复旦邱锡鹏教授:语言模型即服务的五类应用手段,你了解多少
近年来,深度学习已经成为了 NLP 领域的标配技术,2022年10 月15 日“小红书 REDtech 青年技术沙龙”活动中,我们非常荣幸地邀请到了上海复旦大学计算机学院邱锡鹏教授,邱教授分享了《语言模型即服务与黑箱优化》报告,详细讲解了语言模型越来越大的背景下对于新应用模式的探索。
邱锡鹏:国家优青获得者,于复旦大学获得理学学士和博士学位。主要从事自然语言处理、深度学习等方向的研究,发表 CCF A/B 类论文 70 余篇,获得 ACL 2017 杰出论文奖(CCF A 类)、CCL 2019 最佳论文奖、《中国科学:技术科学》2021 年度高影响力论文奖,有 5 篇论文入选 PaperDigest 发布的 IJCAI/ACL/EMNLP 的最有影响力论文(被引用数进入前当届会议的 20 名)。出版开源专著《神经网络与深度学习》,Github 关注数 1.5 万,豆瓣评分 9.4 分。主持开发了开源框架 FudanNLP 和 FastNLP,已被国内外数百家单位使用。2015 年入选首届中国科协青年人才托举工程项目,2018 年获钱伟长中文信息处理科学技术奖青年创新奖一等奖,2020 获第四届上海高校青年教师教学竞赛优等奖,2021 年获首届上海市计算机学会教学成果奖一等奖(第一完成人)等。培养学生多次获得一级学会优博、微软学者、百度奖学金等。
以下内容根据邱教授现场报告整理

背景
在预训练时代,我们大部分的研究工作分两个大类别:上游如何做模型的预训练,下游如何做精调,也就是把预训练模型迁移到下游任务。在上游有很多的公司主导如 Open AI、Google 等,他们把大模型做得非常大,显示出很多很优秀的能力如 Few-shot 小样本的能力。在参数的数量级上升之后,小样本的学习能力就变得非常强,这就是大家还是在不停地让这个模型变得越来越大的原因。
但是随着模型越来越大,这种预训练加精调的模式变得不可行了,一方面上游制造大模型的公司不愿意把它开源,另一方面下游的应用厂商也不太可能把它下载下来,即使下载也很难有资源运行。
所以我们要追求一种新的应用模式。比如以 GPT 为代表提出来的 in-context learning(在上下文中学习),给预训练模型输入一些提示或者例子,让原模型根据这些例子在下游任务上进行适配,它的效果也非常好,以 GPT-3 为例的一些模型表现得非常惊艳。in-context learning 成为我们在这个领域上研究的重点。

Language-Model-as-a-Service
语言模型即服务
如果模型是部署在服务端的,相当于把语言模型做成一个服务,我们就提出了“语言模型即服务”的概念。语言模型即服务事实上已经是一个很成熟的应用了,有很多的应用也都是基于语言模型即服务的能力。像 GPT-3 开发的一些下游的服务——我们可以用 GPT-3 生成一个网页按钮,用它把自然语言转化成数学公式等等。
在语言模型即服务中我们会存在两个挑战:
- 服务的原模型是什么?
- 如何把它适配到下游任务当中?

United Foundation Model
统一的预训练模型的目标是用一个模型来适配所有的自然语言处理任务,比如我们预训练一个模型,让它既能够支持理解任务,也可以支持生成任务。
CPT:一种非对称的预训练 Transformer
在传统的预训练模型上有几类代表,如以 BERT 为例的理解模型,GPT 为代表的生成模型,还有 BART。那么能不能把它们汇总到一起呢?我们提出了一个新的模型 CPT,它的核心思想就是将理解任务和生成任务合并到一起,比如我们把 BERT 和 BART 合并到一起的时候,发现都需要一个共同的编码器,共享编码器后我们得到如下图这种形状。
它同样是 Transformer 的 Encoder-Decoder 架构,但其左边可以用来做理解,右边可以做生成,在很多中文预训练任务上都能够达到目前最好的效果,同时非对称的 Transformer 的 Encoder-Decoder 架构,也使其生成效率提升了2倍以上。

Seq2Seq Masked Language Modeling
目前,自然语言处理当中,能够支持非常多任务类型的语言模型方式就是序列到序列模型,一个典型的代表就是 T5,它可以把很多的自然语言处理任务都转化成为序列到序列的形式。如果可以这样转化,我们的后台去部署一个这样序列到序列的基础模型,就可以用来支持下游任务了。
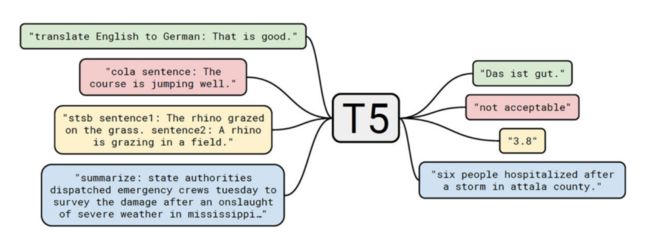
Text-to-Text Transfer Transformer (T5)
但是用 T5 处理自然语言处理任务时依然是非常有挑战性的,在更多的应用当中,一些任务通常来讲是比较难以转化的。比如 ABSA(在自然语言处理方面级的情感分析)。这里给出一句话 “Drink are always well made”,其中有一个评价对象,还有一个评价词以及他的情感倾向,这些都需要从这个句子中抽取出来。
事实上,ABSA 任务又分为很多的子任务,不同的子任务用于处理不同的情况。比如说像 a1 这个任务就是只抽取方面词,还有 o1 这个任务只抽取评价词,不同任务的形式都不一样,所以到目前为止没有一个模型能够同时支持在 ABSA 任务里面所有的子任务。
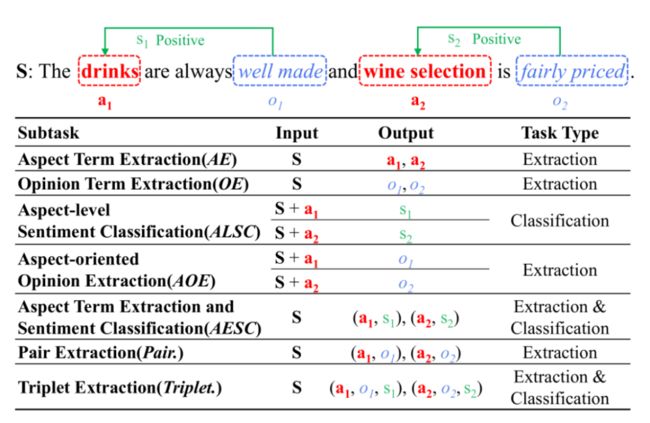
Seven ABSA subtasks
那么能不能用生成序列到序列模型的方式来同时处理7个子任务呢,事实上这个模型也非常简单,我们可以把 ABSA 任务做一个序列生成任务,把它变成一个抽取对象的序列下标的生成,比如说我们要抽取 aspect term “wine list”,我们只需要输出它的起始位置 1,还有它的结束位置 2,再抽 “service”,也是开始位置和结束位置,即 “12, 12”,以序列的方式把它的位置生成出来即可。

ABSA as Sequence Generation
对于三元组的任务,就生成“wine list” 1, 2,再生成对应的 Opinion “interesting”,再生成它的情感倾向,这样我们就把 ABSA 用统一的序列到序列的形式重新形式化,此时我们就可以用一个模型来支持所有的7个子任务,它统一框架就变得非常简单,用一个 BART 的 Encoder-Decoder 就能够去处理了。这个工作不但形式简单,用一个技术模型就做了所有的子任务,同时也得益于这些预训练模型,效果也比其他分开完成的方式更好。
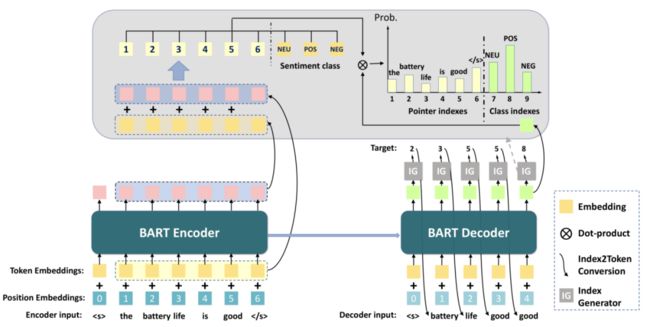
Overall Architecture
同样我们把这个想法也用到 NER(命名实体识别)上,NER也是在自然语言处理中非常重要的一类任务。在 NER 里有非常的多的子任务:
有连续的 NER:NER 中的词是连续出现的;
还有是嵌入的 NER:在一个实体里面嵌套另外一个实体;
以及不连续的 NER:一个实体可能是不连续的在正文出现。
传统解决方式是采用不同的算法来完成,比如连续的 NER 就会用序列标注,不连续的 NER 基本上利用转移方法。

Three kinds of NER tasks
序列标注很难处理不连续的 NER, 所以这些方法之间不通用,我们也可以用序列到序列的方法将 3 种 NER 的子任务做一个统一,同样类似于 ABSA 中的做法。
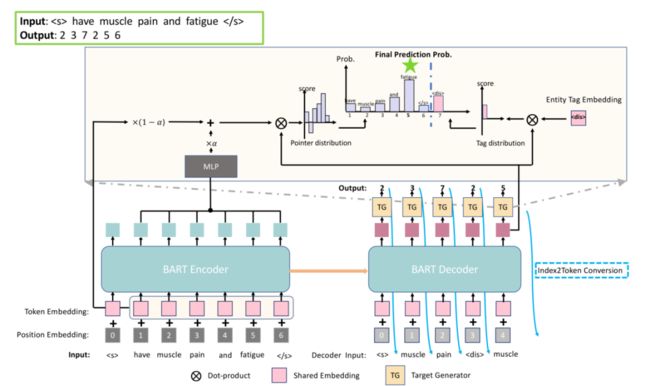
我们把 NER 生成出来,比如要抽取 “muscle pain”,我们就生成它对应的位置,然后再生成它对应的实体的类型即可。同样也可以用基础的 BART Encoder-Decoder ,这样它就可以非常方便地去做各种不同类型的 NER。这种方式效果也非常好,目前在主流的 NER 数据集上都能达到非常好的效果。

Efficient Tuning Algorithm
有了基础的统一预训练模型之后,我们怎么更加有效地把它迁移到下游的各种不同任务上呢?这里就分了很多种方式:
我们能不能想另外一个方法呢?是否可以把 Feature Space 固定,而去调 Label Space,把标签空间向特征空间靠拢?我们通常用 “y” 来表示标签,所以把这个方法叫做 “-Tuning”。
这个方法来自于我们更早之前的一个工作,这个工作可以将文本任务转化成文本匹配任务。传统的文本分配是给你一个句子输入它的标签,此时我们其实并没有太去利用标签的信息,比如说这个标签我们可以用一句话来描述的话,我们就可以把分类任务变成一个文本匹配任务,看这个句子和这个标签有没有进行相互的匹配。通过这种泛式的转变,我们就可以非常轻松的去提升文本分类的性能。
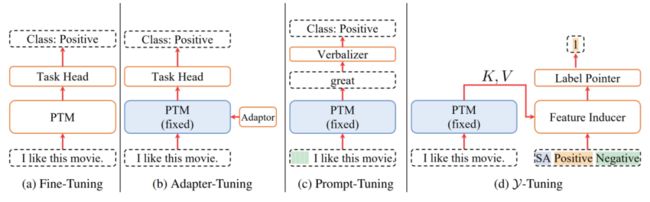
“-Tuning” 也是类似这种考虑。我们将标签或者是标签的表述作为输入,就构造如图架构,左边是预训练模型,其参数是固定不动的,只用来提取 Feature,右边输入一些标签,也就是 “”,同时还有一个 Task token,Task token 用来最后去指出最终的标签是哪一个,它也经过一个Transformer 的架构,类似于一个 Encoder-Decoder 的架构,只不过左端是不做调整的,我们只需要调右端的参数。右端的规模通常比较小,所以它的效率是非常高的。
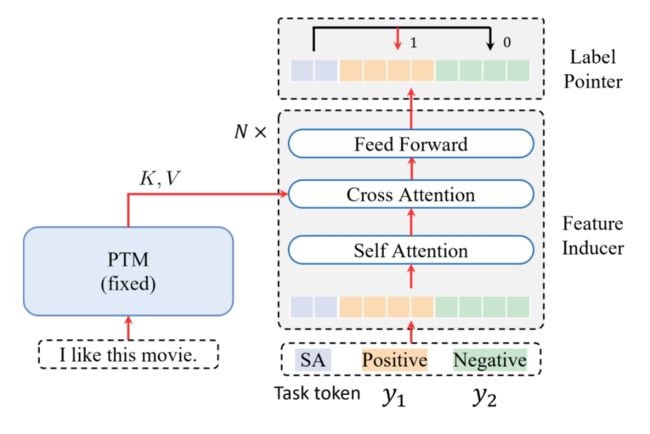
在架构上,“-Tuning”区别于“Fine-Tuning”, “Adapter-Tuning”, “Prompt-Tuning”,不需要计算 PTM 本身的梯度,所以其优化效率非常高。
在一些通用的语言理解数据集上,“-Tuning” 都能比像 “P-Tuning”, “Fix-Tuning” 效果要好。当然和 “Fine-tuning” 还有一定的差距,有很大的改进空间。
“-Tuning” 最大的优点就是训练效率特别高。它不需要计算预训练模型的梯度,所以首先在内存上会有很大的节省,节省的这些内存我们完全可以增大 Bech 之类的东西,进一步提升 “-Tuning” 的效率。
Black-Box Tuning
除了 “-Tuning” 之外,能不能依然调一些参数,但是同样不需要计算梯度,是否能达到这样的效果?
这就是 Black-Box Tuning(黑箱优化),黑箱优化的整体思想是这样的,我们把一个预训练模型部署在服务器端,把它当成一个黑盒子,它只提供前项的计算,我们还可以通过增加一些 Adapt、Prompt 去调节,把它适配到不同的任务上。
通常像 Prompt tuning 的方法,需要通过大模型计算梯度,再通过梯度调节 Prompt 参数,对于这些大模型部署在服务器上如 GBT, 是不可行的。我们希望把预训练模型看成一个黑箱,去寻找一个 Prompt,使得它在下游任务上的效果最好。一旦我们不能获得这个梯度,其实就把它转变成一个黑箱优化问题,或者是无梯度优化问题。在早期工作或优化工作中我们找到了一些有效的无梯度优化方法,但是它仅在低维空间比较有效,在高维空间由于搜索空间非常大,目前来讲还是非常低效。
特别对于大模型来讲,即便是 Prompt,它的参数也非常大。比如说 50 个 Prompt token,每个有 1000 维的话就是 5 万个参数,5 万个参数空间是非常大的。怎样把它在低维空间有效的无梯度优化用到高维空间呢,这是一个挑战。
所幸的是在高维空间中不是所有的参数都等同重要,比如神经网络中也有很多参数都是冗余的,有些参数并不是那么重要,因此在这么多的参数空间中,是不是可以发现这些 Prompt 或者是大模型的本征维度,它的本真维度可能在非常低维度的空间。我们在低维的本真维度空间去优化这个 Prompt,用无梯度的方法达到很好的效果。
基本框架如下图,首先我们把 Prompt 映射到低维空间,在低维空间中用无梯度优化的方法优化,完成之后再把它映射回去,这样可以通过无梯度优化的方法去优化大模型,并且把它适配到下游任务上。

Black-Box Tuning
在比如 Few-shot 这些任务上,Black-Box Tuning 基本可以追平基于梯度的方法,但是有一个缺点,我们的 Prompt 最好 Pre-train 一下。通过 Black-box 我们验证了可以用无梯度的方法进行大规模预训练模型的调参,但是依然存在缺陷,它的 Prompt 调起来依然非常困难,并且需要预训练。
我们能不能把技术进一步改善呢?我们就提出了第二个版本 BBTv2,在这个版本当中我们做了一些改进,我们不需要做 Prompt 的预训练,同时改进随机投影的方法,并且采用 Deep prompt,每一层都加一些 Prompt。事实证明这些策略是有效的。
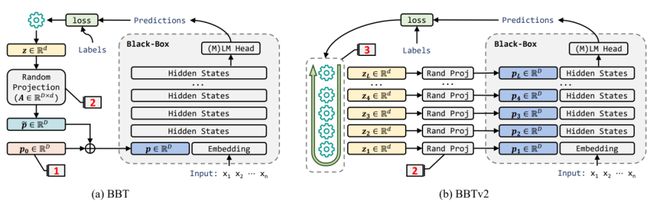
我们可以看到,经过这样一些改进之后,BBTv2 在比如一万个可调参数的情况下,它达到了目前最好的效果,比基于听的方法效果还要好,并且不需要 Pre-train。也就是说对于这些大模型来讲,我们用无梯度方法就能够打败基于梯度的方法,所以这也是这个工作的意义所在,也给将来一些大模型的应用提供了另外一个场景,把大模型部署在服务器端,只用它的 Forword 就行了,我们调参不需要梯度,只需要前项的计算。

Comparable to full model tuning but merely tuning ~10k parameters

Summary
“语言模型即服务”是本文的一个主要概念,语言模型即服务的应用手段,大概分成五类:
Text prompt:
可以人工设计一些基于文本的 Prompt,但是变成了特征工程问题,需要工程师不断去试,相当耗费精力。
In-context learing:
目前来讲 In-context learing 在 GPT 实验上是非常有效的,但在其他模型上还需要一定的验证,但是它是非常有前景的方向,其中的问题也非常值得大家去研究。
Data generation:
我们用大模型去生成一些数据,再用这些数据训练一个更小的模型,这也是一种方法。
Black-box optimization:
即上文所述的 Black-box tuning。
Feature-based-learning:
我们把预训练模型的输出作为一种 Feature,输入给一些特定的模型。“��-Tuning” 就是这种使用。

“Q&A”环节
Q:超大预训练模型语言模型 Large 的模型在工业应用上的可行性是怎样的,像刚刚提到的最近比较火的 Diffusion 模型,或者说其他一些复杂的多模态、预训练模型?
邱锡鹏:据我所知,这些大模型在工业界的应用非常多,比如说在一些终端任务上,特点是一旦有了基础应用,下游都不是问题。现在的主要问题是成本,如何高效的适配以及通过一些模型压缩或者其他方法来提高效率。
Q:生成式实体或者情感抽取应用到工业场景主要会面临什么挑战?
邱锡鹏:这个挑战还是在于,我们这里说的这些方法,其实还是需要大量的训练数据的,在真正的工业场景当中,很多时候标准数据不是那么多,这样的话生成模型不像其他的方法,或者说传统的训练方法效果好。但是我还是坚信随着预训练模型的发展,会有明显的提升。