SQL Server 索引优化——sp_helpindex 改写脚本
SQL Server 索引优化——sp_helpindex 改写脚本
在索引优化中,我们常常用到sp_helpindex 帮我们查看一个表的索引情况,如下所示

但这些信息很明显不足够我们整体深入的剖析一个表的所有索引,因为索引中有包含列,还有索引筛选,索引页的存储等,为了方便索引分析, 改写Kimberly Tripp创建的过程,具体操作如下:
第一步:创建sp_ExposeColsInIndexLevels过程,该过程给出了树和叶的定义,这个过程适合SQL Server 2005/2008/2012/2016/2017 所有版本
/*============================================================================
文件名: sp_ExposeColsInIndexLevels
摘要: 该存储过程列出了非聚集索引键中包含的列,及索引叶包含的列。这依赖于非聚集索引是否唯一,表是否有聚集索引,同时也随着聚集索引是否唯一而改变
日期: 2019.1
版本: SQL Server 2005/2008/2012/2016/2017
------------------------------------------------------------------------------
由 Jack zhou 重写
参考:https://www.sqlskills.com/blogs/kimberly/use-this-new-sql-server-2012-rewrite-for-sp_helpindex/
重写过程中去掉了大量的循环,同时消除索引键列不按顺序输出的问题
============================================================================*/
USE master;
GO
IF OBJECTPROPERTY(OBJECT_ID('sp_ExposeColsInIndexLevels'), 'IsProcedure') = 1
DROP PROCEDURE sp_ExposeColsInIndexLevels;
GO
CREATE PROCEDURE sp_ExposeColsInIndexLevels
(
@object_id INT,
@index_id INT,
@ColsInTree NVARCHAR(2126) OUTPUT,--非唯一索引树中的列=非聚集索引的键列+不包含在非聚集索引中的聚集索引的键列;唯一索引树=非聚集索引的键列+聚集索引的键列
@ColsInLeaf NVARCHAR(MAX) OUTPUT --非唯一索引叶中的列=非聚集索引的键列+聚集索引的键列+包含列;唯一索引叶=非聚集索引的键列+包含列+不在非聚集索引和包含列种的聚集索引的键列
)
AS
BEGIN
DECLARE @nonclus_uniq INT
, @column_id INT
, @column_name NVARCHAR(260)
, @col_descending BIT
, @colstr NVARCHAR (MAX);
--declare @max_clKey_Ordinal int
-- ,@max_nonclKey_Ordinal int
-- 获取聚集索引键的 (id and name)
SELECT sic.key_ordinal,sic.column_id
, QUOTENAME(sc.name, '[') AS column_name
, is_descending_key
INTO #clus_keys
FROM sys.index_columns AS sic
JOIN sys.columns AS sc
ON sic.column_id = sc.column_id AND sc.OBJECT_ID = sic.OBJECT_ID
WHERE sic.[object_id] = @object_id
AND [index_id] = 1;
-- 获取非聚集索引键
SELECT sic.key_ordinal,sic.column_id, sic.is_included_column
, QUOTENAME(sc.name, '[') AS column_name
, is_descending_key
INTO #nonclus_keys
FROM sys.index_columns AS sic
JOIN sys.columns AS sc
ON sic.column_id = sc.column_id
AND sc.OBJECT_ID = sic.OBJECT_ID
WHERE sic.[object_id] = @object_id
AND sic.[index_id] = @index_id;
-- Is the nonclustered unique?
SELECT @nonclus_uniq = is_unique
FROM sys.indexes
WHERE [object_id] = @object_id
AND [index_id] = @index_id;
IF (@nonclus_uniq = 0)
BEGIN
-- Case 1: nonunique nonclustered index
SELECT @colstr=STUFF((
SELECT column_name+CASE WHEN is_descending_key=1 THEN '(-)' ELSE N'' END +N','
FROM #nonclus_keys
WHERE is_included_column=0
ORDER BY key_ordinal
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,'');
-- 如果有聚集索引,则包含聚集键
SELECT @colstr=ISNULL(@colstr,N'')+
ISNULL(STUFF((
SELECT column_name+CASE WHEN is_descending_key=1 THEN '(-)' ELSE N'' END +N','
FROM #clus_keys
WHERE column_id NOT IN (SELECT column_id FROM #nonclus_keys
WHERE is_included_column = 0)
ORDER BY key_ordinal
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,''),'');
SELECT @ColsInTree = SUBSTRING(@colstr, 1, LEN(@colstr) -1);
-- find columns not in the nc and not in cl - that are still left to be included.
SELECT @colstr=ISNULL(@colstr,N'')+
ISNULL(STUFF((
SELECT column_name FROM #nonclus_keys
WHERE column_id NOT IN (SELECT column_id FROM #clus_keys UNION SELECT column_id FROM #nonclus_keys WHERE is_included_column = 0)
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,''),'');
SELECT @ColsInLeaf = @colstr;
END;
-- Case 2: unique nonclustered
ELSE
BEGIN
-- cursor over nonclus_keys that are not includes
SELECT @colstr = '';
SELECT @colstr=STUFF((
SELECT column_name+CASE WHEN is_descending_key=1 THEN '(-)' ELSE N'' END +N','
FROM #nonclus_keys
WHERE is_included_column=0
ORDER BY key_ordinal
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,'');
SELECT @ColsInTree = SUBSTRING(@colstr, 1, LEN(@colstr) -1);
-- start with the @ColsInTree and add remaining columns not present...
SELECT @colstr=ISNULL(@colstr,N'')+
ISNULL(STUFF((
SELECT column_name+CASE WHEN is_descending_key=1 THEN '(-)' ELSE N'' END +N','
FROM #nonclus_keys
WHERE is_included_column = 1
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,''),'');
-- get remaining clustered column as long as they're not already in the nonclustered
SELECT @colstr=ISNULL(@colstr,N'')+
ISNULL(STUFF((
SELECT column_name+CASE WHEN is_descending_key=1 THEN '(-)' ELSE N'' END +N','
FROM #clus_keys
WHERE column_id NOT IN (SELECT column_id FROM #nonclus_keys)
FOR XML PATH(''),TYPE).value('.','varchar(max)'),1,0,''),'');
SELECT @ColsInLeaf = SUBSTRING(@colstr, 1, LEN(@colstr) -1);
SELECT @colstr = '';
END;
-- Cleanup
DROP TABLE #clus_keys;
DROP TABLE #nonclus_keys;
END;
GO
EXECUTE sys.sp_MS_marksystemobject 'sp_ExposeColsInIndexLevels';
GO第二步,创建sp_helpindex_SQL2016.sql
Kimberly Tripp给出了2005~2012的创建脚本,这里对其进行简单调整给出2016的脚本。为方便使用,将其命名改为sp_helpindex_SQL2016
/*============================================================================
文件: sp_helpindex_SQL2016.sql
摘要: 这是对sp_helpindex的修改,修改后的sp_helpindex_SQL2016展示列包含列,过滤列信息,同时给出列索引树和叶所包含的列。
展示索引是否被废弃
2012 Version: Added columnstore indexes to the output
日期: 2019.1
版本:SQL Server 2016
------------------------------------------------------------------------------
由Jack zhou 改写
参考:https://www.sqlskills.com/blogs/kimberly/use-this-new-sql-server-2012-rewrite-for-sp_helpindex/ 的 sp_SQLskills_SQL2012_helpindex.sql
============================================================================*/
USE [master];
GO
IF OBJECTPROPERTY(OBJECT_ID(N'sp_helpindex_SQL2016')
, N'IsProcedure') = 1
DROP PROCEDURE sp_helpindex_SQL2016;
GO
SET ANSI_NULLS ON;
SET QUOTED_IDENTIFIER ON;
GO
CREATE PROCEDURE [dbo].[sp_helpindex_SQL2016]
@objname nvarchar(776) -- the table to check for indexes
as
set nocount on
declare @objid int, -- the object id of the table
@indid smallint, -- the index id of an index
@type tinyint, -- the index type
@groupid int, -- the filegroup id of an index
@indname sysname,
@groupname sysname,
@status int,
@keys nvarchar(2126), --Length (16*max_identifierLength)+(15*2)+(16*3)
@inc_columns nvarchar(max),
@inc_Count smallint,
@loop_inc_Count smallint,
@dbname sysname,
@ignore_dup_key bit,
@is_unique bit,
@is_hypothetical bit,
@is_primary_key bit,
@is_unique_key bit,
@is_disabled bit,
@auto_created bit,
@no_recompute bit,
@filter_definition nvarchar(max),
@ColsInTree nvarchar(2126),
@ColsInLeaf nvarchar(max)
-- Check to see that the object names are local to the current database.
select @dbname = parsename(@objname,3)
if @dbname is null
select @dbname = db_name()
else if @dbname <> db_name()
begin
raiserror(15250,-1,-1)
return (1)
end
-- Check to see the the table exists and initialize @objid.
select @objid = object_id(@objname)
if @objid is NULL
begin
raiserror(15009,-1,-1,@objname,@dbname)
return (1)
end
-- OPEN CURSOR OVER INDEXES (skip stats: bug shiloh_51196)
declare ms_crs_ind cursor local static for
select i.index_id, i.[type], i.data_space_id, QUOTENAME(i.name, N']') AS name,
i.ignore_dup_key, i.is_unique, i.is_hypothetical, i.is_primary_key, i.is_unique_constraint,
s.auto_created, s.no_recompute, i.filter_definition, i.is_disabled
from sys.indexes as i
join sys.stats as s
on i.object_id = s.object_id
and i.index_id = s.stats_id
where i.object_id = @objid
open ms_crs_ind
fetch ms_crs_ind into @indid, @type, @groupid, @indname, @ignore_dup_key, @is_unique, @is_hypothetical,
@is_primary_key, @is_unique_key, @auto_created, @no_recompute, @filter_definition, @is_disabled
-- IF NO INDEX, QUIT
if @@fetch_status < 0
begin
deallocate ms_crs_ind
raiserror(15472,-1,-1,@objname) -- Object does not have any indexes.
return (0)
end
-- create temp tables
CREATE TABLE #spindtab
(
index_name sysname collate database_default NOT NULL,
index_id int,
[type] tinyint,
ignore_dup_key bit,
is_unique bit,
is_hypothetical bit,
is_primary_key bit,
is_unique_key bit,
is_disabled bit,
auto_created bit,
no_recompute bit,
groupname sysname collate database_default NULL,
index_keys nvarchar(2126) collate database_default NULL, -- see @keys above for length descr
filter_definition nvarchar(max),
inc_Count smallint,
inc_columns nvarchar(max),
cols_in_tree nvarchar(2126),
cols_in_leaf nvarchar(max)
)
CREATE TABLE #IncludedColumns
( RowNumber smallint,
[Name] nvarchar(128)
)
-- Now check out each index, figure out its type and keys and
-- save the info in a temporary table that we'll print out at the end.
while @@fetch_status >= 0
begin
-- First we'll figure out what the keys are.
declare @i int, @thiskey nvarchar(131) -- 128+3
select @keys = QUOTENAME(index_col(@objname, @indid, 1), N']'), @i = 2
if (indexkey_property(@objid, @indid, 1, 'isdescending') = 1)
select @keys = @keys + '(-)'
select @thiskey = QUOTENAME(index_col(@objname, @indid, @i), N']')
if ((@thiskey is not null) and (indexkey_property(@objid, @indid, @i, 'isdescending') = 1))
select @thiskey = @thiskey + '(-)'
while (@thiskey is not null )
begin
select @keys = @keys + ', ' + @thiskey, @i = @i + 1
select @thiskey = QUOTENAME(index_col(@objname, @indid, @i), N']')
if ((@thiskey is not null) and (indexkey_property(@objid, @indid, @i, 'isdescending') = 1))
select @thiskey = @thiskey + '(-)'
end
-- Second, we'll figure out what the included columns are.
select @inc_columns = NULL
SELECT @inc_Count = count(*)
FROM sys.tables AS tbl
INNER JOIN sys.indexes AS si
ON (si.index_id > 0
and si.is_hypothetical = 0)
AND (si.object_id=tbl.object_id)
INNER JOIN sys.index_columns AS ic
ON (ic.column_id > 0
and (ic.key_ordinal > 0 or ic.partition_ordinal = 0 or ic.is_included_column != 0))
AND (ic.index_id=CAST(si.index_id AS int) AND ic.object_id=si.object_id)
INNER JOIN sys.columns AS clmns
ON clmns.object_id = ic.object_id
and clmns.column_id = ic.column_id
WHERE ic.is_included_column = 1 and
(si.index_id = @indid) and
(tbl.object_id= @objid)
IF @inc_Count > 0
BEGIN
DELETE FROM #IncludedColumns
INSERT #IncludedColumns
SELECT ROW_NUMBER() OVER (ORDER BY clmns.column_id)
, clmns.name
FROM
sys.tables AS tbl
INNER JOIN sys.indexes AS si
ON (si.index_id > 0
and si.is_hypothetical = 0)
AND (si.object_id=tbl.object_id)
INNER JOIN sys.index_columns AS ic
ON (ic.column_id > 0
and (ic.key_ordinal > 0 or ic.partition_ordinal = 0 or ic.is_included_column != 0))
AND (ic.index_id=CAST(si.index_id AS int) AND ic.object_id=si.object_id)
INNER JOIN sys.columns AS clmns
ON clmns.object_id = ic.object_id
and clmns.column_id = ic.column_id
WHERE ic.is_included_column = 1 and
(si.index_id = @indid) and
(tbl.object_id= @objid)
SELECT @inc_columns = QUOTENAME([Name], N']') FROM #IncludedColumns WHERE RowNumber = 1
SET @loop_inc_Count = 1
WHILE @loop_inc_Count < @inc_Count
BEGIN
SELECT @inc_columns = @inc_columns + ', ' + QUOTENAME([Name], N']')
FROM #IncludedColumns WHERE RowNumber = @loop_inc_Count + 1
SET @loop_inc_Count = @loop_inc_Count + 1
END
END
select @groupname = null
select @groupname = name from sys.data_spaces where data_space_id = @groupid
-- Get the column list for the tree and leaf level, for all nonclustered indexes IF the table has a clustered index
IF @indid = 1 AND (SELECT is_unique FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 0
SELECT @ColsInTree = @keys + N', UNIQUIFIER', @ColsInLeaf = N'All columns "included" - the leaf level IS the data row, plus the UNIQUIFIER'
IF @indid = 1 AND (SELECT is_unique FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 1
SELECT @ColsInTree = @keys, @ColsInLeaf = N'All columns "included" - the leaf level IS the data row.'
IF @indid > 1 AND (SELECT COUNT(*) FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 1
exec sp_ExposeColsInIndexLevels @objid, @indid, @ColsInTree OUTPUT, @ColsInLeaf OUTPUT
IF @indid > 1 AND @is_unique = 0 AND (SELECT is_unique FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 0
SELECT @ColsInTree = @ColsInTree + N', UNIQUIFIER', @ColsInLeaf = @ColsInLeaf + N', UNIQUIFIER'
IF @indid > 1 AND @is_unique = 1 AND (SELECT is_unique FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 0
SELECT @ColsInLeaf = @ColsInLeaf + N', UNIQUIFIER'
IF @indid > 1 AND (SELECT COUNT(*) FROM sys.indexes WHERE index_id = 1 AND object_id = @objid) = 0 -- table is a HEAP
BEGIN
IF (@is_unique_key = 0)
SELECT @ColsInTree = @keys + N', RID'
, @ColsInLeaf = @keys + N', RID' + CASE WHEN @inc_columns IS NOT NULL THEN N', ' + @inc_columns ELSE N'' END
IF (@is_unique_key = 1)
SELECT @ColsInTree = @keys
, @ColsInLeaf = @keys + N', RID' + CASE WHEN @inc_columns IS NOT NULL THEN N', ' + @inc_columns ELSE N'' END
END
-- INSERT ROW FOR INDEX
insert into #spindtab values (@indname, @indid, @type, @ignore_dup_key, @is_unique, @is_hypothetical,
@is_primary_key, @is_unique_key, @is_disabled, @auto_created, @no_recompute, @groupname, @keys, @filter_definition, @inc_Count, @inc_columns, @ColsInTree, @ColsInLeaf)
-- Next index
fetch ms_crs_ind into @indid, @type, @groupid, @indname, @ignore_dup_key, @is_unique, @is_hypothetical,
@is_primary_key, @is_unique_key, @auto_created, @no_recompute, @filter_definition, @is_disabled
end
deallocate ms_crs_ind
-- DISPLAY THE RESULTS
select
'index_id' = index_id,
'is_disabled' = is_disabled,
'index_name' = index_name,
'index_description' = convert(varchar(210), --bits 16 off, 1, 2, 16777216 on, located on group
case when index_id = 1 and type = 1 then 'clustered'
when index_id > 1 and type = 6 then 'nonclustered columnstore'
when index_id > 1 and type = 2 then 'nonclustered'
when index_id > 1 and type = 3 then 'XML'
when index_id > 1 and type = 4 then 'Spatial'
when index_id > 1 and type = 5 then 'Clustered columnstore index'
when index_id > 1 and type = 7 then 'Nonclustered hash index'
else 'new index type' end
+ case when ignore_dup_key <>0 then ', ignore duplicate keys' else '' end
+ case when is_unique=1 then ', unique' else '' end
+ case when is_hypothetical <>0 then ', hypothetical' else '' end
+ case when is_primary_key <>0 then ', primary key' else '' end
+ case when is_unique_key <>0 then ', unique key' else '' end
+ case when auto_created <>0 then ', auto create' else '' end
+ case when no_recompute <>0 then ', stats no recompute' else '' end
+ ' located on ' + groupname),
'index_keys' =
case when type in(5,6,7) then 'n/a, see columns_in_leaf for details'
else index_keys end,
'included_columns' =
case when type in(5,6,7) then 'n/a, columnstore index'
else inc_columns end,
'filter_definition' =
case when type in(5,6,7) then 'n/a, columnstore index'
else filter_definition end,
'columns_in_tree' =
case when type in(5,6,7) then 'n/a, columnstore index'
else cols_in_tree end,
'columns_in_leaf' =
case when type in(5,6,7) then 'Columns with column-based index: ' + cols_in_leaf
else cols_in_leaf end
from #spindtab
order by index_id
return (0) -- sp_helpindex_SQL2016
go
exec sys.sp_MS_marksystemobject 'sp_helpindex_SQL2016'
go第三步,设置快捷键
通过第二步更改名称后,这个过程就更容易记住,加上智能输入提示,基本不用快捷键,也能很快输入。这里仍然将快捷键的设置方法说明一下:
在SSMS的工具→选项→环境→键盘,在Ctrl+F1的存储过程中输入sp_helpindex_SQL2016
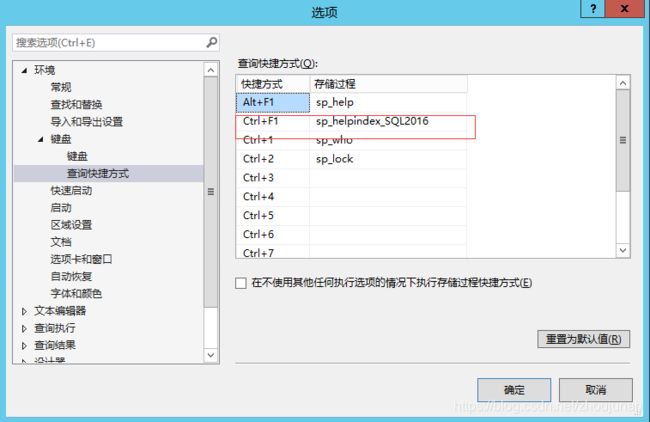
点击确定,重启SSMS,即可以使用Ctrl+F1快捷键查看索引信息了,下面使用快捷键Ctrl+F1查看数据库WideWorldImporters 中Sales架构下的Invoices表中的所有索引信息,输入表名,可以包括数据库名和架构名,选中表名,同时按先Ctrl和F1键,结果如下:
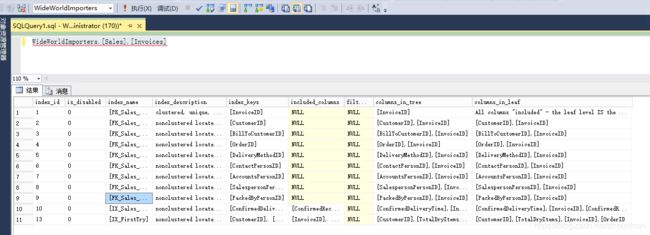
使用如下脚本,可以获得和上面一致的结果:
exec sp_helpindex_SQL2016 'WideWorldImporters.[Sales].[Invoices]'这样,修改后的sp_helpindex已经完全覆盖一个所有索引的基本信息,这对于后续的索引优化将很有帮助。
如果喜欢,可以扫码关注SQL Server 公众号,将有更多精彩内容分享: