【FusionInsight 问题】FusionInsight HD 6.5.1 集群中遇到的问题(01)
FusionInsight HD 6.5.1 集群中遇到的问题(01)
- FusionInsight HD 6.5.1 集群中遇到的问题(01)
-
- Spark-on-HBase认证问题
-
- Failed to find any Kerberos tgt
-
- 服务端配置修改
- 客户端配置修改
- Spark-on-HBase依赖包问题
-
- phoenix-core-4.13.1-HBase-1.3.jar
-
- 数据读取问题
- 数据写入问题
FusionInsight HD 6.5.1 集群中遇到的问题(01)
Spark-on-HBase认证问题
Failed to find any Kerberos tgt
在Spark应用程序中,如果操作了HBase或者Phoenix,那么在提交程序到集群运行的时候可能会遇到认证失败的问题。
org.apache.hadoop.hbase.DoNotRetryIOException: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
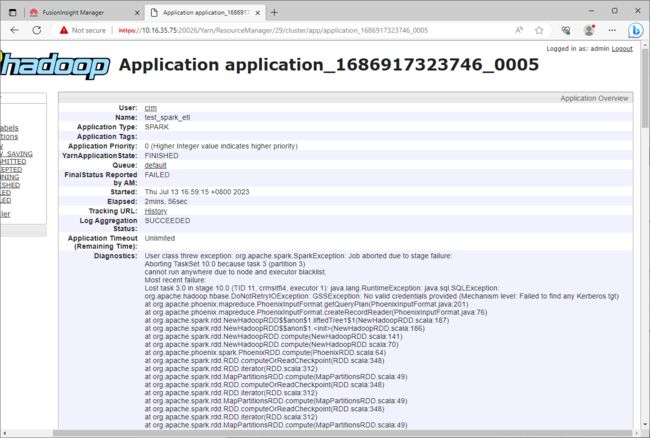
这个问题的主要原因是:在安全模式下,如果需要通过Spark操作HBase,即Spark-on-HBase,则需要启动HBase的验证功能,该配置默认是false的,需要将其修改为true。
服务端配置修改
在Spark2x服务下,找到配置,找到配置项spark.yarn.security.credentials.hbase.enabled将其值设置为true。
- ”基础配置“选项卡下的对应界面
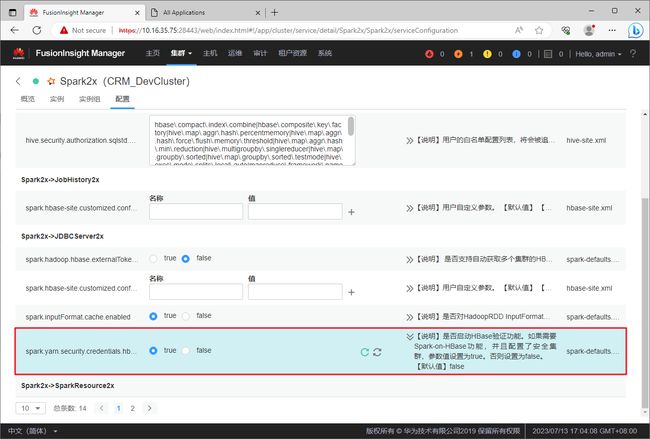
- ”全部配置“选项卡下的对应界面
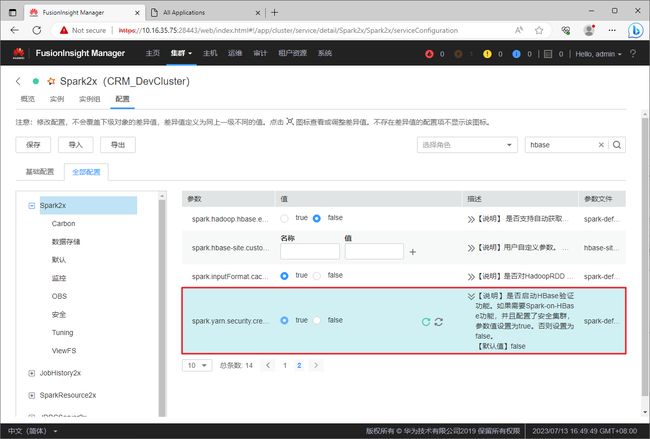
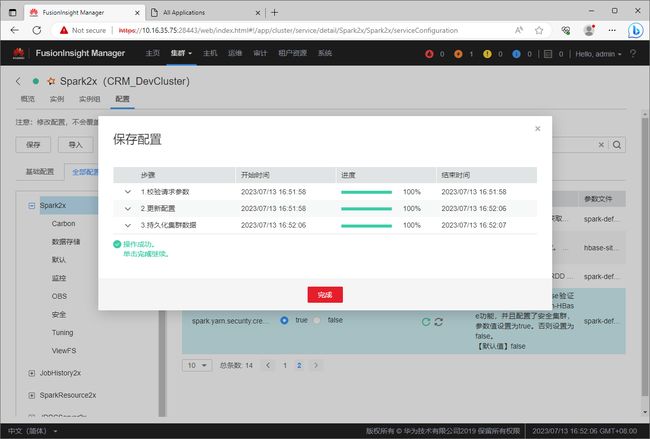
设置完成之后,需要点击”保存“按钮,将配置信息进行保存。
在弹出的”保存配置“对话框中,确认修改的信息后,点击”确定“按钮进行保存。
等待保存进度结束。
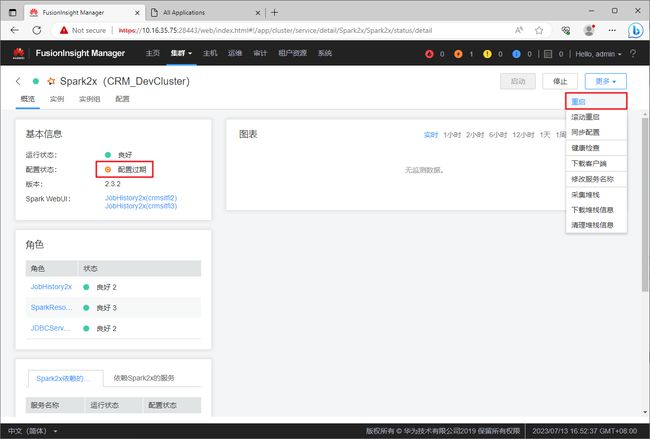
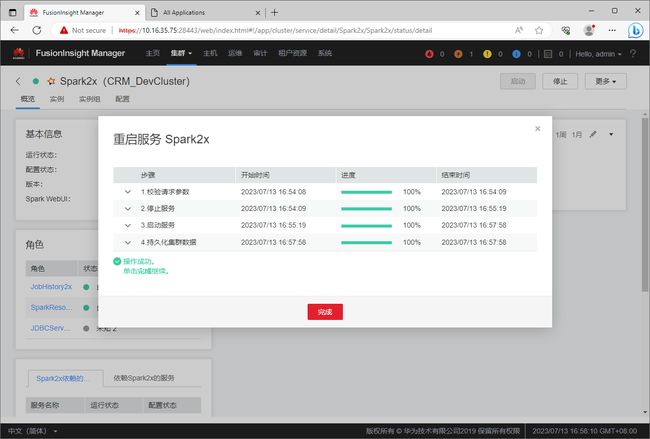
修改完配置后,集群中Spark2x服务的配置状态会变成”配置过期“。此时,需要重启服务才能让配置生效。通过【更多】->【重启】菜单重启Spark2x服务。
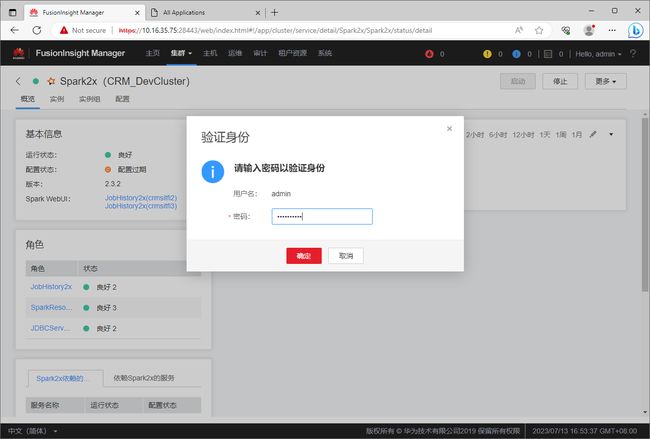
在弹出的”验证身份“对话框中输入密码,身份验证通过后FusionInsight才会重启Spark2x服务。
在弹出的”重启服务“对话框中,点击”确定“按钮,以对重启Spark2x服务进行确认。
尽量确保在没有Spark作业运行的情况下再去重启服务,因为服务重启过程中Spark2x服务将不可用。
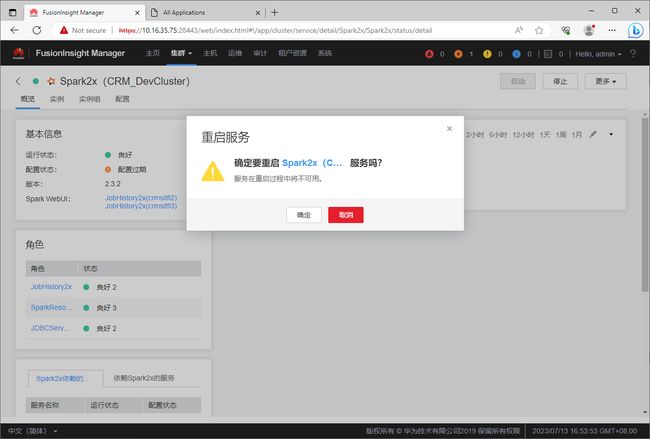
确认重启后,等待服务重启完成。
客户端配置修改
修改完服务端的配置后,重新提交Spark作业,可能还是会遇到同样的认证问题。这是因为我们仅修改了服务端的配置,但是客户端的配置还未修改。
还记得下载客户端的时候的”仅配置文件“选项吗?
我们的客户端已经安装完成,但是后来又修改了服务端的配置!
此时,就需要将服务端的配置同步到客户端。
可以重新安装客户端,选择”仅配置文件“,然后将配置文件覆盖到客户端。
另外,由于我们仅修改了一个配置项,比较简单,也可以直接手工修改客户端本地的配置文件即可。
修改客户端的/opt/hadoopclient/Spark2x/spark/conf/spark-defaults.conf配置文件。
目前该配置文件中的配置项还是false。

将该配置项修改为true。

修改完成客户端的配置后,再次提交Spark作业到集群运行,就不会遇到这个问题了。
但是,你有可能还会遇到其他问题~~~
Spark-on-HBase依赖包问题
phoenix-core-4.13.1-HBase-1.3.jar
数据读取问题
在Spark应用程序中,如果操读取了HBase或者Phoenix的数据,那么在提交程序到集群运行的时候可能会遇到JDBC驱动包缺失的问题。
java.lang.NoClassDefFoundError: org/apache/phoenix/jdbc/PhoenixDriver
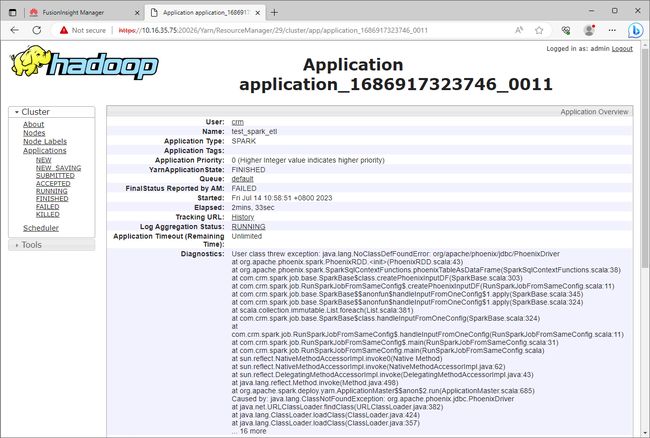
这是由于:Spark读取HBase的数据的时候,通过Phoenix使用JDBC的方式进行读取,需要添加依赖包phoenix-core-4.13.1-HBase-1.3.jar,这里面提供了JDBC驱动程序。
该包在客户端安装目录中有官方提供的版本,直接复制到自己的Spark应用程序的依赖软件包中即可,然后spark-submit的时候,使用--jars包含该jar包即可。
cp /opt/hadoopclient/HBase/hbase/lib/phoenix-core-4.13.1-HBase-1.3.jar ~/spark_job/lib/
数据写入问题
复制了jar包之后,再次提交Spark作业运行,数据读取问题会得到解决,但是数据写入还是会有问题。
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.phoenix.mapreduce.PhoenixOutputFormat not found
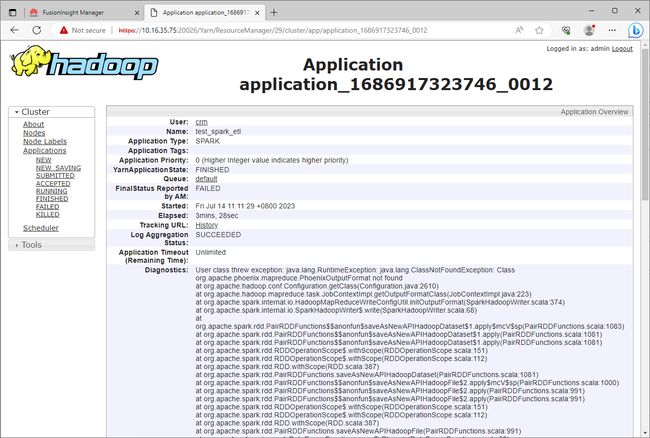
这是一个非常神奇的问题!
这是一个非常神奇的问题,神奇在哪里呢?
在读取数据的时候,我们遇到了org.apache.phoenix.jdbc.PhoenixDriver类不存在的问题,我们添加了依赖包phoenix-core-4.13.1-HBase-1.3.jar。
在写入数据的时候,我们遇到了org.apache.phoenix.mapreduce.PhoenixOutputFormat类不存在的问题。
神奇之处在于:
- phoenix-core-4.13.1-HBase-1.3.jar是客户端安装后的HBase下的包,属于华为官方提供的jar包。
- 打开phoenix-core-4.13.1-HBase-1.3.jar包,可以看到这个包中同时包含了org.apache.phoenix.jdbc.PhoenixDriver类和org.apache.phoenix.mapreduce.PhoenixOutputFormat类。
- 既然该jar包中同时包含了这两个类,并且读取数据正常,说明该jar包已正常加载,并读取到了org.apache.phoenix.jdbc.PhoenixDriver类。既然都已经正常加载了该jar包,那么为什么在写数据的时候还无法找到org.apache.phoenix.mapreduce.PhoenixOutputFormat类呢?
既然通过--jars提交phoenix-core-4.13.1-HBase-1.3.jar无法解决数据写入时的依赖问题,那么就只有将该jar包上传到Spark集群节点的classpath下了。
通过HDFS Web UI,找到文件hdfs://user/spark2x/jars/6.5.1.7/spark-archive-2x.zip文件,下载该文件,并将phoenix-core-4.13.1-HBase-1.3.jar添加到该压缩文件中,重新上传覆盖原文件。
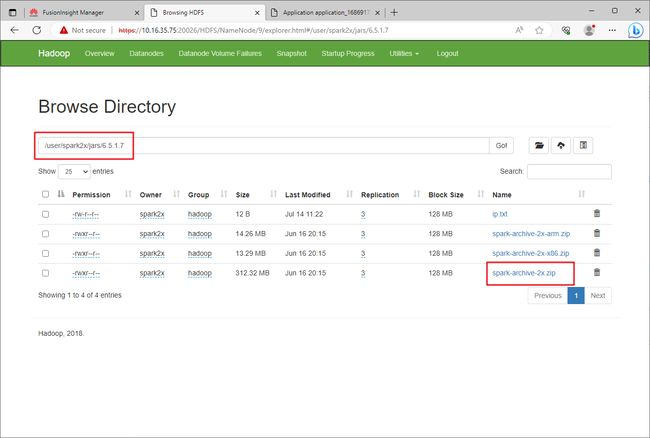
由于压缩包比较大312MB,所以直接在服务器上进行操作。
hdfs dfs -get /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip
unzip spark-archive-2x.zip
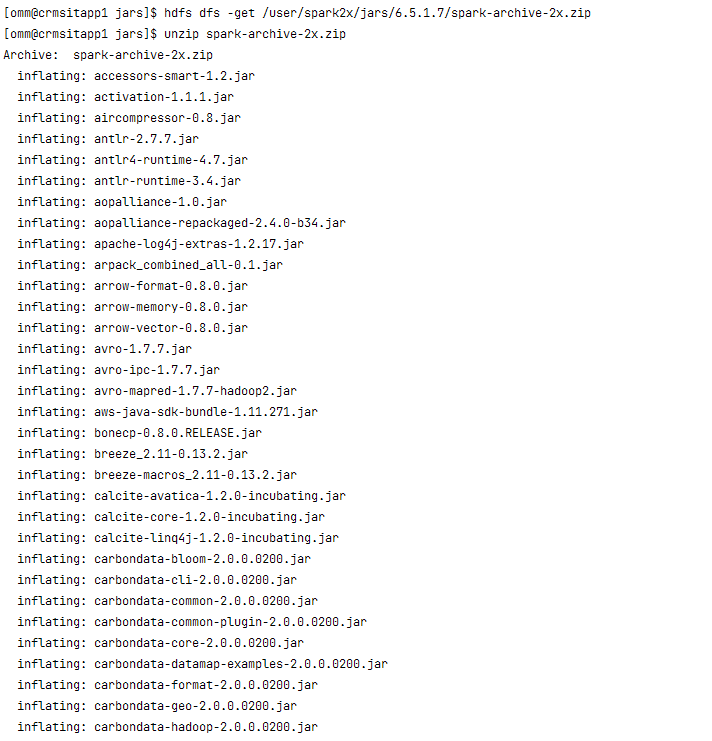
解压完成后,将phoenix-core-4.13.1-HBase-1.3.jar添加到目录中再进行压缩。
cp /opt/hadoopclient/HBase/hbase/lib/phoenix-core-4.13.1-HBase-1.3.jar ./
zip spark-archive-2x.zip *.jar
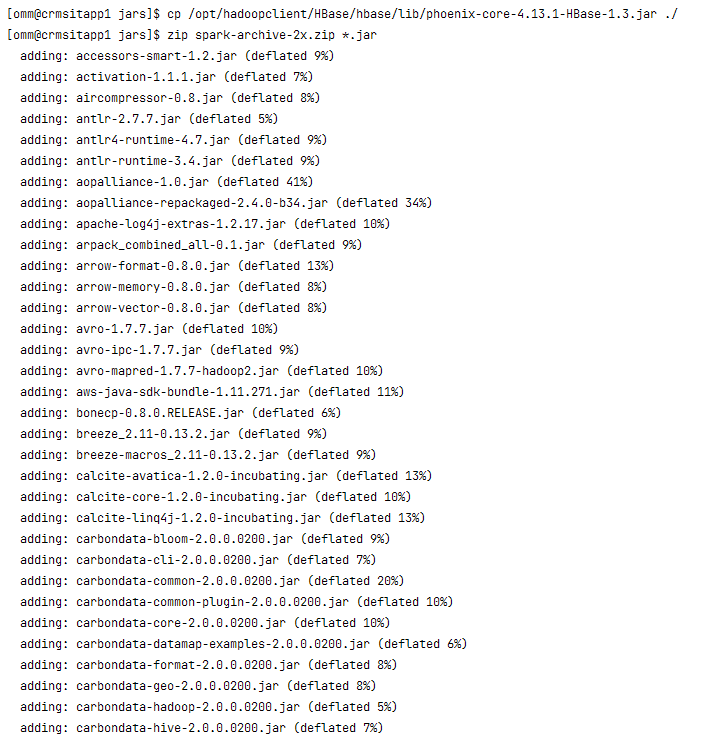
添加完成后,备份原始压缩文件,将新的压缩文件上传到相同路径,并修改文件所属用户、组、权限,以确保文件跟原文件的权限保持一致。
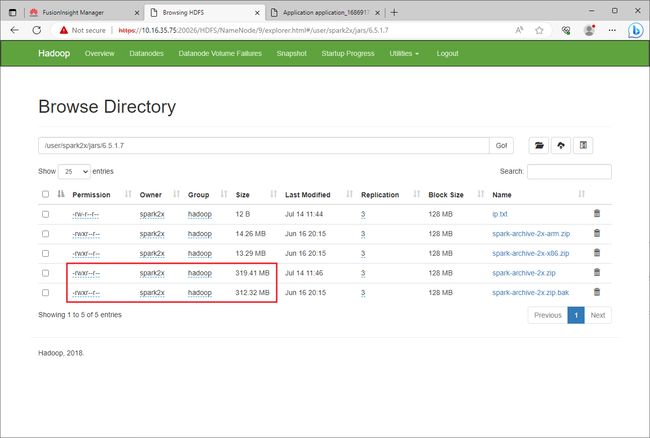
hdfs dfs -mv /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip.bak
hdfs dfs -put spark-archive-2x.zip /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip
hdfs dfs -chown spark2x:hadoop /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip
hdfs dfs -chmod 744 /user/spark2x/jars/6.5.1.7/spark-archive-2x.zip

确保文件具有相同路径、相同用户、组、权限等。
再次提交Spark作业运行,运行成功。
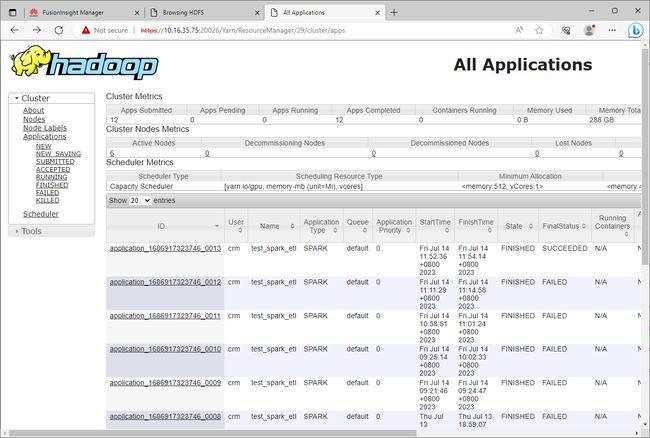
至此,依赖问题解决。