲并传递。
然后通过支持向量机对这些区域中的每一个进行分类。此外,该算法将执行回归,该回归将纠正或预测对首先预测的边界框的任何偏移。在进行下一步之前,让我们回顾一下这里多次使用的两个重要概念。
非极大值抑制。在对象检测算法中,经常会出现这样一种情况,其中多个边界框重叠在一个对象周围。通常要求分类器在不同大小的感兴趣区域周围生成概率分数。为了解决选择一个最佳边界框的问题,该算法使用分类信息和对象的覆盖百分比。
并集交集 (IoU)。用于选择与ground truth最相似的边界框。当我们处理图像分类时,我们尝试将图像映射到它们各自的类。同样,对于对象检测,需要手动干预绘制边界框以定位单独的对象和类。该等式给出了交集与并集的比率。
IoU 的公式由下式给出:

图3-4a显示了具有两个重叠边界框的图像,一个是基本事实,另一个是预测的事实。图3-4b显示了两者聚合的区域。这两个方面相互平衡,以最大程度地覆盖地面实况。
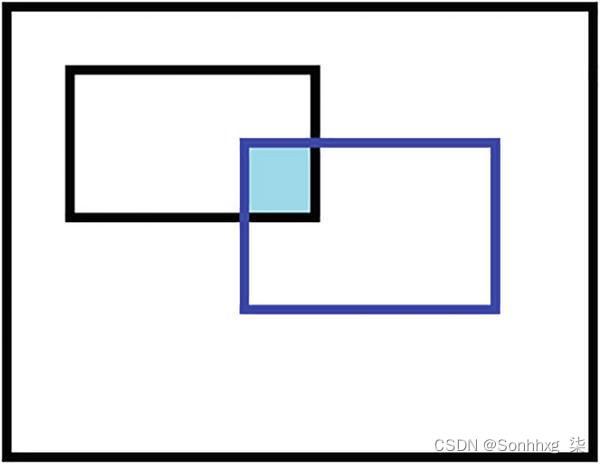
图 3-4a 边界框交互

图 3-4b 边界框联合
总的来说,这个算法可以处理很多与物体检测相关的问题,并且在它发布时是最具革命性的算法之一。但它并非没有缺陷。现在让我们深入研究它的一些明显缺陷:
借助复杂的图像处理技术,该模型将生成 2000 个感兴趣区域。所有这些都需要通过支持向量机运行来进行分类。这个过程涉及大量的计算。
大多数算法在预测时都会花费大量时间对图像进行分类和处理。如果我们处理实时解决方案,则几乎不可能将此模型用作算法。
训练发生在卷积部分;分类器和回归正在校正边界框参数。
在算法的初始部分,使用选择性搜索机制来分割相似区域并共同生成感兴趣区域。整个过程基于复杂图像处理技术的搭配。过程中不涉及任何学习,因此改进的余地很小。
在R-CNN在目标检测中解决的所有问题中,它留下了一系列需要解决的问题。基于区域的目标检测网络出现了进步,称为快速基于区域的卷积网络。
快速基于区域的卷积神经网络
要设置上下文,如果存在对象检测应该工作的图像,根据基于简单区域的卷积神经网络,它将在简单图像之上生成感兴趣区域。组合将是巨大的。但是如果我们可以根据 (x,y) 将图像缩小到更小的尺寸,我们仍然可以获得图像中具有正确对象信息的部分。最终,这归结为我们如何将信息传递给后续层和成本函数。Fast R-CNN 导致更快的操作。
图3-5描述了基于一个感兴趣区域的工作流程。该架构建议对输入数据执行卷积运算,从而减少计算量。
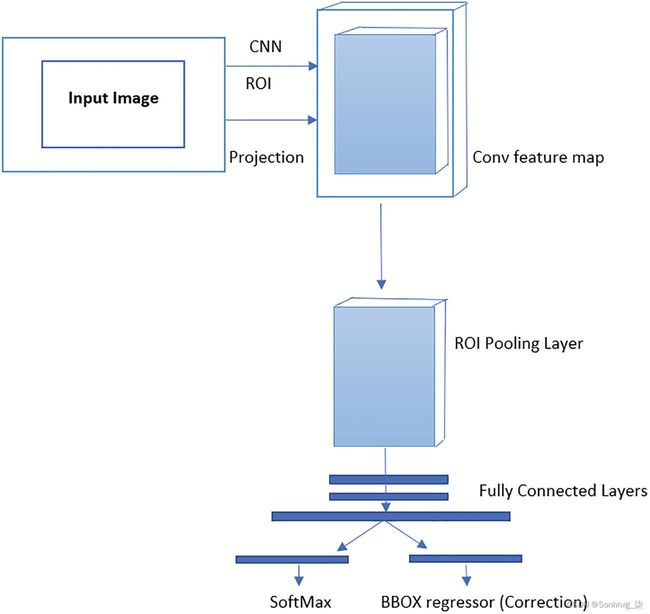
图 3-5 Fast R-CNN 架构
基于区域的快速目标检测涉及的过程如下:
特征图是由多个卷积和池化操作创建的。
由于全连接网络需要一个固定维度的向量,感兴趣区域的池化层提取一个固定长度的向量。
这些特征向量中的每一个都被输入到完全连接的网络中,该网络再次连接到输出层。
第一个连接层包括一个 softmax 概率估计计算,具有超过n 个对象类别和一个用于背景或未知类别的附加类别。
第二层输出为每个对象类别预测四个实数。每个集合都为所讨论的类定义了更正的边界框值。
我们介绍的这些架构中的每一个都使用选择性搜索算法来查找感兴趣的区域。这有两个问题。首先,复杂的计算机视觉过程不会学习数据的任何变化,因为它有一套固定的指令集,与如何识别区域相关。其次,选择性搜索是一个缓慢且耗时的过程。这些问题在该算法的升级版本中得到处理,称为更快的 R-CNN。
区域提案网络如何工作
一个扩展的想法出现了,这个想法也被提出并实施了,它使用神经网络来预测区域建议而没有选择性搜索机制。区域提议网络帮助识别图像中的边界框,然后将相同的块发送到卷积神经网络以获取特征图。
最终,损失函数在特征图上进行训练,并调整网络权重以适应训练。让我们一步一步地完成这个过程:
在第一步中,将输入图像传递到卷积块以生成卷积特征图。
region proposal 网络在每个位置的特征图上使用滑动窗口。
对于每个位置,使用九个具有三种不同比例和三种纵横比(1:1、1:2、2:1)的锚框,这有助于生成区域建议。
分类层告诉输出锚框中是否存在对象。
回归层指示锚框的坐标。
锚框被传递到 Fast R-CNN 架构的感兴趣区域的池化层。
我们使用神经网络来了解区域建议在哪里以及如何根据数据调整它们。这也使该过程比我们之前了解的过程快得多。图3-6显示了 Faster R-CNN 的主要研究论文中的架构。
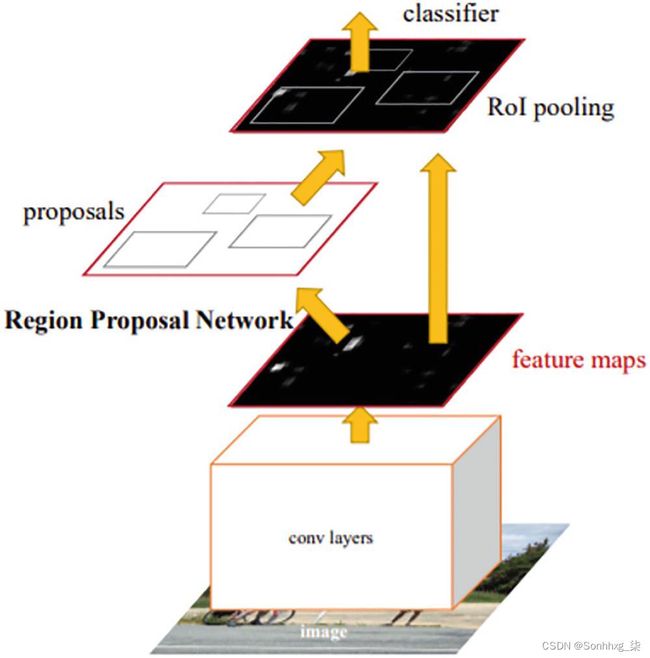
图 3-6 Faster R-CNN总结
该网络有一个区域建议网络的新想法,可以学习边界框并可以概括它们。它具有三种主要类型的网络:
Head:可以是ResNet架构,起到生成feature maps的作用。
Region Proposal Network:为分类器和回归器生成感兴趣区域。
分类网络/回归网络:处理对象的分类和对象性或边界框坐标的正确性。
图3-7描绘了 Faster R-CNN 的基本层。让我们进入细节,这将增强图层的开发。
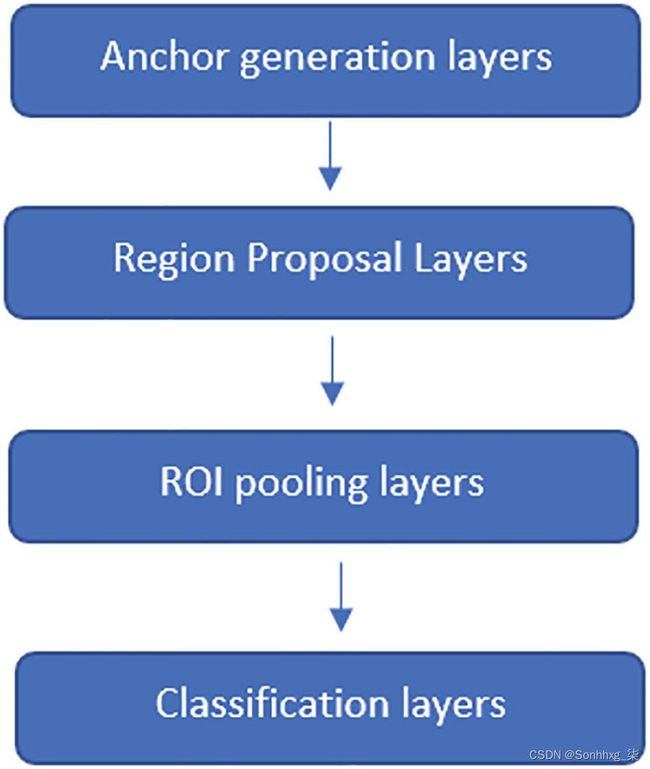
图 3-7 Faster R-CNN流程图
锚生成层
该层生成一系列具有不同大小和纵横比的边界框,以覆盖大部分图像区域。边界框或锚框将包含图像及其对象。然而,这些框将与内容无关并且始终相同,最终区域提议网络将对它们进行处理并确定其中哪个是更好的边界框。小的调整将导致更好的边界框。
由于预测这些坐标有其问题,另一种方法是将参考框作为边界框的标准。取一个参考框作为 (X center , Y center , width, and height) 然后尝试预测和修正偏移值以使其更好地适应。偏移值适用于所有四个参数。
区域提议层
区域建议网络致力于改变锚框的位置、宽度和高度以更好地适应对象。该层可以被认为是区域建议网络、建议层、锚点目标层和建议目标层的组合。
区域提议网络:该层使用特征图并将它们提供给卷积神经网络。然后将输出传递到两个 1x1 卷积层,以生成与边界框、类分数和概率相对应的回归系数。
Proposal layer:该层采用大量锚框,并通过基于前景分数的非最大抑制帮助将它们减少到适当的数量。它还使用区域建议网络生成的系数更改边界框的坐标。
锚目标层:这有助于选择锚框,帮助 RPN 区分前景和背景。
RPN 的损失函数是分类损失和回归损失的组合。
总的来说,Faster R-CNN 有一个基于卷积神经网络的图像特征提取器和区域建议网络来生成感兴趣的区域。我们有 ROI 池来为下一层获取图像的固定尺寸,最后到分类和回归层。这有助于锚框更好地适应并且足以区分前景和背景。
Mask R-CNN
在 Faster R-CNN 已经取得的成就之上,这是在检测到的对象上预测掩码方面的扩展。在ROI pooling层之后还有两个卷积神经网络来添加masks。这也建立了 ROI Align,这有助于更好地将提取的特征与输入对齐,并避免过去在 Faster R-CNN 中发生的扭曲。它使用双线性插值来获得输入区域的精确或接近完美的值。
所有这些对象检测方法的一个重要步骤是锚框的使用。YOLO 通过一些额外的变化扩展了这个想法,我们将研究这些变化。
先决条件
注释。在分类问题中,图像需要按照它们所属的类别进行排序或排列。同样,在目标检测问题中,图像需要用适当的边界框标记,通常称为地面实况。边界框将用于建议对象的坐标和被包围的类。图3-8显示了一个图像实例,这些图像已被注释以训练鸟类所在位置的分类器。通常,注释是手动完成的,有时是多次注释,以获得无偏见的基本事实。但是,如果我们像现在这样练习,我们可以使用任何开源数据进行实验。

图 3-8 带注释的鸟
显卡首选。在处理需要训练和运行推理的计算机视觉任务时,建议使用支持 CUDA 的 GPU 内核以加快处理速度。
安装了 CUDA 功能的 Torch 框架。如上一章所述,我们还需要在系统上安装 PyTorch。
YOLO
对有助于实时推理的对象检测算法有着巨大的需求。Faster R-CNN 非常接近,处理 2000 个边界框预测和传统的计算机视觉方法。它比其前身有了重大改进,但仍有改进的余地。
出现了革命性的算法YOLO,它以每秒 45 帧的速度检测物体 (TITAN X)。早期的模型花费了太多时间在不同层次上进行训练和预测,例如anchor生成层、region proposal层、分类和边界框校正。另一方面,YOLO 试图让一个卷积神经网络块来预测边界框和类别,从而减少计算时间。它有一种更通用的方法来训练和考虑来自整个图像的信息,而不是将它们拼凑在一起。最后,它取代了试图做同样事情的其他前辈。
图3-9显示了 YOLO 中的架构,其灵感来自用于图像分类的 GoogleNet 架构。输入层显示尺寸为 448x448x3。该网络有 24 个卷积层和最大池化层,分批有两个全连接层。
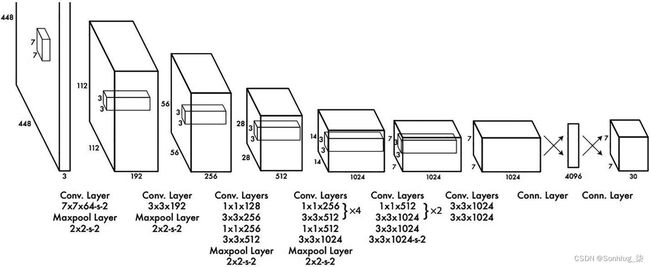
图 3-9 YOLO架构
培训过程相当昂贵,因此从头开始培训对象检测模型需要在良好的治理下进行。这个给定架构的训练以两种方式完成。首先,该模型是在 ImageNet 数据上训练的,前 20 个卷积层是一个平均池,以匹配全连接网络的维度。这个块经过一周的训练以获得 88% 的准确率。
这个预训练网络添加了四个卷积层和两个全连接层以获得最终检测到的对象。输入尺寸也从 224x224 增加到 448x448,这有助于提高检测能力。最后一层预测分类分数和边界框坐标。边界框的宽度和高度被归一化。
图3-10显示了用于优化分类和回归的损失函数。对于五个锚框中的每一个,都有一个目标分数、对应于归一化边界框的四个坐标,以及顶级概率或分数。这些更改效果很好,但需要进一步完善。让我们看看第二次版本更新和版本 3,这是最受欢迎的模型之一。
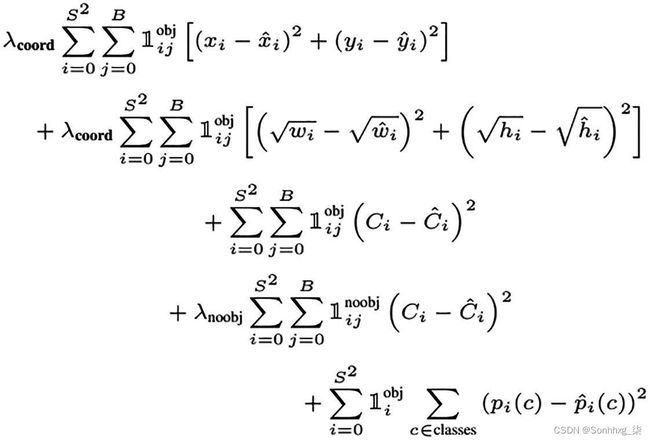
图 3-10 YOLO损失函数
YOLO V2/V3
YOLO 的变化非常显着,第二个版本将方法微调到更高效的水平。以下是第二个版本中解决的几个关键点:
卷积层很深,所以总是有可能出现梯度消失或梯度爆炸。添加了批归一化以帮助学习中的内部协变量转变。
它预测每个锚框的类别和对象。
该网络还预测了五个边界框和每个边界框的五个坐标。
当它删除完全连接的层并用锚框替换它们以预测边界框时,发生了一个重大的架构变化。
这些anchor boxes是在ground truth边界框的聚类帮助下确定的。
即使经过多次更改,研究人员发现再进行一些更改也可以提高准确性。他们进行了必要的更改并将此版本命名为 YOLO V3。它可以说是最受欢迎的对象检测架构之一。YOLO 使用 softmax 层来获得最终的分类分数,而 YOLO V3 在输入上使用了个体逻辑回归或多标签分类。有趣的是,它还删除了池化层,而是使用步幅为 2 的 3x3 来降低维度。
该体系结构还对损失函数进行了更改,得出了三个主要预测——边界框的坐标、对象性值和类别分数。YOLO V3 架构中最流行的主干是 Darnet-53,它是一个 53 层的卷积块架构,如图3-11所示。它使用具有 3x3 和 1x1 卷积层的残差实现来获取用于检测和分类的特征。总的来说,这些变化对架构的准确性和优化产生了巨大影响。
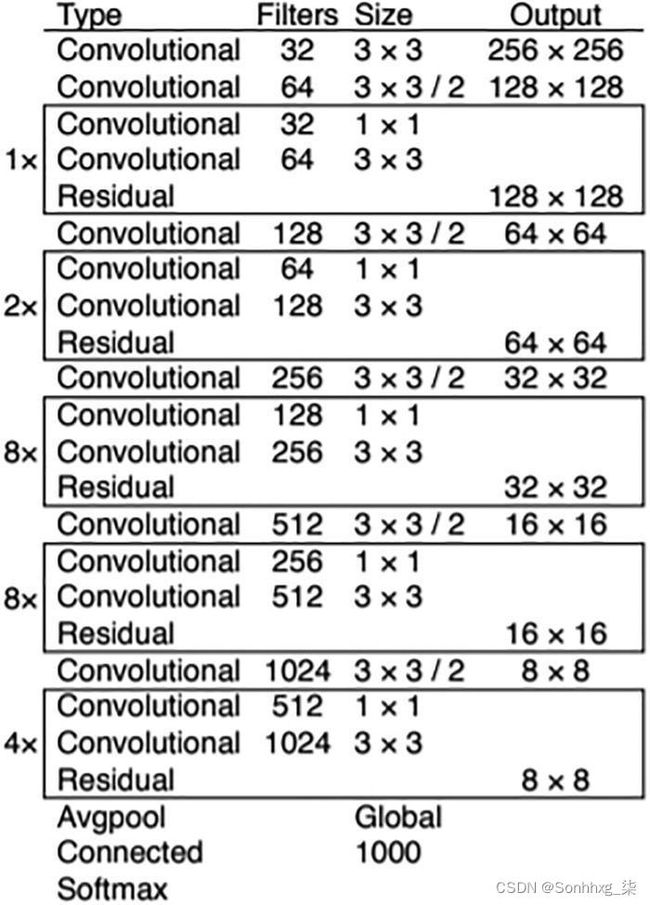
图 3-11 Darknet 53 架构
让我们看一些使用已保存模型并针对自定义数据集对其进行调整的代码。为什么我们不从头开始训练它?这些都是重量级模型,我们并不总是有足够的 GPU 容量来从头开始训练。其次,使用训练好的权重并相应地修改它们是一种学习经验。我们将不断重复的一个术语是迁移学习.
项目代码片段
代码片段改编自 YOLO 的原始创建者,所有源代码归功于 Joseph Redmon 和 Ali Farhadi。尽管从头开始训练相当复杂,但我们可以尝试使用现有的开源模型对这些数据进行迁移学习。如果训练原始模型的类与我们正在使用的类非常相似,我们还可以使用现有模型对我们的数据进行推理。
文件夹设置需要遵循原始创建者的设置,因为我们将使用保存的模型来自定义训练我们的数据。如图3-12所示,对于任何变化,应根据配置文件更正路径 - 在data下。
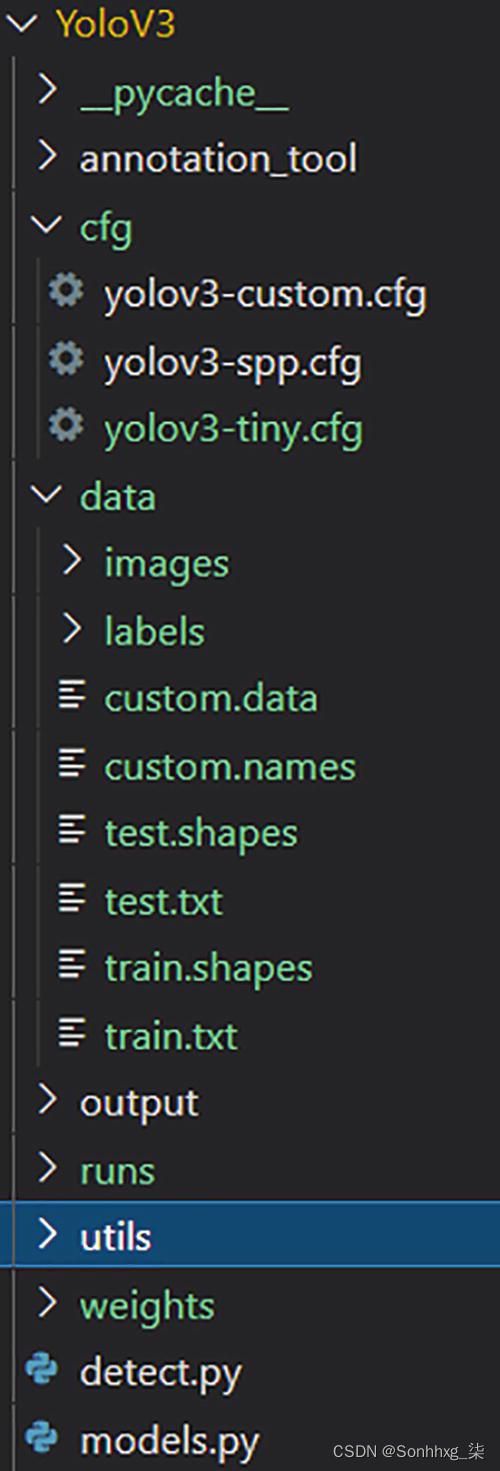
图 3-12 YOLO的文件夹结构
第 1 步:获取注释数据
当我们想要训练自定义数据时,图像注释是对象检测算法最重要的先决条件之一。它们通过分类和回归损失函数帮助模型。他们有基本事实,这是手动解决的。我们可以从多个开源位置对图像进行注释。该工具通常会有一个标记,有助于在图像顶部绘制某种形状的边界框。该程序将允许以 JSON、CSV 或 VOC/COCO 格式下载注释,具体取决于所使用的模型。训练数据和自定义数据应该保持一致。
注释对注释者而言正确且真实是非常重要的。由于这是一项手动且重复的任务,因此需要尽可能好。最后,应该下载生成的文件并将其放在数据文件夹中。例如,每张图片可能如下所示:
0 0.41833333333333333 0.2112676056338028 0.2011111111111111 0.2007042253521127
2 0.43777777777777777 0.3970070422535211 0.1155555555555555 0.15669014084507044
1 0.38722222222222225 0.6813380281690141 0.47 0.4119718309859155
一旦我们聚合了新文件,我们就可以看到如何更改数据文件。在图3-12中,数据下的文件夹主要是标签和图片。这些图像具有与注释图像同名的原始图像。文本文件需要有注释信息并放在标签中。这将是文本文件或 JSON。
完成后,我们将检查文件的自定义数据文件,该文件需要使用诸如训练和测试文件信息存储位置等信息进行更新。我们需要在这里投射两种信息——标签和图像的路径以及实际图像。自定义数据文件将如下所示:
classes=4
train=data/train.txt
valid=data/test.txt
names=data/custom.names
这提供了有关数据及其下落的相关信息。完成后,我们需要在自定义名称文件中提供类名。它看起来像这样:
hardhat
vest
mask
boots
该文件列出了前面链接的编号的类名。如前所述,我们需要带有图像路径的train.txt和test.txt文件。这些文件应具有运行训练功能的相对路径。
还有其他文件,例如训练和测试形状(train.shapes和test.shapes),它们具有所有文件的形状,我们可以根据输入数据进行更改。
完成所有这些后,我们必须从https://pjreddie.com/darknet/yolo/的来源和原始研究人员下载保存的权重。根据项目工作人员的 GPU 强度,有多种选择。权重和配置文件相互关联。所以要注意为权重下载相应的配置文件。通过这些主要步骤,初始设置已完成。现在我们进入下一个过程。
第 2 步:修复配置文件和训练
另一个重要任务是根据要求和资源更改配置文件。图3-13显示了训练和测试配置的第一个变化。它具有更改批量大小、宽度、高度、通道、动量和衰减参数的规定。

图 3-13 训练/测试配置文件的变化
还提供了学习率和老化等重要参数。除了这些变化之外,还有关于类和最后一层的变化。由于我们将针对包含 80 个类的原始训练方法进行自定义训练,因此这种情况可能会有所不同。图3-14显示了一些必需的更改。如果可以在默认的coco数据集中进行训练,则可以使用原始配置文件。
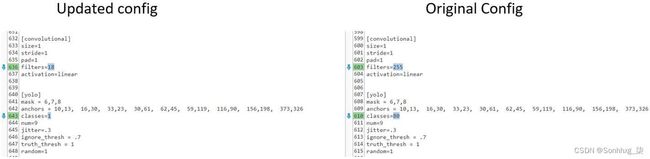
图 3-14 训练/推理管道的配置所需的更改
类和过滤器的所有实例都需要在配置文件中更改。我们需要在YOLO 层之前的实例中将[filters=255]更改为filters=(number of classes + 5)x 3,如第 640 行所示。
进行这些更改后,我们可以转到训练部分。只需要运行一个作业。
!python train.py --data $PATH/custom.data --batch $num_batches --cache --epochs $num_epochs –nosave
$num_batches = Number of batches
$num_epochs = Number of epochs of training (Remember this is transfer learning and we are already using the saved weights)
$path = path to custom data.如果我们的内存不足,我们要么尝试通过采用较小的已保存模型并将它们用于训练来减少模型参数,要么我们减少批量大小或图像分辨率。无论哪种方法看起来简单和适当都可以。
该项目依赖太多,建议直接引用并使用它,以节省时间并使用代码的优化版本。训练代码、模型代码和配置代码是相互关联的。配置文件对训练过程和模型设置有直接影响。让我们从研究人员使用的源代码中查看模型定义的 Python 代码。
模型文件
有带有torchvision和torch函数的标准导入,它们在代码中被多次使用。parse包用于获取命令行参数。模型文件中存在的第一个函数是create_modules函数。让我们完成一些重要步骤,以防创建“从头开始训练”场景。
def create_modules(module_defs, img_size):
# 从 module_defs 中的模块配置构造层块的模块列表
img_size = [img_size] * 2 if isinstance(img_size, int) else img_size # 必要时展开
_ = module_defs.pop(0) # cfg 训练超参数(未使用)
output_filters = [3] # 输入通道
module_list = nn.ModuleList()
routs = [] # 路由到更深层的层列表
yolo_index = -1
for i, mdef in enumerate(module_defs):
modules = nn.Sequential()
if mdef['type'] == 'convolutional':
bn = mdef['batch_normalize']
filters = mdef['filters']
k = mdef['size'] # 内核大小
stride = mdef['stride'] if 'stride' in mdef else (mdef['stride_y'], mdef['stride_x'])
if isinstance(k, int): # single-size conv
modules.add_module('Conv2d', nn.Conv2d(in_channels=output_filters[-1],
out_channels=filters,
kernel_size=k,
stride=stride,
padding=k // 2 if mdef['pad'] else 0,
groups=mdef['groups'] if 'groups' in mdef else 1,
bias=not bn))
else: # multiple-size conv
modules.add_module('MixConv2d', MixConv2d(in_ch=output_filters[-1],
out_ch=filters,
k=k,
stride=stride,
bias=not bn))
if bn:
modules.add_module('BatchNorm2d', nn.BatchNorm2d(filters, momentum=0.03, eps=1E-4))
else:
routs.append(i) # 检测输出(进入 yolo 层)
if mdef['activation'] == 'leaky': # activation study https://github.com/ultralytics/yolov3/issues/441
modules.add_module('activation', nn.LeakyReLU(0.1, inplace=True))
# modules.add_module('activation', nn.PReLU(num_parameters=1, init=0.10))
elif mdef['activation'] == 'swish':
modules.add_module('activation', Swish())
elif mdef['type'] == 'BatchNorm2d':
filters = output_filters[-1]
modules = nn.BatchNorm2d(filters, momentum=0.03, eps=1E-4)
if i == 0 and filters == 3: # 归一化 RGB 图像
# imagenet mean and var https://pytorch.org/docs/stable/torchvision/models.html#classification
modules.running_mean = torch.tensor([0.485, 0.456, 0.406])
modules.running_var = torch.tensor([0.0524, 0.0502, 0.0506])
elif mdef['type'] == 'maxpool':
k = mdef['size'] # 内核大小
stride = mdef['stride']
maxpool = nn.MaxPool2d(kernel_size=k, stride=stride, padding=(k - 1) // 2)
if k == 2 and stride == 1: # yolov3-tiny
modules.add_module('ZeroPad2d', nn.ZeroPad2d((0, 1, 0, 1)))
modules.add_module('MaxPool2d', maxpool)
else:
modules = maxpool
elif mdef['type'] == 'upsample':
if ONNX_EXPORT: # 显式声明大小,避免 scale_factor
g = (yolo_index + 1) * 2 / 32 # gain
modules = nn.Upsample(size=tuple(int(x * g) for x in img_size)) # img_size = (320, 192)
else:
modules = nn.Upsample(scale_factor=mdef['stride'])
elif mdef['type'] == 'route': # nn.Sequential() placeholder for 'route' layer
layers = mdef['layers']
filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])
routs.extend([i + l if l < 0 else l for l in layers])
modules = FeatureConcat(layers=layers)
elif mdef['type'] == 'shortcut': # nn.Sequential() placeholder for 'shortcut' layer
layers = mdef['from']
filters = output_filters[-1]
routs.extend([i + l if l < 0 else l for l in layers])
modules = WeightedFeatureFusion(layers=layers, weight='weights_type' in mdef)
elif mdef['type'] == 'reorg3d': # yolov3-spp-pan-scale
pass
elif mdef['type'] == 'yolo':
yolo_index += 1
stride = [32, 16, 8, 4, 2][yolo_index] # P3-P7 stride
layers = mdef['from'] if 'from' in mdef else []
modules = YOLOLayer(anchors=mdef['anchors'][mdef['mask']], # anchor list
nc=mdef['classes'], # number of classes
img_size=img_size, # (416, 416)
yolo_index=yolo_index, # 0, 1, 2...
layers=layers, # output layers
stride=stride)
# 初始化之前的 Conv2d() 偏差(https://arxiv.org/pdf/1708.02002.pdf 第 3.3 节)
try:
j = layers[yolo_index] if 'from' in mdef else -1
bias_ = module_list[j][0].bias # shape(255,)
bias = bias_[:modules.no * modules.na].view(modules.na, -1) # shape(3,85)
bias[:, 4] += -4.5 # obj
bias[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc)
module_list[j][0].bias = torch.nn.Parameter(bias_, requires_grad=bias_.requires_grad)
except:
print('WARNING: smart bias initialization failure.')
else:
print('Warning: Unrecognized Layer Type: ' + mdef['type'])
# 注册模块列表和输出过滤器的数量
module_list.append(modules)
output_filters.append(filters)
routs_binary = [False] * (i + 1)
for i in routs:
routs_binary[i] = True
return module_list, routs_binary这段代码中的重要步骤是:
初始化顺序模型,它设置模型块的上下文。
该模型从命令行获取参数,并获取与批量归一化、过滤器、激活函数和卷积相关的变量。
可以选择将模型另存为 ONNX版本。
在初始模型定义之后,我们有 YOLO 层类,它使用函数根据收到的配置定义模型。让我们看一下源研究提供的代码。
class YOLOLayer(nn.Module):
def __init__(self, anchors, nc, img_size, yolo_index, layers, stride):
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors)
self.index = yolo_index # 该层在层中的索引
self.layers = layers # 模型输出层索引
self.stride = stride # 层步幅
self.nl = len(layers) # 输出层数 (3)
self.na = len(anchors) # anchors 的数量 (3)
self.nc = nc # 类数 (80)
self.no = nc + 5 # 输出数量 (85)
self.nx, self.ny, self.ng = 0, 0, 0 # 初始化 x, y 网格点的数量
self.anchor_vec = self.anchors / self.stride
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
if ONNX_EXPORT:
self.training = False
self.create_grids((img_size[1] // stride, img_size[0] // stride)) # number x, y grid points
def create_grids(self, ng=(13, 13), device='cpu'):
self.nx, self.ny = ng # x and y grid size
self.ng = torch.tensor(ng)
# build xy offsets
if not self.training:
yv, xv = torch.meshgrid([torch.arange(self.ny, device=device), torch.arange(self.nx, device=device)])
self.grid = torch.stack((xv, yv), 2).view((1, 1, self.ny, self.nx, 2)).float()
if self.anchor_vec.device != device:
self.anchor_vec = self.anchor_vec.to(device)
self.anchor_wh = self.anchor_wh.to(device)
def forward(self, p, out):
ASFF = False # https://arxiv.org/abs/1911.09516
if ASFF:
i, n = self.index, self.nl # index in layers, number of layers
p = out[self.layers[i]]
bs, _, ny, nx = p.shape # bs, 255, 13, 13
if (self.nx, self.ny) != (nx, ny):
self.create_grids((nx, ny), p.device)
# outputs and weights
# w = F.softmax(p[:, -n:], 1) # normalized weights
w = torch.sigmoid(p[:, -n:]) * (2 / n) # sigmoid weights (faster)
# w = w / w.sum(1).unsqueeze(1) # normalize across layer dimension
# weighted ASFF sum
p = out[self.layers[i]][:, :-n] * w[:, i:i + 1]
for j in range(n):
if j != i:
p += w[:, j:j + 1] * \
F.interpolate(out[self.layers[j]][:, :-n], size=[ny, nx], mode='bilinear', align_corners=False)
elif ONNX_EXPORT:
bs = 1 # batch size
else:
bs, _, ny, nx = p.shape # bs, 255, 13, 13
if (self.nx, self.ny) != (nx, ny):
self.create_grids((nx, ny), p.device)
# p.view(bs, 255, 13, 13) -- > (bs, 3, 13, 13, 85) # (bs, anchors, grid, grid, classes + xywh)
p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
if self.training:
return p
elif ONNX_EXPORT:
# 避免为 ANE 操作广播
m = self.na * self.nx * self.ny
ng = 1 / self.ng.repeat((m, 1))
grid = self.grid.repeat((1, self.na, 1, 1, 1)).view(m, 2)
anchor_wh = self.anchor_wh.repeat((1, 1, self.nx, self.ny, 1)).view(m, 2) * ng
p = p.view(m, self.no)
xy = torch.sigmoid(p[:, 0:2]) + grid # x, y
wh = torch.exp(p[:, 2:4]) * anchor_wh # width, height
p_cls = torch.sigmoid(p[:, 4:5]) if self.nc == 1 else \
torch.sigmoid(p[:, 5:self.no]) * torch.sigmoid(p[:, 4:5]) # conf
return p_cls, xy * ng, wh
else: # 推断
io = p.clone() # 推断 output
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method
io[..., :4] *= self.stride
torch.sigmoid_(io[..., 4:])
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85]这段代码定义了 YOLO 层,使用初始化,并为训练完美地设置了一切。代码的重要部分如下:
1.YOLO 层正在配置有用的信息,例如锚点数量、类别、输出数量和类别数量。
2.该代码还设置了图像上的网格,这是锚框所必需的。它还设置前向传播的参数。
3.它还允许设置 ONNX模型。
最后,放置检测模型代码,它使用Darknet框架创建了一个高度优化的对象检测工作流程。
class Darknet(nn.Module):
# YOLOv3 目标检测模型
def __init__(self, cfg, img_size=(416, 416), verbose=False):
super(Darknet, self).__init__()
self.module_defs = parse_model_cfg(cfg)
self.module_list, self.routs = create_modules(self.module_defs, img_size)
self.yolo_layers = get_yolo_layers(self)
# torch_utils.initialize_weights(self)
# Darknet Header https://github.com/AlexeyAB/darknet/issues/2914#issuecomment-496675346
self.version = np.array([0, 2, 5], dtype=np.int32) # (int32) version info: major, minor, revision
self.seen = np.array([0], dtype=np.int64) # (int64) number of images seen during training
self.info(verbose) if not ONNX_EXPORT else None # print model description
def forward(self, x, augment=False, verbose=False):
if not augment:
return self.forward_once(x)
else: # Augment images (inference and test only) https://github.com/ultralytics/yolov3/issues/931
img_size = x.shape[-2:] # height, width
s = [0.83, 0.67] # scales
y = []
for i, xi in enumerate((x,
torch_utils.scale_img(x.flip(3), s[0], same_shape=False), # flip-lr and scale
torch_utils.scale_img(x, s[1], same_shape=False), # scale
)):
# cv2.imwrite('img%g.jpg' % i, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1])
y.append(self.forward_once(xi)[0])
y[1][..., :4] /= s[0] # scale
y[1][..., 0] = img_size[1] - y[1][..., 0] # flip lr
y[2][..., :4] /= s[1] # scale
# for i, yi in enumerate(y): # coco small, medium, large = < 32**2 < 96**2 <
# area = yi[..., 2:4].prod(2)[:, :, None]
# if i == 1:
# yi *= (area < 96. ** 2).float()
# elif i == 2:
# yi *= (area > 32. ** 2).float()
# y[i] = yi
y = torch.cat(y, 1)
return y, None
def forward_once(self, x, augment=False, verbose=False):
img_size = x.shape[-2:] # height, width
yolo_out, out = [], []
if verbose:
print('0', x.shape)
str = ''
# Augment images (inference and test only)
if augment: # https://github.com/ultralytics/yolov3/issues/931
nb = x.shape[0] # batch size
s = [0.83, 0.67] # scales
x = torch.cat((x,
torch_utils.scale_img(x.flip(3), s[0]), # flip-lr and scale
torch_utils.scale_img(x, s[1]), # scale
), 0)
for i, module in enumerate(self.module_list):
name = module.__class__.__name__
if name in ['WeightedFeatureFusion', 'FeatureConcat']: # sum, concat
if verbose:
l = [i - 1] + module.layers # layers
sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # shapes
str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)])
x = module(x, out) # WeightedFeatureFusion(), FeatureConcat()
elif name == 'YOLOLayer':
yolo_out.append(module(x, out))
else: # run module directly, i.e. mtype = 'convolutional', 'upsample', 'maxpool', 'batchnorm2d' etc.
x = module(x)
out.append(x if self.routs[i] else [])
if verbose:
print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str)
str = ''
if self.training: # train
return yolo_out
elif ONNX_EXPORT: # export
x = [torch.cat(x, 0) for x in zip(*yolo_out)]
return x[0], torch.cat(x[1:3], 1) # scores, boxes: 3780x80, 3780x4
else: # inference or test
x, p = zip(*yolo_out) # inference output, training output
x = torch.cat(x, 1) # cat yolo outputs
if augment: # de-augment results
x = torch.split(x, nb, dim=0)
x[1][..., :4] /= s[0] # scale
x[1][..., 0] = img_size[1] - x[1][..., 0] # flip lr
x[2][..., :4] /= s[1] # scale
x = torch.cat(x, 1)
return x, p
def fuse(self):
# Fuse Conv2d + BatchNorm2d layers throughout model
print('Fusing layers...')
fused_list = nn.ModuleList()
for a in list(self.children())[0]:
if isinstance(a, nn.Sequential):
for i, b in enumerate(a):
if isinstance(b, nn.modules.batchnorm.BatchNorm2d):
# fuse this bn layer with the previous conv2d layer
conv = a[i - 1]
fused = torch_utils.fuse_conv_and_bn(conv, b)
a = nn.Sequential(fused, *list(a.children())[i + 1:])
break
fused_list.append(a)
self.module_list = fused_list
self.info() if not ONNX_EXPORT else None # yolov3-spp reduced from 225 to 152 layers
def info(self, verbose=False):
torch_utils.model_info(self, verbose)这些步骤使用Darknet 框架,可从https://pjreddie.com/darknet/获得。它速度快,并且针对计算机视觉问题进行了高度优化。除此之外,模型文件还具有配置详细信息,用于寻找现有的权重以供使用和其他详细信息。训练文件包含大部分可配置的细节,包括处理数据路径、配置文件路径和其他架构细节的设置。它还设置和冻结已经完成训练的权重,并且它只训练那些需要训练和更新的层。至此,我们结束了 YOLO 的训练过程。
概括
目标检测是一个困难的过程,需要同时解决多个任务。它需要针对实时使用进行优化。在本章中,我们探索了允许模型学习对象的分类和定位的机制。
这一切都归结为这样一个事实,即如果允许的话,机器可以发挥强大的能力来学习约束。对象检测算法可用于日常工作,包括自动驾驶汽车、交通摄像头、安全无人机以及更多用例。
在下一章中,我们将了解图像分割,这与我们之前讨论的过程类似。图像分割和对象检测通常用于类似的上下文中。